Información general sobre la migración de almacenes de datos a BigQuery
En este documento se describen los conceptos generales que se aplican a cualquier tecnología de almacenamiento de datos y se explica un marco que puedes usar para organizar y estructurar tu migración a BigQuery.
Terminología
Usamos la siguiente terminología cuando hablamos de la migración de almacenes de datos:
- Caso práctico
-
Un caso práctico consta de todos los
conjuntos de datos, el procesamiento de datos y las interacciones del sistema y de los usuarios necesarios para
conseguir un valor empresarial, como monitorizar los volúmenes de ventas de un producto a lo largo del tiempo. En el almacenamiento de datos, el caso práctico suele consistir en lo siguiente:
- Pipelines de datos que ingieren datos sin procesar de varias fuentes de datos, como una base de datos de gestión de relaciones con clientes (CRM).
- Los datos almacenados en el almacén de datos.
- Secuencias de comandos y procedimientos para manipular, procesar y analizar los datos.
- Una aplicación empresarial que lee o interactúa con los datos.
- Carga de trabajo
-
Un conjunto de casos prácticos que están conectados y tienen dependencias compartidas. Por ejemplo, un caso práctico puede tener las siguientes relaciones y dependencias:
- Los informes de compras se pueden usar de forma independiente y son útiles para conocer los gastos y solicitar descuentos.
- Los informes de ventas se pueden usar de forma independiente y son útiles para planificar campañas de marketing.
- Sin embargo, los informes de pérdidas y ganancias dependen tanto de las compras como de las ventas, y son útiles para determinar el valor de la empresa.
- Aplicación empresarial
- Un sistema con el que interactúan los usuarios finales, como un informe visual o un panel de control. Una aplicación empresarial también puede adoptar la forma de una canalización de datos operativa o de un bucle de retroalimentación. Por ejemplo, después de calcular o predecir los cambios en los precios de los productos, una canalización de datos operativa podría actualizar los nuevos precios de los productos en una base de datos transaccional.
- Proceso de subida
- Los sistemas de origen y las canalizaciones de datos que cargan datos en el almacén de datos.
- Proceso de bajada
- Las secuencias de comandos, los procedimientos y las aplicaciones empresariales que se usan para procesar, consultar y visualizar los datos del almacén de datos.
- Migración de descarga
-
Una estrategia de migración que tiene como objetivo que el caso de uso funcione para el
usuario final en el nuevo entorno lo antes posible o aprovechar
la capacidad adicional disponible en el nuevo entorno. Los casos prácticos se descargan
de la siguiente manera:
- Copiar y, a continuación, sincronizar el esquema y los datos del almacén de datos antiguo.
- Migrar las secuencias de comandos, los procedimientos y las aplicaciones empresariales de nivel inferior.
La delegación de la migración puede aumentar la complejidad y el trabajo que conlleva migrar las canalizaciones de datos.
- Migración completa
- Un enfoque de migración similar a la migración de descarga, pero en lugar de copiar y sincronizar el esquema y los datos, se configura la migración para que ingiera datos directamente en el nuevo almacén de datos en la nube desde los sistemas de origen upstream. Es decir, también se migran las canalizaciones de datos necesarias para el caso práctico.
- Almacén de datos empresariales
- Un almacén de datos que no solo consta de una base de datos analítica, sino de varios componentes y procedimientos analíticos críticos. Entre ellos, se incluyen los flujos de procesamiento de datos, las consultas y las aplicaciones empresariales que se necesitan para completar las cargas de trabajo de la organización.
- Almacén de datos en la nube (CDW)
- Un almacén de datos que tiene las mismas características que un EDW, pero que se ejecuta en un servicio totalmente gestionado en la nube (en este caso, BigQuery).
- Flujo de procesamiento de datos
- Proceso que conecta sistemas de datos mediante una serie de funciones y tareas que realizan varios tipos de transformación de datos. Para obtener más información, consulta el artículo ¿Qué es una canalización de datos? de esta serie.
¿Por qué migrar a BigQuery?
En las últimas décadas, las organizaciones han dominado la ciencia del almacenamiento de datos. Han aplicado cada vez más analíticas descriptivas a grandes cantidades de datos almacenados, lo que les ha permitido obtener información valiosa sobre sus operaciones empresariales principales. La inteligencia empresarial (BI) convencional, que se centra en las consultas, los informes y el procesamiento analítico online, podría haber sido un factor diferenciador en el pasado, que podía determinar el éxito o el fracaso de una empresa, pero ya no es suficiente.
Hoy en día, las organizaciones no solo necesitan comprender los eventos pasados mediante el análisis descriptivo, sino que también necesitan el análisis predictivo, que suele usar el aprendizaje automático para extraer patrones de datos y hacer afirmaciones probabilísticas sobre el futuro. El objetivo final es desarrollar analíticas prescriptivas que combinen las lecciones del pasado con predicciones sobre el futuro para guiar automáticamente las acciones en tiempo real.
Las prácticas tradicionales de los almacenes de datos capturan datos sin procesar de varias fuentes, que a menudo son sistemas de procesamiento de transacciones online (OLTP). A continuación, se extrae un subconjunto de datos en lotes, se transforma según un esquema definido y se carga en el almacén de datos. Como los almacenes de datos tradicionales capturan un subconjunto de datos en lotes y almacenan datos a partir de esquemas rígidos, no son adecuados para gestionar análisis en tiempo real ni para responder a consultas espontáneas. Google diseñó BigQuery en parte para dar respuesta a estas limitaciones inherentes.
Las ideas innovadoras suelen verse frenadas por el tamaño y la complejidad de la organización de TI que implementa y mantiene estos almacenes de datos tradicionales. Se necesitan años y una inversión considerable para crear una arquitectura de almacén de datos escalable, de alta disponibilidad y segura. BigQuery ofrece una sofisticada tecnología de software como servicio (SaaS) que se puede usar para operaciones de almacén de datos sin servidor. De esta forma, puedes centrarte en el desarrollo de tu actividad principal y delegar el mantenimiento de la infraestructura y el desarrollo de la plataforma en Google Cloud.
BigQuery ofrece acceso a almacenamiento, procesamiento y analíticas de datos estructurados que son escalables, flexibles y rentables. Estas características son esenciales cuando los volúmenes de datos crecen de forma exponencial. De este modo, puede almacenar y procesar recursos disponibles según sus necesidades, así como obtener valor de dichos datos. Además, para las organizaciones que están empezando a usar las analíticas de Big Data y el aprendizaje automático, y que quieren evitar las posibles complejidades de los sistemas de Big Data locales, BigQuery ofrece una forma de pago por uso para experimentar con servicios gestionados.
Con BigQuery, puedes encontrar respuestas a problemas que antes eran irresolubles, aplicar el aprendizaje automático para descubrir patrones de datos emergentes y probar nuevas hipótesis. De esta forma, obtienes información valiosa sobre el rendimiento de tu empresa en el momento oportuno, lo que te permite modificar los procesos para conseguir mejores resultados. Además, la experiencia del usuario final suele enriquecerse con estadísticas relevantes obtenidas del análisis de Big Data, como explicaremos más adelante en esta serie.
Qué migrar y cómo hacerlo: el framework de migración
Llevar a cabo una migración puede ser una tarea compleja y larga. Por lo tanto, te recomendamos que sigas un marco para organizar y estructurar el trabajo de migración en fases:
- Preparación y detección: prepara tu migración con la detección de cargas de trabajo y casos prácticos.
- Planificación: prioriza los casos prácticos, define las medidas de éxito y planifica la migración.
- Ejecutar: sigue los pasos de la migración, desde la evaluación hasta la validación.
Preparar y descubrir
En la fase inicial, el objetivo es preparar y descubrir. Se trata de ofrecerte a ti y a las partes interesadas la oportunidad de descubrir los casos prácticos y plantear las primeras dudas. Es importante que también haga un análisis inicial de las ventajas esperadas. Entre ellas, se incluyen mejoras del rendimiento (por ejemplo, una mayor simultaneidad) y reducciones del coste total de propiedad (TCO). Esta fase es crucial para ayudarte a determinar el valor de la migración.
Un almacén de datos suele admitir una amplia gama de casos prácticos y tiene un gran número de partes interesadas, desde analistas de datos hasta responsables de la toma de decisiones empresariales. Te recomendamos que incluyas a representantes de estos grupos para que te ayuden a entender qué casos prácticos existen, si funcionan bien y si las partes interesadas tienen previsto implementar nuevos casos prácticos.
El proceso de la fase de descubrimiento consta de las siguientes tareas:
- Analiza la propuesta de valor de BigQuery y compárala con la de tu almacén de datos antiguo.
- Realiza un análisis inicial del TCO.
- Determina qué casos prácticos se ven afectados por la migración.
- Modeliza las características de los conjuntos de datos y las canalizaciones de datos subyacentes que quieras migrar para identificar las dependencias.
Para obtener información valiosa sobre los casos prácticos, puedes elaborar un cuestionario para recoger información de tus expertos en la materia, usuarios finales y partes interesadas. El cuestionario debe recoger la siguiente información:
- ¿Cuál es el objetivo del caso práctico? ¿Cuál es el valor empresarial?
- ¿Cuáles son los requisitos no funcionales? Actualización de datos, uso simultáneo, etc.
- ¿El caso práctico forma parte de una carga de trabajo mayor? ¿Depende de otros casos de uso?
- ¿Qué conjuntos de datos, tablas y esquemas sustentan el caso práctico?
- ¿Qué sabes sobre los flujos de datos que se introducen en esos conjuntos de datos?
- ¿Qué herramientas, informes y paneles de control de BI se usan actualmente?
- ¿Cuáles son los requisitos técnicos actuales en cuanto a necesidades operativas, rendimiento, autenticación y ancho de banda de la red?
En el siguiente diagrama se muestra una arquitectura antigua de alto nivel antes de la migración. En él se muestra el catálogo de fuentes de datos disponibles, las antiguas canalizaciones de datos, las antiguas canalizaciones operativas y los bucles de retroalimentación, así como los antiguos informes y paneles de control de BI a los que acceden los usuarios finales.

Plan
En la fase de planificación, se toman los datos de la fase de preparación y descubrimiento, se evalúan y se usan para planificar la migración. Esta fase se puede dividir en las siguientes tareas:
Catalogar y priorizar casos prácticos
Te recomendamos que dividas el proceso de migración en iteraciones. Catalogas los casos prácticos actuales y los nuevos, y les asignas una prioridad. Para obtener más información, consulta las secciones Migrar con un enfoque iterativo y Priorizar los casos prácticos de este documento.
Define medidas de éxito
Es útil definir medidas de éxito claras, como los indicadores clave de rendimiento (KPIs), antes de la migración. Las medidas te permitirán evaluar el éxito de la migración en cada iteración. Esto, a su vez, te permite mejorar el proceso de migración en iteraciones posteriores.
Crea una definición de "hecho"
En las migraciones complejas, no siempre es evidente cuándo se ha completado la migración de un caso práctico concreto. Por lo tanto, debes definir formalmente el estado final que quieres conseguir. Esta definición debe ser lo suficientemente genérica para que se pueda aplicar a todos los casos prácticos que quieras migrar. La definición debe actuar como un conjunto de criterios mínimos para que consideres que el caso práctico se ha migrado por completo. Esta definición suele incluir puntos de control para asegurarse de que el caso práctico se ha integrado, probado y documentado.
Diseñar y proponer una prueba de concepto, un estado a corto plazo y un estado final ideal
Una vez que hayas priorizado tus casos prácticos, puedes empezar a pensar en ellos durante todo el periodo de la migración. Considera la primera migración de caso práctico como prueba de concepto para validar el enfoque inicial de la migración. Piensa en lo que se puede conseguir en las primeras semanas o meses, que sería el estado a corto plazo. ¿Cómo afectarán tus planes de migración a tus usuarios? ¿Tendrá una solución híbrida o podrá migrar una carga de trabajo completa para un subconjunto de usuarios primero?
Crear estimaciones de tiempo y costes
Para que un proyecto de migración tenga éxito, es importante hacer estimaciones de tiempo realistas. Para ello, habla con todas las partes interesadas pertinentes para saber su disponibilidad y acordar su nivel de participación a lo largo del proyecto. Esto le ayudará a estimar los costes de mano de obra con mayor precisión. Para estimar los costes relacionados con el consumo previsto de recursos en la nube, consulta los artículos Estimación de los costes de almacenamiento y de las consultas y Introducción al control de los costes de BigQuery en la documentación de BigQuery.
Identificar y colaborar con un partner de migración
En la documentación de BigQuery se describen muchas herramientas y recursos que puedes usar para llevar a cabo la migración. Sin embargo, puede ser difícil llevar a cabo una migración grande y compleja por tu cuenta si no tienes experiencia o no cuentas con todos los conocimientos técnicos necesarios en tu organización. Por lo tanto, te recomendamos que identifiques y colabores con un partner de migración desde el principio. Para obtener más información, consulta nuestros programas de partners globales y servicios de consultoría.
Migrar con un enfoque iterativo
Cuando se migra una operación de almacenamiento de datos de gran tamaño a la nube, es recomendable adoptar un enfoque iterativo. Por lo tanto, te recomendamos que hagas la transición a BigQuery en varias fases. Dividir el esfuerzo de migración en iteraciones facilita el proceso general, reduce los riesgos y ofrece oportunidades para aprender y mejorar después de cada iteración.
Una iteración consta de todo el trabajo necesario para transferir o migrar por completo uno o varios casos prácticos relacionados en un periodo de tiempo determinado. Una iteración es un ciclo de sprint de la metodología ágil que consta de una o varias historias de usuario.
Para que sea más cómodo y fácil de monitorizar, puedes asociar un caso de uso concreto a uno o varios testimonios de usuarios. Por ejemplo, considera la siguiente historia de usuario: "Como analista de precios, quiero analizar los cambios de precio de los productos durante el último año para poder calcular los precios futuros".
El caso práctico correspondiente podría ser el siguiente:
- Ingerir los datos de una base de datos transaccional que almacena productos y precios.
- Transformar los datos en una sola serie temporal para cada producto e introducir los valores que falten.
- Almacenar los resultados en una o varias tablas del almacén de datos.
- Poner los resultados a disposición a través de un cuaderno de Python (la aplicación empresarial).
El valor empresarial de este caso práctico es facilitar el análisis de precios.
Como en la mayoría de los casos prácticos, este probablemente admitirá varias historias de usuario.
Es probable que un caso práctico derivado vaya seguido de una iteración posterior para migrarlo por completo. De lo contrario, es posible que sigas dependiendo del antiguo almacén de datos, ya que los datos se copian de ahí. La migración completa posterior es la diferencia entre la descarga y una migración completa que no ha ido precedida de una descarga. En otras palabras, es la migración de las canalizaciones de datos para extraer, transformar y cargar los datos en el almacén de datos.
Priorizar casos prácticos
El punto de inicio y el de finalización de la migración dependen de las necesidades específicas de tu empresa. Decidir el orden en el que migras los casos prácticos es importante porque el éxito inicial durante una migración es crucial para continuar en tu camino hacia la adopción de la nube. Si se produce un error en una fase inicial, puede suponer un grave revés para el proceso de migración en general. Puede que estés de acuerdo con las ventajas deGoogle Cloud y BigQuery, pero procesar todos los conjuntos de datos y las canalizaciones de datos que se han creado o gestionado en tu antiguo almacén de datos para diferentes casos prácticos puede ser complicado y llevar mucho tiempo.
Aunque no hay una respuesta única, hay prácticas recomendadas que puedes seguir al evaluar tus casos prácticos y aplicaciones empresariales locales. Este tipo de planificación inicial puede facilitar el proceso de migración y hacer que toda la transición a BigQuery sea más fluida.
En las siguientes secciones se analizan posibles enfoques para priorizar los casos prácticos.
Estrategia: aprovechar las oportunidades actuales
Busca oportunidades actuales que puedan ayudarte a maximizar el retorno de la inversión de un caso práctico específico. Esta estrategia es especialmente útil si tienes que justificar el valor empresarial de la migración a la nube. También ofrece la oportunidad de recoger puntos de datos adicionales para ayudar a evaluar el coste total de la migración.
Aquí tienes algunas preguntas de ejemplo que puedes hacer para identificar qué casos prácticos debes priorizar:
- ¿El caso práctico consta de conjuntos de datos o de canalizaciones de datos que están limitados por el antiguo almacén de datos empresarial?
- ¿Tu almacén de datos empresarial requiere una actualización de hardware o prevés que necesitarás ampliarlo? En ese caso, puede ser interesante transferir los casos prácticos a BigQuery cuanto antes.
Identificar oportunidades de migración puede generar resultados rápidos que aporten beneficios tangibles e inmediatos a los usuarios y a la empresa.
Estrategia: migrar primero las cargas de trabajo analíticas
Migra las cargas de trabajo de procesamiento analítico online (OLAP) antes que las cargas de trabajo de procesamiento de transacciones online(OLTP). Un almacén de datos suele ser el único lugar de la organización donde se encuentran todos los datos necesarios para crear una vista global de las operaciones de la organización. Por lo tanto, es habitual que las organizaciones tengan algunas canalizaciones de datos que se retroalimentan en los sistemas transaccionales para actualizar el estado o activar procesos. Por ejemplo, para comprar más stock cuando el inventario de un producto es bajo. Las cargas de trabajo de procesamiento de transacciones online (OLTP) suelen ser más complejas y tienen requisitos operativos más estrictos y acuerdos de nivel de servicio (SLAs) que las cargas de trabajo de procesamiento analítico online (OLAP), por lo que suele ser más fácil migrar primero las cargas de trabajo de OLAP.
Enfoque: centrarse en la experiencia del usuario
Identificar oportunidades para mejorar la experiencia de usuario migrando conjuntos de datos específicos y habilitando nuevos tipos de analíticas avanzadas. Por ejemplo, una forma de mejorar la experiencia de usuario es con las analíticas en tiempo real. Puedes crear experiencias de usuario sofisticadas en torno a un flujo de datos en tiempo real cuando se combina con datos históricos. Por ejemplo:
- Un empleado de la oficina recibe una alerta en su aplicación móvil sobre el bajo nivel de existencias.
- Un cliente online al que le vendría bien saber que, si gasta un dólar más, pasará al siguiente nivel de recompensa.
- Una enfermera recibe una alerta sobre las constantes vitales de un paciente en su smartwatch, lo que le permite tomar las medidas más adecuadas consultando el historial de tratamiento del paciente en su tablet.
También puedes mejorar la experiencia de usuario con analíticas predictivas y prescriptivas. Para ello, puedes usar BigQuery ML, Vertex AI AutoML tabular o los modelos preentrenados de Google para análisis de imágenes, análisis de vídeo, reconocimiento de voz, lenguaje natural y traducción. También puedes servir tu modelo entrenado de forma personalizada con Vertex AI para casos prácticos adaptados a las necesidades de tu empresa. Esto puede implicar lo siguiente:
- Recomendar un producto en función de las tendencias del mercado y del comportamiento de compra de los usuarios.
- Predecir un retraso de un vuelo.
- Detectar actividades fraudulentas.
- Denunciar contenido inapropiado.
- Otras ideas innovadoras que podrían diferenciar tu aplicación de la competencia.
Estrategia: priorizar los casos prácticos menos arriesgados
El departamento de TI puede hacer varias preguntas para evaluar qué casos prácticos son los que conllevan menos riesgos al migrarlos, lo que los convierte en los más atractivos para migrar en las primeras fases de la migración. Por ejemplo:
- ¿Cuál es la importancia de este caso práctico para la empresa?
- ¿Depende del caso práctico un gran número de empleados o clientes?
- ¿Cuál es el entorno de destino (por ejemplo, desarrollo o producción) del caso práctico?
- ¿Qué entiende nuestro equipo de TI sobre el caso práctico?
- ¿Cuántas dependencias e integraciones tiene el caso práctico?
- ¿Nuestro equipo de TI tiene documentación adecuada, actualizada y completa para el caso práctico?
- ¿Cuáles son los requisitos operativos (SLAs) del caso práctico?
- ¿Cuáles son los requisitos de cumplimiento legales o gubernamentales del caso práctico?
- ¿Cuáles son los tiempos de inactividad y las sensibilidades de latencia para acceder al conjunto de datos subyacente?
- ¿Hay propietarios de líneas de negocio que estén dispuestos a migrar su caso de uso pronto?
Repasar esta lista de preguntas puede ayudarte a clasificar los conjuntos de datos y las canalizaciones de datos de menor a mayor riesgo. Los recursos de bajo riesgo deben migrarse primero y los de mayor riesgo, después.
Ejecutar
Una vez que hayas recopilado información sobre tus sistemas antiguos y hayas creado una lista de casos prácticos priorizada, puedes agrupar los casos prácticos en cargas de trabajo y proceder con la migración en iteraciones.
Una iteración puede constar de un solo caso práctico, de varios casos prácticos independientes o de varios casos prácticos relacionados con una sola carga de trabajo. La opción que elijas para la iteración dependerá de la interconectividad de los casos prácticos, de las dependencias compartidas y de los recursos que tengas disponibles para llevar a cabo el trabajo.
Una migración suele incluir los siguientes pasos:
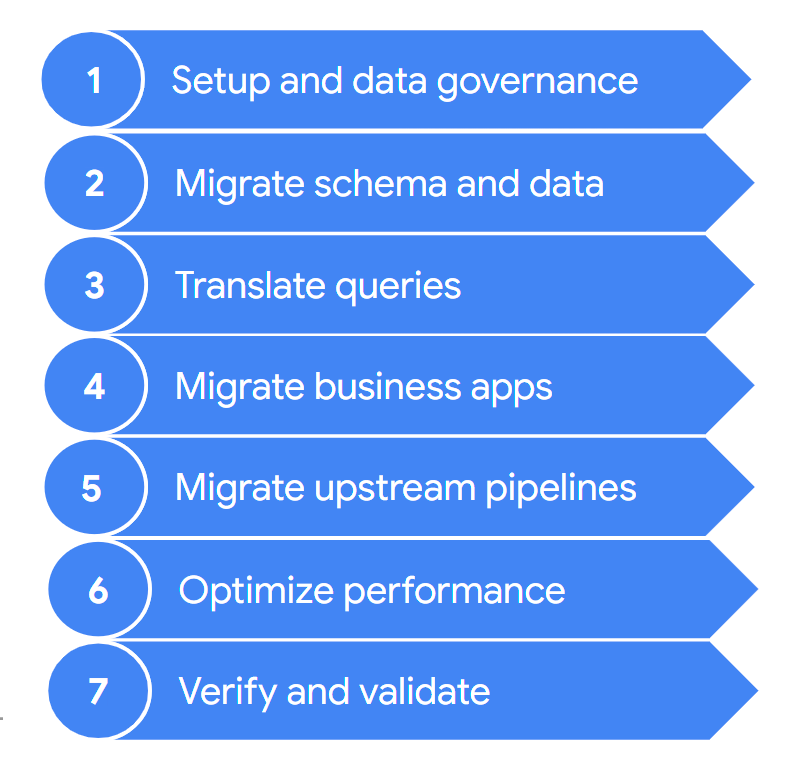
Estos pasos se describen con más detalle en las siguientes secciones. Puede que no tengas que seguir todos estos pasos en cada iteración. Por ejemplo, en una iteración, puedes decidir centrarte en copiar algunos datos de tu almacén de datos antiguo a BigQuery. Por el contrario, en una iteración posterior, puedes centrarte en modificar el flujo de procesamiento de ingestión de una fuente de datos original directamente a BigQuery.
1. Configuración y gobierno de datos
La configuración es el trabajo fundamental que se necesita para que los casos prácticos se puedan ejecutar en Google Cloud. La configuración puede incluir la de tusGoogle Cloud proyectos, red, nube privada virtual (VPC) y gobernanza de datos. También incluye el desarrollo de una buena comprensión de dónde te encuentras hoy en día: qué funciona y qué no. Esto te ayudará a entender los requisitos de tu migración. Puedes usar la función de evaluación de la migración de BigQuery para ayudarte con este paso.
El gobierno de datos es un enfoque riguroso para gestionar los datos durante su ciclo de vida, desde la adquisición hasta la eliminación, pasando por el uso. Tu programa de gobierno de datos debe definir claramente las políticas, los procedimientos, las responsabilidades y los controles relacionados con las actividades de datos. Este programa ayuda a asegurar que la información se recoja, mantenga, use y difunda de forma que se cumplan tanto la integridad de los datos como las necesidades de seguridad de tu organización. También ayuda a tus empleados a descubrir y usar los datos con todo su potencial.
La documentación sobre gobierno de datos te ayuda a entender el gobierno de datos y los controles que necesitas al migrar tu almacén de datos on-premise a BigQuery.
2. Migrar esquemas y datos
El esquema del almacén de datos define cómo se estructuran los datos y las relaciones entre las entidades de datos. El esquema es el elemento central del diseño de tus datos e influye en muchos procesos, tanto anteriores como posteriores.
En la documentación sobre la transferencia de esquemas y datos, se explica detalladamente cómo puede mover sus datos a BigQuery y se ofrecen recomendaciones para actualizar su esquema y aprovechar al máximo las funciones de BigQuery.
3. Traducir consultas
Usa la traducción de SQL por lotes para migrar tu código SQL en bloque o la traducción de SQL interactiva para traducir consultas puntuales.
Algunos almacenes de datos antiguos incluyen extensiones del estándar SQL para habilitar funciones de su producto. BigQuery no admite estas extensiones propietarias, sino que se ajusta al estándar ANSI/ISO SQL:2011. Esto significa que es posible que algunas de tus consultas aún necesiten refactorización manual si los traductores de SQL no pueden interpretarlas.
4. Migrar aplicaciones empresariales
Las aplicaciones empresariales pueden adoptar muchas formas, desde paneles de control hasta aplicaciones personalizadas o pipelines de datos operativos que proporcionan bucles de retroalimentación a los sistemas transaccionales.
Para obtener más información sobre las opciones de analíticas al trabajar con BigQuery, consulta el artículo Descripción general de las analíticas de BigQuery. En este tema se ofrece una descripción general de las herramientas de informes y análisis que puede usar para obtener estadísticas valiosas a partir de sus datos.
En la sección sobre bucles de retroalimentación de la documentación de la canalización de datos se describe cómo puedes usar una canalización de datos para crear un bucle de retroalimentación que aprovisione sistemas upstream.
5. Migrar flujos de procesamiento de datos
En la documentación sobre flujos de procesamiento de datos se describen los procedimientos, los patrones y las tecnologías para migrar tus flujos de procesamiento de datos antiguos a Google Cloud. Te ayuda a entender qué es una canalización de datos, qué procedimientos y patrones puede emplear, y qué opciones y tecnologías de migración están disponibles en relación con la migración de almacén de datos a mayor escala.
6. Optimización del rendimiento
BigQuery procesa los datos de forma eficiente tanto en conjuntos de datos pequeños como en conjuntos de datos de petabytes. Con la ayuda de BigQuery, tus trabajos de analíticas de datos deberían funcionar correctamente sin necesidad de hacer modificaciones en el almacén de datos recién migrado. Si observas que, en determinadas circunstancias, el rendimiento de las consultas no se ajusta a tus expectativas, consulta la introducción a la optimización del rendimiento de las consultas para obtener más información.
7. Verificar y validar
Al final de cada iteración, valida que la migración del caso de uso se ha completado correctamente. Para ello, comprueba lo siguiente:
- Los datos y el esquema se han migrado por completo.
- Las preocupaciones sobre el gobierno de datos se han abordado y probado por completo.
- Se han establecido procedimientos de mantenimiento y monitorización, así como automatización.
- Las consultas se han traducido correctamente.
- Los flujos de procesamiento de datos migrados funcionan correctamente.
- Las aplicaciones empresariales están configuradas correctamente para acceder a los datos y las consultas migrados.
Puedes empezar a usar la herramienta de validación de datos, una herramienta de CLI de Python de código abierto que compara los datos de los entornos de origen y de destino para asegurarse de que coinciden. Admite varios tipos de conexión, así como una función de validación multinivel.
También es recomendable medir el impacto de la migración de los casos prácticos, por ejemplo, en términos de mejora del rendimiento, reducción de costes o habilitación de nuevas oportunidades técnicas o empresariales. De esta forma, podrás cuantificar con mayor precisión el valor del retorno de la inversión y compararlo con los criterios de éxito de la iteración.
Una vez que se haya validado la iteración, puedes lanzar el caso de uso migrado a producción y dar acceso a tus usuarios a los conjuntos de datos y las aplicaciones empresariales migrados.
Por último, toma notas y documenta las lecciones aprendidas de esta iteración para poder aplicarlas en la siguiente y acelerar la migración.
Resumen del esfuerzo de migración
Durante la migración, ejecutas tanto tu antiguo almacén de datos como BigQuery, tal como se detalla en este documento. La arquitectura de referencia del siguiente diagrama destaca que ambos almacenes de datos ofrecen funciones y rutas similares: ambos pueden ingerir datos de los sistemas de origen, integrarse con las aplicaciones empresariales y proporcionar el acceso de usuario necesario. Es importante destacar que el diagrama también muestra que los datos se sincronizan desde tu almacén de datos con BigQuery. Esto permite que los casos prácticos se descarguen durante toda la duración del esfuerzo de migración.

Si tu intención es migrar por completo tu almacén de datos a BigQuery, el estado final de la migración será el siguiente:

Siguientes pasos
Realiza una migración a BigQuery con las siguientes herramientas:
- Realiza una evaluación de la migración para determinar la viabilidad y las ventajas potenciales de migrar tu almacén de datos a BigQuery.
- Usa las herramientas de traducción de SQL, como el traductor interactivo de SQL, la API Translation y el traductor de SQL por lotes, para automatizar la conversión de tus consultas de SQL a GoogleSQL, incluida la personalización de SQL mejorada con Gemini.
- Una vez que haya migrado su almacén de datos a BigQuery, ejecute la herramienta de validación de datos para validar los datos recién migrados.
Consulta los siguientes recursos para obtener más información sobre la migración de un almacén de datos:
- El centro de arquitectura en la nube ofrece recursos de migración para planificar y llevar a cabo tu migración a Google Cloud
- Consulta cómo migrar esquemas y datos desde tu almacén de datos.
- Consulta cómo migrar flujos de procesamiento de datos desde tu almacén de datos.
- Consulta información sobre el gobierno de datos en BigQuery.
Colabora con el equipo de Servicios Profesionales para planificar y llevar a cabo tu Google Cloud migración. Para obtener más información, consulta Servicios profesionales de Google Cloud.
Consulta información sobre cómo migrar de almacenes de datos específicos a BigQuery: