在資料表結構定義中指定巢狀與重複的資料欄
本頁說明如何在 BigQuery 中定義具有巢狀和重複欄的資料表結構定義。如要瞭解資料表結構定義的總覽,請參閱指定結構定義。
定義巢狀與重複的資料欄
如要建立含有巢狀資料的資料欄,請在結構定義中將資料欄的資料類型設為 RECORD。在 GoogleSQL 中,RECORD 可以做為 STRUCT 類型存取。STRUCT 是已排序欄位的容器。
如要建立含有重複資料的資料欄,請在結構定義中將資料欄的模式設為 REPEATED。在 GoogleSQL 中,重複欄位可以做為 ARRAY 類型存取。
RECORD 資料欄可以有 REPEATED 模式,以 STRUCT 型別的陣列表示。此外,記錄中的欄位可以重複,這會以包含 ARRAY 的 STRUCT 表示。陣列無法直接包含另一個陣列。詳情請參閱「宣告 ARRAY 型別」。
限制
巢狀與重複結構定義有下列限制:
- 結構定義無法包含超過 15 層的巢狀
RECORD類型。 - 類型的資料欄可以包含巢狀
RECORD類型,也稱為子記錄。RECORD巢狀結構深度上限為 15 層。此限制與RECORD是否為純量或陣列形式 (重複) 無關。
RECORD 類型與 UNION、INTERSECT、EXCEPT DISTINCT 和 SELECT DISTINCT 不相容。
結構定義範例
以下範例顯示巢狀與重複資料範例。此資料表含有人員的相關資訊。組成欄位如下:
idfirst_namelast_namedob(出生日期)addresses(巢狀且重複的欄位)addresses.status(目前或之前)addresses.addressaddresses.cityaddresses.stateaddresses.zipaddresses.numberOfYears(在此地址居住的年數)
JSON 資料檔案會與以下內容類似。請注意,地址資料欄含有值陣列 (以 [ ] 表示)。陣列中的多個地址是重複資料。每個地址中的多重欄位為巢狀資料。
{"id":"1","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]}
{"id":"2","first_name":"Jane","last_name":"Doe","dob":"1980-10-16","addresses":[{"status":"current","address":"789 Any Avenue","city":"New York","state":"NY","zip":"33333","numberOfYears":"2"},{"status":"previous","address":"321 Main Street","city":"Hoboken","state":"NJ","zip":"44444","numberOfYears":"3"}]}
此資料表的結構定義如下所示:
[ { "name": "id", "type": "STRING", "mode": "NULLABLE" }, { "name": "first_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "last_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "dob", "type": "DATE", "mode": "NULLABLE" }, { "name": "addresses", "type": "RECORD", "mode": "REPEATED", "fields": [ { "name": "status", "type": "STRING", "mode": "NULLABLE" }, { "name": "address", "type": "STRING", "mode": "NULLABLE" }, { "name": "city", "type": "STRING", "mode": "NULLABLE" }, { "name": "state", "type": "STRING", "mode": "NULLABLE" }, { "name": "zip", "type": "STRING", "mode": "NULLABLE" }, { "name": "numberOfYears", "type": "STRING", "mode": "NULLABLE" } ] } ]
在範例中指定巢狀與重複的資料欄
如要使用先前的巢狀和重複資料欄建立新資料表,請選取下列其中一個選項:
主控台
指定巢狀與重複的 addresses 資料欄:
在 Google Cloud 控制台開啟「BigQuery」頁面。
在「Explorer」面板中展開專案並選取資料集。
在詳細資料面板中,按一下 「建立資料表」。
在「建立資料表」頁面中,指定下列詳細資料:
- 在「Source」(來源) 的「Create table from」(建立資料表來源) 欄位中,選取「Empty table」(空白資料表)。
在「目的地」部分,指定下列欄位:
- 在「Dataset」(資料集) 部分,選取要建立資料表的資料集。
- 在「Table」(資料表) 中,輸入要建立的資料表名稱。
針對「Schema」(結構定義),請按一下 「Add field」(新增欄位),然後輸入下列資料表結構定義:
- 在「欄位名稱」部分,輸入「
addresses」。 - 在「Type」(類型) 部分選取「RECORD」(記錄)。
- 在「Mode」(模式) 部分,選擇「REPEATED」(重複)。
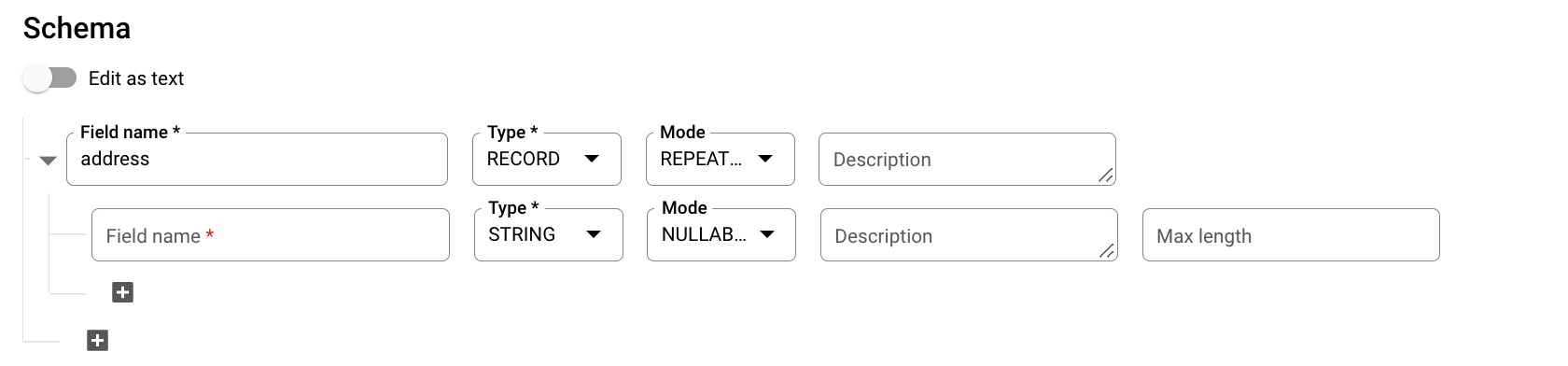
為巢狀欄位指定下列欄位:
- 在「Field name」(欄位名稱) 欄位中輸入
status。 - 在「Type」(類型) 部分,選擇「STRING」。
- 在「Mode」部分,將值保持為「NULLABLE」。
按一下「新增欄位」,新增下列欄位:
欄位名稱 類型 模式 addressSTRINGNULLABLEcitySTRINGNULLABLEstateSTRINGNULLABLEzipSTRINGNULLABLEnumberOfYearsSTRINGNULLABLE
您也可以按一下 [Edit as Text] (以文字形式編輯),然後以 JSON 陣列形式指定結構定義。
- 在「Field name」(欄位名稱) 欄位中輸入
- 在「欄位名稱」部分,輸入「
SQL
使用 CREATE TABLE 陳述式。使用 column 選項指定結構定義:
前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中輸入下列陳述式:
CREATE TABLE IF NOT EXISTS mydataset.mytable ( id STRING, first_name STRING, last_name STRING, dob DATE, addresses ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> ) OPTIONS ( description = 'Example name and addresses table');
按一下「執行」。
如要進一步瞭解如何執行查詢,請參閱「執行互動式查詢」。
bq
如要在 JSON 結構定義檔中指定巢狀且重複的 addresses 資料欄,請使用文字編輯器建立新檔案。貼上上方顯示的範例結構定義。
建立 JSON 結構定義檔後,您可以透過 bq 指令列工具提供檔案。詳情請參閱「使用 JSON 結構定義檔」。
Go
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Go 設定說明進行操作。詳情請參閱 BigQuery Go API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Java
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Java 設定說明進行操作。詳情請參閱 BigQuery Java API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Node.js
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Node.js 設定說明進行操作。詳情請參閱 BigQuery Node.js API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Python
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Python 設定說明進行操作。詳情請參閱 BigQuery Python API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
在範例中插入巢狀資料欄中的資料
使用下列查詢,將巢狀資料記錄插入含有 RECORD 資料型別資料欄的資料表。
範例 1
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22", ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> [("current","123 First Avenue","Seattle","WA","11111","1")])
示例 2
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22",[("current","123 First Avenue","Seattle","WA","11111","1")])
查詢巢狀與重複的資料欄
如要選取特定位置的 ARRAY 值,請使用陣列下標運算子。如要存取 STRUCT 中的元素,請使用點運算子。以下範例會選取 addresses 欄位中列出的名字、姓氏和第一個地址:
SELECT first_name, last_name, addresses[offset(0)].address FROM mydataset.mytable;
結果如下:
+------------+-----------+------------------+ | first_name | last_name | address | +------------+-----------+------------------+ | John | Doe | 123 First Avenue | | Jane | Doe | 789 Any Avenue | +------------+-----------+------------------+
如要擷取 ARRAY 的所有元素,請搭配 CROSS JOIN 使用 UNNEST 運算子。以下範例會選取不在紐約的所有地址的名字、姓氏、地址和州別:
SELECT first_name, last_name, a.address, a.state FROM mydataset.mytable CROSS JOIN UNNEST(addresses) AS a WHERE a.state != 'NY';
結果如下:
+------------+-----------+------------------+-------+ | first_name | last_name | address | state | +------------+-----------+------------------+-------+ | John | Doe | 123 First Avenue | WA | | John | Doe | 456 Main Street | OR | | Jane | Doe | 321 Main Street | NJ | +------------+-----------+------------------+-------+
修改巢狀與重複的資料欄
當您在資料表結構定義中加入一個巢狀資料欄或是加入一個巢狀且重複的資料欄時,您仍可以修改資料欄,就如同其他類型的資料欄一般。BigQuery 針對多種結構定義變更提供原生支援,例如在一筆記錄中新增一個巢狀欄位或是放寬一個巢狀欄位的模式。詳情請參閱修改資料表結構定義一文。
使用巢狀與重複資料欄的時機
BigQuery 在資料去標準化時執行效能最佳。其中不保留星狀或雪花狀結構定義等關聯結構定義,改為將資料去標準化並善用巢狀與重複的資料欄。巢狀與重複的資料欄可保留關係,但不會因保留關係 (標準化) 結構定義而影響效能。
舉例來說,用來追蹤圖書館書籍的關聯資料庫會以不同的資料表儲存所有作者資訊。並使用 author_id 之類的金鑰來將書籍與作者連結。
在 BigQuery 中,您可以保留書籍與作者之間的關係,而不需要建立個別的作者資料表。但您需建立一個作者資料欄,在其中建立巢狀欄位,如作者名字、姓氏、生日等等。如果一本書有多位作者,您可以重複建立巢狀作者資料欄。
假設您有下列資料表 mydataset.books:
+------------------+------------+-----------+ | title | author_ids | num_pages | +------------------+------------+-----------+ | Example Book One | [123, 789] | 487 | | Example Book Two | [456] | 89 | +------------------+------------+-----------+
您也可以使用下表 mydataset.authors,查看每個作者 ID 的完整資訊:
+-----------+-------------+---------------+ | author_id | author_name | date_of_birth | +-----------+-------------+---------------+ | 123 | Alex | 01-01-1960 | | 456 | Rosario | 01-01-1970 | | 789 | Kim | 01-01-1980 | +-----------+-------------+---------------+
如果資料表很大,定期聯結可能會耗用大量資源。 視情況而定,建立包含所有資訊的單一資料表可能會有幫助:
CREATE TABLE mydataset.denormalized_books( title STRING, authors ARRAY<STRUCT<id INT64, name STRING, date_of_birth STRING>>, num_pages INT64) AS ( SELECT title, ARRAY_AGG(STRUCT(author_id, author_name, date_of_birth)) AS authors, ANY_VALUE(num_pages) FROM mydataset.books, UNNEST(author_ids) id JOIN mydataset.authors ON id = author_id GROUP BY title );
產生的資料表如下所示:
+------------------+-------------------------------+-----------+
| title | authors | num_pages |
+------------------+-------------------------------+-----------+
| Example Book One | [{123, Alex, 01-01-1960}, | 487 |
| | {789, Kim, 01-01-1980}] | |
| Example Book Two | [{456, Rosario, 01-01-1970}] | 89 |
+------------------+-------------------------------+-----------+
BigQuery 支援從支援物件型結構定義的來源格式載入巢狀與重複的資料,如 JSON 檔案、Avro 檔案、Firestore 匯出檔案和 Datastore 匯出檔案。
在表格中移除重複記錄
下列查詢使用 row_number() 函式,找出範例中 last_name 和 first_name 值相同的重複記錄,並依 dob 排序:
CREATE OR REPLACE TABLE mydataset.mytable AS ( SELECT * except(row_num) FROM ( SELECT *, row_number() over (partition by last_name, first_name order by dob) row_num FROM mydataset.mytable) temp_table WHERE row_num=1 )
表格安全性
如要控管 BigQuery 資料表的存取權,請參閱「使用 IAM 控管資源存取權」。
後續步驟
- 如要插入及更新含有巢狀和重複資料欄的資料列,請參閱資料操縱語言語法。