Présentation : Migrer des entrepôts de données vers BigQuery
Ce document présente les concepts généraux qui s'appliquent à toute technologie d'entreposage de données et décrit un framework permettant d'organiser et de structurer votre migration vers BigQuery.
Terminologie
Nous utilisons la terminologie suivante pour discuter de la migration d'entrepôts de données :
- Cas d'utilisation
- Un cas d'utilisation comprend tous les ensembles de données, les opérations de traitement des données, ainsi que les interactions système et utilisateur permettant de générer une valeur métier ou commerciale, par exemple le suivi des volumes de vente d'un produit au fil du temps. En matière d'entreposage de données, un cas d'utilisation est souvent constitué :
- de pipelines de données qui ingèrent des données brutes provenant de diverses sources de données, telles que la base de données de gestion de la relation client (CRM) ;
- de données stockées dans l'entrepôt de données ;
- de procédures et scripts relatifs à la manipulation, au traitement et à l'analyse des données ;
- d'une application métier qui lit les données ou interagit avec elles.
- Charge de travail
- Un ensemble de cas d'utilisation qui sont connectés et partagent des dépendances. Par exemple, un cas d'utilisation peut inclure les relations et dépendances suivantes :
- Les rapports d'achat peuvent être utilisés seuls et sont utiles pour analyser les dépenses et demander des remises.
- Les rapports sur les ventes peuvent être utilisés seuls. Ils sont utiles pour planifier des campagnes marketing.
- Le compte de résultat dépend quant à lui des achats et des ventes. Il est utile pour déterminer la valeur de l'entreprise.
- Application d'entreprise
- Un système avec lequel les utilisateurs finaux interagissent, par exemple un rapport visuel ou un tableau de bord. Une application métier peut également prendre la forme d'un pipeline de données opérationnel ou d'une boucle de rétroaction. Par exemple, une fois que des changements de prix de produits ont été calculés ou prévus, un pipeline de données opérationnel peut mettre à jour les tarifs des produits dans une base de données transactionnelle.
- Processus en amont
- Les systèmes sources et les pipelines de données qui chargent des données dans l'entrepôt de données.
- Processus en aval
- Les scripts, procédures et applications métier utilisés pour traiter, interroger et visualiser les données dans l'entrepôt de données.
- Migration de déchargement
- Stratégie de migration visant à faire fonctionner le cas d'utilisation dans le nouvel environnement aussi rapidement que possible ou à exploiter la capacité supplémentaire disponible dans le nouvel environnement. Les cas d'utilisation sont déchargés en procédant comme suit :
- Copie puis synchronisation du schéma et des données provenant de l'ancien entrepôt de données
- Migration des scripts, procédures et applications métier en aval
La migration de déchargement peut accroître la complexité et le travail liés à la migration des pipelines de données.
- Migration complète
- S'apparente à une migration de déchargement, à la différence que le schéma et les données ne sont pas copiés puis synchronisés. Les données sont ingérées directement dans le nouvel entrepôt de données cloud à partir des systèmes sources en amont. En d'autres termes, les pipelines de données requis pour le cas d'utilisation sont également migrés.
- Entrepôt de données d'entreprise (EDW)
- Entrepôt de données qui comprend non seulement une base de données analytique, mais également plusieurs composants et procédures d'analyse critiques. Il s'agit entre autres des pipelines de données, des requêtes et des applications d'entreprise qui sont nécessaires pour remplir les charges de travail de l'organisation.
- Entrepôt de données cloud (CDW)
- Un entrepôt de données qui présente les mêmes caractéristiques qu'un EDW, mais s'exécute sur un service entièrement géré dans le cloud, BigQuery dans le cas présent.
- Pipeline de données
- Un processus qui connecte les systèmes de données via une série de fonctions et de tâches qui effectuent divers types de transformations de données. Pour en savoir plus, reportez-vous à la section Qu'est-ce qu'un pipeline de données ? de cette série.
Pourquoi migrer vers BigQuery ?
Au cours des dernières décennies, les entreprises sont passées maîtres dans la science de l'entreposage de données. Elles ont de plus en plus recours à l'analyse descriptive pour traiter de grandes quantités de données stockées, ce qui leur permet de mieux comprendre leurs opérations commerciales. La veille stratégique conventionnelle (BI), qui se concentre sur l'interrogation des données, la génération de rapports et le traitement analytique en ligne, a peut-être été par le passé un facteur de différenciation pouvant contribuer grandement à l'essor ou à la chute d'une entreprise, mais cela n'est plus suffisant.
Désormais, non seulement les entreprises doivent comprendre les événements passés à l'aide d'analyses descriptives, mais elles ont également besoin d'analyses prédictives, qui se basent la plupart du temps sur le machine learning (ML) pour extraire des modèles de données et formuler des affirmations probabilistes concernant l'avenir. L'objectif est de développer une analyse prescriptive combinant les leçons du passé avec des prédictions sur l'avenir pour guider automatiquement les actions en temps réel.
Les entrepôts de données traditionnels sont conçus pour collecter des données provenant de diverses sources, lesquelles sont généralement des systèmes de traitement transactionnel en ligne (OLTP). Ensuite, par le biais d'opérations par lots, un sous-ensemble de données est extrait, transformé en fonction d'un schéma défini et, enfin, chargé dans l'entrepôt de données. Dans la mesure où les entrepôts de données traditionnels capturent un sous-ensemble de données par lots et stockent les données selon des schémas rigides, ils sont incapables de gérer une analyse en temps réel ou de répondre à des requêtes spontanées. Google a conçu BigQuery en partie pour répondre à ces limitations inhérentes aux entrepôts de données traditionnels.
Les idées innovantes sont souvent ralenties par la taille et la complexité de l'organisation informatique qui met en œuvre et entretient ces entrepôts de données traditionnels. Créer une architecture d'entrepôt de données évolutive, hautement disponible et sécurisée représente un investissement substantiel et peut prendre plusieurs années. BigQuery offre une technologie SaaS (Software as a service) sophistiquée qui peut être utilisée pour des opérations d'entrepôt de données sans serveur. Vous pouvez ainsi vous concentrer sur le développement de votre activité principale, tout en déléguant la maintenance de l'infrastructure et le développement de la plate-forme à Google Cloud.
BigQuery offre l'accès au stockage, au traitement et à l'analyse de données structurées sur une base évolutive, flexible et économique. Ces caractéristiques sont essentielles pour les clients lorsque les volumes de données croissent de manière exponentielle. Cela leur permet de disposer en toutes circonstances de ressources de stockage et de traitement adaptées à leurs besoins, et de dégager de la valeur à partir de ces données. En outre, pour les entreprises qui se lancent dans l'analyse big data et le machine learning et ne souhaitent pas avoir à gérer la potentielle complexité des systèmes big data sur site, BigQuery offre la possibilité d'expérimenter ces disciplines via des services gérés facturés à l'utilisation.
Avec BigQuery, vous pouvez trouver des solutions à des problèmes auparavant insolubles, vous appuyer sur le machine learning pour découvrir les modèles de données émergents et tester de nouvelles hypothèses. Vous obtenez ainsi une idée précise des performances de votre entreprise, ce qui vous permet de modifier certains processus afin d'obtenir de meilleurs résultats. De plus, l'expérience de l'utilisateur final est souvent enrichie d'informations pertinentes tirées de ces analyses big data, comme nous vous l'expliquerons dans la suite de cette série de documents.
Que faut-il migrer et comment procéder : le cadre de migration
Entreprendre une migration peut être une entreprise longue et complexe. Par conséquent, nous recommandons de définir et de respecter un cadre pour organiser et structurer le travail de migration en plusieurs phases :
- Préparer et découvrir : pour préparer la migration, identifiez les charges de travail et les cas d'utilisation.
- Planifier : hiérarchisez les cas d'utilisation, définissez des mesures de réussite et planifiez votre migration.
- Mettre en œuvre : Effectuez des itérations dans les étapes de migration, de l'évaluation à la validation.
Préparer et découvrir
Dans cette phase initiale, l'accent est mis sur la préparation et la découverte. Le but est ici de vous donner, à vous et aux personnes concernées, l'occasion d'identifier le plus tôt possible les cas d'utilisation existants, de soulever les préoccupations initiales et, surtout, d'effectuer une analyse initiale concernant les avantages attendus. Ces avantages incluent les gains de performances (par exemple, l'amélioration de la simultanéité), ainsi que les facteurs de réduction du coût total de possession (TCO). Cette phase est cruciale, car elle vous aidera à déterminer la valeur de la migration.
Un entrepôt de données accepte généralement une large gamme de cas d'utilisation et concerne un grand nombre de personnes, des analystes de données aux décisionnaires. Nous vous recommandons de faire participer activement les représentants de ces groupes afin d'assurer une bonne compréhension des cas d'utilisation existants, ainsi que pour déterminer si ces cas d'utilisation fonctionnent bien et si d'autres personnes planifient de nouveaux cas d'utilisation.
La phase de découverte comprend les tâches suivantes :
- Examiner la proposition de valeur de BigQuery et la comparer à celle de votre ancien entrepôt de données
- Effectuer une analyse initiale du coût total de possession
- Déterminer quels sont les cas d'utilisation affectés par la migration
- Modéliser les caractéristiques des ensembles de données et pipelines de données sous-jacents que vous souhaitez migrer afin d'identifier les dépendances
Pour obtenir des insights sur les cas d'utilisation, vous pouvez développer un questionnaire afin de recueillir des informations auprès de vos experts, des utilisateurs finaux et des autres personnes concernées. Ce questionnaire doit rassembler les réponses aux questions suivantes :
- Quel est l'objectif du cas d'utilisation ? Quelle est sa valeur métier ?
- Quelles sont les exigences d'ordre non fonctionnel (fraîcheur des données, utilisation simultanée, etc.) ?
- Le cas d'utilisation fait-il partie d'une charge de travail de dimension plus importante ? Dépend-il d'autres cas d'utilisation ?
- Quels ensembles de données, tables et schémas sous-tendent le cas d'utilisation ?
- Que savez-vous des pipelines de données qui alimentent ces ensembles de données ?
- Quels outils de veille stratégique, solutions de création de rapports et tableaux de bord sont utilisés à l'heure actuelle ?
- Quelles sont les exigences techniques actuelles en ce qui concerne les besoins opérationnels, les performances, l'authentification et la bande passante réseau ?
Le diagramme qui suit montre une vue d'ensemble de l'architecture avant la migration. Il illustre le catalogue des sources de données disponibles, des anciens pipelines de données, des anciens pipelines opérationnels, des anciennes boucles de rétroaction, ainsi que des anciens rapports et tableaux de bord de veille stratégique exploités par vos utilisateurs finaux.

Planifier
La phase de planification consiste à récupérer l'ensemble des informations recueillies lors de la phase de préparation et de découverte, à les évaluer, puis à les utiliser pour planifier la migration. Cette phase peut être divisée en plusieurs tâches :
Cataloguer et hiérarchiser les cas d'utilisation
Nous vous recommandons de décomposer votre processus de migration en itérations. Vous devez cataloguer les cas d'utilisation existants et nouveaux et leur attribuer une priorité. Pour en savoir plus, consultez les sections Effectuer la migration selon une approche itérative et Hiérarchiser les cas d'utilisation de ce document.
Définir des mesures de réussite
Il est utile de définir des mesures de réussite claires en prévision de la migration, par exemple des indicateurs clés de performance (KPI). Ces mesures vous permettront d'évaluer la réussite de la migration à chaque itération. Vous pourrez ainsi apporter des améliorations au processus de migration lors des itérations suivantes.
Créer une définition parfaitement claire de "terminé"
Avec les migrations complexes, il n'est pas forcément évident de déterminer à quel moment vous avez fini de migrer un cas d'utilisation donné. Par conséquent, vous devez développer une définition formelle de l'état final escompté. Cette définition doit être suffisamment générique pour pouvoir être appliquée à tous les cas d'utilisation que vous souhaitez migrer. Elle agit comme un ensemble de critères minimum, qui doivent tous être validés pour que le cas d'utilisation soit considéré comme migré. Une telle définition inclut généralement des points de contrôle permettant de s'assurer que le cas d'utilisation a été intégré, testé et documenté.
Concevoir et proposer une démonstration de faisabilité (POC) et définir l'état attendu à court terme ainsi que l'état terminal idéal
Une fois que vous avez hiérarchisé les cas d'utilisation, vous pouvez commencer à les prendre en considération pour l'ensemble de la période de migration. Considérez la migration du premier cas d'utilisation comme une démonstration de faisabilité (PoC) permettant de valider l'approche définie initialement pour la migration. Considérez ce qui est réalisable dans les premières semaines ou les premiers mois comme l'état à court terme. Quel impact peuvent avoir vos plans de migration sur vos utilisateurs ? Devront-ils utiliser temporairement une solution hybride, ou pouvez-vous migrer l'intégralité d'une charge de travail pour un sous-ensemble d'utilisateurs dans un premier temps ?
Créer des estimations de délais et de coût
Pour garantir le succès d'un projet de migration, il est important de produire des estimations réalistes en termes de délais. Pour ce faire, discutez avec toutes les personnes concernées de leur disponibilité et convenez de leur niveau d'engagement tout au long du projet. Cela vous permettra d'estimer les coûts de main-d'œuvre de façon plus précise. Pour estimer les coûts liés à la consommation de ressources cloud prévue, reportez-vous aux sections Estimer les coûts du stockage et des requêtes et Présentation du contrôle des coûts BigQuery de la documentation BigQuery.
Identifier et engager un partenaire de migration
La documentation BigQuery décrit de nombreux outils et ressources que vous pouvez utiliser pour effectuer la migration. Cependant, il peut s'avérer difficile de procéder vous-même à une migration massive et complexe si vous n'avez aucune expérience préalable ou si vous ne disposez pas de toutes les compétences techniques requises au sein de votre organisation. Par conséquent, nous vous recommandons d'identifier et d'engager dès le départ un partenaire de migration. Pour en savoir plus, reportez-vous aux articles concernant notre programme international de partenaires et nos services de conseil.
Effectuer la migration selon une approche itérative
Pour effectuer la migration d'une solution d'entreposage de données de grande taille vers le cloud, il est judicieux d'adopter une approche itérative. C'est pourquoi nous vous recommandons d'effectuer la transition vers BigQuery par le biais d'itérations. Diviser l'effort de migration en itérations facilite l'ensemble du processus et réduit les risques. Cela permet en outre de tirer des enseignements et d'apporter des améliorations après chaque itération.
Une itération représente l'ensemble des opérations nécessaires pour décharger ou migrer intégralement un ou plusieurs cas d'utilisation connexes dans un temps limité. On peut considérer une itération comme un cycle sprint (dans la méthodologie agile), qui consisterait en une ou plusieurs user stories (exigences utilisateurs).
Pour plus de commodité et de facilité de suivi, vous pouvez envisager d'associer un cas d'utilisation individuel à une ou plusieurs "user stories". Par exemple, considérons l'exigence utilisateur suivante : "En tant qu'analyste des prix, je souhaite analyser les variations du prix des produits au cours de la dernière année afin de pouvoir calculer les prix futurs."
Le cas d'utilisation correspondant pourrait être le suivant :
- Ingérer les données d'une base de données transactionnelle qui contient les références des produits et leurs prix
- Transformer les données en une seule série chronologique par produit et en imputer les valeurs manquantes.
- Stocker les résultats dans une ou plusieurs tables dans l'entrepôt de données
- Rendre les résultats disponibles via un notebook Python (l'application métier)
La valeur métier de ce cas d'utilisation provient du fait qu'il facilite l'analyse des prix.
Comme la plupart des cas d'utilisation, celui-ci permettra probablement de répondre à plusieurs exigences utilisateurs.
Dans le cas où vous déchargez un cas d'utilisation, vous devrez probablement procéder à sa migration complète lors d'une itération ultérieure. Si vous ne le faites pas, une dépendance subsiste vis-à-vis de l'ancien entrepôt de données, car les données sont copiées à partir de ce dernier. La migration complète ultérieure représente le delta (la différence) entre le déchargement et une migration complète qui n'a pas été précédée d'un déchargement. En d'autres termes, il s'agit de migrer le ou les pipelines de données afin d'extraire, de transformer et de charger les données dans l'entrepôt de données.
Hiérarchiser les cas d'utilisation
Là où vous commencez et là où vous terminez votre migration dépend de vos besoins spécifiques. Décider de l'ordre dans lequel vous allez migrer les cas d'utilisation est important. En effet, pour poursuivre votre parcours d'adoption du cloud, il est essentiel que vous réussissiez les premières étapes du processus de migration. Une défaillance survenant à un stade précoce peut représenter un obstacle sérieux pour l'ensemble de ce processus. Vous pouvez profiter des avantages deGoogle Cloud et de BigQuery, mais le traitement de tous les ensembles de données et les pipelines de données créés ou gérés dans votre ancien entrepôt de données pour différents cas d'utilisation peut s'avérer compliqué et chronophage.
Bien qu'il n'existe pas de solution unique, vous pouvez vous appuyer sur certaines bonnes pratiques lorsque vous évaluez vos cas d'utilisation et applications métier sur site. Ce type de planification en amont peut faciliter le processus de migration et permet une transition en douceur vers BigQuery.
Les sections suivantes présentent certaines approches envisageables pour établir l'ordre de priorité des cas d'utilisation.
Approche : exploiter les opportunités actuelles
Intéressez-vous aux opportunités existantes qui pourraient vous aider à optimiser le retour sur investissement d'un cas d'utilisation spécifique. Cette approche est particulièrement utile si vous subissez une pression pour justifier la valeur métier de la migration vers le cloud. Cela vous offre également la possibilité de rassembler des points de données supplémentaires qui vous aideront à évaluer le coût total de la migration.
Voici quelques exemples de questions à soulever qui vous aideront à identifier les cas d'utilisation que vous devez considérer comme prioritaires :
- Le cas d'utilisation est-il constitué d'ensembles de données ou de pipelines de données qui sont actuellement limités par l'ancien entrepôt de données d'entreprise ?
- Pensez-vous que vous aurez rapidement besoin de renouveler certains équipements matériels ou d'ajouter des équipements dans votre entrepôt de données d'entreprise existant ? Si tel est le cas, il peut être intéressant de décharger certains cas d'utilisation vers BigQuery le plus tôt possible.
Identifier des opportunités de migration permet d'avancer plus rapidement et produit des avantages tangibles et immédiats pour les utilisateurs et les entreprises.
Approche : migrer en premier lieu les charges de travail analytiques
Migrez les charges de travail de traitement analytique en ligne (OLAP, Online Analytical Processing) avant les charges de travail de traitement des transactions en ligne (OLTP, Online Transaction Processing). Un entrepôt de données est souvent le seul endroit de l'organisation où vous disposez de toutes les données pour créer une vue unique et globale des opérations de l'organisation. Par conséquent, il est courant que les entreprises disposent de pipelines de données qui alimentent les systèmes transactionnels pour mettre à jour des statuts ou déclencher des processus, par exemple pour acheter davantage de stock lorsque le stock d'un produit est faible. Les charges de travail OLTP ont tendance à être plus complexes et à être associées à des exigences opérationnelles et des contrats de niveau de service (SLA)) plus stricts que les charges de travail OLAP. Il est donc plus facile de migrer les charges de travail OLAP en premier.
Approche : se concentrer sur l'expérience utilisateur
Identifiez les possibilités d'amélioration de l'expérience utilisateur en migrant des ensembles de données spécifiques et en offrant aux utilisateurs de nouveaux types d'analyse avancée. Par exemple, l'analyse en temps réel est l'un des moyens d'améliorer l'expérience utilisateur. Vous pouvez créer des expériences utilisateur sophistiquées en vous basant sur un flux de données en temps réel combiné avec des données historiques. Exemple :
- Un employé de back-office qui reçoit sur son application mobile une alerte indiquant que le stock d'un produit est faible
- Un client en ligne qui est prévenu qu'en dépensant un dollar de plus, il accédera au niveau de récompense supérieur
- Une infirmière qui reçoit une alerte relative aux signes vitaux d'un patient sur sa montre connectée, ce qui lui permet de prendre les mesures qui s'imposent en extrayant l'historique de traitement du patient sur sa tablette
Vous pouvez également améliorer l'expérience utilisateur avec des analyses prédictives et normatives. Pour ce faire, vous pouvez utiliser BigQuery ML, Vertex AI AutoML Tabular ou les modèles pré-entraînés de Google pour l'analyse d'images, l'analyse vidéo, la reconnaissance vocale, le langage naturel et la traduction. Vous avez également la possibilité de diffuser votre modèle personnalisé à l'aide de Vertex AI pour des cas d'utilisation adaptés aux besoins de votre entreprise. Vous pourriez par exemple :
- Recommander un produit en fonction des tendances du marché et du comportement d'achat de l'utilisateur
- Prévoir qu'un vol sera retardé
- Détecter des activités frauduleuses
- Signaler un contenu inapproprié
- Exploiter toute autre idée innovante susceptibles de différencier votre application de la concurrence
Approche : donner la priorité aux cas d'utilisation les moins risqués
Plusieurs questions peuvent aider le service informatique à déterminer quels sont les cas d'utilisation dont la migration présente le risque le plus faible. En raison de ce risque limité, nous vous recommandons d'effectuer la migration de ces cas d'utilisation en premier. Exemple :
- Quelle est la criticité métier de ce cas d'utilisation ?
- Un grand nombre d'employés ou de clients dépendent-ils du cas d'utilisation ?
- Quel est l'environnement cible (par exemple, développement ou production) pour le cas d'utilisation ?
- Comment notre équipe informatique comprend-elle le cas d'utilisation ?
- Combien de dépendances et d'intégrations le cas d'utilisation compte-t-il ?
- Notre équipe informatique dispose-t-elle d'une documentation appropriée, à jour et exhaustive pour le cas d'utilisation ?
- Quelles sont les exigences opérationnelles (contrat SLA) pour le cas d'utilisation ?
- Quelles sont les exigences de conformité légales ou gouvernementales applicables au cas d'utilisation ?
- Quelle incidence peuvent avoir les temps d'arrêt et la latence sur l'accès à l'ensemble de données sous-jacent ?
- Certains responsables de services désirent-ils migrer leur cas d'utilisation plus tôt ?
Le fait de compiler les réponses aux questions présentées dans cette liste peut vous aider à classer les ensembles de données et pipelines de données en fonction du niveau de risque qu'ils présentent, du plus faible au plus élevé. Il est recommandé de migrer en premier lieu les éléments à faible risque. Ceux qui présentent le risque le plus élevé doivent être migrés plus tard.
Mettre en œuvre
Une fois que vous avez collecté des informations sur vos anciens systèmes et créé une liste hiérarchisée de cas d'utilisation, vous pouvez regrouper ces cas d'utilisation dans différentes charges de travail et poursuivre la migration par itérations.
Une itération peut être constituée d'un seul cas d'utilisation, de quelques cas d'utilisation distincts ou de plusieurs cas d'utilisation associés à une même charge de travail. Vous choisirez l'une ou l'autre de ces options en fonction de l'interconnectivité des cas d'utilisation, des dépendances partagées et des ressources dont vous disposez pour entreprendre le travail.
Une migration comporte généralement les étapes suivantes :
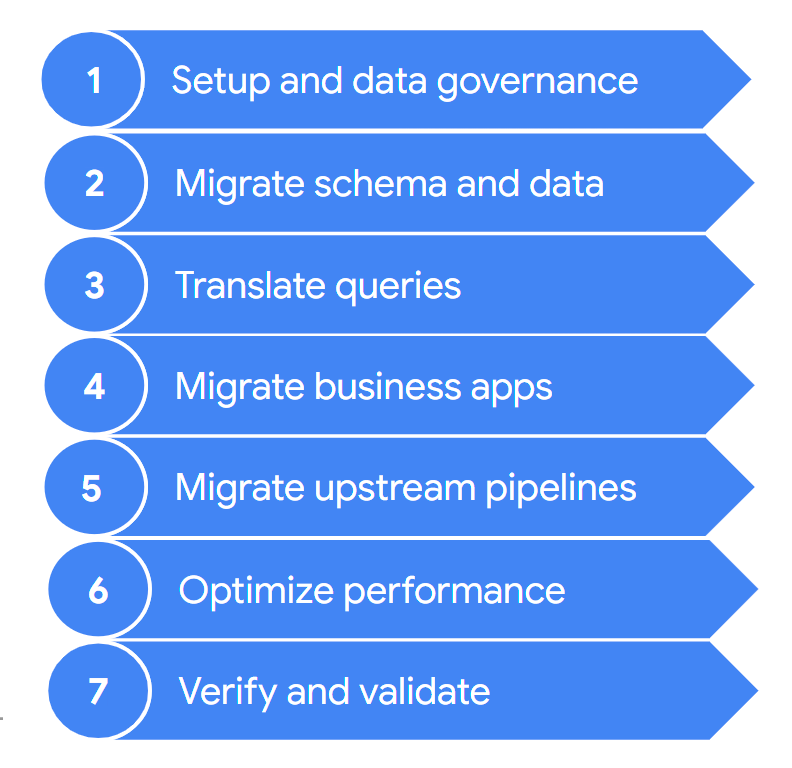
Ces étapes sont décrites plus en détail dans les sections suivantes. Vous n'aurez peut-être pas besoin de suivre toutes ces étapes à chaque itération. Par exemple, dans une itération, vous pouvez décider de vous concentrer sur la copie de certaines données de votre ancien entrepôt de données vers BigQuery. Lors d'une itération ultérieure, vous pourriez plutôt vous consacrer à la modification du pipeline d'ingestion d'une source de données d'origine afin qu'il pointe directement vers BigQuery.
1. Configurer et assurer la gouvernance des données
La configuration est la tâche de base nécessaire pour activer l'exécution des cas d'utilisation sur Google Cloud. La configuration peut inclure la configuration de vos projetsGoogle Cloud , de votre réseau, de votre cloud privé virtuel (VPC) et de la gouvernance des données. Elle implique également de développer une bonne compréhension de votre situation actuelle, à savoir ce qui fonctionne et ce qui ne fonctionne pas. Cela vous permet de comprendre les exigences et les besoins pour votre effort de migration. Vous pouvez utiliser la fonctionnalité d'évaluation de migration BigQuery pour vous aider lors de cette étape.
La gouvernance des données est une approche fondée sur des principes qui permet de gérer le cycle de vie des données de bout en bout, de l'acquisition à la suppression, en passant par leur utilisation. Votre programme de gouvernance des données doit clairement décrire les règles, procédures, responsabilités et contrôles qui régissent les activités relatives aux données. Ce programme permet de s'assurer que les informations sont collectées, conservées, utilisées et diffusées de manière à satisfaire à la fois l'intégrité des données et les besoins de votre organisation en termes de sécurité. En outre, il offre à vos employés la possibilité d'explorer et d'utiliser les données de manière optimale.
La documentation sur la gouvernance des données vous permet de comprendre ce concept et vous aide à déterminer les contrôles que vous devez mettre en œuvre lorsque vous choisissez de migrer vos entrepôts de données sur site vers BigQuery.
2. Migrer le schéma et les données
Le schéma de l'entrepôt de données définit la structure de vos données et les relations entre les différentes entités de données. Ce schéma est au cœur de la conception de vos données. Il influence de nombreux processus, en amont comme en aval.
La documentation concernant le Schéma et transfert de données fournit des informations détaillées sur le transfert de données vers BigQuery, ainsi que des recommandations sur la façon de mettre à jour votre schéma afin de profiter de tous les avantages des fonctionnalités de BigQuery.
3. Traduire les requêtes
Utilisez la traduction SQL par lot pour migrer votre code SQL de façon groupée, ou la traduction SQL interactive pour traduire des requêtes ad hoc.
Certains anciens entrepôts de données incluent des extensions de la norme SQL permettant d'activer les fonctionnalités de leur produit. BigQuery n'est pas compatible avec ces extensions propriétaires, mais conforme à la norme ANSI/ISO SQL 2011. Cela signifie que certaines requêtes peuvent toujours nécessiter une refactorisation manuelle si les traducteurs SQL ne peuvent pas les interpréter.
4. Migrer les applications métier
Les applications métier peuvent prendre de nombreuses formes, allant des tableaux de bord aux applications personnalisées, en passant par les pipelines de données opérationnels qui fournissent des boucles de rétroaction aux systèmes transactionnels.
Pour en savoir plus sur les options d'analyse lorsque vous utilisez BigQuery, consultez la page Présentation des analyses BigQuery. Cet article présente les outils de création de rapports et d'analyse que vous pouvez utiliser pour obtenir des insights de grande valeur à partir de vos données.
La section de la documentation "Pipeline de données" relative aux boucles de rétroaction explique comment vous pouvez utiliser un pipeline de données pour créer une boucle de rétroaction permettant d'alimenter les systèmes en amont.
5. Migrer les pipelines de données
La documentation sur les pipelines de données présente les procédures, les modèles et les technologies permettant de migrer vos anciens pipelines de données vers Google Cloud. Il vous aide à comprendre ce qu'est un pipeline de données, et à connaître les procédures et modèles qu'il peut employer. Il vous permet aussi d'identifier les options et technologies de migration disponibles par rapport à celles utilisées dans le cadre plus large de la migration d'un entrepôt de données.
6. Optimiser les performances
BigQuery traite efficacement les données de tous les ensembles de données, qu'ils soient de petite taille ou atteignent l'échelle du pétaoctet. Cet outil vous permet d'exécuter vos tâches d'analyse de données en toute fluidité, sans qu'aucune modification ne soit requise au niveau de votre entrepôt de données fraîchement migré. Si vous constatez que, dans certaines circonstances, les performances des requêtes ne correspondent pas à vos attentes, consultez la page Présentation de l'optimisation des performances des requêtes pour obtenir des conseils.
7. Vérifier et valider
À la fin de chaque itération, pour vous assurer que la migration des cas d'utilisation a réussi, vérifiez que :
- les données et le schéma ont été entièrement migrés ;
- les préoccupations relatives à la gouvernance des données ont été pleinement prises en compte et que les tests ont été concluants ;
- les procédures de maintenance et de surveillance ont été établies et automatisées ;
- les requêtes ont été correctement traduites ;
- les pipelines de données migrés fonctionnent comme prévu ;
- les applications métier sont correctement configurées pour accéder aux données et requêtes migrées.
Vous pouvez commencer à utiliser l'Outil de validation des données, un outil de CLI Python Open Source qui compare les données des environnements source et cible afin de s'assurer qu'elles correspondent. Elle est compatible avec plusieurs types de connexion et offre une fonctionnalité de validation à plusieurs niveaux.
Il est également judicieux de mesurer l'impact de la migration des cas d'utilisation, par exemple en termes d'amélioration des performances, de réduction des coûts ou de création de nouvelles opportunités techniques ou commerciales. Ainsi, vous pouvez quantifier avec plus de précision la valeur du retour sur investissement et la comparer à vos critères de réussite pour l'itération.
Une fois l'itération validée, vous pouvez basculer le cas d'utilisation migré en production et accorder à vos utilisateurs l'accès aux ensembles de données et applications métier migrés.
Enfin, prenez des notes et documentez les leçons tirées de cette itération afin de pouvoir appliquer ces enseignements à la prochaine itération et accélérer la migration.
Récapitulatif de l'effort de migration
Comme indiqué dans ce document, lors de la migration, vous exécutez à la fois votre ancien entrepôt de données et BigQuery. L'architecture de référence présentée dans le diagramme suivant montre que ces deux entrepôts de données offrent des fonctionnalités et des chemins d'accès semblables. Ils peuvent tous deux ingérer des données provenant des systèmes sources, s'intégrer aux applications métier et offrir l'accès utilisateur requis. Autre point important mis en lumière par le schéma, les données sont synchronisées entre votre entrepôt de données et BigQuery. Cela permet de décharger des cas d'utilisation pendant toute la durée de l'effort de migration.

Si votre intention est d'effectuer la migration complète de votre entrepôt de données vers BigQuery, l'état final de la migration doit ressembler à ce qui suit :

Étapes suivantes
Effectuez une migration BigQuery à l'aide des outils suivants :
- Exécutez une évaluation de la migration pour évaluer la faisabilité et les avantages potentiels de la migration de votre entrepôt de données vers BigQuery.
- Utilisez les outils de traduction SQL, tels que le traducteur SQL interactif, l'API de traduction et le traducteur SQL par lot, pour automatiser la conversion de vos requêtes SQL en GoogleSQL, y compris la personnalisation SQL optimisée par Gemini.
- Une fois que vous avez migré votre entrepôt de données vers BigQuery, exécutez l'outil de validation des données pour valider les données que vous venez de migrer.
Pour en savoir plus sur la migration d'entrepôts de données, consultez les ressources suivantes :
- Le Cloud Architecture Center fournit des ressources de migration pour planifier et exécuter votre migration vers Google Cloud.
- Découvrez comment migrer le schéma et les données de votre entrepôt de données.
- Découvrez comment migrer des pipelines de données depuis votre entrepôt de données.
- En savoir plus sur la gouvernance des données dans BigQuery
Collaborez avec l'équipe des services professionnels pour planifier et déployer votre migration Google Cloud . Pour en savoir plus, consultez Services professionnels Google Cloud.
Découvrez comment migrer des entrepôts de données spécifiques vers BigQuery :