Introducción a BigQuery Omni
.Con BigQuery Omni, puedes ejecutar analíticas de BigQuery en datos almacenados en Amazon Simple Storage Service (Amazon S3) o Azure Blob Storage mediante tablas BigLake.
Muchas organizaciones almacenan datos en varias nubes públicas. Con frecuencia estos datos acababan en silos, lo que complicaba la extracción de información valiosa a partir de ellos. Quieres poder analizar los datos con una herramienta de datos multicloud que sea económica y rápida, y que no cree una sobrecarga adicional de gobernanza de datos descentralizada. Al usar BigQuery Omni, reducimos estos problemas con una interfaz unificada.
Para ejecutar analíticas de BigQuery en sus datos externos, primero debe conectarse a Amazon S3 o a Blob Storage. Si quieres consultar datos externos, tendrás que crear una tabla BigLake que haga referencia a los datos de Amazon S3 o Blob Storage.
Herramientas de BigQuery Omni
Puedes usar las siguientes herramientas de BigQuery Omni para ejecutar analíticas de BigQuery en tus datos externos:
- Combinaciones entre nubes: ejecuta una consulta directamente desde una región de BigQuery que pueda combinar datos de una región de BigQuery Omni.
- Vistas materializadas entre nubes: usa réplicas de vistas materializadas para replicar continuamente datos de regiones de BigQuery Omni. Admite el filtrado de datos.
- Transferencia entre nubes con
SELECT: ejecuta una consulta con las instruccionesCREATE TABLE AS SELECToINSERT INTO SELECTen una región de BigQuery Omni y mueve el resultado a una región de BigQuery. - Transferencia entre nubes con
LOAD: UsaLOAD DATAinstrucciones para cargar datos directamente de Amazon Simple Storage Service (Amazon S3) o Azure Blob Storage en BigQuery.
En la siguiente tabla se resumen las principales funciones y características de cada herramienta multicloud:
| Uniones entre nubes | Vista materializada entre nubes | Transferencia entre nubes con SELECT |
Transferencia entre nubes con LOAD |
|
|---|---|---|---|---|
| Uso sugerido | Consulta datos externos para un solo uso, donde puedes combinar tablas locales o datos entre dos regiones de BigQuery Omni diferentes (por ejemplo, entre regiones de AWS y Azure Blob Storage). Usa combinaciones entre nubes si los datos no son grandes y si el almacenamiento en caché no es un requisito clave | Configura consultas repetidas o programadas para transferir continuamente datos externos de forma incremental, donde el almacenamiento en caché es un requisito clave. Por ejemplo, para mantener un panel de control | Consultar datos externos para un solo uso, de una región de BigQuery Omni a una región de BigQuery, donde los controles manuales, como el almacenamiento en caché y la optimización de consultas, son un requisito clave, y si usas consultas complejas que no son compatibles con las combinaciones entre nubes o las vistas materializadas entre nubes | Migrar conjuntos de datos de gran tamaño tal cual, sin necesidad de filtrarlos, mediante consultas programadas para mover datos sin procesar |
| Permite filtrar antes de mover los datos | Sí. Se aplican límites a determinados operadores de consulta. Para obtener más información, consulta Limitaciones de las uniones entre nubes. | Sí. Se aplican límites a determinados operadores de consulta, como las funciones de agregación y el operador UNION. |
Sí. Sin límites en los operadores de consulta | No |
| Limitaciones de tamaño de las transferencias | 60 GB por transferencia (cada subconsulta a una región remota genera una transferencia) | Sin límite | 60 GB por transferencia (cada subconsulta a una región remota genera una transferencia) | Sin límite |
| Compresión de transferencia de datos | Compresión de cables | Columnar | Compresión de cables | Compresión de cables |
| Almacenamiento en caché | No compatible | Se admite en tablas con caché habilitada y vistas materializadas | No compatible | No compatible |
| Precios de salida | Coste de salida de AWS y entre continentes | Coste de salida de AWS y entre continentes | Coste de salida de AWS y entre continentes | Coste de salida de AWS y entre continentes |
| Uso de recursos de computación para la transferencia de datos | Usa ranuras en la región de AWS o Azure Blob Storage de origen (reserva o bajo demanda). | No utilizado | Usa ranuras en la región de AWS o Azure Blob Storage de origen (reserva o bajo demanda). | No utilizado |
| Uso de recursos de computación para filtrar | Usa ranuras en la región de AWS o Azure Blob Storage de origen (reserva o bajo demanda). | Usa ranuras en la región de AWS o Azure Blob Storage de origen (de reserva o bajo demanda) para calcular las vistas materializadas y los metadatos locales. | Usa ranuras en la región de AWS o Azure Blob Storage de origen (reserva o bajo demanda). | No utilizado |
| Transferencia incremental | No compatible | Se admite en vistas materializadas no agregadas | No compatible | No compatible |
También puedes usar las siguientes alternativas para transferir datos de Amazon Simple Storage Service (Amazon S3) o Azure Blob Storage a Google Cloud:
- Servicio de transferencia de Storage: transfiere datos entre el almacenamiento de objetos y archivos en Google Cloud y Amazon Simple Storage Service (Amazon S3) o Azure Blob Storage.
- BigQuery Data Transfer Service: configura la transferencia de datos automatizada a BigQuery de forma gestionada y programada. Admite varias fuentes y es adecuada para la migración de datos. BigQuery Data Transfer Service no admite filtros.
Arquitectura
La arquitectura de BigQuery separa los recursos de computación del almacenamiento, lo que permite que BigQuery se escale horizontalmente según sea necesario para gestionar cargas de trabajo muy grandes. BigQuery Omni amplía esta arquitectura ejecutando el motor de consultas de BigQuery en otras nubes. Por lo tanto, no tienes que mover físicamente los datos al almacenamiento de BigQuery. El tratamiento se realiza donde ya se encuentran esos datos.
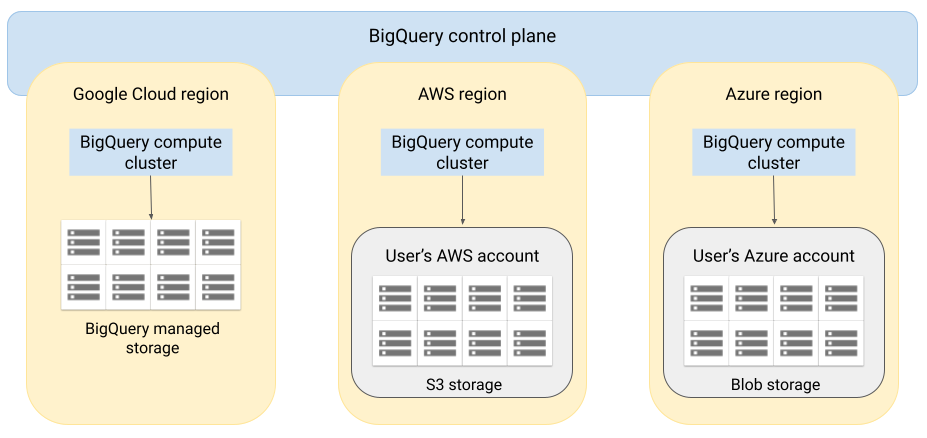
Los resultados de las consultas se pueden devolver a través de una conexión segura, por ejemplo, para que se muestren en la consola. Google Cloud Google Cloud También puedes escribir los resultados directamente en los segmentos de Amazon S3 o en Blob Storage. En ese caso, los resultados de la consulta no se mueven entre nubes.
BigQuery Omni usa roles de gestión de identidades y accesos (IAM) de AWS estándar o principales de Azure Active Directory para acceder a los datos de tu suscripción. Delegas el acceso de lectura o escritura en BigQuery Omni y puedes revocar el acceso en cualquier momento.
Flujo de datos al consultar datos
En la siguiente imagen se describe cómo se mueven los datos entre Google Cloud y AWS o Azure en las siguientes consultas:
SELECTdeclaraciónCREATE EXTERNAL TABLEdeclaración

- El plano de control de BigQuery recibe las tareas de consulta que envías a través de la consolaGoogle Cloud , la herramienta de línea de comandos bq, un método de API o una biblioteca de cliente.
- El plano de control de BigQuery envía tareas de consulta para que se procesen en el plano de datos de BigQuery en AWS o Azure.
- El plano de datos de BigQuery recibe la consulta del plano de control a través de una conexión VPN.
- El plano de datos de BigQuery lee los datos de las tablas de tu segmento de Amazon S3 o Blob Storage.
- El plano de datos de BigQuery ejecuta la tarea de consulta en los datos de la tabla. El procesamiento de los datos de las tablas se lleva a cabo en la región de AWS o Azure especificada.
- El resultado de la consulta se transmite del plano de datos al plano de control a través de la conexión VPN.
- El plano de control de BigQuery recibe los resultados del trabajo de consulta para mostrárselos en respuesta al trabajo de consulta. Estos datos se almacenan durante un máximo de 24 horas.
- Se te devuelve el resultado de la consulta.
Para obtener más información, consulta Consultar datos de Amazon S3 y datos de Blob Storage.
Flujo de datos al exportar datos
En la siguiente imagen se describe cómo se mueven los datos entre Google Cloud y AWS o Azure durante una instrucción EXPORT DATA.

- El plano de control de BigQuery recibe las tareas de consulta de exportación que envías a través de la consola de Google Cloud , la herramienta de línea de comandos bq, un método de API o una biblioteca de cliente. La consulta contiene la ruta de destino del resultado de la consulta en tu segmento de Amazon S3 o Blob Storage.
- El plano de control de BigQuery envía tareas de consulta de exportación para que se procesen en el plano de datos de BigQuery (en AWS o Azure).
- El plano de datos de BigQuery recibe la consulta de exportación del plano de control a través de la conexión VPN.
- El plano de datos de BigQuery lee los datos de las tablas de tu segmento de Amazon S3 o Blob Storage.
- El plano de datos de BigQuery ejecuta la tarea de consulta en los datos de la tabla. El procesamiento de los datos de la tabla se realiza en la región de AWS o Azure especificada.
- BigQuery escribe el resultado de la consulta en la ruta de destino especificada de tu segmento de Amazon S3 o Blob Storage.
Para obtener más información, consulta Exportar resultados de consultas a Amazon S3 y Blob Storage.
Ventajas
Rendimiento. Puedes obtener información valiosa más rápido, ya que los datos no se copian entre nubes y las consultas se ejecutan en la misma región en la que residen tus datos.
Coste. Ahorras en los costes de transferencia de datos salientes porque los datos no se mueven. No se aplican cargos adicionales a tu cuenta de AWS o Azure relacionados con las analíticas de BigQuery Omni, ya que las consultas se ejecutan en clústeres gestionados por Google. Solo se te cobra por ejecutar las consultas, según el modelo de precios de BigQuery.
Seguridad y control de los datos. Tú gestionas los datos de tu suscripción de AWS o Azure. No es necesario que transfieras ni copies los datos sin procesar de tu nube pública. Todos los cálculos se realizan en el servicio multitenant de BigQuery, que se ejecuta en la misma región que tus datos.
Arquitectura sin servidor. Al igual que el resto de BigQuery, BigQuery Omni es una oferta sin servidor. Google implementa y gestiona los clústeres que ejecutan BigQuery Omni. No tienes que aprovisionar ningún recurso ni gestionar ningún clúster.
Facilidad de gestión. BigQuery Omni proporciona una interfaz de gestión unificada a través de Google Cloud. BigQuery Omni puede usar tu Google Cloud cuenta y proyectos de BigQuery. Puedes escribir una consulta de GoogleSQL en la consola Google Cloud para consultar datos de AWS o Azure y ver los resultados en la consola Google Cloud .
Transferencia entre nubes. Puede cargar datos en tablas estándar de BigQuery desde los contenedores de S3 y Blob Storage. Para obtener más información, consulta los artículos sobre cómo transferir datos de Amazon S3 y Blob Storage a BigQuery.
Almacenamiento en caché de metadatos para mejorar el rendimiento
Puede usar metadatos almacenados en caché para mejorar el rendimiento de las consultas en tablas de BigLake que hagan referencia a datos de Amazon S3. Resulta especialmente útil cuando trabajas con un gran número de archivos o si los datos están particionados en Apache Hive.
BigQuery usa CMETA como sistema de metadatos distribuido para gestionar tablas grandes de forma eficiente. CMETA proporciona metadatos pormenorizados a nivel de columna y de bloque, a los que se puede acceder a través de tablas del sistema. Este sistema ayuda a mejorar el rendimiento de las consultas optimizando el acceso y el procesamiento de los datos. Para acelerar aún más el rendimiento de las consultas en tablas grandes, BigQuery mantiene una caché de metadatos. Los trabajos de actualización de CMETA mantienen esta caché actualizada.Los metadatos incluyen nombres de archivo, información de partición y metadatos físicos de archivos, como el número de filas. Puedes elegir si quieres habilitar el almacenamiento en caché de metadatos en una tabla. Las consultas con un gran número de archivos y con filtros de partición de Apache Hive son las que más se benefician del almacenamiento en caché de metadatos.
Si no habilita el almacenamiento en caché de metadatos, las consultas en la tabla deben leer la fuente de datos externa para obtener los metadatos del objeto. La lectura de estos datos aumenta la latencia de las consultas. Listar millones de archivos de la fuente de datos externa puede llevar varios minutos. Si habilitas el almacenamiento en caché de metadatos, las consultas pueden evitar enumerar archivos de la fuente de datos externa y pueden particionar y eliminar archivos más rápidamente.
El almacenamiento en caché de metadatos también se integra con la gestión de versiones de objetos de Cloud Storage. Cuando se rellena o se actualiza la caché, se capturan los metadatos en función de la versión activa de los objetos de Cloud Storage en ese momento. Por lo tanto, las consultas con el almacenamiento en caché de metadatos habilitado leen los datos correspondientes a la versión específica del objeto almacenado en caché, aunque se publiquen versiones más recientes en Cloud Storage. Para acceder a los datos de las versiones de objetos actualizadas posteriormente en Cloud Storage, es necesario actualizar la caché de metadatos.
Hay dos propiedades que controlan esta función:
- Antigüedad máxima especifica cuándo las consultas usan metadatos almacenados en caché.
- El modo de caché de metadatos especifica cómo se recogen los metadatos.
Si tienes habilitada la caché de metadatos, puedes especificar el intervalo máximo de obsolescencia de los metadatos que se acepta para las operaciones en la tabla. Por ejemplo, si especificas un intervalo de 1 hora, las operaciones en la tabla usarán los metadatos almacenados en caché si se han actualizado en la última hora. Si los metadatos almacenados en caché son anteriores a esa fecha, la operación recurre a la recuperación de metadatos de Amazon S3. Puedes especificar un intervalo de antigüedad entre 30 minutos y 7 días.
Cuando habilitas el almacenamiento de metadatos en caché para tablas de BigLake o de objetos, BigQuery activa tareas de actualización de la generación de metadatos. Puedes actualizar la caché de forma automática o manual:
- En el caso de las actualizaciones automáticas, la caché se actualiza a intervalos definidos por el sistema, normalmente entre 30 y 60 minutos. Actualizar la caché automáticamente es una buena opción si los archivos de Amazon S3 se añaden, eliminan o modifican a intervalos aleatorios. Si necesitas controlar el momento de la actualización (por ejemplo, para activarla al final de un trabajo de extracción, transformación y carga), usa la actualización manual.
Para las actualizaciones manuales, ejecuta el procedimiento del sistema
BQ.REFRESH_EXTERNAL_METADATA_CACHEpara actualizar la caché de metadatos según una programación que se ajuste a tus necesidades. Actualizar la caché manualmente es una buena opción si los archivos de Amazon S3 se añaden, eliminan o modifican a intervalos conocidos, por ejemplo, como resultado de una canalización.Si emite varias actualizaciones manuales simultáneas, solo se completará una.
La caché de metadatos caduca al cabo de 7 días si no se actualiza.
Tanto las actualizaciones de caché manuales como las automáticas se ejecutan con la prioridad de consulta INTERACTIVE.
Usar reservas de BACKGROUND
Si decides usar las actualizaciones automáticas, te recomendamos que crees una reserva y, a continuación, una asignación con el tipo de tarea BACKGROUND para el proyecto que ejecute las tareas de actualización de la caché de metadatos. Con las reservas de BACKGROUND, las tareas de actualización usan un grupo de recursos específico, lo que evita que compitan con las consultas de los usuarios y que puedan fallar si no hay suficientes recursos disponibles.
Aunque el uso de un grupo de ranuras compartido no conlleva ningún coste adicional, el uso de BACKGROUND reservas proporciona un rendimiento más constante al asignar un grupo de recursos específico y mejora la fiabilidad de los trabajos de actualización y la eficiencia general de las consultas en BigQuery.
Antes de definir los valores del intervalo de obsolescencia y del modo de almacenamiento en caché de metadatos, debes tener en cuenta cómo interactuarán. Ten en cuenta los siguientes ejemplos:
- Si actualizas manualmente la caché de metadatos de una tabla y estableces el intervalo de obsolescencia en 2 días, debes ejecutar el procedimiento del sistema
BQ.REFRESH_EXTERNAL_METADATA_CACHEcada 2 días o menos si quieres que las operaciones de la tabla usen metadatos almacenados en caché. - Si actualizas automáticamente la caché de metadatos de una tabla y estableces el intervalo de obsolescencia en 30 minutos, es posible que algunas de tus operaciones en la tabla lean datos de Amazon S3 si la actualización de la caché de metadatos tarda más de lo habitual (entre 30 y 60 minutos).
Para obtener información sobre los trabajos de actualización de metadatos, consulta la vista INFORMATION_SCHEMA.JOBS, como se muestra en el siguiente ejemplo:
SELECT * FROM `region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT` WHERE job_id LIKE '%metadata_cache_refresh%' AND creation_time > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 6 HOUR) ORDER BY start_time DESC LIMIT 10;
Para obtener más información, consulta Almacenamiento en caché de metadatos.
Tablas habilitadas para la caché con vistas materializadas
Puedes usar vistas materializadas en tablas con la caché de metadatos de Amazon Simple Storage Service (Amazon S3) habilitada para mejorar el rendimiento y la eficiencia al consultar datos estructurados almacenados en Amazon S3. Estas vistas materializadas funcionan como las vistas materializadas de las tablas de almacenamiento gestionadas por BigQuery, incluidas las ventajas de la actualización automática y la optimización inteligente.
Para que los datos de Amazon S3 de una vista materializada estén disponibles en una región de BigQuery admitida para las combinaciones, crea una réplica de la vista materializada. Solo puede crear réplicas de vistas materializadas en vistas materializadas autorizadas.
Limitaciones
Además de las limitaciones de las tablas de BigLake, se aplican las siguientes limitaciones a BigQuery Omni, que incluye tablas de BigLake basadas en datos de Amazon S3 y Blob Storage:
- Las ediciones Standard y Enterprise Plus no admiten el uso de datos en ninguna de las regiones de BigQuery Omni. Para obtener más información sobre las ediciones, consulta el artículo Introducción a las ediciones de BigQuery.
- Las
OBJECT_PRIVILEGES,STREAMING_TIMELINE_BY_*,TABLE_SNAPSHOTS,TABLE_STORAGE,TABLE_CONSTRAINTS,KEY_COLUMN_USAGE,CONSTRAINT_COLUMN_USAGEyPARTITIONSvistas no están disponibles para las tablas de BigLake basadas en datos de Amazon S3 y Blob Storage.INFORMATION_SCHEMA - Las vistas materializadas no se admiten en Blob Storage.
- No se admiten funciones definidas por el usuario de JavaScript.
No se admiten las siguientes instrucciones SQL:
- Declaraciones de BigQuery ML.
- Instrucciones del lenguaje de definición de datos (DDL)
que requieren datos gestionados en BigQuery. Por ejemplo, se admiten
CREATE EXTERNAL TABLE,CREATE SCHEMAyCREATE RESERVATION, pero noCREATE TABLE. - Declaraciones de lenguaje de manipulación de datos (DML).
Se aplican las siguientes limitaciones a las consultas y lecturas de tablas temporales de destino:
- No se pueden consultar tablas temporales de destino con la instrucción
SELECT.
- No se pueden consultar tablas temporales de destino con la instrucción
Las consultas programadas solo se admiten a través de la API o de la CLI. La opción Tabla de destino está inhabilitada para las consultas. Solo se permiten consultas
EXPORT DATA.La API Storage de BigQuery no está disponible en las regiones de BigQuery Omni.
Si tu consulta usa la cláusula
ORDER BYy el tamaño de los resultados es superior a 256 MB, la consulta fallará. Para solucionarlo, reduce el tamaño del resultado o elimina la cláusulaORDER BYde la consulta. Para obtener más información sobre las cuotas de BigQuery Omni, consulta Cuotas y límites.No se admite el uso de claves de encriptado gestionadas por el cliente (CMEK) con conjuntos de datos y tablas externas.
Precios
Para obtener información sobre los precios y las ofertas por tiempo limitado de BigQuery Omni, consulta los precios de BigQuery Omni.
Cuotas y límites
Para obtener información sobre las cuotas de BigQuery Omni, consulta Cuotas y límites.
Si el resultado de la consulta es superior a 20 GiB, considere la posibilidad de exportarlo a Amazon S3 o Blob Storage. Para obtener información sobre las cuotas de la API Connection de BigQuery, consulta API Connection de BigQuery.
Ubicaciones
BigQuery Omni procesa las consultas en la misma ubicación que el conjunto de datos que contiene las tablas que estás consultando. Una vez creado el conjunto de datos, la ubicación no se puede cambiar. Tus datos se encuentran en tu cuenta de AWS o Azure. Las regiones de BigQuery Omni admiten reservas de la edición Enterprise y precios de computación (análisis) bajo demanda. Para obtener más información sobre las ediciones, consulta el artículo Introducción a las ediciones de BigQuery.
| Descripción de la región | Nombre de la región | Región de BigQuery colocada | |
|---|---|---|---|
| AWS | |||
| AWS: Este de EE. UU. Virginia) | aws-us-east-1 |
us-east4 |
|
| AWS - Oeste de EE. UU. (Oregón) | aws-us-west-2 |
us-west1 |
|
| AWS - Asia Pacífico (Seúl) | aws-ap-northeast-2 |
asia-northeast3 |
|
| AWS - Asia Pacífico (Sídney) | aws-ap-southeast-2 |
australia-southeast1 |
|
| AWS - Europa (Irlanda) | aws-eu-west-1 |
europe-west1 |
|
| AWS - Europa (Fráncfort) | aws-eu-central-1 |
europe-west3 |
|
| Azure | |||
| Azure - Este de EE. UU. 2 | azure-eastus2 |
us-east4 |
|
Siguientes pasos
- Consulta cómo conectarte a Amazon S3 y a Blob Storage.
- Consulta cómo crear tablas de BigLake de Amazon S3 y Blob Storage.
- Consulta cómo consultar tablas de BigLake de Amazon S3 y Blob Storage.
- Consulta cómo combinar tablas de BigLake de Amazon S3 y Blob Storage con tablas de Google Cloud mediante combinaciones entre nubes.
- Consulta cómo exportar resultados de consultas a Amazon S3 y Blob Storage.
- Consulta cómo transferir datos de Amazon S3 y Blob Storage a BigQuery.
- Consulta cómo configurar un perímetro de Controles de Servicio de VPC.
- Consulta cómo especificar tu ubicación.