教程:将 Teradata 迁移到 BigQuery
本文档介绍如何使用示例数据从 Teradata 迁移到 BigQuery。它提供了一个概念验证教程,会引导您完成将架构和数据从 Teradata 数据仓库转移到 BigQuery 的过程。
目标
- 生成合成数据并将其上传到 Teradata。
- 使用 BigQuery Data Transfer Service (BQDT) 将架构和数据迁移到 BigQuery。
- 验证在 Teradata 和 BigQuery 上返回的查询结果是否相同。
费用
本快速入门使用 Google Cloud的以下收费组件:
- BigQuery:本教程在一次执行多个查询时,会将大约 1 GB 的数据存储在 BigQuery 中,且处理的数据量不到 2 GB。作为Google Cloud 免费层级的一部分,BigQuery 提供一些有特定限额的免费资源。这些免费资源的用量限额在免费试用期间及试用结束后均有效。如果超过这些用量限额且免费试用期已结束,您需要根据 BigQuery 价格页面上的价格支付费用。
您可使用价格计算器根据您的预计用量来估算费用。
前提条件
- 确保您对机器拥有写入权限和执行权限且机器可访问互联网,以便下载数据生成工具并运行该工具。
- 确保您可以连接到 Teradata 数据库。
确保机器已安装 Teradata BTEQ 和 FastLoad 客户端工具。您可以从 Teradata 网站获取 Teradata 客户端工具。如需安装上述工具的相关帮助,请联系系统管理员,了解有关安装、配置和运行这些工具的详细信息。您也可以执行以下操作,作为 BTEQ 的补充或替代方式:
- 安装具有图形界面的工具,如 DBeaver。
- 安装 Python 版 Teradata SQL 驱动程序,用于编写与 Teradata 数据库的交互的脚本。
确保机器和Google Cloud 之间具有网络连接,以便 BigQuery Data Transfer Service 代理能与 BigQuery 通信并转移架构和数据。
简介
本快速入门将逐步说明迁移过程的概念验证。在本快速入门中,您首先需要生成合成数据并将其加载到 Teradata 中。然后,使用 BigQuery Data Transfer Service 将架构和数据迁移至 BigQuery。最后,您需要对 Teradata 和 BigQuery 运行查询并比较结果。最终状态应是 Teradata 中的架构和数据会一对一地映射到 BigQuery。
本快速入门主要面向意在获得使用 BigQuery Data Transfer Service 迁移架构和数据实际经验的数据仓库管理员、开发者和数据从业者。
生成数据
国际事务处理性能委员会(Transaction Processing Performance Council,简称 TPC)是一家负责发布基准化规范的非营利组织。这些规范已成为运行数据相关基准测试的通行行业标准。
TPC-H 规范是一项以决策支持为主的基准。在本快速入门中,您将使用此规范的部分来创建表格并生成合成数据,以此作为实际数据仓库的模型。虽然该规范是为了基准化而设,但在本快速入门中,您将此模型作为迁移概念验证的一环,而非用于基准化任务。
- 在要连接到 Teradata 的计算机上,使用网络浏览器从 TPC 网站下载最新版本的 TPC-H 工具。
- 打开命令终端并切换到下载工具的目标目录。
解压缩下载的 ZIP 文件。将 file-name 替换为您下载的文件的名称:
unzip file-name.zip
系统会解压缩名称中包含工具版本号的目录。此目录包含 DBGEN 数据生成工具的 TPC 源代码以及 TPC-H 规范本身。
转到
dbgen子目录。请使用与您的版本对应的父级目录名称,如以下示例所示:cd 2.18.0_rc2/dbgen使用提供的模板创建 makefile:
cp makefile.suite makefile使用文本编辑器修改此 makefile。例如,使用 vi 修改该文件:
vi makefile在 makefile 中,更改以下变量的值:
CC = gcc # TDAT -> TERADATA DATABASE = TDAT MACHINE = LINUX WORKLOAD = TPCHC 编译器 (
CC) 或MACHINE值可能因环境而异。如果需要,请咨询您的系统管理员。保存更改并关闭该文件。
处理 makefile:
make使用
dbgen工具生成 TPC-H 数据:dbgen -v数据生成过程需要几分钟时间完成。
-v(详细)标志会使该命令报告进度。数据生成完成后,您会在当前文件夹中找到 8 个扩展名为.tbl的 ASCII 文件。这些文件包含用竖线分隔的合成数据,这些便是需载入各个 TPC-H 表中的数据。
将示例数据上传到 Teradata
在本部分中,您需要将生成的数据上传到 Teradata 数据库。
创建 TPC-H 数据库
Teradata 客户端(名称为 Basic Teradata Query (BTEQ))用于与一个或多个 Teradata 数据库服务器通信并在这些系统上运行 SQL 查询。在本部分中,您将使用 BTEQ 为 TPC-H 表创建新的数据库。
打开 Teradata BTEQ 客户端:
bteq登录 Teradata。将 teradata-ip 和 teradata-user 替换为与您的环境相对应的值。
.LOGON teradata-ip/teradata-user
创建一个名为
tpch的数据库并为其分配 2 GB 的空间:CREATE DATABASE tpch AS PERM=2e+09;退出 BTEQ:
.QUIT
加载生成的数据
在本部分中,您将创建 FastLoad 脚本来创建和加载示例表。TPC-H 规范的第 1.4 节介绍了表定义。第 1.2 节提供了整个数据库架构的实体关系图。
以下过程演示了如何创建 lineitem 表,这是最大且最复杂的 TPC-H 表。创建 lineitem 表后,请重复此过程,继续创建其余的表。
使用文本编辑器创建名为
fastload_lineitem.fl的新文件:vi fastload_lineitem.fl将以下脚本复制到该文件中,该文件将连接到 Teradata 数据库并创建名为
lineitem的表。在
logon命令中,将 teradata-ip、teradata-user、teradata-pwd 替换为您的连接详细信息。logon teradata-ip/teradata-user,teradata-pwd; drop table tpch.lineitem; drop table tpch.error_1; drop table tpch.error_2; CREATE multiset TABLE tpch.lineitem, NO FALLBACK, NO BEFORE JOURNAL, NO AFTER JOURNAL, CHECKSUM = DEFAULT, DEFAULT MERGEBLOCKRATIO ( L_ORDERKEY INTEGER NOT NULL, L_PARTKEY INTEGER NOT NULL, L_SUPPKEY INTEGER NOT NULL, L_LINENUMBER INTEGER NOT NULL, L_QUANTITY DECIMAL(15,2) NOT NULL, L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL, L_DISCOUNT DECIMAL(15,2) NOT NULL, L_TAX DECIMAL(15,2) NOT NULL, L_RETURNFLAG CHAR(1) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_LINESTATUS CHAR(1) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_SHIPDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_COMMITDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_RECEIPTDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_SHIPINSTRUCT CHAR(25) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_SHIPMODE CHAR(10) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_COMMENT VARCHAR(44) CHARACTER SET LATIN CASESPECIFIC NOT NULL) PRIMARY INDEX ( L_ORDERKEY ) PARTITION BY RANGE_N(L_COMMITDATE BETWEEN DATE '1992-01-01' AND DATE '1998-12-31' EACH INTERVAL '1' DAY);该脚本首先会确保不存在
lineitem表和临时错误表,然后才继续创建lineitem表。在同一文件中添加以下代码,以将数据加载到新创建的表中。请填写三个代码块(
define、insert和values)中的所有表字段,确保您使用varchar作为加载数据类型。begin loading tpch.lineitem errorfiles tpch.error_1, tpch.error_2; set record vartext; define in_ORDERKEY(varchar(50)), in_PARTKEY(varchar(50)), in_SUPPKEY(varchar(50)), in_LINENUMBER(varchar(50)), in_QUANTITY(varchar(50)), in_EXTENDEDPRICE(varchar(50)), in_DISCOUNT(varchar(50)), in_TAX(varchar(50)), in_RETURNFLAG(varchar(50)), in_LINESTATUS(varchar(50)), in_SHIPDATE(varchar(50)), in_COMMITDATE(varchar(50)), in_RECEIPTDATE(varchar(50)), in_SHIPINSTRUCT(varchar(50)), in_SHIPMODE(varchar(50)), in_COMMENT(varchar(50)) file = lineitem.tbl; insert into tpch.lineitem ( L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER, L_QUANTITY, L_EXTENDEDPRICE, L_DISCOUNT, L_TAX, L_RETURNFLAG, L_LINESTATUS, L_SHIPDATE, L_COMMITDATE, L_RECEIPTDATE, L_SHIPINSTRUCT, L_SHIPMODE, L_COMMENT ) values ( :in_ORDERKEY, :in_PARTKEY, :in_SUPPKEY, :in_LINENUMBER, :in_QUANTITY, :in_EXTENDEDPRICE, :in_DISCOUNT, :in_TAX, :in_RETURNFLAG, :in_LINESTATUS, :in_SHIPDATE, :in_COMMITDATE, :in_RECEIPTDATE, :in_SHIPINSTRUCT, :in_SHIPMODE, :in_COMMENT ); end loading; logoff;
FastLoad 脚本会从同一目录中名为
lineitem.tbl的文件(在上一部分中生成)加载数据。保存更改并关闭该文件。
运行 FastLoad 脚本:
fastload < fastload_lineitem.fl对 TPC-H 规范第 1.4 节中列出的其余 TPC-H 表重复上述过程。请务必针对每个表格相应地调整这些步骤。
将架构和数据迁移到 BigQuery
如需了解如何将架构和数据迁移到 BigQuery,可参考另一教程:从 Teradata 迁移数据。本部分将详细介绍如何进行该教程的特定步骤。完成另一教程的步骤后,请回到本文,继续进行下一部分(验证查询结果)中的操作。
创建 BigQuery 数据集
在初始 Google Cloud 配置步骤期间,系统会要求您在 BigQuery 中创建一个数据集来保存迁移后的表。将该数据集命名为 tpch。本快速入门结尾的查询将采用此名称,您无需进行任何修改。
# Use the bq utility to create the dataset
bq mk --location=US tpch
创建服务账号
此外,作为 Google Cloud 配置步骤的一部分,您还必须创建 Identity and Access Management (IAM) 服务账号。此服务账号用于将数据写入 BigQuery 以及将临时数据存储到 Cloud Storage 中。
# Set the PROJECT variable
export PROJECT=$(gcloud config get-value project)
# Create a service account
gcloud iam service-accounts create tpch-transfer
向该服务账号授予相关权限,让其管理 BigQuery 数据集及 Cloud Storage 中的暂存区域:
# Set TPCH_SVC_ACCOUNT = service account email
export TPCH_SVC_ACCOUNT=tpch-transfer@${PROJECT}.iam.gserviceaccount.com
# Bind the service account to the BigQuery Admin role
gcloud projects add-iam-policy-binding ${PROJECT} \
--member serviceAccount:${TPCH_SVC_ACCOUNT} \
--role roles/bigquery.admin
# Bind the service account to the Storage Admin role
gcloud projects add-iam-policy-binding ${PROJECT} \
--member serviceAccount:${TPCH_SVC_ACCOUNT} \
--role roles/storage.admin
创建暂存 Cloud Storage 存储分区
Google Cloud 配置中的一项额外任务是创建 Cloud Storage 存储桶。该存储分区供 BigQuery Data Transfer Service 用作暂存区域,用来放置要提取到 BigQuery 的数据文件。
# Use gcloud storage to create the bucket
gcloud storage buckets create gs://${PROJECT}-tpch --location=us-central1
指定表名模式
在 BigQuery Data Transfer Service 中配置新的转移作业期间,系统会要求您指定一个表达式,以指明要加入转移作业的表格。在本快速入门中,请添加 tpch 数据库中的所有表。
表达式的格式为 database.table,表名可以替换为通配符。Java 的通配符以两个圆点开头,因此转移 tpch 数据库中所有表的表达式应如下所示:
tpch..*
请注意,该表达式中有两个圆点。
验证查询结果
至此,您已按照另一教程中的说明创建了示例数据、将数据上传到 Teradata,并使用了 BigQuery Data Transfer Service 将其迁移到 BigQuery。在本部分中,您将运行两个 TPC-H 标准查询来验证 Teradata 和 BigQuery 中的结果是否相同。
运行价格摘要报告查询
第一个查询是价格摘要报告查询(TPC-H 规范的第 2.4.1 节)。该查询会报告截至指定日期的已出账单商品数、已发货商品数和遭退回的商品数。
完整查询如下:
SELECT
l_returnflag,
l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice*(1-l_discount)) AS sum_disc_price,
SUM(l_extendedprice*(1-l_discount)*(1+l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM tpch.lineitem
WHERE l_shipdate BETWEEN '1996-01-01' AND '1996-01-10'
GROUP BY
l_returnflag,
l_linestatus
ORDER BY
l_returnflag,
l_linestatus;
在 Teradata 中运行该查询:
- 运行 BTEQ 并连接到 Teradata。如需了解详情,请参阅本文档前面的创建 TPC-H 数据库部分。
将输出显示宽度更改为 500 个字符:
.set width 500复制该查询并将其粘贴到 BTEQ 提示符下。
输出类似于以下内容:
L_RETURNFLAG L_LINESTATUS sum_qty sum_base_price sum_disc_price sum_charge avg_qty avg_price avg_disc count_order ------------ ------------ ----------------- ----------------- ----------------- ----------------- ----------------- ----------------- ----------------- ----------- N O 629900.00 943154565.63 896323924.4600 932337245.114003 25.45 38113.41 .05 24746
在 BigQuery 中运行同一查询:
转到 BigQuery 控制台:
将该查询复制到查询编辑器中。
确保
FROM行中的数据集名称正确无误。点击运行。
所得结果与 Teradata 的结果相同。
您可以选择更长的查询时间间隔,以确保扫描表中的所有行。
运行本地供应商数量查询
第二个示例查询是本地供应商数量查询报告(TPC-H 规范的第 2.4.5 节)。此查询会针对某个区域中的各个国家/地区,返回位于该国家/地区的客户和供应商各条专列项所产生的收入。这些结果对于规划物流中心位置这类工作来说相当实用。
完整查询如下:
SELECT
n_name AS nation,
SUM(l_extendedprice * (1 - l_discount) / 1000) AS revenue
FROM
tpch.customer,
tpch.orders,
tpch.lineitem,
tpch.supplier,
tpch.nation,
tpch.region
WHERE c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'EUROPE'
AND o_orderdate >= '1996-01-01'
AND o_orderdate < '1997-01-01'
GROUP BY
n_name
ORDER BY
revenue DESC;
请按照上一部分中的说明,在 Teradata BTEQ 和 BigQuery 控制台中运行该查询。
Teradata 返回的结果如下:
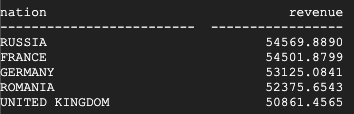
BigQuery 返回的结果如下:
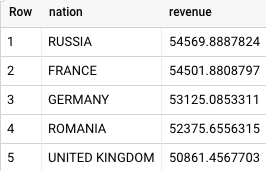
Teradata 和 BigQuery 都返回相同的结果。
运行产品类型利润评估查询
最后一项迁移验证测试是产品类型利润评估查询的最后一个查询示例(TPC-H 规范的第 2.4.9 节)。此查询会找出每个国家/地区每年卖出的所有零件的利润。这项查询按零件名称中的子字符串和特定供应商来过滤结果。
完整查询如下:
SELECT
nation,
o_year,
SUM(amount) AS sum_profit
FROM (
SELECT
n_name AS nation,
EXTRACT(YEAR FROM o_orderdate) AS o_year,
(l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity)/1e+3 AS amount
FROM
tpch.part,
tpch.supplier,
tpch.lineitem,
tpch.partsupp,
tpch.orders,
tpch.nation
WHERE s_suppkey = l_suppkey
AND ps_suppkey = l_suppkey
AND ps_partkey = l_partkey
AND p_partkey = l_partkey
AND o_orderkey = l_orderkey
AND s_nationkey = n_nationkey
AND p_name like '%blue%' ) AS profit
GROUP BY
nation,
o_year
ORDER BY
nation,
o_year DESC;
请按照上一部分中的说明,在 Teradata BTEQ 和 BigQuery 控制台中运行该查询。
Teradata 返回的结果如下:
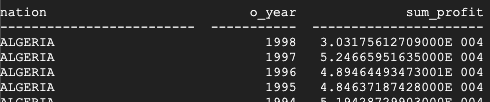
BigQuery 返回的结果如下:
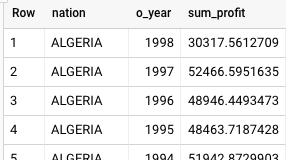
Teradata 和 BigQuery 都会返回相同的结果,但 Teradata 使用的是以科学记数法表示的总和。
其他查询
您可以选择运行 TPC-H 规范第 2.4 节中定义的其余 TPC-H 查询。
您还可以依照 TPC-H 标准,使用 QGEN 工具生成查询,该工具与 DBGEN 工具位于相同目录中。QGEN 是使用与 DBGEN 相同的 makefile 构建而成的,因此当您运行 make 来编译 dbgen 时,也会生成 qgen 可执行文件。
如需详细了解这两种工具及其命令行选项,请参阅每个工具各自的 README 文件。
清理
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请移除这些资源。
删除项目
停止计费的最简单方法是删除您为本教程创建的项目。
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
后续步骤
- 查看将 Teradata 迁移到 BigQuery 的分步说明。