Eseguire la migrazione da IBM Netezza
Questo documento fornisce indicazioni generali su come eseguire la migrazione da Netezza a BigQuery. Descrive le differenze di architettura fondamentali tra Netezza e BigQuery e le funzionalità aggiuntive offerte da BigQuery. Inoltre, mostra come puoi rivedere il tuo modello di dati esistente e le procedure di estrazione, trasformazione e caricamento (ETL) per massimizzare i vantaggi di BigQuery.
Questo documento è rivolto ad architetti aziendali, DBA, sviluppatori di applicazioni e professionisti della sicurezza IT che vogliono eseguire la migrazione da Netezza a BigQuery e risolvere le sfide tecniche del processo di migrazione. Questo documento fornisce dettagli sulle seguenti fasi del processo di migrazione:
- Esportazione di dati
- Importazione dei dati
- Sfruttare gli strumenti di terze parti
Puoi anche utilizzare la traduzione SQL batch per eseguire la migrazione collettiva degli script SQL o la traduzione SQL interattiva per tradurre query ad hoc. IBM Netezza SQL/NZPLSQL è supportato da entrambi gli strumenti in anteprima.
Confronto dell'architettura
Netezza è un sistema potente che può aiutarti ad archiviare e analizzare enormi quantità di dati. Tuttavia, un sistema come Netezza richiede enormi investimenti in hardware, manutenzioni e licenze. Questo può essere difficile da scalare a causa delle difficoltà di gestione dei nodi, del volume di dati per origine e dei costi di archiviazione. Con Netezza, la capacità di archiviazione e elaborazione è limitata dalle appliance hardware. Quando viene raggiunto il livello di utilizzo massimo, il processo di estensione della capacità dell'appliance è elaborato e a volte non è nemmeno possibile.
Con BigQuery non devi gestire l'infrastruttura e non hai bisogno di un amministratore del database. BigQuery è un data warehouse serverless completamente gestito con scalabilità nell'ordine dei petabyte che può eseguire la scansione di miliardi di righe senza un indice in decine di secondi. Poiché BigQuery condivide l'infrastruttura di Google, può eseguire in parallelo ogni query ed eseguirla su decine di migliaia di server contemporaneamente. Le seguenti tecnologie di base fanno la differenza di BigQuery:
- Spazio di archiviazione colonnare. I dati vengono archiviati in colonne anziché in righe, il che consente di ottenere un rapporto di compressione e un throughput di scansione molto elevati.
- Architettura ad albero. Le query vengono inviate e i risultati vengono aggregati su migliaia di macchine in pochi secondi.
Architettura Netezza
Netezza è un'appliance con accelerazione hardware dotata di un livello di astrazione dei dati software. Il livello di astrazione dei dati gestisce la distribuzione dei dati nell'appliance e ottimizza le query distribuendo l'elaborazione dei dati tra le CPU e le FPGA sottostanti.
Il supporto dei modelli Netezza TwinFin e Striper è terminato a giugno 2019.
Il seguente diagramma illustra i livelli di astrazione dei dati in Netezza:
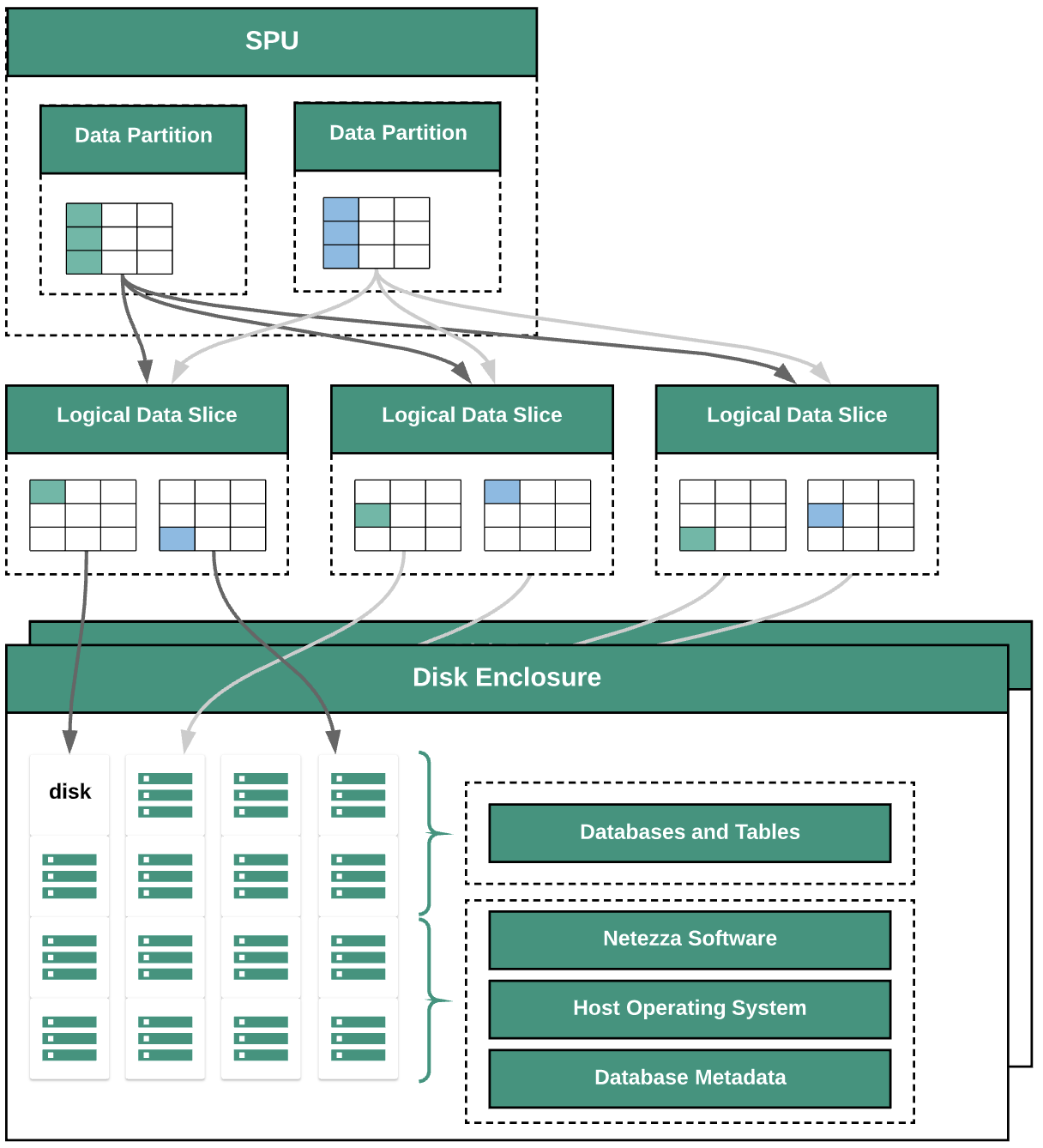
Il diagramma mostra i seguenti livelli di astrazione dei dati:
- Alloggiamento per dischi. Lo spazio fisico all'interno dell'appliance in cui sono montati i dischi.
- Dischi. I dischi fisici all'interno delle unità di espansione dei dischi archiviano i database e le tabelle.
- Slicing dei dati. Rappresentazione logica dei dati salvati su un disco.
I dati vengono distribuiti tra i vari slice utilizzando una chiave di distribuzione. Puoi monitorare lo stato dei segmenti di dati utilizzando i comandi
nzds. - Partizioni di dati. Rappresentazione logica di uno slice di dati gestito da una specifica unità di elaborazione snippet (SPU). Ogni SPU possiede una o più partizioni di dati contenenti i dati utente di cui è responsabile dell'elaborazione durante le query.
Tutti i componenti del sistema sono collegati dalla struttura di rete. L'appliance Netezza esegue un protocollo personalizzato in base agli indirizzi IP.
Architettura di BigQuery
BigQuery è un data warehouse aziendale completamente gestito che ti aiuta a gestire e analizzare i dati con funzionalità integrate come machine learning, analisi geospaziale e business intelligence. Per ulteriori informazioni, consulta Che cos'è BigQuery?.
BigQuery gestisce lo spazio di archiviazione e i calcoli per fornire archiviazione di dati durevoli e risposte ad alte prestazioni alle query di analisi. Per ulteriori informazioni, consulta BigQuery spiegato.
Per informazioni sui prezzi di BigQuery, consulta Informazioni su scalabilità rapida e prezzi semplici di BigQuery.
Pre-migrazione
Per garantire una migrazione del data warehouse efficace, inizia a pianificare la strategia di migrazione all'inizio della sequenza temporale del progetto. Per informazioni su come pianificare sistematicamente il lavoro di migrazione, consulta Che cosa e come eseguire la migrazione: il framework di migrazione.
Pianificazione della capacità di BigQuery
La velocità effettiva delle analisi in BigQuery viene misurata in slot. Uno slot BigQuery è un'unità di calcolo, RAM e throughput di rete proprietaria di Google necessaria per eseguire query SQL. BigQuery calcola automaticamente quanti slot sono necessari per ogni query, a seconda delle dimensioni e della complessità della query.
Per eseguire query in BigQuery, seleziona uno dei seguenti modelli di prezzo:
- On demand. Il modello di determinazione del prezzo predefinito, in cui ti viene addebitato il numero di byte elaborati da ogni query.
- Prezzi basati sulla capacità. Acquisti
slot, ovvero CPU virtuali. Quando acquisti slot, acquisti una capacità di elaborazione dedicata che puoi utilizzare per eseguire le query. Gli slot sono disponibili nei seguenti piani di impegno:
- Annuale. Ti impegni per un utilizzo di 365 giorni.
- Tre anni. Ti impegni per 365*3 giorni.
Uno slot BigQuery condivide alcune somiglianze con le SPU di Netezza, come CPU, memoria ed elaborazione dei dati. Tuttavia, non rappresentano la stessa unità di misura. Le SPU Netezza hanno una mappatura fissa ai componenti hardware di base, mentre lo slot BigQuery rappresenta una CPU virtuale utilizzata per eseguire le query. Per facilitare la stima degli slot, ti consigliamo di configurare il monitoraggio di BigQuery tramite Cloud Monitoring e di analizzare gli audit log utilizzando BigQuery. Per visualizzare l'utilizzo degli slot BigQuery, puoi anche utilizzare strumenti come Looker Studio o Looker. Monitorare e analizzare regolarmente l'utilizzo degli slot ti aiuta a stimare il numero totale di slot di cui la tua organizzazione ha bisogno man mano che cresce Google Cloud.
Ad esempio, supponiamo che tu prenoti inizialmente 2000 slot BigQuery per eseguire 50 query di media complessità contemporaneamente. Se l'esecuzione delle query richiede costantemente più di alcune ore e le dashboard mostrano un utilizzo elevato degli slot, le query potrebbero non essere ottimizzate o potresti aver bisogno di altri slot BigQuery per supportare i tuoi carichi di lavoro. Per acquistare personalmente gli slot con impegni annuali o trienni, puoi creare prenotazioni BigQuery utilizzando la Google Cloud console o lo strumento a riga di comando bq. Se hai firmato un contratto offline per l'acquisto in base alla capacità, il tuo piano potrebbe differire dai dettagli descritti qui.
Per informazioni su come controllare i costi di archiviazione e di elaborazione delle query su BigQuery, consulta Ottimizzare i workload.
Sicurezza a Google Cloud
Le sezioni seguenti descrivono i controlli di sicurezza comuni di Netezza e come puoi contribuire a proteggere il tuo data warehouse in un ambiente Google Cloud .
Gestione di identità e accessi
Il database Netezza contiene un insieme di funzionalità di controllo dell'accesso del sistema completamente integrate che consentono agli utenti di accedere alle risorse per le quali sono autorizzati.
L'accesso a Netezza viene controllato tramite la rete all'appliance Netezza tramite la gestione degli account utente Linux che possono accedere al sistema operativo. L'accesso al database, agli oggetti e alle attività Netezza viene gestito utilizzando gli account utente del database Netezza che possono stabilire connessioni SQL al sistema.
BigQuery utilizza il servizio Identity and Access Management (IAM) di Google per gestire l'accesso alle risorse. I tipi di risorse disponibili in BigQuery sono organizzazioni, progetti, set di dati, tabelle e viste. Nella gerarchia dei criteri IAM, i set di dati sono risorse secondarie dei progetti. Una tabella eredita le autorizzazioni dal set di dati che la contiene.
Per concedere l'accesso a una risorsa, assegna uno o più ruoli a un utente, un gruppo o un account di servizio. I ruoli dell'organizzazione e del progetto controllano l'accesso per eseguire job o gestire il progetto, mentre i ruoli del set di dati controllano l'accesso per visualizzare o modificare i dati all'interno di un progetto.
IAM fornisce i seguenti tipi di ruoli:
- Ruoli predefiniti. Per supportare scenari di utilizzo comuni e pattern di controllo dell'accesso.
- Ruoli di base. Include i ruoli Proprietario, Editor e Visualizzatore. I ruoli di base forniscono accesso granulare per un servizio specifico e sono gestiti da Google Cloud.
- Ruoli personalizzati. Fornisci accesso granulare in base a un elenco di autorizzazioni specificato dall'utente.
Quando assegni a un utente sia i ruoli di base che quelli predefiniti, le autorizzazioni concesse sono l'unione delle autorizzazioni di ciascun ruolo individuale.
Sicurezza a livello di riga
La sicurezza a più livelli è un modello di sicurezza astratto utilizzato da Netezza per definire regole per controllare l'accesso degli utenti alle tabelle con sicurezza a riga (RST). Una tabella protetta a livello di riga è una tabella di database con etichette di sicurezza sulle righe per filtrare gli utenti che non dispongono dei privilegi appropriati. I risultati restituiti dalle query variano in base ai privilegi dell'utente che effettua la query.
Per ottenere la sicurezza a livello di riga in BigQuery, puoi utilizzare viste autorizzate e criteri di accesso a livello di riga. Per maggiori informazioni su come progettare e implementare questi criteri, consulta la sezione Introduzione alla sicurezza a livello di riga di BigQuery.
Crittografia dei dati
Le appliance Netezza utilizzano unità con crittografia integrata (SED) per una maggiore sicurezza e protezione dei dati archiviati nell'appliance. I dischi SED criptano i dati quando vengono scritti sul disco. Ogni disco ha una chiave di crittografia del disco (DEK) impostata in fabbrica e archiviata sul disco. Il disco utilizza la DEK per criptare i dati durante la scrittura e poi per decriptarli quando vengono letti dal disco. Il funzionamento del disco, la sua crittografia e decrittografia, è trasparente per gli utenti che leggono e scrivono dati. Questa modalità di crittografia e decrittografia predefinita è indicata come modalità di eliminazione sicura.
In modalità di eliminazione sicura, non è necessaria una password o una chiave di autenticazione per decriptare e leggere i dati. I dischi SED offrono funzionalità migliorate per un'eliminazione sicura facile e rapida in situazioni in cui i dischi devono essere riutilizzati o restituiti per motivi di assistenza o in garanzia.
Netezza utilizza la crittografia simmetrica. Se i dati sono criptati a livello di campo, la seguente funzione di decrittografia può aiutarti a leggere ed esportare i dati:
varchar = decrypt(varchar text, varchar key [, int algorithm [, varchar IV]]); nvarchar = decrypt(nvarchar text, nvarchar key [, int algorithm[, varchar IV]]);
Tutti i dati archiviati in BigQuery sono criptati quando non sono in uso. Se vuoi controllare autonomamente la crittografia, puoi utilizzare le chiavi di crittografia gestite dal cliente (CMEK) per BigQuery. Con CMEK, invece che Google, sei tu a controllare e gestire le chiavi di crittografia delle chiavi che proteggono i tuoi dati in Cloud Key Management Service. Per ulteriori informazioni, consulta Crittografia at-rest.
Benchmarking delle prestazioni
Per monitorare l'avanzamento e il miglioramento durante il processo di migrazione, è importante stabilire un rendimento di riferimento per l'ambiente Netezza attuale. Per stabilire la linea di base, seleziona un insieme di query rappresentative, che vengono acquisite dalle applicazioni di consumo (come Tableau o Cognos).
| Ambiente | Netezza | BigQuery |
|---|---|---|
| Dimensioni dei dati | size TB | - |
| Query 1: name (scansione completa della tabella) | mm:ss.ms | - |
| Query 2: name | mm:ss.ms | - |
| Query 3: name | mm:ss.ms | - |
| Totale | mm:ss.ms | - |
Configurazione di base del progetto
Prima di eseguire il provisioning delle risorse di archiviazione per la migrazione dei dati, devi completare la configurazione del progetto.
- Per configurare i progetti e abilitare IAM a livello di progetto, consulta Google Cloud Well-Architected Framework.
- Per progettare le risorse di base per rendere il tuo deployment cloud adatto alle aziende, consulta Design della zona di destinazione in Google Cloud.
- Per informazioni sulla governance dei dati e sui controlli necessari per eseguire la migrazione del data warehouse on-premise a BigQuery, consulta la Panoramica della sicurezza e della governance dei dati.
Connettività di rete
È necessaria una connessione di rete affidabile e sicura tra il data center on-premise (dove è in esecuzione l'istanza Netezza) e l'ambiente Google Cloud. Per informazioni su come contribuire a proteggere la connessione, consulta Introduzione alla governance dei dati in BigQuery. Quando carichi estrazioni di dati, la larghezza di banda della rete può essere un fattore limitante. Per informazioni su come soddisfare i requisiti di trasferimento dati, consulta Aumentare la larghezza di banda di rete.
Tipi di dati e proprietà supportati
I tipi di dati di Netezza sono diversi da quelli di BigQuery. Per informazioni sui tipi di dati di BigQuery, consulta Tipi di dati. Per un confronto dettagliato tra i tipi di dati di Netezza e BigQuery, consulta la guida alla traduzione di SQL di IBM Netezza.
Confronto SQL
SQL dei dati Netezza è costituito da DDL, DML e Data Control Language (DCL) solo per Netezza, che sono diversi da GoogleSQL. GoogleSQL è conforme allo standard SQL 2011 e dispone di estensioni che supportano le query sui dati nidificati e ripetuti. Se utilizzi SQL precedente di BigQuery, consulta Funzioni e operatori SQL precedente. Per un confronto dettagliato tra le funzioni e gli SQL di Netezza e BigQuery, consulta la guida alla traduzione di SQL di IBM Netezza.
Per facilitare la migrazione del codice SQL, utilizza la traduzione SQL batch per eseguire la migrazione collettiva del codice SQL o la traduzione SQL interattiva per tradurre le query ad hoc.
Confronto delle funzioni
È importante capire come le funzioni Netezza vengono mappate alle funzioni BigQuery. Ad esempio, la funzione Months_Between
di Netezza restituisce un numero decimale, mentre la funzione DateDiff
di BigQuery restituisce un numero intero. Pertanto, devi utilizzare una
funzione UDF personalizzata per produrre il tipo di
dati corretto. Per un confronto dettagliato tra le funzioni Netezza SQL e GoogleSQL, consulta la guida alla traduzione di IBM Netezza SQL.
Migrazione dei dati
Per eseguire la migrazione dei dati da Netezza a BigQuery, esportali da Netezza, trasferiscili e mettili in fase su Google Cloud, quindi caricali in BigQuery. Questa sezione fornisce una panoramica generale della procedura di migrazione dei dati. Per una descrizione dettagliata del processo di migrazione dei dati, consulta Procedura di migrazione di schema e dati. Per un confronto dettagliato tra i tipi di dati supportati da Netezza e BigQuery, consulta la guida alla traduzione di IBM Netezza SQL.
Esportare dati da Netezza
Per esplorare i dati delle tabelle di database Netezza, ti consigliamo di esportarli in una tabella esterna in formato CSV. Per ulteriori informazioni, consulta Scaricare i dati su un sistema client remoto. Puoi anche leggere i dati utilizzando sistemi di terze parti come Informatica (o ETL personalizzati) con connettori JDBC/ODBC per produrre file CSV.
Netezza supporta solo l'esportazione di file flat non compressi (CSV) per ogni tabella.
Tuttavia, se esporti tabelle di grandi dimensioni, il file CSV non compresso può diventare molto grande. Se possibile, valuta la possibilità di convertire il file CSV in un formato consapevole dello schema, come Parquet, Avro o ORC, in modo da ottenere file di esportazione più piccoli e più affidabili. Se CSV è l'unico formato disponibile, ti consigliamo di comprimere
i file di esportazione per ridurre le dimensioni prima di caricarli su Google Cloud.
La riduzione delle dimensioni del file consente di velocizzare il caricamento e di aumentare l'affidabilità del trasferimento. Se trasferisci file su Cloud Storage, puoi utilizzare il flag --gzip-local in un comando gcloud storage cp, che comprime i file prima di caricarli.
Trasferimento e gestione temporanea dei dati
Dopo l'esportazione, i dati devono essere trasferiti e sottoposti a staging su Google Cloud. Esistono diverse opzioni per il trasferimento dei dati, a seconda della quantità di dati da trasferire e della larghezza di banda della rete disponibile. Per ulteriori informazioni, consulta la Panoramica del trasferimento di schemi e dati.
Quando utilizzi Google Cloud CLI, puoi automatizzare e parallelizzare il trasferimento di file in Cloud Storage. Limita le dimensioni dei file a 4 TB (non compressi) per un caricamento più rapido in BigQuery. Tuttavia, devi esportare lo schema in precedenza. Questa è una buona opportunità per ottimizzare BigQuery utilizzando il partizionamento e il clustering.
Utilizza gcloud storage bucket create per creare i bucket di staging per l'archiviazione dei dati esportati e gcloud storage cp per trasferire i file di esportazione dei dati nei bucket Cloud Storage.
L'interfaccia a riga di comando gcloud esegue automaticamente l'operazione di copia utilizzando una combinazione di multithreading e multiprocessing.
Caricamento di dati in BigQuery
Dopo aver eseguito il staging dei dati su Google Cloud, esistono diverse opzioni per caricarli in BigQuery. Per ulteriori informazioni, consulta Carica lo schema e i dati in BigQuery.
Strumenti e assistenza per i partner
Puoi ricevere assistenza da un partner durante il tuo percorso di migrazione. Per facilitare la migrazione del codice SQL, utilizza la traduzione SQL collettiva per eseguire la migrazione collettiva del codice SQL.
Molti Google Cloud partner offrono anche servizi di migrazione dei data warehouse. Per un elenco dei partner e delle soluzioni fornite, consulta Collabora con un partner con competenze di BigQuery.
Dopo la migrazione
Al termine della migrazione dei dati, puoi iniziare a ottimizzare l'utilizzo diGoogle Cloud per soddisfare le esigenze aziendali. Ad esempio, potresti utilizzare gli strumenti di esplorazione e visualizzazione diGoogle Cloudper ricavare approfondimenti per gli stakeholder aziendali, ottimizzare le query con un rendimento insoddisfacente o sviluppare un programma per favorire l'adozione da parte degli utenti.
Connettiti alle API BigQuery tramite internet
Il seguente diagramma mostra come un'applicazione esterna può connettersi a BigQuery utilizzando l'API:
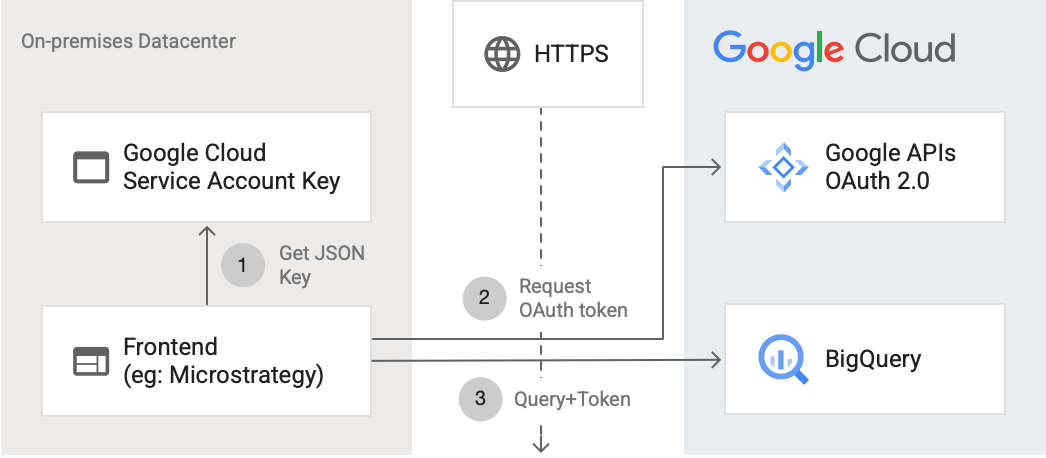
Il diagramma mostra i seguenti passaggi:
- In Google Cloud, viene creato un account di servizio con autorizzazioni IAM. La chiave dell'account di servizio viene generata in formato JSON e copiata sul server frontend (ad esempio MicroStrategy).
- Il frontend legge la chiave e richiede un token OAuth dalle API di Google su HTTPS.
- Il frontend invia quindi le richieste BigQuery insieme al token a BigQuery.
Per ulteriori informazioni, consulta Autorizzare le richieste API.
Ottimizzazione per BigQuery
GoogleSQL supporta la conformità allo standard SQL 2011 e dispone di estensioni che supportano le query su dati nidificati e ripetuti. L'ottimizzazione delle query per BigQuery è fondamentale per migliorare le prestazioni e il tempo di risposta.
Sostituzione della funzione Mesi_Tra in BigQuery con UDF
Netezza considera 31 i giorni di un mese. La seguente UDF personalizzata ricrea la funzione Nettezza con elevata precisione e puoi chiamarla dalle tue query:
CREATE TEMP FUNCTION months_between(date_1 DATE, date_2 DATE) AS ( CASE WHEN date_1 = date_2 THEN 0 WHEN EXTRACT(DAY FROM DATE_ADD(date_1, INTERVAL 1 DAY)) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(date_1,date_2, MONTH) WHEN EXTRACT(DAY FROM date_1) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(DATE_ADD(date_1, INTERVAL -1 DAY), date_2, MONTH) + 1/31 ELSE date_diff(date_1, date_2, MONTH) - 1 + ((EXTRACT(DAY FROM date_1) + (31 - EXTRACT(DAY FROM date_2))) / 31) END );
Esegui la migrazione delle stored procedure Netezza
Se utilizzi stored procedure Netezza nei workload ETL per creare tabelle di fatti, devi eseguire la migrazione di queste stored procedure alle query SQL compatibili con BigQuery. Netezza utilizza il linguaggio di scripting NZPLSQL per lavorare con le procedure memorizzate. NZPLSQL si basa sul linguaggio Postgres PL/pgSQL. Per ulteriori informazioni, consulta la guida alla traduzione di SQL di IBM Netezza.
FDU personalizzata per emulare ASCII di Netezza
La seguente UDF personalizzata per BigQuery corregge gli errori di codifica nelle colonne:
CREATE TEMP FUNCTION ascii(X STRING) AS (TO_CODE_POINTS(x)[ OFFSET (0)]);
Passaggi successivi
- Scopri come ottimizzare i carichi di lavoro per l'ottimizzazione delle prestazioni complessive e la riduzione dei costi.
- Scopri come ottimizzare lo spazio di archiviazione in BigQuery.
- Consulta la guida alla traduzione SQL di IBM Netezza.