程序化分析工具
本文档介绍了多种用于编写和运行代码以分析在 BigQuery 中管理的数据的方法。
虽然 SQL 是一种功能强大的查询语言,但 Python、Java 或 R 等编程语言也提供了语法和大量内置统计函数,数据分析师可能会发现这些语言对特定类型的数据分析更具表现力和操作性。
同样,虽然电子表格被广泛使用,但笔记本等其他编程环境有时可提供更灵活的环境来进行复杂的数据分析和探索。
Colab Enterprise 笔记本
您可以在 BigQuery 中使用 Colab Enterprise 笔记本,借助 SQL、Python 以及其他常见的软件包和 API 完成分析和机器学习 (ML) 工作流。笔记本可通过以下选项改进协作和管理:
- 使用 Identity and Access Management (IAM) 与特定用户和群组共享笔记本。
- 查看笔记本版本记录。
- 还原到先前的笔记本版本或从先前的笔记本版本创建分支。
笔记本是由 Dataform 提供支持的 BigQuery Studio 代码资产,但 Dataform 中不会显示笔记本。已保存的查询也是代码资产。所有代码资产都存储在默认区域中。更新默认区域会更改此后创建的所有代码资产的区域。
笔记本功能仅在 Google Cloud 控制台中提供。
BigQuery 中的笔记本具有以下优势:
- BigQuery DataFrames 已集成到笔记本中,无需进行任何设置。BigQuery DataFrames 是一种 Python API,您可以使用 pandas DataFrame 和 scikit-learn API 大规模分析 BigQuery 数据。
- 由 Gemini 生成式 AI 提供支持的辅助式代码开发。
- SQL 语句的自动补全,与在 BigQuery 编辑器中相同。
- 能够保存、共享和管理笔记本的版本。
- 能够使用 matplotlib、seaborn 和其他常用库来直观呈现工作流中的任何时间点的数据。
- 能够在单元格中编写和执行 SQL,该单元格可以引用笔记本中的 Python 变量。
- 支持聚合和自定义的交互式 DataFrame 可视化。
您可以使用笔记本库模板开始使用笔记本。如需了解详情,请参阅使用笔记本库创建笔记本。
BigQuery DataFrames
BigQuery DataFrames 是一组开源 Python 库,可让您通过熟悉的 Python API 来充分利用 BigQuery 数据处理。BigQuery DataFrames 通过 SQL 转换将处理下推至 BigQuery,从而实现 Pandas 和 scikit-learn API。借助这种设计,您可以使用 BigQuery 探索和处理 TB 级的数据,以及训练机器学习 (ML) 模型,所有这些操作都通过 Python API 来完成。
BigQuery DataFrames 具有以下优势:
- 通过 SQL 到 BigQuery 和 BigQuery ML API 的透明转换实现了 750 多个 Pandas 和 scikit-learn API。
- 延迟查询执行以提升性能。
- 使用用户定义的 Python 函数扩展数据转换,使您可以在云端处理数据。这些函数会自动部署为 BigQuery 远程函数。
- 与 Vertex AI 集成,使您可以使用 Gemini 模型生成文本。
其他程序化分析解决方案
BigQuery 中还提供以下程序化分析解决方案。
Jupyter 笔记本
Jupyter 是一个开源 Web 应用,用于发布包含实时代码、文本说明和可视化的笔记本。数据科学家、机器学习专家和学生通常使用此平台来执行数据清理和转换、数值模拟、统计建模、数据可视化和机器学习等任务。
Jupyter 笔记本在 IPython 内核的基础上进行构建,IPython 内核是一种功能强大的互动式 shell,可通过适用于 BigQuery 的 IPython 魔法命令与 BigQuery 直接互动。或者,您还可以通过安装任何可用的 BigQuery 客户端库从 Jupyter 笔记本实例访问 BigQuery。您可以通过 GeoJSON 扩展程序使用 Jupyter 笔记本直观呈现 BigQuery GIS 数据。如需详细了解 BigQuery 集成,请参阅在 Jupyter 笔记本中直观呈现 BigQuery 数据教程。
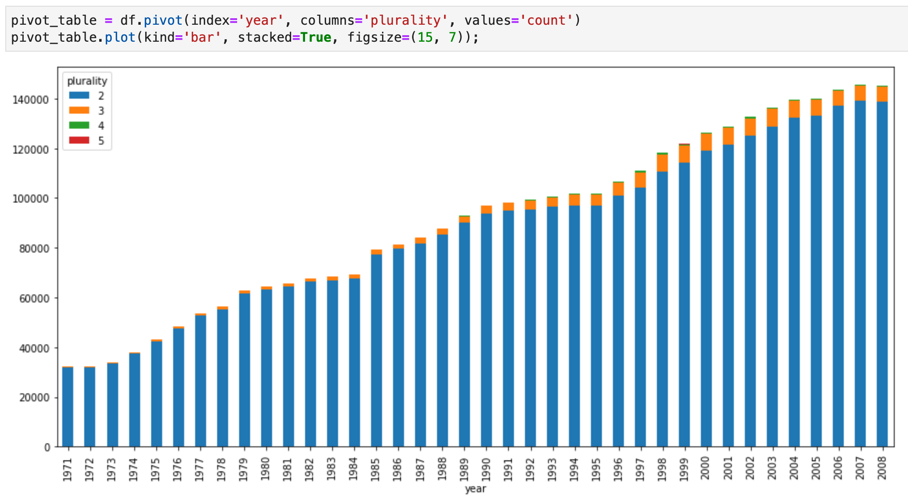
JupyterLab 是一个网页界面,用于管理文档和活动,例如 Jupyter 笔记本、文本编辑器、终端和自定义组件。借助 JupyterLab,您可以使用标签和分隔符在工作区中并行安排多个文档和活动。
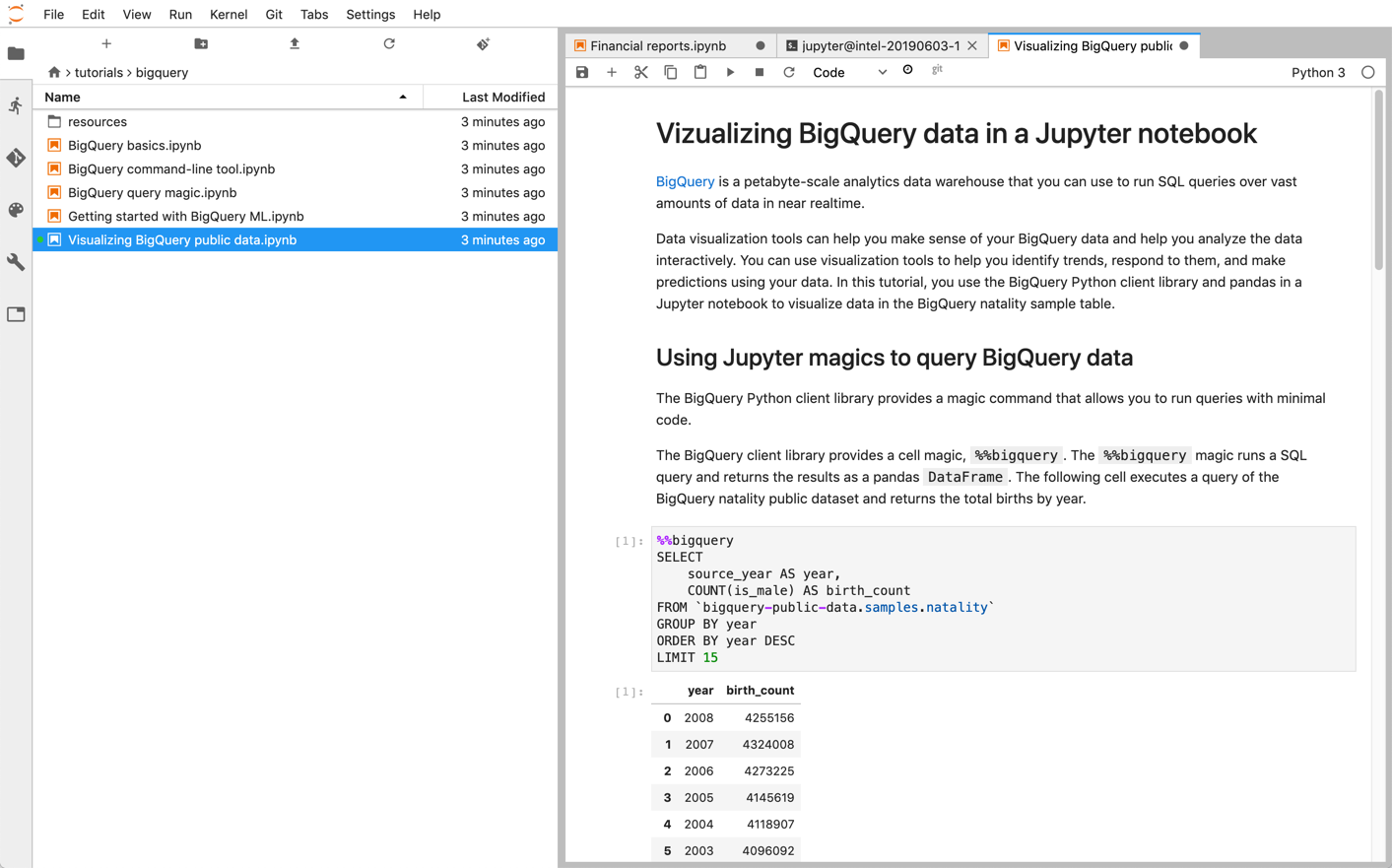
您可以使用以下任一产品在Google Cloud 上部署 Jupyter 笔记本和 JupyterLab 环境:
- Vertex AI Workbench 实例,该服务提供集成式 JupyterLab 环境,机器学习开发者和数据科学家可在该环境中使用一些最新的数据科学和机器学习框架。Vertex AI Workbench 集成了 BigQuery 等其他 Google Cloud 数据产品,可使您轻松进行数据注入、预处理和探索,并最终进行模型训练和部署。如需了解详情,请参阅 Vertex AI Workbench 实例简介。
- Dataproc 是一项快速、易用的全代管式服务,让您能够以简单、经济实惠的方式运行 Apache Spark 和 Apache Hadoop 集群。您可以使用 Jupyter 可选组件在 Dataproc 集群上安装 Jupyter 笔记本和 JupyterLab。该组件提供 Python 内核来运行 PySpark 代码。默认情况下,Dataproc 自动将笔记本配置为保存在 Cloud Storage 中,以便其他集群能够访问相同的笔记本文件。当您将现有笔记本迁移到 Dataproc 时,请检查受支持的 Dataproc 版本是否涵盖笔记本的依赖项。如需安装自定义软件,您可以考虑创建自定义 Dataproc 映像、编写自定义初始化操作或指定自定义 Python 软件包要求。如需开始使用此服务,请参阅在 Dataproc 集群上安装并运行 Jupyter 笔记本的教程。
Apache Zapepelin
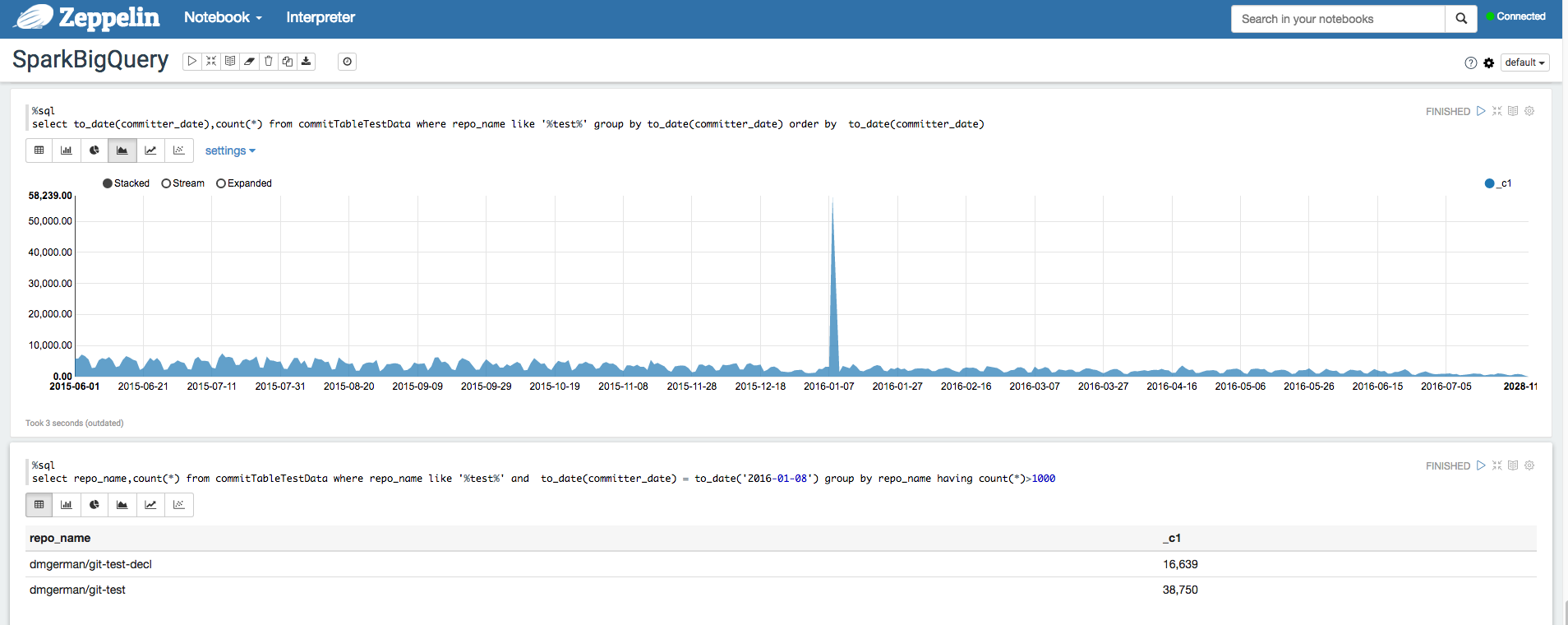
Apache Zeppelin 是一个开源项目,提供用于数据分析的 Web 笔记本。
您可以安装 Zeppelin 可选组件,以在 Dataproc 上部署 Apache Zeppelin 实例。默认情况下,笔记本保存在 Cloud Storage 的 Dataproc 暂存存储桶中,该存储桶由用户指定或在创建集群时自动创建。您可以在创建集群时添加 zeppelin:zeppelin.notebook.gcs.dir 属性来更改笔记本位置。如需详细了解如何安装和配置 Apache Zeppelin,请参阅 Zeppelin 组件指南。如需查看示例,请参阅使用适用于 Apache Zeppelin 的 BigQuery Parser 分析 BigQuery 数据集。
Apache Hadoop、Apache Spark 和 Apache Hive
在数据分析流水线迁移过程中,您可能需要迁移一些需要直接处理数据仓库中的数据的旧版 Apache Hadoop、Apache Spark 或 Apache Hive 作业。例如,您可能会提取您的机器学习工作负载的特征。
借助 Dataproc,您可以通过高效且经济实惠的方式部署全托管式 Hadoop 和 Spark 集群。Dataproc 与开源 BigQuery 连接器集成。这些连接器使用 BigQuery Storage API,此 API 通过 gRPC 直接从 BigQuery 并行流式传输数据。
当您将现有 Hadoop 和 Spark 工作负载迁移到 Dataproc 时,可以检查受支持的 Dataproc 版本是否涵盖工作负载的依赖项。如需安装自定义软件,您可以考虑创建自己的 Dataproc 映像、编写自己的初始化操作或指定自定义 Python 软件包要求。
如需开始使用此工具,请参阅 Dataproc 快速入门指南和 BigQuery 连接器代码示例。
Apache Beam
Apache Beam 是一种开源框架,提供一组丰富的数据选取和会话分析基本功能,以及一个包含来源连接器与接收器连接器(包括 BigQuery 的连接器)的生态系统。您可以通过 Apache Beam 以流式(实时)模式和批量(历史)模式对数据进行转换并丰富数据内容,同时保持同等的可靠性和表现力。
Dataflow 是一种用于大规模运行 Apache Beam 作业的全代管式服务。Dataflow 的无服务器方案减免了运营开销,同时可自动处理性能、规模、可用性、安全性和合规性方面的问题,因此您可专注于编程,而不用去管理服务器集群。
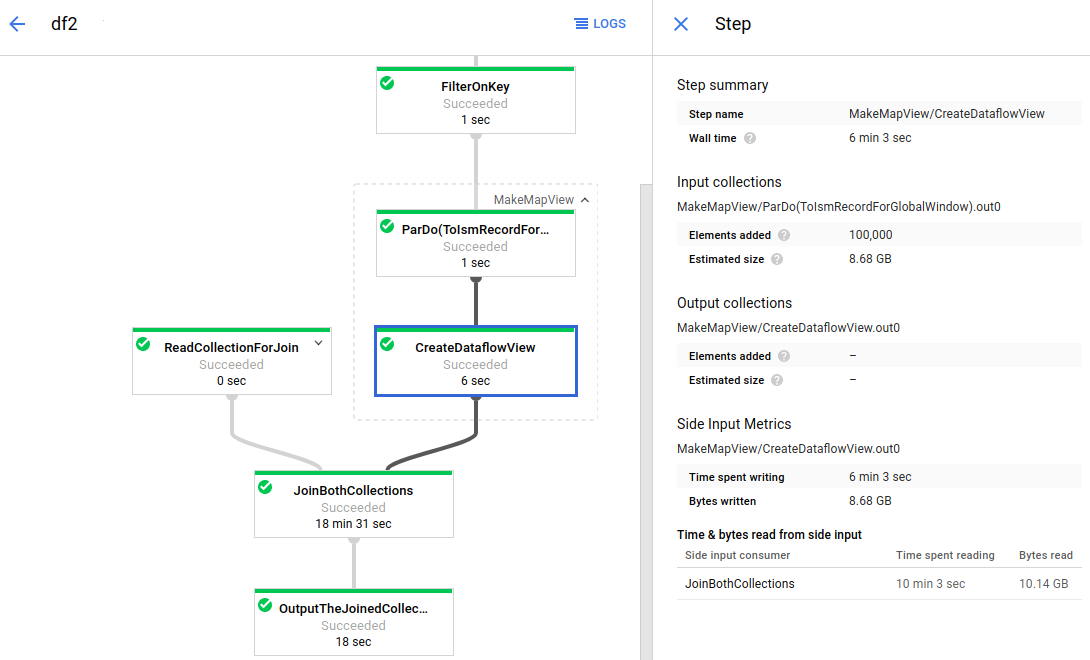
您可以通过命令行界面、Java SDK 或 Python SDK 提交 Dataflow 作业。
如果您想将数据查询和流水线从其他框架迁移到 Apache Beam 和 Dataflow,请参阅 Apache Beam 编程模型并浏览官方的 Dataflow 文档。
其他资源
BigQuery 提供大量支持 Java、Go、Python、JavaScript、PHP 和 Ruby 等多种编程语言的客户端库。一些数据分析框架(如 Pandas)提供了可直接与 BigQuery 进行交互的插件。如需查看一些实际的示例,请参阅在 Jupyter 笔记本中直观呈现 BigQuery 数据教程。
最后,如果您希望在 shell 环境中编写程序,可以使用 bq 命令行工具。