Introduction to partitioned tables
A partitioned table is divided into segments, called partitions, that make it easier to manage and query your data. By dividing a large table into smaller partitions, you can improve query performance and control costs by reducing the number of bytes read by a query. You partition tables by specifying a partition column which is used to segment the table.
If a query uses a qualifying filter on the value of the partitioning column, BigQuery can scan the partitions that match the filter and skip the remaining partitions. This process is called pruning.
In a partitioned table, data is stored in physical blocks, each of which holds one partition of data. Each partitioned table maintains various metadata about the sort properties across all operations that modify it. The metadata lets BigQuery more accurately estimate a query cost before the query is run.
When to use partitioning
Consider partitioning a table in the following scenarios:
- You want to improve the query performance by only scanning a portion of a table.
- Your table operation exceeds a standard table quota and you can scope the table operations to specific partition column values allowing higher partitioned table quotas.
- You want to determine query costs before a query runs. BigQuery provides query cost estimates before the query is run on a partitioned table. Calculate a query cost estimate by pruning a partitioned table, then issuing a query dry run to estimate query costs.
- You want any of the following partition-level management features:
- Set a partition expiration time to automatically delete entire partitions after a specified period of time.
- Write data to a specific partition using load jobs without affecting other partitions in the table.
- Delete specific partitions without scanning the entire table.
Consider clustering a table instead of partitioning a table in the following circumstances:
- You need more granularity than partitioning allows.
- Your queries commonly use filters or aggregation against multiple columns.
- The cardinality of the number of values in a column or group of columns is large.
- You don't need strict cost estimates before query execution.
- Partitioning results in a small amount of data per partition (approximately less than 10 GB). Creating many small partitions increases the table's metadata, and can affect metadata access times when querying the table.
- Partitioning results in a large number of partitions, exceeding the limits on partitioned tables.
- Your DML operations frequently modify (for example, every few minutes) most partitions in the table.
In such cases, table clustering lets you accelerate queries by clustering data in specific columns based on user-defined sort properties.
You can also combine clustering and table partitioning to achieve finer-grained sorting. For more information about this approach, see Combining clustered and partitioning tables.
Types of partitioning
This section describes the different ways to partition a table.
Integer range partitioning
You can partition a table based on ranges of values in a specific INTEGER
column. To create an integer-range partitioned table, you provide:
- The partitioning column.
- The starting value for range partitioning (inclusive).
- The ending value for range partitioning (exclusive).
- The interval of each range within the partition.
For example, suppose you create an integer range partition with the following specification:
| Argument | Value |
|---|---|
| column name | customer_id |
| start | 0 |
| end | 100 |
| interval | 10 |
The table is partitioned on the customer_id column into ranges of interval 10.
The values 0 to 9 go into one partition, values 10 to 19 go into the next
partition, etc., up to 99. Values outside this range go into a partition
named __UNPARTITIONED__. Any rows where customer_id is NULL go into a
partition named __NULL__.
For information about integer-range partitioned tables, see Create an integer-range partitioned table.
Time-unit column partitioning
You can partition a table on a DATE,TIMESTAMP, or DATETIME column in the
table. When you write data to the table, BigQuery automatically
puts the data into the correct partition, based on the values in the column.
For TIMESTAMP and DATETIME columns, the partitions can have either hourly,
daily, monthly, or yearly granularity. For DATE columns, the partitions can
have daily, monthly, or yearly granularity. Partitions boundaries are based on
UTC time.
For example, suppose that you partition a table on a DATETIME column with
monthly partitioning. If you insert the following values into the table, the
rows are written to the following partitions:
| Column value | Partition (monthly) |
|---|---|
DATETIME("2019-01-01") |
201901 |
DATETIME("2019-01-15") |
201901 |
DATETIME("2019-04-30") |
201904 |
In addition, two special partitions are created:
__NULL__: Contains rows withNULLvalues in the partitioning column.__UNPARTITIONED__: Contains rows where the value of the partitioning column is earlier than 1960-01-01 or later than 2159-12-31.
For information about time-unit column-partitioned tables, see Create a time-unit column-partitioned table.
Ingestion time partitioning
When you create a table partitioned by ingestion time, BigQuery automatically assigns rows to partitions based on the time when BigQuery ingests the data. You can choose hourly, daily, monthly, or yearly granularity for the partitions. Partitions boundaries are based on UTC time.
If your data might reach the maximum number of partitions per table when using a finer time granularity, use a coarser granularity instead. For example, you can partition by month instead of day to reduce the number of partitions. You can also cluster the partition column to further improve performance.
An ingestion-time partitioned table has a pseudocolumn named _PARTITIONTIME.
The value of this column is the ingestion time for each row, truncated to the
partition boundary (such as hourly or daily). For example, suppose that you
create an ingestion-time partitioned table with hourly partitioning and send
data at the following times:
| Ingestion time | _PARTITIONTIME |
Partition (hourly) |
|---|---|---|
| 2021-05-07 17:22:00 | 2021-05-07 17:00:00 | 2021050717 |
| 2021-05-07 17:40:00 | 2021-05-07 17:00:00 | 2021050717 |
| 2021-05-07 18:31:00 | 2021-05-07 18:00:00 | 2021050718 |
Because the table in this example uses hourly partitioning, the value of
_PARTITIONTIME is truncated to an hour boundary. BigQuery
uses this value to determine the correct partition for the data.
You can also write data to a specific partition. For example, you might want to load historical data or adjust for time zones. You can use any valid date between 0001-01-01 and 9999-12-31. However, DML statements cannot reference dates prior to 1970-01-01 or after 2159-12-31. For more information, see Write data to a specific partition.
Instead of using _PARTITIONTIME, you can also use
_PARTITIONDATE.
The _PARTITIONDATE pseudocolumn contains the UTC date corresponding to the value
in the _PARTITIONTIME pseudocolumn.
Select daily, hourly, monthly, or yearly partitioning
When you partition a table by time-unit column or ingestion time, you choose whether the partitions have daily, hourly, monthly, or yearly granularity.
Daily partitioning is the default partitioning type. Daily partitioning is a good choice when your data is spread out over a wide range of dates, or if data is continuously added over time.
Choose hourly partitioning if your tables have a high volume of data that spans a short date range — typically less than six months of timestamp values. If you choose hourly partitioning, make sure the partition count stays within the partition limits.
Choose monthly or yearly partitioning if your tables have a relatively small amount of data for each day, but span a wide date range. This option is also recommended if your workflow requires frequently updating or adding rows that span a wide date range (for example, more than 500 dates). In these scenarios, use monthly or yearly partitioning along with clustering on the partitioning column to achieve the best performance. For more information, see Combining clustered and partitioning tables in this document.
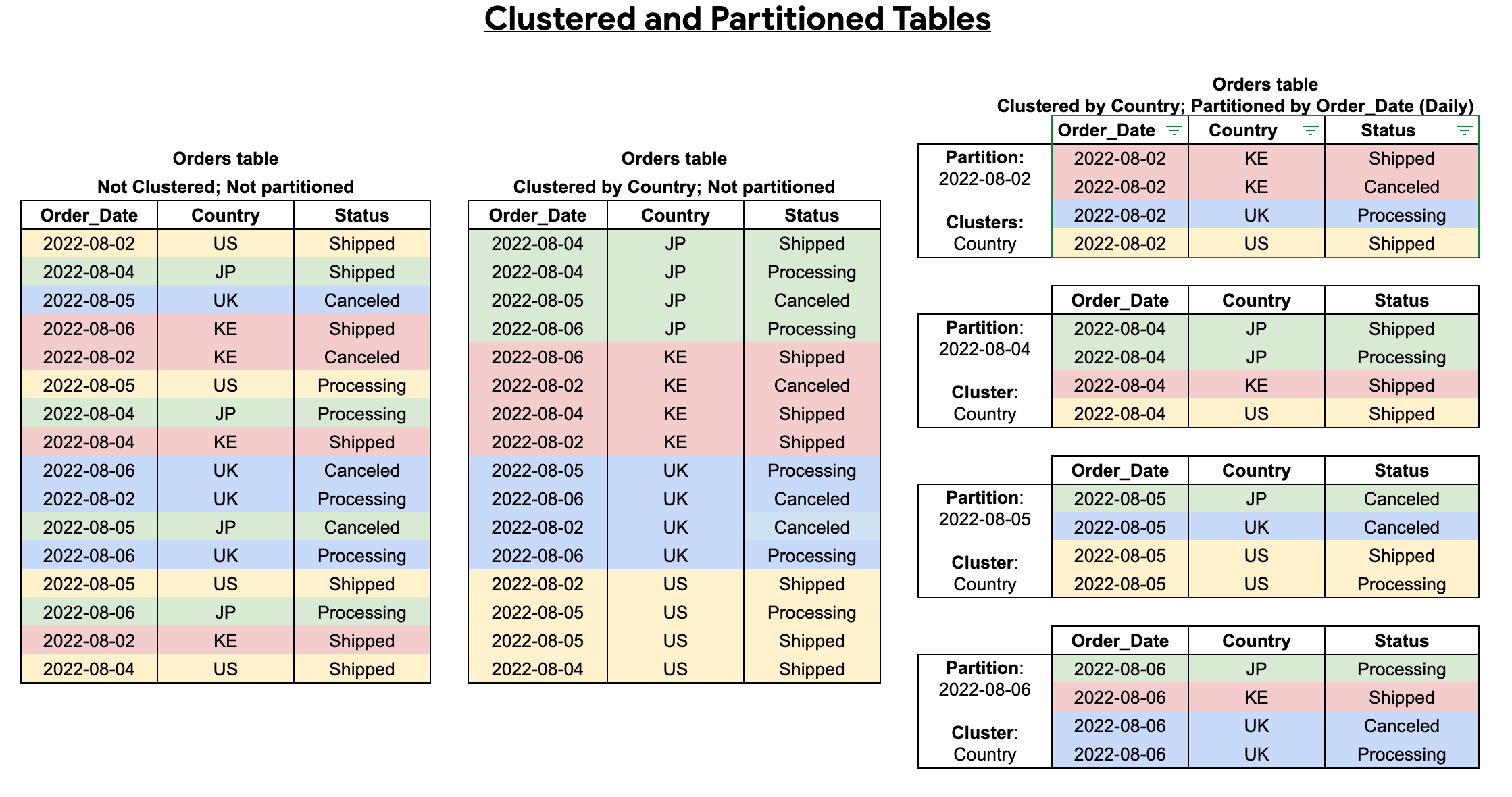
Combining clustered and partitioned tables
You can combine table partitioning with table clustering to achieve finely grained sorting for further query optimization.
A clustered table contains clustered columns that sort data based on user-defined sort properties. Data within these clustered columns are sorted into storage blocks which are adaptively sized based on the size of the table. When you run a query that filters by the clustered column, BigQuery only scans the relevant blocks based on the clustered columns instead of the entire table or table partition. In a combined approach using both table partitioning and clustering, you first segment table data into partitions, then you cluster the data within each partition by the clustering columns.
When you create a table that is clustered and partitioned, you can achieve more finely grained sorting, as the following diagram shows:
Partitioning versus sharding
Table sharding is the practice of storing data in multiple tables, using a
naming prefix such as [PREFIX]_YYYYMMDD.
Partitioning is recommended over table sharding, because partitioned tables perform better. With sharded tables, BigQuery must maintain a copy of the schema and metadata for each table. BigQuery might also need to verify permissions for each queried table. This practice also adds to query overhead and affects query performance.
If you previously created date-sharded tables, you can convert them into an ingestion-time partitioned table. For more information, see Convert date-sharded tables into ingestion-time partitioned tables.
Partition decorators
Partition decorators enable you to reference a partition in a table. For example, you can use them to write data to a specific partition.
A partition decorator has the form table_name$partition_id where the format
of the partition_id segment depends on the type of partitioning:
| Partitioning type | Format | Example |
|---|---|---|
| Hourly | yyyymmddhh |
my_table$2021071205 |
| Daily | yyyymmdd |
my_table$20210712 |
| Monthly | yyyymm |
my_table$202107 |
| Yearly | yyyy |
my_table$2021 |
| Integer range | range_start |
my_table$40 |
Browse the data in a partition
To browse the data in a specified partition, use the
bq head command with a
partition decorator.
For example, the following command lists all fields in the first 10 rows of
my_dataset.my_table in the 2018-02-24 partition:
bq head --max_rows=10 'my_dataset.my_table$20180224'
Export table data
Exporting all data from a partitioned table is the same process as exporting data from a non-partitioned table. For more information, see Exporting table data.
To export data from an individual partition, use the bq extract command and
append the partition decorator to
the table name. For example, my_table$20160201. You can also export data from
the __NULL__ and __UNPARTITIONED__
partitions by appending the partition names to the table name. For example,
my_table$__NULL__ or my_table$__UNPARTITIONED__.
Limitations
You cannot use legacy SQL to query partitioned tables or to write query results to partitioned tables.
BigQuery does not support partitioning by multiple columns. Only one column can be used to partition a table.
Time-unit column-partitioned tables are subject to the following limitations:
- The partitioning column must be either a scalar
DATE,TIMESTAMP, orDATETIMEcolumn. While the mode of the column can beREQUIREDorNULLABLE, it cannot beREPEATED(array-based). - The partitioning column must be a top-level field. You cannot use a leaf field
from a
RECORD(STRUCT) as the partitioning column.
For information about time-unit column-partitioned tables, see Create a time-unit column-partitioned table.
Integer-range partitioned tables are subject to the following limitations:
- The partitioning column must be an
INTEGERcolumn. While the mode of the column may beREQUIREDorNULLABLE, it cannot beREPEATED(array-based). - The partitioning column must be a top-level field. You cannot use a leaf field
from a
RECORD(STRUCT) as the partitioning column.
For information about integer-range partitioned tables, see Create an integer-range partitioned table.
Quotas and limits
Partitioned tables have defined limits in BigQuery.
Quotas and limits also apply to the different types of jobs you can run against partitioned tables, including:
- Loading data (load jobs)
- Exporting data (export jobs)
- Querying data (query jobs)
- Copying tables (copy jobs)
For more information on all quotas and limits, see Quotas and limits.
Table pricing
When you create and use partitioned tables in BigQuery, your charges are based on how much data is stored in the partitions and on the queries you run against the data:
- For information on storage pricing, see Storage pricing.
- For information on query pricing, see Query pricing.
Many partitioned table operations are free, including loading data into partitions, copying partitions, and exporting data from partitions. Though free, these operations are subject to BigQuery's Quotas and limits. For information on all free operations, see Free operations on the pricing page.
For best practices for controlling costs in BigQuery, see Controlling costs in BigQuery
Table security
Access control for partitioned tables is the same as access control for standard tables. For more information, see Introduction to table access controls.
What's next
- To learn how to create partitioned tables, see Creating partitioned tables.
- To learn how to manage and update partitioned tables, see Managing partitioned tables.
- For information on querying partitioned tables, see Querying partitioned tables.