Eseguire la migrazione di schema e dati da Teradata
La combinazione di BigQuery Data Transfer Service e di un agente speciale di migrazione ti consente di copiare i dati da un'istanza di data warehouse on-premise Teradata a BigQuery. Questo documento descrive la procedura passo passo per eseguire la migrazione dei dati da Teradata utilizzando BigQuery Data Transfer Service.
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery, BigQuery Data Transfer Service, Cloud Storage, and Pub/Sub APIs.
-
Create a service account:
-
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the following roles to the service account: roles/bigquery.user, roles/storage.objectAdmin, roles/iam.serviceAccountTokenCreator.
To grant a role, find the Select a role list, then select the role.
To grant additional roles, click Add another role and add each additional role.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery, BigQuery Data Transfer Service, Cloud Storage, and Pub/Sub APIs.
-
Create a service account:
-
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the following roles to the service account: roles/bigquery.user, roles/storage.objectAdmin, roles/iam.serviceAccountTokenCreator.
To grant a role, find the Select a role list, then select the role.
To grant additional roles, click Add another role and add each additional role.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
- Visualizzatore log (
roles/logging.viewer) - Amministratore Storage (
roles/storage.admin) o un ruolo personalizzato che concede le seguenti autorizzazioni:storage.objects.createstorage.objects.getstorage.objects.list
- Amministratore BigQuery (
roles/bigquery.admin) o un ruolo personalizzato che concede le seguenti autorizzazioni:bigquery.datasets.createbigquery.jobs.createbigquery.jobs.getbigquery.jobs.listAllbigquery.transfers.getbigquery.transfers.update
- L'agente di migrazione utilizza una connessione JDBC con l'istanza Teradata e le API Google Cloud . Assicurati che l'accesso alla rete non sia bloccato da un firewall.
- Assicurati che sia installato Java Runtime Environment 8 o versioni successive.
- Assicurati di avere spazio di archiviazione sufficiente per il metodo di estrazione che hai scelto, come descritto in Metodo di estrazione.
- Se hai deciso di utilizzare l'estrazione Teradata Parallel Transporter (TPT),
assicurati che sia installata l'utilità
tbuild. Per saperne di più sulla scelta di un metodo di estrazione, consulta Metodo di estrazione. Assicurati di disporre del nome utente e della password di un utente Teradata con accesso in lettura alle tabelle di sistema e alle tabelle di cui viene eseguita la migrazione.
Assicurati di conoscere il nome host e il numero di porta per connetterti all'istanza Teradata.
Nella console Google Cloud , vai alla pagina BigQuery.
Fai clic su Trasferimenti di dati.
Fai clic su Crea trasferimento.
Nella sezione Tipo di origine, segui questi passaggi:
- Scegli Migrazione: Teradata.
- Per Nome configurazione di trasferimento, inserisci un nome visualizzato per il trasferimento, ad esempio
My Migration. Il nome visualizzato può essere qualsiasi valore che ti consenta di identificare facilmente il trasferimento se devi modificarlo in un secondo momento. - (Facoltativo) Per Opzioni di pianificazione, puoi lasciare il valore predefinito di Giornaliero (in base all'ora di creazione) o scegliere un'altra ora se vuoi un trasferimento incrementale ricorrente. In caso contrario, scegli On demand per un trasferimento una tantum.
Per Impostazioni destinazione, scegli il set di dati appropriato.
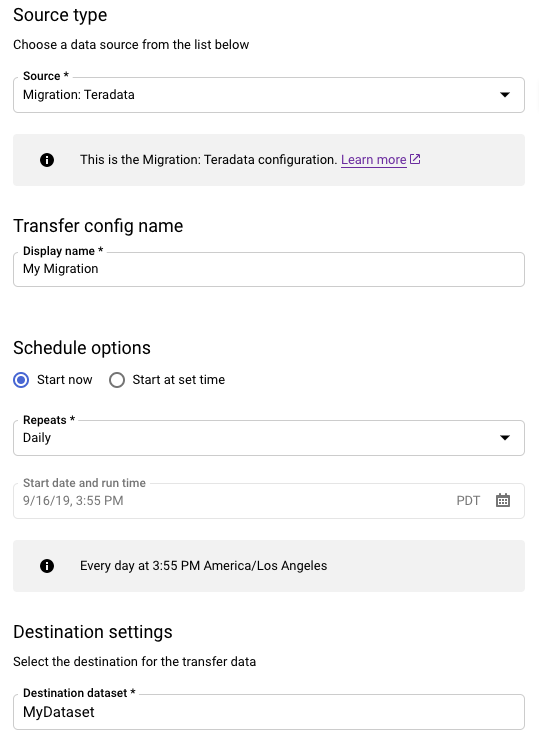
Nella sezione Dettagli origine dati, continua con i dettagli specifici per il trasferimento Teradata.
- Per Tipo di database, scegli Teradata.
- Per Bucket Cloud Storage, cerca il nome del bucket Cloud Storage per la gestione temporanea dei dati di migrazione. Non digitare il prefisso
gs://: inserisci solo il nome del bucket. - In Nome database, inserisci il nome del database di origine in Teradata.
Per Pattern nome tabella, inserisci un pattern per la corrispondenza dei nomi delle tabelle nel database di origine. Puoi utilizzare le espressioni regolari per specificare il pattern. Ad esempio:
sales|expensescorrisponde alle tabelle denominatesaleseexpenses..*corrisponde a tutte le tabelle.
In Email del service account, inserisci l'indirizzo email associato alle credenziali del account di servizio utilizzate da un agente di migrazione.
(Facoltativo) Per Percorso file schema, inserisci il percorso e il nome di un file schema personalizzato. Per saperne di più sulla creazione di un file schema personalizzato, vedi File schema personalizzato. Puoi lasciare vuoto questo campo per consentire a BigQuery di rilevare automaticamente lo schema della tabella di origine.
(Facoltativo) Per Directory radice di output della traduzione, inserisci il percorso e il nome file del file di mapping dello schema fornito dal motore di traduzione BigQuery. Per ulteriori informazioni sulla generazione di un file di mapping dello schema, vedi Utilizzo dell'output del motore di traduzione per lo schema (anteprima). Puoi lasciare questo campo vuoto per consentire a BigQuery di rilevare automaticamente lo schema della tabella di origine.
Nel menu Service account, seleziona un service account tra quelli associati al tuo progettoGoogle Cloud . Puoi associare un account di servizio al trasferimento anziché utilizzare le tue credenziali utente. Per ulteriori informazioni sull'utilizzo dei service account con i trasferimenti di dati, consulta Utilizza i service account.
- Se hai eseguito l'accesso con un'identità federata, è necessario un account di servizio per creare un trasferimento. Se hai eseguito l'accesso con un Account Google, il service account per il trasferimento è facoltativo.
- Il account di servizio deve disporre delle autorizzazioni richieste.
(Facoltativo) Nella sezione Opzioni di notifica, segui questi passaggi:
- Fai clic sul pulsante di attivazione/disattivazione Notifiche via email se vuoi che l'amministratore del trasferimento riceva una notifica via email quando l'esecuzione di un trasferimento non riesce.
- Fai clic sul pulsante di attivazione/disattivazione Notifiche Pub/Sub per configurare le notifiche di esecuzione di Pub/Sub per il trasferimento. In Seleziona un argomento Pub/Sub, scegli il nome dell'argomento o fai clic su Crea un argomento.
Fai clic su Salva.
Nella pagina Dettagli trasferimento, fai clic sulla scheda Configurazione.
Prendi nota del nome della risorsa per questo trasferimento perché ti servirà per eseguire l'agente di migrazione.
--data_source--display_name--target_dataset--params- project ID è l'ID progetto. Se
--project_idnon viene fornito per specificare un progetto particolare, viene utilizzato il progetto predefinito. - dataset è il set di dati di destinazione (
--target_dataset) per la configurazione del trasferimento. - name è il nome visualizzato (
--display_name) per la configurazione del trasferimento. Il nome visualizzato del trasferimento può essere qualsiasi valore che ti consenta di identificare il trasferimento se devi modificarlo in un secondo momento. - service_account è il nome del account di servizio utilizzato per
autenticare il trasferimento. Il account di servizio deve appartenere allo stesso
project_idutilizzato per creare il trasferimento e deve disporre di tutte le autorizzazioni richieste elencate. - parameters contiene i parametri (
--params) per la configurazione di trasferimento creata in formato JSON. Ad esempio:--params='{"param":"param_value"}'.- Per le migrazioni da Teradata, utilizza i seguenti parametri:
bucketè il bucket Cloud Storage che fungerà da area di staging durante la migrazione.database_typeè Teradata.agent_service_accountè l'indirizzo email associato al account di servizio che hai creato.database_nameè il nome del database di origine in Teradata.table_name_patternsè un pattern o più pattern per la corrispondenza dei nomi delle tabelle nel database di origine. Puoi utilizzare le espressioni regolari per specificare il pattern. Il pattern deve seguire la sintassi delle espressioni regolari Java. Ad esempio:sales|expensescorrisponde alle tabelle denominatesaleseexpenses..*corrisponde a tutte le tabelle.
- Per le migrazioni da Teradata, utilizza i seguenti parametri:
- data_source è l'origine dati (
--data_source):on_premises. Apri una nuova sessione. Nella riga di comando, esegui il comando di inizializzazione, che segue questo formato:
java -cp \ OS-specific-separated-paths-to-jars (JDBC and agent) \ com.google.cloud.bigquery.dms.Agent \ --initialize
L'esempio seguente mostra il comando di inizializzazione quando il driver JDBC e i file JAR dell'agente di migrazione si trovano in una directory
migrationlocale:Unix, Linux, Mac OS
java -cp \ /usr/local/migration/terajdbc4.jar:/usr/local/migration/mirroring-agent.jar \ com.google.cloud.bigquery.dms.Agent \ --initialize
Windows
Copia tutti i file nella cartella
C:\migration(o modifica i percorsi nel comando), poi esegui:java -cp C:\migration\terajdbc4.jar;C:\migration\mirroring-agent.jar com.google.cloud.bigquery.dms.Agent --initialize
Quando richiesto, configura le seguenti opzioni:
- Scegli se salvare il modello Teradata Parallel Transporter (TPT) su disco. Se prevedi di utilizzare il metodo di estrazione TPT, puoi modificare il modello salvato con i parametri adatti alla tua istanza Teradata.
- Digita il percorso di una directory locale che il job di trasferimento può utilizzare per l'estrazione dei file. Assicurati di avere lo spazio di archiviazione minimo consigliato come descritto in Metodo di estrazione.
- Digita il nome host del database.
- Digita la porta del database.
- Scegli se utilizzare Teradata Parallel Transporter (TPT) come metodo di estrazione.
- (Facoltativo) Digita il percorso di un file delle credenziali del database.
Scegli se specificare un nome di configurazione di BigQuery Data Transfer Service.
Se stai inizializzando l'agente di migrazione per un trasferimento che hai già configurato, procedi nel seguente modo:
- Digita il nome della risorsa del trasferimento. Puoi trovare questa informazione nella scheda Configurazione della pagina Dettagli trasferimento per il trasferimento.
- Quando richiesto, digita un percorso e un nome file per il file di configurazione dell'agente di migrazione che verrà creato. Fai riferimento a questo file quando esegui l'agente di migrazione per avviare il trasferimento.
- Ignora i passaggi rimanenti.
Se utilizzi l'agente di migrazione per configurare un trasferimento, premi Invio per passare al prompt successivo.
Digita l' Google Cloud ID progetto.
Digita il nome del database di origine in Teradata.
Digita un pattern per la corrispondenza dei nomi delle tabelle nel database di origine. Puoi utilizzare le espressioni regolari per specificare il pattern. Ad esempio:
sales|expensescorrisponde alle tabelle denominatesaleseexpenses..*corrisponde a tutte le tabelle.
(Facoltativo) Digita il percorso di un file di schema JSON locale. Questa opzione è consigliata vivamente per i trasferimenti ricorrenti.
Se non utilizzi un file schema o se vuoi che l'agente di migrazione ne crei uno per te, premi Invio per passare al prompt successivo.
Scegli se creare un nuovo file schema.
Se vuoi creare un file dello schema:
- Digita
yes - Digita il nome utente di un utente Teradata che ha accesso in lettura alle tabelle di sistema e alle tabelle di cui vuoi eseguire la migrazione.
Digita la password per l'utente.
L'agente di migrazione crea il file di schema e ne restituisce la posizione.
Modifica il file dello schema per contrassegnare le colonne di partizionamento, clustering, chiavi primarie e monitoraggio delle modifiche e verifica di voler utilizzare questo schema per la configurazione del trasferimento. Consulta File dello schema personalizzato per suggerimenti.
Premi
Enterper passare al prompt successivo.
Se non vuoi creare un file di schema, digita
no.- Digita
Digita il nome del bucket Cloud Storage di destinazione per i dati di migrazione di gestione temporanea prima del caricamento in BigQuery. Se l'agente di migrazione ha creato un file di schema personalizzato, questo viene caricato anche in questo bucket.
Digita il nome del set di dati di destinazione in BigQuery.
Digita un nome visualizzato per la configurazione del trasferimento.
Digita un percorso e un nome file per il file di configurazione dell'agente di migrazione che verrà creato.
Dopo aver inserito tutti i parametri richiesti, l'agente di migrazione crea un file di configurazione e lo restituisce al percorso locale specificato. Consulta la sezione successiva per un'analisi più approfondita del file di configurazione.
transfer-configuration: informazioni su questa configurazione di trasferimento in BigQuery.teradata-config: Informazioni specifiche per questa estrazione di Teradata:connection: Informazioni sul nome host e sulla portalocal-processing-space: la cartella di estrazione in cui l'agente estrarrà i dati delle tabelle prima di caricarli in Cloud Storage.database-credentials-file-path: (facoltativo) il percorso di un file che contiene le credenziali per la connessione automatica al database Teradata. Il file deve contenere due righe per le credenziali. Puoi utilizzare un nome utente/password, come mostrato nell'esempio seguente:username=abc password=123
username=abc secret_resource_id=projects/my-project/secrets/my-secret-name/versions/1
max-local-storage: la quantità massima di spazio di archiviazione locale da utilizzare per l'estrazione nella directory di staging specificata. Il valore predefinito è50GB. Il formato supportato è:numberKB|MB|GB|TB.In tutte le modalità di estrazione, i file vengono eliminati dalla directory di staging locale dopo essere stati caricati in Cloud Storage.
use-tpt: indica all'agente di migrazione di utilizzare Teradata Parallel Transporter (TPT) come metodo di estrazione.Per ogni tabella, l'agente di migrazione genera uno script TPT, avvia un processo
tbuilde attende il completamento. Una volta completato il processotbuild, l'agente elenca e carica i file estratti in Cloud Storage, quindi elimina lo script TPT. Per ulteriori informazioni, vedi Metodo di estrazione.transfer-views: indica all'agente di migrazione di trasferire anche i dati dalle visualizzazioni. Utilizza questa opzione solo quando è necessaria la personalizzazione dei dati durante la migrazione. Negli altri casi, esegui la migrazione delle viste alle viste BigQuery. Questa opzione ha i seguenti prerequisiti:- Puoi utilizzare questa opzione solo con Teradata versione 16.10 e successive.
- Una vista deve avere una colonna di numeri interi "partition" definita, che punta a un ID di partizione per la riga specificata nella tabella sottostante.
max-sessions: specifica il numero massimo di sessioni utilizzate dal job di esportazione (FastExport o TPT). Se impostato su 0, il database Teradata determinerà il numero massimo di sessioni per ogni job di esportazione.gcs-upload-chunk-size: un file di grandi dimensioni viene caricato in Cloud Storage in blocchi. Questo parametro, insieme amax-parallel-upload, viene utilizzato per controllare la quantità di dati caricati contemporaneamente in Cloud Storage. Ad esempio, segcs-upload-chunk-sizeè 64 MB emax-parallel-uploadè 10 MB, teoricamente un agente di migrazione può caricare 640 MB (64 MB * 10) di dati contemporaneamente. Se il caricamento del blocco non va a buon fine, è necessario riprovare a caricarlo. La dimensione del chunk deve essere piccola.max-parallel-upload: questo valore determina il numero massimo di thread utilizzati dall'agente di migrazione per caricare i file in Cloud Storage. Se non specificato, il valore predefinito è il numero di processori disponibili per la Java Virtual Machine. La regola generale è scegliere il valore in base al numero di core della macchina che esegue l'agente. Quindi, se haincore, il numero ottimale di thread dovrebbe esseren. Se i core sono hyper-threaded, il numero ottimale deve essere(2 * n). Esistono anche altre impostazioni, come la larghezza di banda della rete, che devi considerare durante la regolazione dimax-parallel-upload. La modifica di questo parametro può migliorare le prestazioni del caricamento su Cloud Storage.spool-mode: nella maggior parte dei casi, la modalità NoSpool è l'opzione migliore.NoSpoolè il valore predefinito nella configurazione dell'agente. Puoi modificare questo parametro se si applica al tuo caso uno qualsiasi degli svantaggi di NoSpool.max-unload-file-size: determina la dimensione massima del file estratto. Questo parametro non viene applicato per le estrazioni TPT.max-parallel-extract-threads: Questa configurazione viene utilizzata solo in modalità FastExport. Determina il numero di thread paralleli utilizzati per estrarre i dati da Teradata. La modifica di questo parametro potrebbe migliorare le prestazioni dell'estrazione.tpt-template-path: utilizza questa configurazione per fornire uno script di estrazione TPT personalizzato come input. Puoi utilizzare questo parametro per applicare le trasformazioni ai dati di migrazione.schema-mapping-rule-path: (facoltativo) il percorso di un file di configurazione che contiene una mappatura dello schema per ignorare le regole di mappatura predefinite. Alcuni tipi di mapping funzionano solo con la modalità Teradata Parallel Transporter (TPT).Esempio: mappatura dal tipo Teradata
TIMESTAMPal tipo BigQueryDATETIME:{ "rules": [ { "database": { "name": "database.*", "tables": [ { "name": "table.*" } ] }, "match": { "type": "COLUMN_TYPE", "value": "TIMESTAMP" }, "action": { "type": "MAPPING", "value": "DATETIME" } } ] }
Attributi:
database: (facoltativo)nameè un'espressione regolare per i database da includere. Per impostazione predefinita, sono inclusi tutti i database.tables: (facoltativo) contiene un array di tabelle.nameè un'espressione regolare per le tabelle da includere. Per impostazione predefinita, sono incluse tutte le tabelle.match: (obbligatorio)- Valori supportati di
type:COLUMN_TYPE. - Valori supportati per
value:TIMESTAMP,DATETIME.
- Valori supportati di
action: (obbligatorio)- Valori supportati di
type:MAPPING. - Valori supportati per
value:TIMESTAMP,DATETIME.
- Valori supportati di
compress-output: (facoltativo) indica se i dati devono essere compressi prima di essere archiviati in Cloud Storage. Questa impostazione viene applicata solo in tpt-mode. Per impostazione predefinita, questo valore èfalse.
Esegui l'agente specificando i percorsi del driver JDBC, dell'agente di migrazione e del file di configurazione creato nel passaggio di inizializzazione precedente.
java -cp \ OS-specific-separated-paths-to-jars (JDBC and agent) \ com.google.cloud.bigquery.dms.Agent \ --configuration-file=path to configuration file
Unix, Linux, Mac OS
java -cp \ /usr/local/migration/Teradata/JDBC/terajdbc4.jar:mirroring-agent.jar \ com.google.cloud.bigquery.dms.Agent \ --configuration-file=config.json
Windows
Copia tutti i file nella cartella
C:\migration(o modifica i percorsi nel comando), poi esegui:java -cp C:\migration\terajdbc4.jar;C:\migration\mirroring-agent.jar com.google.cloud.bigquery.dms.Agent --configuration-file=config.json
Se vuoi procedere con la migrazione, premi
Entere l'agente procederà se il classpath fornito durante l'inizializzazione è valido.Quando richiesto, digita il nome utente e la password per la connessione al database. Se il nome utente e la password sono validi, inizia la migrazione dei dati.
(Facoltativo) Nel comando per avviare la migrazione, puoi anche utilizzare un flag che passa un file di credenziali all'agente, anziché inserire il nome utente e la password ogni volta. Per saperne di più, consulta il parametro facoltativo
database-credentials-file-pathnel file di configurazione dell'agente. Quando utilizzi un file delle credenziali, adotta le misure appropriate per controllare l'accesso alla cartella in cui lo memorizzi sul file system locale, perché non verrà criptato.Lascia aperta questa sessione fino al completamento della migrazione. Se hai creato un trasferimento di migrazione ricorrente, mantieni aperta questa sessione a tempo indeterminato. Se questa sessione viene interrotta, le esecuzioni di trasferimento attuali e future non vanno a buon fine.
Monitora periodicamente se l'agente è in esecuzione. Se un trasferimento è in corso e nessun agente risponde entro 24 ore, il trasferimento non va a buon fine.
Se l'agente di migrazione smette di funzionare durante il trasferimento in corso o pianificato, la Google Cloud console mostra lo stato di errore e ti chiede di riavviare l'agente. Per riavviare l'agente di migrazione, riprendi dall'inizio di questa sezione, eseguendo l'agente di migrazione, con il comando per eseguire l'agente di migrazione. Non è necessario ripetere il comando di inizializzazione. Il trasferimento riprende dal punto in cui le tabelle non sono state completate.
- Prova una migrazione di test da Teradata a BigQuery.
- Scopri di più su BigQuery Data Transfer Service.
- Esegui la migrazione del codice SQL con la traduzione SQL batch.
Impostare le autorizzazioni richieste
Assicurati che l'entità che crea il trasferimento disponga dei seguenti ruoli nel progetto contenente il job di trasferimento:
Crea un set di dati
Crea un set di dati BigQuery per archiviare i dati. Non è necessario creare tabelle.
Crea un bucket Cloud Storage
Crea un bucket Cloud Storage per lo staging dei dati durante il job di trasferimento.
Prepara l'ambiente locale
Completa le attività in questa sezione per preparare l'ambiente locale per il job di trasferimento.
Requisiti del computer locale
Dettagli della connessione Teradata
Scaricare il driver JDBC
Scarica il file del driver JDBC terajdbc4.jar da Teradata
su una macchina che può connettersi al data warehouse.
Imposta la variabile GOOGLE_APPLICATION_CREDENTIALS
Imposta la variabile di ambiente GOOGLE_APPLICATION_CREDENTIALS sulla chiave del account di servizio scaricata nella sezione Prima di iniziare.
Aggiorna la regola di uscita dei Controlli di servizio VPC
Aggiungi un progetto gestito da BigQuery Data Transfer Service Google Cloud (numero di progetto: 990232121269) alla regola di uscita nel perimetro Controlli di servizio VPC.
Il canale di comunicazione tra l'agente in esecuzione on-premise e BigQuery Data Transfer Service avviene tramite la pubblicazione di messaggi Pub/Sub in un argomento per trasferimento. BigQuery Data Transfer Service deve inviare comandi all'agente per estrarre i dati e l'agente deve pubblicare messaggi in BigQuery Data Transfer Service per aggiornare lo stato e restituire le risposte all'estrazione dei dati.
Creare un file di schema personalizzato
Per utilizzare un file di schema personalizzato anziché il rilevamento automatico dello schema, creane uno manualmente o chiedi all'agente di migrazione di crearne uno per te quando inizializzi l'agente.
Se crei un file di schema manualmente e intendi utilizzare la console Google Cloud per creare un trasferimento, carica il file di schema in un bucket Cloud Storage nello stesso progetto che prevedi di utilizzare per il trasferimento.
Scarica l'agente di migrazione
Scarica l'agente di migrazione su una macchina che può connettersi al data warehouse. Sposta il file JAR dell'agente di migrazione nella stessa directory del file JAR del driver JDBC di Teradata.
Configurare un trasferimento
Crea un trasferimento con BigQuery Data Transfer Service.
Se vuoi che venga creato automaticamente un file schema personalizzato, utilizza l'agente di migrazione per configurare il trasferimento.
Non puoi creare un trasferimento on demand utilizzando lo strumento a riga di comando bq. Devi utilizzare la console Google Cloud o l'API BigQuery Data Transfer Service.
Se crei un trasferimento ricorrente, ti consigliamo vivamente di specificare un file di schema in modo che i dati dei trasferimenti successivi possano essere partizionati correttamente quando vengono caricati in BigQuery. Senza un file schema, BigQuery Data Transfer Service deduce lo schema della tabella dai dati di origine trasferiti e tutte le informazioni su partizionamento, clustering, chiavi primarie e monitoraggio delle modifiche vengono perse. Inoltre, i trasferimenti successivi saltano le tabelle di cui è già stata eseguita la migrazione dopo il trasferimento iniziale. Per saperne di più su come creare un file schema, vedi File schema personalizzato.
Console
bq
Quando crei un trasferimento Cloud Storage utilizzando lo strumento bq, la configurazione del trasferimento viene impostata in modo che si ripeta ogni 24 ore. Per i trasferimenti on demand, utilizza la console Google Cloud o l'API BigQuery Data Transfer Service.
Non puoi configurare le notifiche utilizzando lo strumento bq.
Inserisci il
comando
bq mk
e fornisci il flag di creazione del trasferimento
--transfer_config. Sono necessari anche i seguenti flag:
bq mk \ --transfer_config \ --project_id=project ID \ --target_dataset=dataset \ --display_name=name \ --service_account_name=service_account \ --params='parameters' \ --data_source=data source
Dove:
Ad esempio, il seguente comando crea un trasferimento Teradata denominato
My Transfer utilizzando il bucket Cloud Storage mybucket e il set di dati di destinazione
mydataset. Il trasferimento eseguirà la migrazione di tutte le tabelle dal data warehouse Teradata mydatabase e il file dello schema facoltativo è myschemafile.json.
bq mk \ --transfer_config \ --project_id=123456789876 \ --target_dataset=MyDataset \ --display_name='My Migration' \ --params='{"bucket": "mybucket", "database_type": "Teradata", "database_name":"mydatabase", "table_name_patterns": ".*", "agent_service_account":"myemail@mydomain.com", "schema_file_path": "gs://mybucket/myschemafile.json"}' \ --data_source=on_premises
Dopo aver eseguito il comando, ricevi un messaggio simile al seguente:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Segui le istruzioni e incolla il codice di autenticazione nella riga di comando.
API
Utilizza il metodo projects.locations.transferConfigs.create e fornisci un'istanza della risorsa TransferConfig.
Java
Prima di provare questo esempio, segui le istruzioni di configurazione di Java nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Java.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Agente di migrazione
Se vuoi, puoi configurare il trasferimento direttamente dall'agente di migrazione. Per maggiori informazioni, vedi Inizializzare l'agente di migrazione.
Inizializzare l'agente di migrazione
Per un nuovo trasferimento, devi inizializzare l'agente di migrazione. L'inizializzazione è richiesta una sola volta per un trasferimento, indipendentemente dal fatto che sia ricorrente o meno. L'inizializzazione configura solo l'agente di migrazione, non avvia il trasferimento.
Se utilizzi l'agente di migrazione per creare un file di schema personalizzato,
assicurati di avere una directory scrivibile nella directory di lavoro con lo stesso nome del progetto che vuoi utilizzare per il
trasferimento. Qui l'agente di migrazione crea il file dello schema.
Ad esempio, se lavori in /home e stai configurando
il trasferimento nel progetto myProject, crea la directory /home/myProject
e assicurati che sia scrivibile dagli utenti.
File di configurazione per l'agente di migrazione
Il file di configurazione creato nel passaggio di inizializzazione è simile a questo esempio:
{
"agent-id": "81f452cd-c931-426c-a0de-c62f726f6a6f",
"transfer-configuration": {
"project-id": "123456789876",
"location": "us",
"id": "61d7ab69-0000-2f6c-9b6c-14c14ef21038"
},
"source-type": "teradata",
"console-log": false,
"silent": false,
"teradata-config": {
"connection": {
"host": "localhost"
},
"local-processing-space": "extracted",
"database-credentials-file-path": "",
"max-local-storage": "50GB",
"gcs-upload-chunk-size": "32MB",
"use-tpt": true,
"transfer-views": false,
"max-sessions": 0,
"spool-mode": "NoSpool",
"max-parallel-upload": 4,
"max-parallel-extract-threads": 1,
"session-charset": "UTF8",
"max-unload-file-size": "2GB"
}
}
Opzioni del job di trasferimento nel file di configurazione dell'agente di migrazione
Esegui l'agente di migrazione
Dopo aver inizializzato l'agente di migrazione e creato il file di configurazione, segui i passaggi riportati di seguito per eseguire l'agente e avviare la migrazione:
Monitorare l'avanzamento della migrazione
Puoi visualizzare lo stato della migrazione nella console Google Cloud . Puoi anche configurare notifiche Pub/Sub o email. Consulta Notifiche di BigQuery Data Transfer Service.
BigQuery Data Transfer Service pianifica e avvia un'esecuzione del trasferimento in base a una pianificazione specificata al momento della creazione della configurazione del trasferimento. È importante che l'agente di migrazione sia in esecuzione quando un'esecuzione del trasferimento è attiva. Se non vengono ricevuti aggiornamenti da parte dell'agente entro 24 ore, l'esecuzione del trasferimento non va a buon fine.
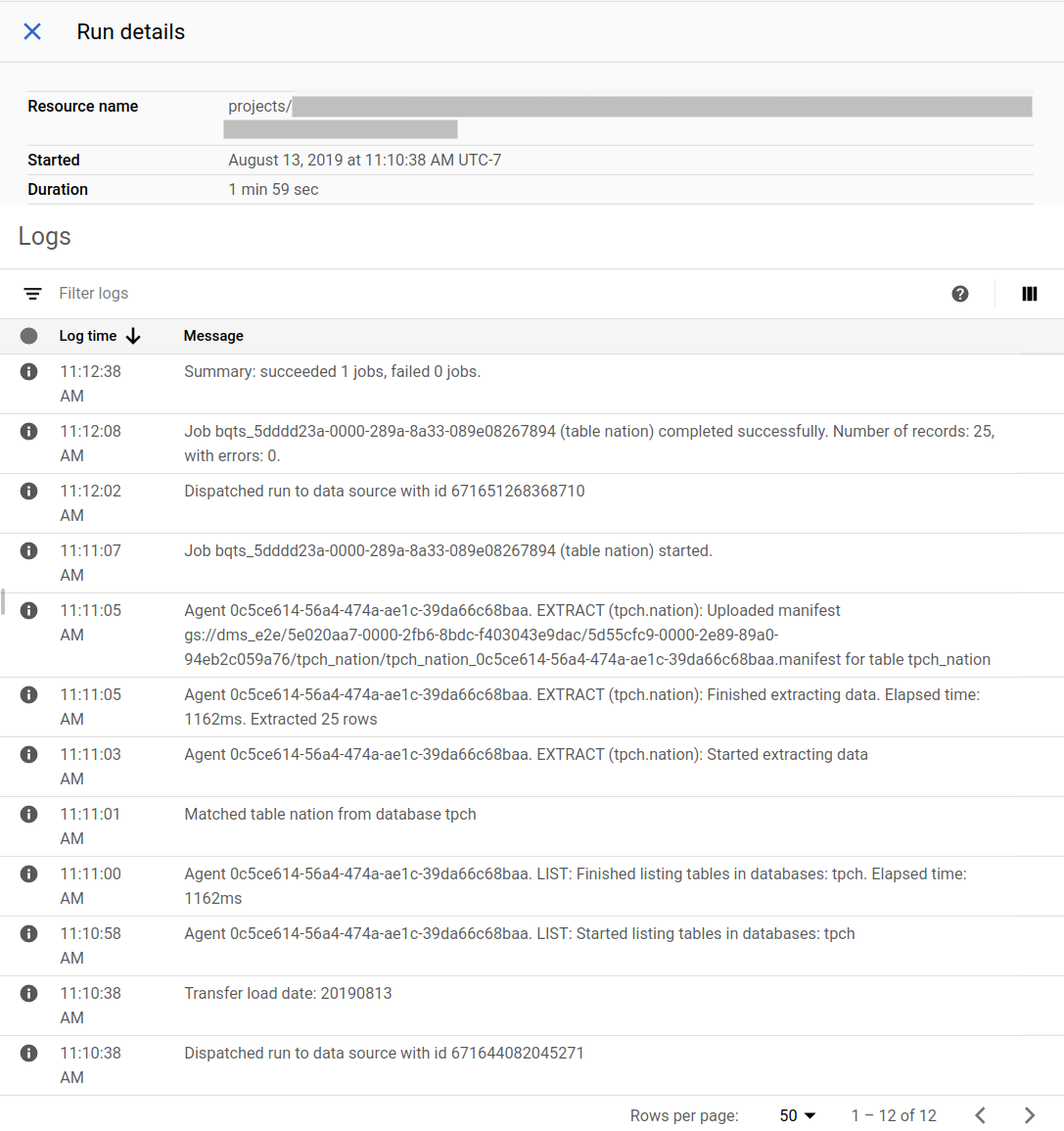
Esempio di stato della migrazione nella console Google Cloud :
Esegui l'upgrade dell'agente di migrazione
Se è disponibile una nuova versione dell'agente di migrazione, devi aggiornarlo manualmente. Per ricevere notifiche relative a BigQuery Data Transfer Service, iscriviti alle note di rilascio.