Migración de Snowflake a BigQuery: descripción general
En este documento se explica cómo migrar datos de Snowflake a BigQuery.
Para obtener un marco general sobre cómo migrar de otros almacenes de datos a BigQuery, consulta el artículo Información general sobre la migración de almacenes de datos a BigQuery.
Descripción general de la migración de Snowflake a BigQuery
En el caso de una migración de Snowflake, te recomendamos que configures una arquitectura de migración que afecte lo mínimo posible a las operaciones actuales. En el siguiente ejemplo se muestra una arquitectura en la que puedes reutilizar tus herramientas y procesos actuales mientras transfieres otras cargas de trabajo a BigQuery.
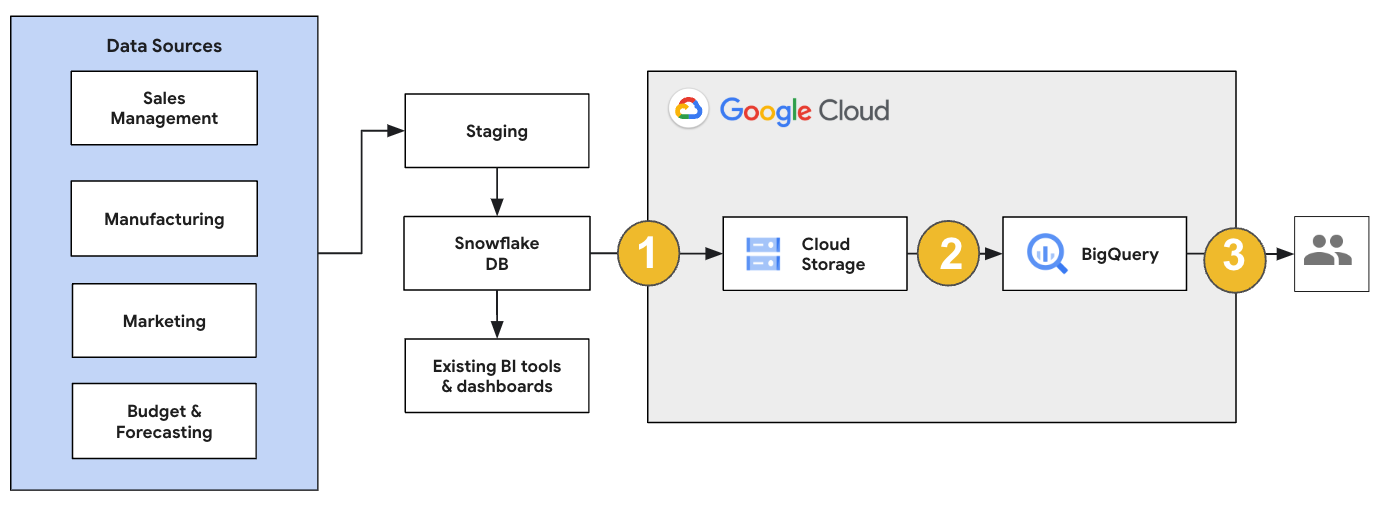
También puede validar informes y paneles de control con versiones anteriores. Para obtener más información, consulta Migrar almacenes de datos a BigQuery: verificar y validar.
Migrar cargas de trabajo concretas
Cuando planifiques tu migración a Snowflake, te recomendamos que migres las siguientes cargas de trabajo de forma individual y en el orden que se indica a continuación:
Migrar esquema
Empieza replicando los esquemas necesarios de tu entorno de Snowflake en BigQuery. Te recomendamos que uses BigQuery Migration Service para migrar tu esquema. BigQuery Migration Service admite una amplia gama de patrones de diseño de modelos de datos, como el esquema de estrella o el esquema de copo de nieve, lo que elimina la necesidad de actualizar tus flujos de datos ascendentes para un nuevo esquema. BigQuery Migration Service también ofrece migración de esquemas automatizada, incluidas las funciones de extracción y traducción de esquemas, para agilizar el proceso de migración.
Migrar consultas de SQL
Para migrar tus consultas de SQL, el servicio de migración de BigQuery ofrece varias funciones de traducción de SQL para automatizar la conversión de tus consultas de SQL de Snowflake a SQL de Google, como el traductor de SQL por lotes para traducir consultas en bloque, el traductor de SQL interactivo para traducir consultas individuales y la API de traducción de SQL. Estos servicios de traducción también incluyen funciones mejoradas con Gemini para simplificar aún más el proceso de migración de consultas de SQL.
Cuando traduzcas tus consultas SQL, revisa cuidadosamente las consultas traducidas para verificar que los tipos de datos y las estructuras de las tablas se gestionan correctamente. Para ello, te recomendamos que crees una amplia gama de casos de prueba con diferentes situaciones y datos. A continuación, ejecuta estos casos de prueba en BigQuery para comparar los resultados con los originales de Snowflake. Si hay alguna diferencia, analice y corrija las consultas convertidas.
Migrar datos
Hay varias formas de configurar tu flujo de procesamiento de migración de datos para transferir tus datos a BigQuery. Por lo general, estas canalizaciones siguen el mismo patrón:
Extrae los datos de tu origen: copia los archivos extraídos de tu origen en el almacenamiento provisional de tu entorno local. Para obtener más información, consulta el artículo Migrar almacenes de datos a BigQuery: extraer los datos de origen.
Transfiere los datos a un segmento de Cloud Storage de staging: después de extraer los datos de la fuente, transfiérelos a un segmento temporal de Cloud Storage. En función de la cantidad de datos que transfieras y del ancho de banda de la red disponible, tendrás varias opciones.
Es importante verificar que la ubicación de su conjunto de datos de BigQuery y de su fuente de datos externa, o de su segmento de Cloud Storage, se encuentren en la misma región.
Carga los datos del segmento de Cloud Storage en BigQuery: tus datos ahora están en un segmento de Cloud Storage. Hay varias opciones para subir los datos a BigQuery. Esas opciones dependen de la cantidad de datos que se tengan que transformar. También puedes transformar tus datos en BigQuery siguiendo la estrategia de extracción, carga y transformación (ELT).
Cuando importas tus datos de forma masiva desde un archivo JSON, un archivo Avro o un archivo CSV, BigQuery detecta automáticamente el esquema, por lo que no es necesario que lo definas previamente. Para obtener una descripción detallada del proceso de migración de esquemas para cargas de trabajo de EDW, consulta Proceso de migración de esquemas y datos.
Para ver una lista de las herramientas que admiten la migración de datos de Snowflake, consulta Herramientas de migración.
Para ver ejemplos completos de cómo configurar una canalización de migración de datos de Snowflake, consulta Ejemplos de canalizaciones de migración de Snowflake.
Optimizar el esquema y las consultas
Después de la migración del esquema, puede probar el rendimiento y hacer optimizaciones en función de los resultados. Por ejemplo, puedes introducir particiones para que sea más eficiente gestionar y consultar tus datos. Las particiones de tablas te permiten mejorar el rendimiento de las consultas y controlar los costes mediante particiones por tiempo de ingestión, marca de tiempo o intervalo de números enteros. Para obtener más información, consulta el artículo Introducción a las tablas particionadas.
Las tablas agrupadas en clústeres son otra optimización de esquemas. Puedes agrupar en clústeres tus tablas para organizar los datos de las tablas en función del contenido del esquema de la tabla, lo que mejora el rendimiento de las consultas que usan cláusulas de filtro o que agregan datos. Para obtener más información, consulta Introducción a las tablas agrupadas en clústeres.
Tipos de datos, propiedades y formatos de archivo admitidos
Snowflake y BigQuery admiten la mayoría de los mismos tipos de datos, aunque a veces usan nombres diferentes. Para ver una lista completa de los tipos de datos admitidos en Snowflake y BigQuery, consulta Tipos de datos. También puedes usar herramientas de traducción de SQL, como el traductor de SQL interactivo, la API de traducción de SQL o el traductor de SQL por lotes, para traducir diferentes dialectos de SQL a GoogleSQL.
Para obtener más información sobre los tipos de datos admitidos en BigQuery, consulta Tipos de datos de GoogleSQL.
Snowflake puede exportar datos en los siguientes formatos de archivo. Puede cargar los siguientes formatos directamente en BigQuery:
- Cargar datos CSV desde Cloud Storage.
- Cargar datos de Parquet desde Cloud Storage.
- Cargar datos de JSON desde Cloud Storage.
- Consultar datos de Apache Iceberg.
Herramientas de migración
En la siguiente lista se describen las herramientas que puedes usar para migrar datos de Snowflake a BigQuery. Para ver ejemplos de cómo se pueden usar estas herramientas juntas en una canalización de migración de Snowflake, consulte Ejemplos de canalizaciones de migración de Snowflake.
- Comando
COPY INTO <location>: utiliza este comando en Snowflake para extraer datos de una tabla de Snowflake directamente en un segmento de Cloud Storage especificado. Para ver un ejemplo completo, consulta Snowflake to BigQuery (snowflake2bq) en GitHub. - Apache Sqoop: Para extraer datos de Snowflake en HDFS o Cloud Storage, envía tareas de Hadoop con el controlador JDBC de Sqoop y Snowflake. Sqoop se ejecuta en un entorno de Dataproc.
- JDBC de Snowflake: utiliza este controlador con la mayoría de las herramientas o aplicaciones cliente que admiten JDBC.
Puede usar las siguientes herramientas genéricas para migrar datos de Snowflake a BigQuery:
- Conector de BigQuery Data Transfer Service para Snowflake Vista previa: realiza una transferencia por lotes automatizada de datos de Cloud Storage a BigQuery.
- La CLI de Google Cloud: copia los archivos de Snowflake descargados en Cloud Storage con esta herramienta de línea de comandos.
- Herramienta de línea de comandos bq: interactúa con BigQuery mediante esta herramienta de línea de comandos. Entre los casos de uso habituales se incluyen la creación de esquemas de tablas de BigQuery, la carga de datos de Cloud Storage en tablas y la ejecución de consultas.
- Bibliotecas de cliente de Cloud Storage: copia los archivos de Snowflake descargados en Cloud Storage con una herramienta personalizada que utilice las bibliotecas de cliente de Cloud Storage.
- Bibliotecas de cliente de BigQuery: interactúa con BigQuery con una herramienta personalizada creada a partir de la biblioteca de cliente de BigQuery.
- Programador de consultas de BigQuery: programa consultas de SQL periódicas con esta función integrada de BigQuery.
- Cloud Composer: utiliza este entorno de Apache Airflow totalmente gestionado para orquestar trabajos de carga y transformaciones de BigQuery.
Para obtener más información sobre cómo cargar datos en BigQuery, consulta el artículo Cargar datos en BigQuery.
Ejemplos de flujos de procesamiento de migración de Snowflake
En las siguientes secciones se muestran ejemplos de cómo migrar datos de Snowflake a BigQuery mediante tres procesos diferentes: ELT, ETL y herramientas de partners.
Extraer, cargar y transformar
Puede configurar un proceso de extracción, carga y transformación (ELT) de dos formas:
- Usar una canalización para extraer datos de Snowflake y cargarlos en BigQuery
- Extraer datos de Snowflake con otros productos Google Cloud .
Usar una canalización para extraer datos de Snowflake
Para extraer datos de Snowflake y cargarlos directamente en Cloud Storage, usa la herramienta snowflake2bq.
A continuación, puede cargar los datos de Cloud Storage en BigQuery con una de las siguientes herramientas:
- Conector de BigQuery Data Transfer Service para Cloud Storage
- El comando
LOADcon la herramienta de línea de comandos bq - Bibliotecas de cliente de la API de BigQuery
Otras herramientas para extraer datos de Snowflake
También puedes usar las siguientes herramientas para extraer datos de Snowflake:
- Dataflow
- Cloud Data Fusion
- Dataproc
- Conector de Apache Spark BigQuery
- Conector de Snowflake para Apache Spark
- Conector de Hadoop BigQuery
- El controlador JDBC de Snowflake y Sqoop para extraer datos de Snowflake en Cloud Storage:
Otras herramientas para cargar datos en BigQuery
También puedes usar las siguientes herramientas para cargar datos en BigQuery:
- Dataflow
- Cloud Data Fusion
- Dataproc
- Dataprep de Trifacta
Extracción, transformación y carga
Si quieres transformar tus datos antes de cargarlos en BigQuery, puedes usar las siguientes herramientas:
- Dataflow
- Clona el código de la plantilla de JDBC a BigQuery y modifica la plantilla para añadir transformaciones de Apache Beam.
- Cloud Data Fusion
- Crea una canalización reutilizable y transforma tus datos con plugins de CDAP.
- Dataproc
- Transforma tus datos con Spark SQL o con código personalizado en cualquiera de los lenguajes de Spark admitidos, como Scala, Java, Python o R.
Herramientas para partners de migración
Hay varios proveedores especializados en la migración de EDWs. Para ver una lista de los partners principales y las soluciones que ofrecen, consulta la página Partners de BigQuery.
Tutorial de exportación de Snowflake
En el siguiente tutorial se muestra un ejemplo de exportación de datos de Snowflake a BigQuery mediante el comando COPY INTO <location> de Snowflake.
Para ver un proceso detallado paso a paso que incluye ejemplos de código, consulta la Google Cloud herramienta de servicios profesionales de Snowflake a BigQuery.
Preparar la exportación
Para preparar los datos de Snowflake para la exportación, puedes extraerlos en un segmento de Cloud Storage o de Amazon Simple Storage Service (Amazon S3) siguiendo estos pasos:
Cloud Storage
En este tutorial se prepara el archivo en formato PARQUET.
Usa instrucciones SQL de Snowflake para crear una especificación de formato de archivo con nombre.
create or replace file format NAMED_FILE_FORMAT type = 'PARQUET'
Sustituye
NAMED_FILE_FORMATpor el nombre del formato de archivo. Por ejemplo,my_parquet_unload_format.Crea una integración con el comando
CREATE STORAGE INTEGRATION.create storage integration INTEGRATION_NAME type = external_stage storage_provider = gcs enabled = true storage_allowed_locations = ('BUCKET_NAME')
Haz los cambios siguientes:
INTEGRATION_NAME: nombre de la integración de almacenamiento. Por ejemplo,gcs_intBUCKET_NAME: la ruta al segmento de Cloud Storage. Por ejemplo,gcs://mybucket/extract/
Recupera la cuenta de servicio de Cloud Storage para Snowflake con el comando
DESCRIBE INTEGRATION.desc storage integration INTEGRATION_NAME;
El resultado debería ser similar al siguiente:
+-----------------------------+---------------+-----------------------------------------------------------------------------+------------------+ | property | property_type | property_value | property_default | +-----------------------------+---------------+-----------------------------------------------------------------------------+------------------| | ENABLED | Boolean | true | false | | STORAGE_ALLOWED_LOCATIONS | List | gcs://mybucket1/path1/,gcs://mybucket2/path2/ | [] | | STORAGE_BLOCKED_LOCATIONS | List | gcs://mybucket1/path1/sensitivedata/,gcs://mybucket2/path2/sensitivedata/ | [] | | STORAGE_GCP_SERVICE_ACCOUNT | String | service-account-id@iam.gserviceaccount.com | | +-----------------------------+---------------+-----------------------------------------------------------------------------+------------------+
Concede a la cuenta de servicio que aparece como
STORAGE_GCP_SERVICE_ACCOUNTacceso de lectura y escritura al segmento especificado en el comando de integración de almacenamiento. En este ejemplo, se concede a la cuenta de servicioservice-account-id@acceso de lectura y escritura al segmento<var>UNLOAD_BUCKET</var>.Crea una fase de Cloud Storage externa que haga referencia a la integración que has creado anteriormente.
create or replace stage STAGE_NAME url='UNLOAD_BUCKET' storage_integration = INTEGRATION_NAME file_format = NAMED_FILE_FORMAT;
Haz los cambios siguientes:
STAGE_NAME: nombre del objeto de la fase de Cloud Storage. Por ejemplo,my_ext_unload_stage
Amazon S3
En el siguiente ejemplo se muestra cómo mover datos de una tabla de Snowflake a un segmento de Amazon S3:
En Snowflake, configure un objeto de integración de almacenamiento para permitir que Snowflake escriba en un segmento de Amazon S3 al que se haga referencia en un área de almacenamiento externo de Cloud Storage.
Este paso implica configurar los permisos de acceso al bucket de Amazon S3, crear el rol de gestión de identidades y accesos (IAM) de Amazon Web Services (AWS) y crear una integración de almacenamiento en Snowflake con el comando
CREATE STORAGE INTEGRATION:create storage integration INTEGRATION_NAME type = external_stage storage_provider = s3 enabled = true storage_aws_role_arn = 'arn:aws:iam::001234567890:role/myrole' storage_allowed_locations = ('BUCKET_NAME')
Haz los cambios siguientes:
INTEGRATION_NAME: nombre de la integración de almacenamiento. Por ejemplo,s3_intBUCKET_NAME: la ruta al segmento de Amazon S3 en el que se cargarán los archivos. Por ejemplo,s3://unload/files/
Recupere el usuario de AWS IAM con el comando
DESCRIBE INTEGRATION.desc integration INTEGRATION_NAME;
El resultado debería ser similar al siguiente:
+---------------------------+---------------+================================================================================+------------------+ | property | property_type | property_value | property_default | +---------------------------+---------------+================================================================================+------------------| | ENABLED | Boolean | true | false | | STORAGE_ALLOWED_LOCATIONS | List | s3://mybucket1/mypath1/,s3://mybucket2/mypath2/ | [] | | STORAGE_BLOCKED_LOCATIONS | List | s3://mybucket1/mypath1/sensitivedata/,s3://mybucket2/mypath2/sensitivedata/ | [] | | STORAGE_AWS_IAM_USER_ARN | String | arn:aws:iam::123456789001:user/abc1-b-self1234 | | | STORAGE_AWS_ROLE_ARN | String | arn:aws:iam::001234567890:role/myrole | | | STORAGE_AWS_EXTERNAL_ID | String | MYACCOUNT_SFCRole=
| | +---------------------------+---------------+================================================================================+------------------+ Crea un rol que tenga el privilegio
CREATE STAGEpara el esquema y el privilegioUSAGEpara la integración de almacenamiento:CREATE role ROLE_NAME; GRANT CREATE STAGE ON SCHEMA public TO ROLE ROLE_NAME; GRANT USAGE ON INTEGRATION s3_int TO ROLE ROLE_NAME;
Sustituye
ROLE_NAMEpor el nombre del rol. Por ejemplo,myrole.Concede al usuario de gestión de identidades y accesos de AWS permisos para acceder al contenedor de Amazon S3 y crea un área de almacenamiento externa con el comando
CREATE STAGE:USE SCHEMA mydb.public; create or replace stage STAGE_NAME url='BUCKET_NAME' storage_integration = INTEGRATION_NAMEt file_format = NAMED_FILE_FORMAT;
Haz los cambios siguientes:
STAGE_NAME: nombre del objeto de la fase de Cloud Storage. Por ejemplo,my_ext_unload_stage
Exportar datos de Snowflake
Una vez que hayas preparado los datos, puedes transferirlos a Google Cloud.
Usa el comando COPY INTO para copiar datos de la tabla de la base de datos de Snowflake en un segmento de Cloud Storage o Amazon S3. Para ello, especifica el objeto de área de stage externa, STAGE_NAME.
copy into @STAGE_NAME/d1 from TABLE_NAME;
Sustituye TABLE_NAME por el nombre de tu tabla de base de datos de Snowflake.
Como resultado de este comando, los datos de la tabla se copian en el objeto de almacenamiento intermedio, que está vinculado al segmento de Cloud Storage o Amazon S3. El archivo incluye el prefijo d1.
Otros métodos de exportación
Para usar Azure Blob Storage en tus exportaciones de datos, sigue los pasos que se detallan en Descarga en Microsoft Azure. A continuación, transfiere los archivos exportados a Cloud Storage mediante Storage Transfer Service.
Precios
Cuando planifiques la migración de Snowflake, ten en cuenta el coste de transferir y almacenar datos, así como el de usar servicios en BigQuery. Para obtener más información, consulta los precios.
Puede haber costes de salida por mover datos fuera de Snowflake o AWS. También puede haber costes adicionales al transferir datos entre regiones o entre diferentes proveedores de la nube.
Siguientes pasos
- Rendimiento y optimización después de la migración.