테이블 데이터 관리
이 문서에서는 BigQuery에서 테이블 데이터를 관리하는 방법을 설명합니다. BigQuery 테이블 데이터에 할 수 있는 작업은 다음과 같습니다.
- 테이블에 데이터 로드
- 테이블에 데이터 추가 또는 테이블 데이터 덮어쓰기
- 테이블 데이터 찾아보기(또는 미리보기)
- 테이블 데이터 쿼리
- 데이터 조작 언어(DML)를 사용하여 테이블 데이터 수정
- 테이블 데이터 복사
- 테이블 데이터 내보내기
테이블 스키마 관리에 대한 자세한 내용은 테이블 스키마 수정을 참조하세요.
시작하기 전에
이 문서의 각 작업을 수행해야 하는 사용자에게 필요한 권한을 주는 역할을 부여하세요. 작업을 수행하는 데 필요한 권한(있는 경우)은 작업의 '필수 권한' 섹션에 나열되어 있습니다.
테이블에 데이터 로드
테이블을 만들 때 데이터를 로드하거나, 빈 테이블을 만든 후 나중에 데이터를 로드할 수 있습니다. 데이터를 로드할 때는 지원되는 데이터 형식에 스키마 자동 감지를 사용하거나 스키마를 직접 지정할 수 있습니다.
데이터 로드에 자세한 내용은 소스 데이터 형식 및 위치에 대한 문서를 참조하세요.
Cloud Storage에서 데이터를 로드하는 방법에 대한 자세한 내용은 다음을 참조하세요.
로컬 소스에서 데이터를 로드하는 방법에 대한 자세한 내용은 로컬 파일에서 데이터 로드를 참조하세요.
테이블 데이터 추가 및 덮어쓰기
로드 또는 쿼리 작업을 수행하여 테이블 데이터를 덮어쓸 수 있습니다. 로드-추가 작업을 수행하거나 쿼리 결과를 테이블에 추가하여 기존 테이블에 데이터를 추가할 수도 있습니다.
데이터를 로드할 때 테이블 데이터를 추가하거나 덮어쓰는 자세한 방법은 소스 데이터 형식에 대한 다음 문서를 참조하세요.
- 테이블에 Avro 데이터 추가 또는 덮어쓰기
- 테이블에 CSV 데이터 추가 또는 덮어쓰기
- 테이블에 JSON 데이터 추가 또는 덮어쓰기
- 테이블에 Parquet 데이터 추가 또는 덮어쓰기
- 테이블에 ORC 데이터 추가 또는 덮어쓰기
- Datastore 데이터로 테이블 추가 또는 덮어쓰기
쿼리 결과를 사용하여 테이블에 데이터를 추가하거나 테이블을 덮어쓰려면 대상 테이블을 지정하고 쓰기 처리를 다음 중 하나로 설정합니다.
- 테이블에 추가 - 쿼리 결과를 기존 테이블에 추가합니다.
- 테이블 덮어쓰기 - 쿼리 결과를 사용하여 이름이 같은 기존 테이블을 덮어씁니다.
다음 쿼리를 사용하여 한 테이블의 레코드를 다른 테이블에 추가할 수 있습니다.
INSERT INTO <projectID>.<datasetID>.<table1> ( <column2>, <column3>) (SELECT * FROM <projectID>.<datasetID>.<table2>)
쿼리 결과를 사용한 데이터 추가 또는 덮어쓰기에 대한 자세한 내용은 쿼리 결과 쓰기를 참조하세요.
테이블 데이터 찾아보기
다음과 같은 방법으로 테이블 데이터를 찾아보거나 읽을 수 있습니다.
- Google Cloud 콘솔 사용
- bq 명령줄 도구의
bq head명령어 사용 tabledata.listAPI 메서드 호출- 클라이언트 라이브러리 사용
필수 권한
테이블 및 파티션 데이터를 읽으려면 bigquery.tables.getData Identity and Access Management(IAM) 권한이 필요합니다.
다음과 같은 사전 정의된 각 IAM 역할에는 테이블 및 파티션 데이터를 탐색하는 데 필요한 권한이 포함되어 있습니다.
roles/bigquery.dataViewerroles/bigquery.dataEditorroles/bigquery.dataOwnerroles/bigquery.admin
bigquery.datasets.create 권한이 있는 경우 사용자가 만든 데이터 세트의 테이블 및 파티션에서 데이터를 찾아볼 수 있습니다.
BigQuery의 IAM 역할과 권한에 대한 자세한 내용은 사전 정의된 역할 및 권한을 참조하세요.
테이블 데이터 찾아보기
테이블 데이터를 찾아보려면 다음 안내를 따르세요.
콘솔
Google Cloud 콘솔에서 BigQuery 페이지를 엽니다.
탐색기 패널에서 프로젝트를 확장하고 데이터 세트를 선택합니다.
목록에서 테이블을 클릭합니다.
세부정보를 클릭하고 행 개수 값을 확인합니다. bq 명령줄 도구 또는 API를 사용하여 결과의 시작점을 제어하려면 이 값이 필요할 수 있습니다.
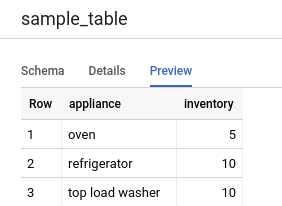
미리보기를 클릭합니다. 샘플 데이터 세트가 표시됩니다.
명령줄
특정 수의 테이블 행에 있는 모든 열을 나열하려면 bq head 명령어를 --max_rows 플래그와 함께 실행합니다. --max_rows를 지정하지 않으면 기본값은 100입니다.
테이블의 일부 열(중첩 열 및 반복 열 포함)을 찾아보려면 --selected_fields 플래그를 사용하고 열을 쉼표로 구분된 목록으로 입력합니다.
테이블 데이터를 표시하기 전에 건너뛸 행 수를 지정하려면 --start_row=integer 플래그(또는 -s 단축키)를 사용합니다. 기본값은 0입니다. bq show 명령어로 테이블 정보를 검색하여 테이블의 행 수를 검색할 수 있습니다.
찾아볼 테이블이 기본 프로젝트가 아닌 다른 프로젝트에 있으면 프로젝트 ID를 project_id:dataset.table 형식으로 명령어에 추가합니다.
bq head \ --max_rows integer1 \ --start_row integer2 \ --selected_fields "columns" \ project_id:dataset.table
각 항목의 의미는 다음과 같습니다.
- integer1은 표시할 행 수입니다.
- integer2는 데이터를 표시하기 전에 건너뛸 행 수입니다.
- columns는 쉼표로 구분된 열 목록입니다.
- project_id는 프로젝트 ID입니다.
- dataset는 테이블이 포함된 데이터 세트 이름입니다.
- table은 찾아볼 테이블 이름입니다.
예시:
mydataset.mytable에서 처음 10행의 모든 열을 나열하려면 다음 명령어를 입력합니다. 여기서 mydataset는 기본 프로젝트에 있습니다.
bq head --max_rows=10 mydataset.mytable
mydataset.mytable에서 처음 100행의 모든 열을 나열하려면 다음 명령어를 입력합니다. 여기서 mydataset는 기본 프로젝트가 아닌 myotherproject에 있습니다.
bq head myotherproject:mydataset.mytable
mydataset.mytable에 field1 및 field2만 표시하려면 다음 명령어를 입력합니다. 이 명령어에서 --start_row 플래그를 사용하면 100번째 행으로 건너뜁니다.
여기서 mydataset.mytable은 기본 프로젝트에 있습니다.
bq head --start_row 100 --selected_fields "field1,field2" mydataset.mytable
bq head 명령어는 쿼리 작업을 만들지 않으므로 bq head 명령어는 쿼리 기록에 나타나지 않고 비용이 청구되지 않습니다.
API
tabledata.list를 호출하여 테이블의 데이터를 찾아볼 수 있습니다.
tableId 매개변수에 테이블 이름을 지정하세요.
다음과 같은 선택적 매개변수를 구성하여 출력을 제어할 수 있습니다.
maxResults— 반환할 결과의 최대 수입니다.selectedFields— 반환할 필드를 쉼표로 구분한 목록입니다. 지정하지 않으면 모든 열이 반환됩니다.startIndex— 읽기를 시작할 행의 0부터 시작하는 색인입니다.
반환되는 값은 JSON 객체에 래핑되므로 tabledata.list 참조 문서의 설명에 따라 객체를 파싱해야 합니다.
C#
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 C# 설정 안내를 따르세요. 자세한 내용은 BigQuery C# API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Go
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Go 설정 안내를 따르세요. 자세한 내용은 BigQuery Go API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Go용 Cloud 클라이언트 라이브러리는 기본적으로 자동 페이지 나누기를 수행하므로 사용자가 직접 페이지 나누기를 구현할 필요가 없습니다. 예를 들면 다음과 같습니다.
Java
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Java 설정 안내를 따르세요. 자세한 내용은 BigQuery Java API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Node.js
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Node.js 설정 안내를 따르세요. 자세한 내용은 BigQuery Node.js API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Node.js용 Cloud 클라이언트 라이브러리는 기본적으로 자동 페이지 나누기를 수행하므로 사용자가 직접 페이지 나누기를 구현할 필요가 없습니다. 예를 들면 다음과 같습니다.
PHP
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 PHP 설정 안내를 따르세요. 자세한 내용은 BigQuery PHP API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
PHP용 Cloud 클라이언트 라이브러리에서는 생성기 함수 rows를 사용하여 페이지 나누기를 자동으로 수행하고 반복을 통해 다음 결과 페이지를 가져옵니다.
Python
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Python 설정 안내를 따르세요. 자세한 내용은 BigQuery Python API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Ruby
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Ruby 설정 안내를 따르세요. 자세한 내용은 BigQuery Ruby API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Ruby용 Cloud 클라이언트 라이브러리에서는 Table#data 및 Data#next를 사용하여 페이지 매김이 자동으로 수행됩니다.
테이블 데이터 쿼리
다음 쿼리 작업 유형 중 하나를 사용하여 BigQuery 데이터를 쿼리할 수 있습니다.
대화형 쿼리 작업. 기본적으로 BigQuery는 가능한 한 빨리 실행되도록 설계된 대화형 쿼리 작업으로 쿼리를 실행합니다.
일괄 쿼리 작업. 일괄 쿼리는 대화형 쿼리보다 우선순위가 낮습니다. 프로젝트나 예약에서 사용 가능한 모든 컴퓨팅 리소스를 사용하는 경우 일괄 쿼리는 큐에 추가되어 큐에 남아 있을 가능성이 높습니다. 일괄 쿼리가 실행되기 시작하면 대화형 쿼리와 동일하게 실행됩니다. 자세한 내용은 쿼리 큐를 참조하세요.
연속 쿼리 작업. 이러한 작업을 사용하면 쿼리가 연속적으로 실행되므로 BigQuery에서 수신되는 데이터를 실시간으로 분석한 후 결과를 BigQuery 테이블에 쓰거나 결과를 Bigtable 또는 Pub/Sub로 내보낼 수 있습니다. 이 기능을 사용하여 통계를 만들어 즉시 조치, 실시간 머신러닝(ML) 추론 적용, 이벤트 기반 데이터 파이프라인 빌드 등 시간에 민감한 작업을 수행할 수 있습니다.
다음 메서드를 사용하여 쿼리 작업을 실행할 수 있습니다.
- Google Cloud 콘솔에서 쿼리를 작성하고 실행합니다.
- bq 명령줄 도구에서
bq query명령어를 실행합니다. - BigQuery REST API의
jobs.query또는jobs.insert메서드를 프로그래매틱 방식으로 호출합니다. - BigQuery 클라이언트 라이브러리를 사용합니다.
BigQuery 테이블 쿼리에 대한 자세한 내용은 BigQuery 데이터 쿼리 소개를 참조하세요.
BigQuery 테이블에 저장된 데이터뿐만 아니라 외부에 저장된 데이터도 쿼리할 수 있습니다. 자세한 내용은 외부 데이터 소스 소개를 참조하세요.
테이블 데이터 수정
SQL의 DML 문을 사용하여 테이블의 데이터를 수정할 수 있습니다. DML 문을 사용하여 테이블의 행을 업데이트, 병합, 삽입, 삭제할 수 있습니다. 각 유형의 DML 문에 대한 구문 참조 및 예시는 GoogleSQL의 DML 문을 참조하세요.
legacy SQL 언어는 DML 문을 지원하지 않습니다. legacy SQL을 사용하여 데이터를 업데이트하거나 삭제하려면 테이블을 삭제한 다음 새 데이터로 다시 만들어야 합니다. 또는 데이터를 수정하고 쿼리 결과를 새 대상 테이블에 쓰는 쿼리를 작성할 수도 있습니다.
테이블 데이터 복사
다음 방법을 사용하여 테이블을 복사할 수 있습니다.
- Google Cloud 콘솔 사용
- bq 명령줄 도구의
bq cp명령어 사용 jobs.insertAPI 메서드 호출 및 복사 작업 구성- 클라이언트 라이브러리 사용
테이블 복사에 대한 자세한 내용은 테이블 복사를 참조하세요.
테이블 데이터 내보내기
테이블 데이터를 CSV, JSON, Avro, Parquet(미리보기) 형식으로 Cloud Storage 버킷으로 내보낼 수 있습니다. 로컬 머신으로 내보내기는 지원되지 않습니다. 하지만 Google Cloud 콘솔을 사용하여 쿼리 결과를 다운로드하고 저장할 수는 있습니다.
자세한 내용은 테이블 데이터 내보내기를 참조하세요.
테이블 보안
BigQuery에서 테이블에 대한 액세스를 제어하려면 IAM으로 리소스에 대한 액세스 제어를 참고하세요.
다음 단계
- 데이터 로드에 대한 자세한 내용은 데이터 로드 소개를 참조하세요.
- 데이터 쿼리에 대한 자세한 내용은 BigQuery 데이터 쿼리 소개를 참조하세요.
- 테이블 스키마 수정에 대한 자세한 내용은 테이블 스키마 수정을 참조하세요.
- 테이블 만들기 및 사용에 대한 자세한 내용은 테이블 만들기 및 사용을 참조하세요.
- 테이블 관리에 대한 자세한 내용은 테이블 관리를 참조하세요.