BigQuery Omni 소개
BigQuery Omni를 사용하면 BigLake 테이블을 사용하여 Amazon Simple Storage Service(Amazon S3) 또는 Azure Blob Storage에 저장된 데이터에 대해 BigQuery 분석을 실행할 수 있습니다.
많은 조직들이 데이터를 퍼블릭 클라우드에 저장합니다. 하지만 모든 데이터로부터 유용한 정보를 얻는 것이 어렵기 때문에 이러한 데이터가 결국 고립되는 경우가 많습니다. 저렴하고, 빠르고, 분산된 데이터 거버넌스에 따른 추가 오버헤드를 일으키지 않는 멀티 클라우드 데이터 도구를 사용해서 데이터를 분석할 수 있어야 합니다. BigQuery Omni를 사용하면 통합된 인터페이스를 통해 이러한 문제를 줄일 수 있습니다.
외부 데이터에 대한 BigQuery 분석을 실행하려면 먼저 Amazon S3 또는 Blob Storage에 연결해야 합니다. 외부 데이터를 쿼리하려면 Amazon S3 또는 Blob Storage 데이터를 참조하는 BigLake 테이블을 만들어야 합니다.
BigQuery Omni 도구
다음 BigQuery Omni 도구를 사용하여 외부 데이터에 BigQuery 분석을 실행할 수 있습니다.
- 교차 클라우드 조인: BigQuery Omni 리전의 데이터를 조인할 수 있는 BigQuery 리전에서 직접 쿼리를 실행합니다.
- 교차 클라우드 구체화된 뷰: 구체화된 뷰 복제본을 사용하여 BigQuery Omni 리전의 데이터를 지속적으로 복제합니다. 데이터 필터링을 지원합니다.
SELECT를 사용한 교차 클라우드 전송: BigQuery Omni 리전에서CREATE TABLE AS SELECT또는INSERT INTO SELECT문을 사용하여 쿼리를 실행하고 결과를 BigQuery 리전으로 이동합니다.LOAD를 사용한 교차 클라우드 전송:LOAD DATA문을 사용하여 Amazon Simple Storage Service(Amazon S3) 또는 Azure Blob Storage에서 BigQuery로 직접 데이터를 로드합니다.
다음 표에는 각 교차 클라우드 도구의 주요 기능과 기능이 간략히 나와 있습니다.
| 교차 클라우드 조인 | 교차 클라우드 구체화된 뷰 | SELECT를 사용한 교차 클라우드 전송 |
LOAD를 사용한 교차 클라우드 전송 |
|
|---|---|---|---|---|
| 추천 사용량 | 일회성으로 외부 데이터를 쿼리합니다. 이때 로컬 테이블과 조인하거나 두 개의 서로 다른 BigQuery Omni 리전(예: AWS 리전과 Azure Blob Storage 리전 간의 데이터 조인) 간에 데이터를 조인할 수 있습니다. 데이터가 크지 않고 캐싱이 주요 요구사항이 아닌 경우 교차 클라우드 조인을 사용합니다. | 캐싱이 중요한 요구사항인 경우 외부 데이터를 점진적으로 지속적으로 전송하도록 반복 또는 예약된 쿼리를 설정합니다. 예를 들어 대시보드를 유지 관리하는 경우가 있습니다. | 캐싱 및 쿼리 최적화와 같은 수동 제어가 주요 요구사항인 BigQuery Omni 리전에서 BigQuery 리전으로 일회성으로 사용할 외부 데이터를 쿼리하는 경우, 교차 클라우드 조인 또는 교차 클라우드 구체화된 뷰에서 지원하지 않는 복잡한 쿼리를 사용하는 경우 | 필터링 없이 대규모 데이터 세트를 그대로 마이그레이션하고 예약된 쿼리를 사용하여 원시 데이터를 이동 |
| 데이터 이동 전 필터링 지원 | 예. 특정 쿼리 연산자에는 한도가 적용됩니다. 자세한 내용은 교차 클라우드 조인 제한사항을 참고하세요. | 예. 집계 함수 및 UNION 연산자와 같은 특정 쿼리 연산자에 한도가 적용됩니다. |
예. 쿼리 연산자에 제한이 없음 | 아니요 |
| 전송 크기 제한 | 전송당 60GB(원격 리전의 각 하위 쿼리는 전송 1개를 생성함) | 제한 없음 | 전송당 60GB(원격 리전의 각 하위 쿼리는 전송 1개를 생성함) | 제한 없음 |
| 데이터 전송 압축 | 와이어 압축 | 열 형식 | 와이어 압축 | 와이어 압축 |
| 캐싱 | 지원되지 않음 | 구체화된 뷰가 있는 캐시 지원 테이블에서 지원됨 | 지원되지 않음 | 지원되지 않음 |
| 이그레스 가격 책정 | AWS 이그레스 및 대륙 간 비용 | AWS 이그레스 및 대륙 간 비용 | AWS 이그레스 및 대륙 간 비용 | AWS 이그레스 및 대륙 간 비용 |
| 데이터 전송의 컴퓨팅 사용량 | 소스 AWS 또는 Azure Blob Storage 리전의 슬롯을 사용합니다(예약 또는 주문형). | 사용되지 않음 | 소스 AWS 또는 Azure Blob Storage 리전의 슬롯을 사용합니다(예약 또는 주문형). | 사용되지 않음 |
| 필터링을 위한 사용량 계산 | 소스 AWS 또는 Azure Blob Storage 리전의 슬롯을 사용합니다(예약 또는 주문형). | 로컬 구체화된 뷰와 메타데이터를 계산하기 위해 소스 AWS 또는 Azure Blob Storage 리전의 슬롯(예약 또는 주문형)을 사용합니다. | 소스 AWS 또는 Azure Blob Storage 리전의 슬롯을 사용합니다(예약 또는 주문형). | 사용되지 않음 |
| 증분 전송 | 지원되지 않음 | 비집계 구체화된 뷰에서 지원됨 | 지원되지 않음 | 지원되지 않음 |
Amazon Simple Storage Service(Amazon S3) 또는 Azure Blob Storage에서 Google Cloud로 데이터를 전송하는 다음 대안을 고려해 볼 수도 있습니다.
- Storage Transfer Service: Google Cloud 와 Amazon Simple Storage Service(Amazon S3) 또는 Azure Blob Storage 간에 객체 저장소와 파일 저장소 간에 데이터를 전송합니다.
- BigQuery Data Transfer Service: 정해진 일정에 따라 관리되는 방식으로 BigQuery로 자동 데이터 전송을 설정합니다. 다양한 소스를 지원하며 데이터 이전에 적합합니다. BigQuery Data Transfer Service는 필터링을 지원하지 않습니다.
아키텍처
BigQuery 아키텍처는 스토리지에서 컴퓨팅을 분리하고 필요에 따라 대용량 워크로드를 처리하기 위해 BigQuery 수평 확장을 허용합니다. BigQuery Omni는 다른 클라우드에서 BigQuery 쿼리 엔진을 실행하여 이 아키텍처를 확장합니다. 그 결과 데이터를 BigQuery 스토리지로 물리적으로 이동할 필요가 없습니다. 처리 작업은 데이터가 이미 있는 위치에서 수행됩니다.
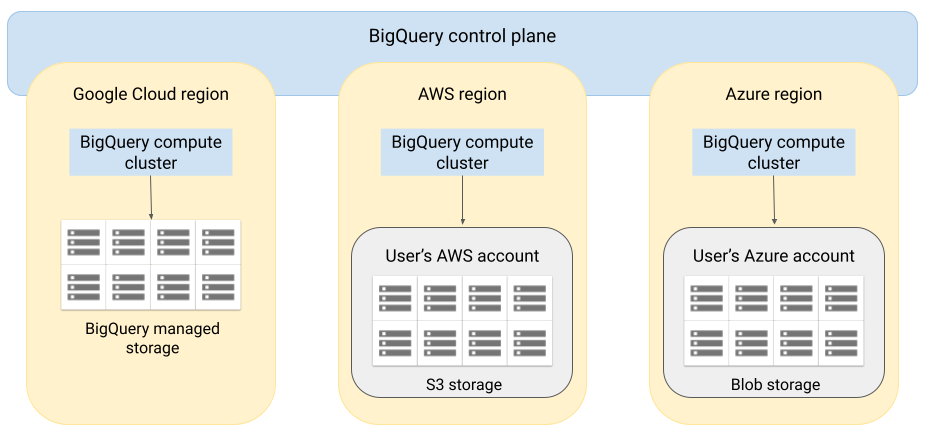
Google Cloud 콘솔에 표시하는 것과 같이 보안 연결을 통해 쿼리 결과를 Google Cloud 로 반환할 수 있습니다. 또는 결과를 Amazon S3 버킷 또는 Blob Storage에 직접 기록할 수 있습니다. 이 경우 쿼리 결과에 대한 클라우드 간 이동이 발생하지 않습니다.
BigQuery Omni는 표준 AWS IAM 역할 또는 Azure Active Directory 원칙을 사용하여 구독 데이터에 액세스합니다. BigQuery Omni에 읽기 또는 쓰기 액세스를 위임하고 언제든지 액세스 권한을 취소할 수 있습니다.
데이터 쿼리 시의 데이터 흐름
다음 이미지는 다음 쿼리에 대해 Google Cloud 와 AWS 또는 Azure 간에 데이터가 어떻게 이동하는지 설명합니다.
SELECT문CREATE EXTERNAL TABLE문

- BigQuery 컨트롤 플레인은Google Cloud 콘솔, bq 명령줄 도구, API 메서드, 클라이언트 라이브러리를 통해 쿼리 작업을 수신합니다.
- BigQuery 컨트롤 플레인이 처리를 위해 쿼리 작업을 AWS 또는 Azure의 BigQuery 데이터 영역으로 전송합니다.
- BigQuery 데이터 영역이 VPN 연결을 통해 컨트롤 플레인의 쿼리를 수신합니다.
- BigQuery 데이터 영역은 Amazon S3 버킷 또는 Blob Storage에서 테이블 데이터를 읽습니다.
- BigQuery 데이터 영역이 테이블 데이터에서 쿼리 작업을 실행합니다. 지정된 AWS 또는 Azure 리전에서 테이블 데이터 처리가 수행됩니다.
- 쿼리 결과가 VPN 연결을 통해 데이터 영역에서 컨트롤 플레인으로 전송됩니다
- BigQuery 컨트롤 플레인은 쿼리 작업에 대한 응답으로 표시할 쿼리 작업 결과를 수신합니다. 이 데이터는 최대 24시간 동안 저장됩니다.
- 쿼리 결과가 개발자에게 반환됩니다.
자세한 내용은 Amazon S3 데이터 및 Blob Storage 데이터 쿼리를 참조하세요.
데이터를 내보낼 때의 데이터 흐름
다음 이미지는 EXPORT DATA 문 중에 Google Cloud 와 AWS 또는 Azure 간에 데이터가 어떻게 이동하는지 설명합니다.

- BigQuery 컨트롤 플레인은 Google Cloud 콘솔, bq 명령줄 도구, API 메서드, 클라이언트 라이브러리를 통해 내보내기 쿼리 작업을 수신합니다. 쿼리에는 Amazon S3 버킷 또는 Blob Storage의 쿼리 결과에 대한 대상 경로가 포함됩니다.
- BigQuery 컨트롤 플레인이 처리를 위해 내보내기 쿼리 작업을 AWS 또는 Azure의 BigQuery 데이터 영역으로 전송합니다.
- BigQuery 데이터 영역은 VPN 연결을 통해 컨트롤 플레인으로부터 내보내기 쿼리를 수신합니다.
- BigQuery 데이터 영역은 Amazon S3 버킷 또는 Blob Storage에서 테이블 데이터를 읽습니다.
- BigQuery 데이터 영역이 테이블 데이터에서 쿼리 작업을 실행합니다. 지정된 AWS 또는 Azure 리전에서 테이블 데이터 처리가 수행됩니다.
- BigQuery는 쿼리 결과를 Amazon S3 버킷 또는 Blob Storage에 지정된 대상 경로에 기록합니다.
자세한 내용은 Amazon S3 및 Blob Storage로 쿼리 결과 내보내기를 참조하세요.
이점
성능. 데이터를 클라우드 간에 복사하지 않고 데이터가 있는 리전과 동일한 리전에서 쿼리가 실행되어 더욱 빠르게 유용한 정보를 얻을 수 있습니다.
비용. 데이터가 이동하지 않으므로 아웃바운드 데이터 전송 비용이 절약됩니다. Google에서 관리되는 클러스터에서 쿼리가 실행되기 때문에 BigQuery Omni 분석과 관련된 AWS 또는 Azure 계정에 추가 비용이 발생하지 않습니다. BigQuery 가격 책정 모델에 따라 쿼리 실행에 대해서만 비용이 청구됩니다.
보안 및 데이터 거버넌스. 자체 AWS 또는 Azure 구독으로 데이터를 관리합니다. 퍼블릭 클라우드 바깥으로 원시 데이터를 이동하거나 복사할 필요가 없습니다. 모든 계산은 데이터와 동일한 리전 내에서 실행되는 BigQuery 멀티 테넌트 서비스에서 발생합니다.
서버리스 아키텍처. 나머지 BigQuery와 마찬가지로 BigQuery Omni는 서버리스 제품입니다. Google은 BigQuery Omni를 실행하는 클러스터를 배포하고 관리합니다. 리소스를 프로비저닝하거나 클러스터를 관리할 필요가 없습니다.
관리 용이성. BigQuery Omni는 Google Cloud를 통해 통합된 관리 인터페이스를 제공합니다. BigQuery Omni는 기존 Google Cloud 계정 및 BigQuery 프로젝트를 사용할 수 있습니다. Google Cloud 콘솔에서 GoogleSQL 쿼리를 작성하여 AWS 또는 Azure에서 데이터를 쿼리하고 Google Cloud 콘솔에 표시된 결과를 확인할 수 있습니다.
교차 클라우드 전송. S3 버킷 및 Blob Storage에서 표준 BigQuery 테이블로 데이터를 로드할 수 있습니다. 자세한 내용은 Amazon S3 데이터 및 Blob Storage 데이터를 BigQuery로 전송을 참조하세요.
성능을 위한 메타데이터 캐싱
캐시된 메타데이터를 사용하여 Amazon S3 데이터를 참조하는 BigLake 테이블의 쿼리 성능을 향상시킵니다. 이 방법은 많은 파일로 작업하거나 데이터가 Apache Hive로 분할되는 경우에 특히 유용합니다.
BigQuery는 CMETA를 분산 메타데이터 시스템으로 사용하여 대규모 테이블을 효율적으로 처리합니다. CMETA는 시스템 테이블을 통해 액세스할 수 있는 열 및 블록 수준의 세분화된 메타데이터를 제공합니다. 이 시스템은 데이터 액세스 및 처리를 최적화하여 쿼리 성능을 개선하는 데 도움이 됩니다. 대용량 테이블에서 쿼리 성능을 더욱 가속화하기 위해 BigQuery는 메타데이터 캐시를 유지합니다. CMETA 새로고침 작업은 이 캐시를 최신 상태로 유지합니다.메타데이터에는 파일 이름, 파티셔닝 정보, 행 수와 같은 파일의 물리적 메타데이터가 포함됩니다. 테이블에서 메타데이터 캐싱을 사용 설정할지 여부를 선택할 수 있습니다. 파일 수가 더 많고 Apache Hive 파티션 필터가 포함된 쿼리는 메타데이터 캐싱의 이점을 극대화할 수 있습니다.
메타데이터 캐싱을 사용 설정하지 않으면 테이블의 쿼리에서 외부 데이터 소스를 읽어 객체 메타데이터를 가져와야 합니다. 이 데이터를 읽으면 쿼리 지연 시간이 늘어나므로 외부 데이터 소스에서 수백만 개의 파일을 나열하는 데 몇 분 정도 걸릴 수 있습니다. 메타데이터 캐싱을 사용 설정하면 쿼리가 외부 데이터 소스에서 파일을 나열하지 않고 파티션과 파일 프루닝을 더 빠르게 수행할 수 있습니다.
메타데이터 캐싱은 Cloud Storage 객체 버전 관리와도 통합됩니다. 캐시가 채워지거나 새로고침되면 당시의 Cloud Storage 객체의 라이브 버전을 기반으로 메타데이터가 캡처됩니다. 따라서 메타데이터 캐싱이 사용 설정된 쿼리는 Cloud Storage에서 최신 버전이 라이브가 되더라도 캐시된 특정 객체 버전에 해당하는 데이터를 읽습니다. Cloud Storage에서 이후에 업데이트된 객체 버전의 데이터에 액세스하려면 메타데이터 캐시를 새로고침해야 합니다.
이 기능을 제어하는 두 가지 속성은 다음과 같습니다.
- 최대 비활성은 쿼리에서 캐시된 메타데이터를 사용하는 시점을 지정합니다.
- 메타데이터 캐시 모드는 메타데이터가 수집되는 방식을 지정합니다.
메타데이터 캐싱을 사용 설정했으면 테이블 작업에 허용되는 메타데이터 비활성 간격을 최대한으로 지정합니다. 예를 들어 1시간 간격을 지정하면 이전 한 시간 내에 새로고침된 경우 테이블 작업에 캐시된 메타데이터가 사용됩니다. 캐시된 메타데이터가 이보다 오래된 경우 작업은 대신 Amazon S3에서 메타데이터를 검색하도록 되돌아갑니다. 비활성 간격은 30분부터 7일까지로 지정할 수 있습니다.
BigLake 또는 객체 테이블에 대해 메타데이터 캐싱을 사용 설정하면 BigQuery에서 메타데이터 생성 새로고침 작업을 트리거합니다. 캐시를 자동 또는 수동으로 새로고침하도록 선택할 수 있습니다.
- 자동 새로고침의 경우 일반적으로 30분에서 60분 사이로 시스템에서 정의된 간격으로 캐시가 새로고침됩니다. Amazon S3의 파일이 무작위 간격으로 추가, 삭제, 수정될 경우에는 캐시를 자동으로 새로고침하는 것이 좋습니다. 추출-변환-로드 작업이 끝날 때 새로고침을 트리거할 때와 같이 새로고침 시간을 제어해야 할 경우에는 수동 새로고침을 사용합니다.
수동 새로고침의 경우
BQ.REFRESH_EXTERNAL_METADATA_CACHE시스템 프로시저를 실행하여 요구사항을 충족하는 일정에 따라 메타데이터 캐시를 새로고침합니다. Amazon S3의 파일이 파이프라인 출력과 같이 알려진 간격으로 추가, 삭제, 수정될 경우에는 캐시를 수동으로 새로고침하는 것이 좋습니다.여러 번의 수동 새로고침을 동시에 수행하면 하나만 성공합니다.
메타데이터 캐시는 새로고침되지 않을 경우 7일 후 만료됩니다.
수동 및 자동 캐시 새로고침 모두 INTERACTIVE 쿼리 우선순위로 실행됩니다.
BACKGROUND 예약 사용
자동 새로고침을 사용하는 경우 메타데이터 캐시 새로고침 작업을 실행하는 프로젝트에 대해 예약을 만든 후 BACKGROUND 작업 유형으로 할당을 만드는 것이 좋습니다. BACKGROUND 예약을 사용하면 새로고침 작업이 전용 리소스 풀을 사용하므로 새로고침 작업이 사용자 쿼리와 경쟁하지 않으며 사용할 수 있는 리소스가 충분하지 않은 경우 작업이 실패할 가능성을 줄여줍니다.
공유 슬롯 풀을 사용해도 추가 비용이 들지 않지만 대신 BACKGROUND 예약을 사용하면 전용 리소스 풀을 할당하여 더 일관된 성능을 제공하고 BigQuery에서 새로고침 작업의 안정성과 전반적인 쿼리 효율성을 개선할 수 있습니다.
설정하기 전 비활성 간격 및 메타데이터 캐싱 모드 값이 상호작용하는 방식을 고려해야 합니다. 다음 예를 고려하세요.
- 테이블에 대해 메타데이터 캐시를 수동으로 새로고침할 때 비활성 간격을 2일로 설정하면 테이블 작업에 캐시된 메타데이터가 사용되도록 하려면
BQ.REFRESH_EXTERNAL_METADATA_CACHE시스템 프로시저를 2일 이내 간격으로 실행해야 합니다. - 테이블의 메타데이터 캐시를 자동으로 새로고침하고 비활성 간격을 30분으로 설정한 경우 메타데이터 캐시 새로고침이 일반적인 30분~60분 기간보다 길어지면 테이블에 대한 일부 작업이 Amazon S3에서 읽을 수 있습니다.
메타데이터 새로고침 작업에 대한 정보를 보려면 다음 예시에 표시된 것처럼 INFORMATION_SCHEMA.JOBS 뷰를 쿼리합니다.
SELECT * FROM `region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT` WHERE job_id LIKE '%metadata_cache_refresh%' AND creation_time > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 6 HOUR) ORDER BY start_time DESC LIMIT 10;
자세한 내용은 메타데이터 캐싱을 참조하세요.
구체화된 뷰가 있는 캐시 지원 테이블
Amazon S3에 저장된 정형 데이터를 쿼리할 때 Amazon Simple Storage Service(Amazon S3) 메타데이터 캐시 지원 테이블을 통해 구체화된 뷰를 사용하여 성능과 효율성을 개선할 수 있습니다. 이러한 구체화된 뷰는 자동 새로고침 및 스마트 조정의 이점을 포함하여 BigQuery 관리형 스토리지 테이블을 통한 구체화된 뷰처럼 작동합니다.
조인에 지원되는 BigQuery 리전에서 구체화된 뷰의 Amazon S3 데이터를 사용할 수 있도록 하려면 구체화된 뷰의 복제본을 만듭니다. 승인된 구체화된 뷰를 통해서만 구체화된 뷰 복제본을 만들 수 있습니다.
제한사항
BigLake 테이블 제한사항 외에도 Amazon S3 및 Blob Storage 데이터를 기반으로 하는 BigLake 테이블이 포함된 BigQuery Omni에는 다음 제한사항이 적용됩니다.
- BigQuery Omni 리전에서의 데이터 작업은 Standard 및 Enterprise Plus 버전에서 지원되지 않습니다. 버전에 대한 자세한 내용은 BigQuery 버전 소개를 참조하세요.
- Amazon S3 및 Blob Storage 데이터를 사용하는 BigLake 테이블에는
OBJECT_PRIVILEGES,STREAMING_TIMELINE_BY_*,TABLE_SNAPSHOTS,TABLE_STORAGE,TABLE_CONSTRAINTS,KEY_COLUMN_USAGE,CONSTRAINT_COLUMN_USAGE,PARTITIONSINFORMATION_SCHEMA뷰를 사용할 수 없습니다. - Blob 스토리지에는 구체화된 뷰가 지원되지 않습니다.
- JavaScript UDF는 지원되지 않습니다.
다음 SQL 문이 지원되지 않습니다.
- BigQuery ML 문.
- BigQuery에서 관리되는 데이터를 필요로 하는 데이터 정의 언어(DDL) 문. 예를 들어
CREATE EXTERNAL TABLE,CREATE SCHEMA,CREATE RESERVATION이 지원되지만CREATE TABLE이 지원되지 않습니다. - DML(Data manipulation language) 문.
대상 임시 테이블 쿼리 및 읽기에는 다음 제한사항이 적용됩니다.
SELECT문을 포함하는 대상 임시 테이블 쿼리는 지원되지 않습니다.
예약된 쿼리는 API 또는 CLI 메서드를 통해서만 지원됩니다. 쿼리에는 대상 테이블 옵션이 사용 중지되어 있습니다.
EXPORT DATA쿼리만 허용됩니다.BigQuery Storage API를 BigQuery Omni 리전에서 사용할 수 없습니다.
쿼리에서
ORDER BY절을 사용하고 결과 크기가 256MB보다 크면 쿼리가 실패합니다. 이 문제를 해결하려면 결과 크기를 줄이거나 쿼리에서ORDER BY절을 삭제합니다. BigQuery Omni 할당량에 대한 자세한 내용은 할당량 및 한도를 참조하세요.데이터 세트 및 외부 테이블과 함께 고객 관리 암호화 키(CMEK)를 사용할 수 없습니다.
가격 책정
BigQuery Omni의 가격 책정 및 기간 한정 혜택에 대해서는 BigQuery Omni 가격 책정을 참조하세요.
할당량 및 한도
BigQuery Omni 할당량에 대한 자세한 내용은 할당량 및 한도를 참조하세요.
쿼리 결과가 20GiB보다 크면 결과를 Amazon S3 또는 Blob Storage로 내보내는 것이 좋습니다. BigQuery Connection API의 할당량에 대한 자세한 내용은 BigQuery Connection API를 참조하세요.
위치
BigQuery Omni는 쿼리 중인 테이블이 포함된 데이터 세트와 동일한 위치에 있는 쿼리를 처리합니다. 데이터 세트를 만든 후에는 이 위치를 변경할 수 없습니다. 데이터는 자체 AWS 또는 Azure 계정 내에 있습니다. BigQuery Omni 리전은 Enterprise 버전 예약과 주문형 컴퓨팅(분석) 가격 책정을 지원합니다. 버전에 대한 자세한 내용은 BigQuery 버전 소개를 참조하세요.
| 리전 설명 | 리전 이름 | 같은 위치에 배치된 BigQuery 리전 | |
|---|---|---|---|
| AWS | |||
| AWS - 미국 동부(북 버지니아) | aws-us-east-1 |
us-east4 |
|
| AWS 미국 서부(오리건) | aws-us-west-2 |
us-west1 |
|
| AWS - 아시아 태평양(서울) | aws-ap-northeast-2 |
asia-northeast3 |
|
| AWS - 아시아 태평양(시드니) | aws-ap-southeast-2 |
australia-southeast1 |
|
| AWS - 유럽(아일랜드) | aws-eu-west-1 |
europe-west1 |
|
| AWS - 유럽(프랑크푸르트) | aws-eu-central-1 |
europe-west3 |
|
| Azure | |||
| Azure - 미국 동부 2 | azure-eastus2 |
us-east4 |
|
다음 단계
- Amazon S3 및 Blob Storage에 연결하는 방법 알아보기
- Amazon S3 및 Blob Storage BigLake 테이블을 만드는 방법 알아보기
- Amazon S3 및 Blob Storage BigLake 테이블을 쿼리하는 방법 알아보기
- 교차 클라우드 조인을 사용하여 Google Cloud 테이블과 Amazon S3 및 Blob Storage BigLake 테이블을 조인하는 방법 알아보기
- Amazon S3 및 Blob Storage로 쿼리 결과를 내보내는 방법 알아보기
- Amazon S3 및 Blob Storage에서 BigQuery로 데이터를 전송하는 방법 알아보기
- VPC 서비스 제어 경계 설정 알아보기
- 위치 지정 방법 알아보기