Ripristino di emergenza gestito
Questo documento fornisce una panoramica del disaster recovery gestito di BigQuery e di come implementarlo per i tuoi dati e workload.
Panoramica
BigQuery supporta scenari di ripristino di emergenza in caso di interruzione totale a livello di regione. Ripristino di emergenza di BigQuery si basa sulla replica dei set di dati tra regioni per gestire il failover dello spazio di archiviazione. Dopo aver creato una replica del set di dati in una regione secondaria, puoi controllare il comportamento di failover per il calcolo e l'archiviazione per mantenere la continuità aziendale durante un'interruzione. Dopo un failover, puoi accedere alla capacità di calcolo (slot) e ai set di dati replicati nella regione promossa. Il disaster recovery è supportato solo con la versione Enterprise Plus.
Il ripristino di emergenza gestito offre due opzioni di failover: hard failover e
soft failover. Un failover rigido promuove immediatamente le repliche della prenotazione e del set di dati della regione secondaria a diventare principali. Questa azione viene eseguita
anche se la regione primaria attuale è offline e non attende la
replica di eventuali dati non replicati. Per questo motivo, durante il failover forzato può verificarsi una perdita di dati.
Qualsiasi job che ha eseguito il commit dei dati nella regione di origine prima del valore della replica
replication_time
potrebbe dover essere eseguito di nuovo nella regione di destinazione dopo il failover.
A differenza di un failover hard, un failover soft attende che tutte le modifiche
alle prenotazioni e ai set di dati eseguite nella regione primaria vengano replicate nella
regione secondaria prima di completare il processo di failover. Un failover controllato
richiede che siano disponibili sia la regione principale sia quella secondaria.
L'avvio di un failover parziale imposta softFailoverStartTime
per la prenotazione. softFailoverStartTime
viene cancellato al termine del failover temporaneo.
Per attivare ripristino di emergenza, devi creare una prenotazione dell'edizione Enterprise Plus nella regione primaria, ovvero la regione in cui si trova il set di dati prima del failover. La capacità di calcolo di standby nella regione accoppiata è inclusa nella prenotazione Enterprise Plus. Poi colleghi un set di dati a questa prenotazione per attivare il failover per quel set di dati. Puoi collegare un set di dati a una prenotazione solo se il set di dati è stato sottoposto a backfill e ha le stesse località principali e secondarie accoppiate della prenotazione. Dopo che un set di dati è collegato a una prenotazione di failover, solo le prenotazioni Enterprise Plus possono scrivere in questi set di dati e non puoi eseguire la promozione della replica tra regioni sul set di dati. Puoi leggere dai set di dati collegati a una prenotazione di failover con qualsiasi modello di capacità. Per saperne di più sulle prenotazioni, consulta Introduzione alla gestione dei carichi di lavoro.
La capacità di calcolo della regione principale è disponibile nella regione secondaria subito dopo un failover. Questa disponibilità si applica alla base di riferimento della prenotazione, indipendentemente dal fatto che venga utilizzata o meno.
Devi scegliere attivamente di eseguire il failover nell'ambito dei test o in risposta a un disastro reale. Non devi eseguire il failover più di una volta in un intervallo di 10 minuti. Negli scenari di replica dei dati, il backfill si riferisce al processo di compilazione di una replica di un set di dati con dati storici esistenti prima della creazione o dell'attivazione della replica. I set di dati devono completare il backfill prima che tu possa eseguire il failover sul set di dati.
Il seguente diagramma mostra l'architettura del ripristino di emergenza gestito:
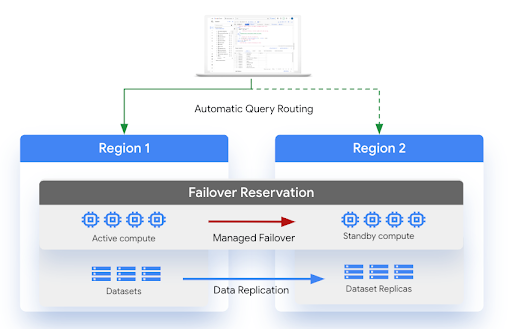
Limitazioni
Si applicano le seguenti limitazioni al ripristino di emergenza di BigQuery:
Il ripristino di emergenza BigQuery è soggetto alle stesse limitazioni della replica dei set di dati tra regioni.
La scalabilità automatica dopo un failover dipende dalla disponibilità di capacità di calcolo nella regione secondaria. Nella regione secondaria è disponibile solo la base di riferimento della prenotazione.
La
INFORMATION_SCHEMA.RESERVATIONSvisualizzazione non contiene dettagli di failover.Se hai più prenotazioni di failover con lo stesso progetto di amministrazione, ma i cui set di dati collegati utilizzano posizioni secondarie diverse, non utilizzare una prenotazione di failover con i set di dati collegati a una prenotazione di failover diversa.
Se vuoi convertire una prenotazione esistente in una prenotazione di failover, la prenotazione esistente non può avere più di 1000 assegnazioni di prenotazione.
Una prenotazione di failover non può avere più di 1000 set di dati collegati.
Il failover temporaneo può essere attivato solo se sono disponibili sia la regione di origine che quella di destinazione.
Il failover temporaneo non può essere attivato se si verificano errori temporanei o di altro tipo durante la replica della prenotazione. Ad esempio, se la quota di slot nella regione secondaria è insufficiente per l'aggiornamento della prenotazione.
La prenotazione e i set di dati allegati non possono essere aggiornati durante un failover soft attivo, ma possono comunque essere letti.
I job in esecuzione su una prenotazione di failover durante un soft failover attivo potrebbero non essere eseguiti sulla prenotazione a causa di modifiche temporanee nel routing del set di dati e della prenotazione durante l'operazione di failover. Tuttavia, questi job utilizzeranno gli slot di prenotazione prima dell'avvio di qualsiasi failover graduale e dopo il suo completamento.
Località
Le seguenti regioni sono disponibili quando crei una prenotazione di failover:
| Codice località | Nome regione | Descrizione regione |
|---|---|---|
ASIA |
||
ASIA-EAST1 |
Taiwan | |
ASIA-SOUTHEAST1 |
Singapore | |
AU |
||
AUSTRALIA-SOUTHEAST1 |
Sydney | |
AUSTRALIA-SOUTHEAST2 |
Melbourne | |
CA |
||
NORTHAMERICA-NORTHEAST1 |
Montréal | |
NORTHAMERICA-NORTHEAST2 |
Toronto | |
DE |
||
EUROPE-WEST3 |
Francoforte | |
EUROPE-WEST10 |
Berlino | |
EU |
||
EU |
Multiregione EU | |
EUROPE-CENTRAL2 |
Varsavia | |
EUROPE-NORTH1 |
Finlandia | |
EUROPE-SOUTHWEST1 |
Madrid | |
EUROPE-WEST1 |
Belgio | |
EUROPE-WEST3 |
Francoforte | |
EUROPE-WEST4 |
Paesi Bassi | |
EUROPE-WEST8 |
Milano | |
EUROPE-WEST9 |
Parigi | |
IN |
||
ASIA-SOUTH1 |
Mumbai | |
ASIA-SOUTH2 |
Delhi | |
US |
||
US |
Stati Uniti (multiregionale) | |
US-CENTRAL1 |
Iowa | |
US-EAST1 |
Carolina del Sud | |
US-EAST4 |
Virginia del Nord | |
US-EAST5 |
Columbus | |
US-SOUTH1 |
Dallas | |
US-WEST1 |
Oregon | |
US-WEST2 |
Los Angeles | |
US-WEST3 |
Salt Lake City | |
US-WEST4 |
Las Vegas |
Le coppie di regioni devono essere selezionate all'interno di ASIA, AU, CA, DE, EU, IN o
US. Ad esempio, una regione all'interno di US non può essere accoppiata a una regione all'interno di EU.
Se il tuo set di dati BigQuery si trova in una località multiregionale, non puoi utilizzare le seguenti coppie di regioni. Questa limitazione è necessaria per garantire che la prenotazione del failover e i dati siano geograficamente separati dopo la replica. Per saperne di più sulle regioni contenute all'interno di più regioni, consulta Più regioni.
us-central1-usmultiregionaleus-west1-usmultiregionaleeu-west1-eumultiregionaleeu-west4-eumultiregionale
Prima di iniziare
- Verifica di disporre dell'autorizzazione
bigquery.reservations.updateIdentity and Access Management (IAM) per aggiornare le prenotazioni. - Verifica di avere set di dati esistenti configurati per la replica. Per ulteriori informazioni, vedi Replicare un set di dati.
Replica turbo
Il ripristino di emergenza utilizza la replica turbo per una replica dei dati più rapida tra le regioni, il che riduce il rischio di esposizione alla perdita di dati, riduce al minimo i tempi di inattività del servizio e consente di supportare un servizio ininterrotto in seguito a un'interruzione regionale.
La replica turbo non si applica all'operazione di backfill iniziale. Una volta completata l'operazione di backfill iniziale, la replica turbo mira a replicare i set di dati in una singola coppia di regioni di failover con una replica secondaria entro 15 minuti, a condizione che la quota di larghezza di banda non venga superata e non si verifichino errori dell'utente.
Recovery Time Objective
Un Recovery Time Objective (RTO) è il tempo di ripristino target consentito in BigQuery in caso di emergenza. Per saperne di più sull'RTO, consulta Nozioni di base della RE del DR.Il ripristino di emergenza gestito ha un RTO di cinque minuti dopo l'avvio di un failover. A causa dell'RTO, la capacità è disponibile nella regione secondaria entro cinque minuti dall'avvio della procedura di failover.
Recovery Point Objective
Un Recovery Point Objective (RPO) è il momento più recente da cui i dati devono poter essere ripristinati. Per saperne di più sull'RPO, consulta Nozioni di base della pianificazione del DR. Il ripristino di emergenza gestito ha un RPO definito per set di dati. L'RPO mira a mantenere la replica secondaria entro 15 minuti dalla replica primaria. Per rispettare questo RPO, non puoi superare la quota di larghezza di banda e non possono verificarsi errori dell'utente.
Quota
Devi disporre della capacità di calcolo scelta nella regione secondaria prima di configurare una prenotazione di failover. Se non è disponibile una quota nella regione secondaria, non puoi configurare o aggiornare la prenotazione. Per ulteriori informazioni, consulta Quote e limiti.
La larghezza di banda della replica turbo ha una quota. Per ulteriori informazioni, consulta Quote e limiti.
Prezzi
La configurazione del ripristino di emergenza gestito richiede i seguenti piani tariffari:
Capacità di calcolo: devi acquistare la versione Enterprise Plus.
Replica turbo: il ripristino di emergenza si basa sulla replica turbo durante la replica. L'addebito avviene in base ai byte fisici e su base di GiB fisici replicati. Per saperne di più, consulta Prezzi del trasferimento di dati per la replica dei dati per la replica turbo.
Archiviazione: i byte di archiviazione nella regione secondaria vengono fatturati allo stesso prezzo dei byte di archiviazione nella regione primaria. Per maggiori informazioni, consulta la pagina Prezzi dell'archiviazione.
I clienti sono tenuti a pagare solo la capacità di calcolo nella regione principale. La capacità di calcolo secondaria (in base alla baseline della prenotazione) è disponibile nella regione secondaria senza costi aggiuntivi. Gli slot inattivi non possono utilizzare la capacità di calcolo secondaria a meno che non sia stato eseguito il failover della prenotazione.
Se devi eseguire letture non aggiornate nella regione secondaria, devi acquistare capacità di calcolo aggiuntiva.
Creare o modificare una prenotazione Enterprise Plus
Prima di collegare un set di dati a una prenotazione, devi creare una prenotazione Enterprise Plus o modificare una prenotazione esistente e configurarla per il ripristino di emergenza.
Crea una prenotazione
Seleziona una delle seguenti opzioni:
Console
Nella console Google Cloud , vai alla pagina BigQuery.
Nel menu di navigazione, fai clic su Gestione della capacità e poi su Crea prenotazione.
Nel campo Nome prenotazione, inserisci un nome per la prenotazione.
Nell'elenco Località, seleziona la località.
Nell'elenco Versione, seleziona la versione Enterprise Plus.
Nell'elenco Selettore dimensione massima prenotazione, seleziona la dimensione massima della prenotazione.
(Facoltativo) Nel campo Slot di base, inserisci il numero di slot di base per la prenotazione.
Il numero di slot con scalabilità automatica disponibili viene determinato sottraendo il valore degli slot di riferimento dal valore della dimensione massima della prenotazione. Ad esempio, se crei una prenotazione con 100 slot di riferimento e una dimensione massima della prenotazione di 400, la prenotazione ha 300 slot con scalabilità automatica. Per saperne di più sugli slot di base, vedi Utilizzo delle prenotazioni con slot di base e di scalabilità automatica.
Nell'elenco Località secondaria, seleziona la località secondaria.
Per disattivare la condivisione degli slot inattivi e utilizzare solo la capacità degli slot specificata, fai clic sul pulsante di attivazione/disattivazione Ignora slot inattivi.
Per espandere la sezione Impostazioni avanzate, fai clic sulla freccia di espansione .
(Facoltativo) Per impostare la concorrenza target dei job, fai clic sul pulsante di attivazione/disattivazione Ignora la concorrenza automatica target dei job e poi inserisci un valore per Concorrenza target dei job. La suddivisione degli slot viene visualizzata nella tabella Stima dei costi. Un riepilogo della prenotazione viene visualizzato nella tabella Riepilogo capacità.
Fai clic su Salva.
La nuova prenotazione è visibile nella scheda Prenotazioni slot.
SQL
Per creare una prenotazione, utilizza l'istruzione DDL (Data Definition Language) CREATE RESERVATION.
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, inserisci la seguente istruzione:
CREATE RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` OPTIONS ( slot_capacity = NUMBER_OF_BASELINE_SLOTS, edition = ENTERPRISE_PLUS, secondary_location = SECONDARY_LOCATION);
Sostituisci quanto segue:
ADMIN_PROJECT_ID: l'ID progetto del progetto di amministrazione proprietario della risorsa di prenotazione.LOCATION: la posizione della prenotazione. Se selezioni una posizione BigQuery Omni, l'opzione di edizione è limitata all'edizione Enterprise.RESERVATION_NAME: il nome della prenotazione.Il nome deve iniziare e terminare con una lettera minuscola o un numero e contenere solo lettere minuscole, numeri e trattini.
NUMBER_OF_BASELINE_SLOTS: il numero di slot di base da allocare alla prenotazione. Non puoi impostare l'opzioneslot_capacitye l'opzioneeditionnella stessa prenotazione.SECONDARY_LOCATION: la posizione secondaria della prenotazione. In caso di interruzione, tutti i set di dati collegati a questa prenotazione verranno sottoposti a failover in questa posizione.
Fai clic su Esegui.
Per maggiori informazioni su come eseguire le query, consulta Eseguire una query interattiva.
Modificare una prenotazione esistente
Seleziona una delle seguenti opzioni:
Console
Nella console Google Cloud , vai alla pagina BigQuery.
Nel menu di navigazione, fai clic su Gestione della capacità.
Fai clic sulla scheda Prenotazioni slot.
Trova la prenotazione che vuoi aggiornare.
Fai clic su Azioni prenotazioni e poi su Modifica.
Nel campo Località secondaria, inserisci la località secondaria.
Fai clic su Salva.
SQL
Per aggiungere o modificare una posizione secondaria in una prenotazione, utilizza l'istruzione DDL ALTER RESERVATION SET OPTIONS.
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, inserisci la seguente istruzione:
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( secondary_location = SECONDARY_LOCATION);
Sostituisci quanto segue:
ADMIN_PROJECT_ID: l'ID progetto del progetto di amministrazione proprietario della risorsa di prenotazione.LOCATION: la posizione della prenotazione, ad esempioeurope-west9.RESERVATION_NAME: il nome della prenotazione. Il nome deve iniziare e terminare con una lettera minuscola o un numero e contenere solo lettere minuscole, numeri e trattini.SECONDARY_LOCATION: la posizione secondaria della prenotazione. In caso di interruzione, tutti i set di dati collegati a questa prenotazione verranno sottoposti a failover in questa posizione.
Fai clic su Esegui.
Per maggiori informazioni su come eseguire le query, consulta Eseguire una query interattiva.
Allegare un set di dati a una prenotazione
Per abilitare ripristino di emergenza per la prenotazione creata in precedenza, completa i seguenti passaggi. Il set di dati deve essere già configurato per la replica nelle stesse regioni primaria e secondaria della prenotazione. Per saperne di più, consulta Replica dei set di dati tra regioni.
Console
Nella console Google Cloud , vai alla pagina BigQuery.
Nel menu di navigazione, fai clic su Gestione della capacità, quindi sulla scheda Prenotazioni slot.
Fai clic sulla prenotazione a cui vuoi allegare un set di dati.
Fai clic sulla scheda Recupero di emergenza.
Fai clic su Aggiungi set di dati di failover.
Inserisci il nome del set di dati che vuoi associare alla prenotazione.
Fai clic su Aggiungi.
SQL
Per collegare un set di dati a una prenotazione, utilizza l'istruzione DDL ALTER SCHEMA SET OPTIONS.
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, inserisci la seguente istruzione:
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = ADMIN_PROJECT_ID.RESERVATION_NAME);
Sostituisci quanto segue:
DATASET_NAME: il nome del set di dati.ADMIN_PROJECT_ID.RESERVATION_NAME: il nome della prenotazione a cui vuoi associare il set di dati.
Fai clic su Esegui.
Per maggiori informazioni su come eseguire le query, consulta Eseguire una query interattiva.
Scollegare un set di dati da una prenotazione
Per interrompere la gestione del comportamento di failover di un set di dati tramite una prenotazione, scollega il set di dati dalla prenotazione. Non viene modificata la replica primaria corrente per il set di dati né vengono rimosse le repliche del set di dati esistenti. Per ulteriori informazioni sulla rimozione delle repliche del set di dati dopo il distacco di un set di dati, vedi Rimuovere la replica del set di dati.
Console
Nella console Google Cloud , vai alla pagina BigQuery.
Nel menu di navigazione, fai clic su Gestione della capacità, quindi sulla scheda Prenotazioni slot.
Fai clic sulla prenotazione da cui vuoi scollegare un set di dati.
Fai clic sulla scheda Recupero di emergenza.
Espandi l'opzione Azioni per la replica principale del set di dati.
Fai clic su Rimuovi.
SQL
Per scollegare un set di dati da una prenotazione, utilizza l'istruzione DDL ALTER SCHEMA SET OPTIONS.
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, inserisci la seguente istruzione:
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = NULL);
Sostituisci quanto segue:
DATASET_NAME: il nome del set di dati.
Fai clic su Esegui.
Per maggiori informazioni su come eseguire le query, consulta Eseguire una query interattiva.
Avviare un failover
In caso di interruzione regionale, devi eseguire manualmente il failover della prenotazione nella località utilizzata dalla replica. Il failover della prenotazione include anche eventuali set di dati associati. Per eseguire manualmente il failover di una prenotazione:
Console
Nella console Google Cloud , vai alla pagina BigQuery.
Nel menu di navigazione, fai clic su Recupero di emergenza.
Fai clic sul nome della prenotazione a cui vuoi eseguire il failover.
Seleziona Modalità di failover forzata (valore predefinito) o Modalità di failover soft.
Fai clic su Failover.
SQL
Per aggiungere o modificare una località secondaria in una prenotazione, utilizza l'istruzione DDL ALTER RESERVATION SET OPTIONS e imposta is_primary su TRUE.
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, inserisci la seguente istruzione:
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( is_primary = TRUE, failover_mode=FAILOVER_MODE);
Sostituisci quanto segue:
ADMIN_PROJECT_ID: l'ID progetto del progetto di amministrazione proprietario della risorsa di prenotazione.LOCATION: la nuova posizione principale della prenotazione, ovvero la posizione secondaria corrente prima del failover, ad esempioeurope-west9.RESERVATION_NAME: il nome della prenotazione. Il nome deve iniziare e terminare con una lettera minuscola o un numero e contenere solo lettere minuscole, numeri e trattini.PRIMARY_STATUS: uno stato booleano che dichiara se la prenotazione è la replica primaria.FAILOVER_MODE: un parametro facoltativo utilizzato per descrivere la modalità di failover. Può essere impostato suHARDoSOFT. Se questo parametro non è specificato, viene utilizzatoHARDper impostazione predefinita.
Fai clic su Esegui.
Per maggiori informazioni su come eseguire le query, consulta Eseguire una query interattiva.
Monitoraggio
Per determinare lo stato delle repliche, esegui una query sulla
visualizzazione INFORMATION_SCHEMA.SCHEMATA_REPLICAS. Ad esempio:
SELECT schema_name, replica_name, creation_complete, replica_primary_assigned, replica_primary_assignment_complete FROM `region-LOCATION`.INFORMATION_SCHEMA.SCHEMATA_REPLICAS WHERE schema_name="my_dataset"
La seguente query restituisce i job degli ultimi sette giorni che non andrebbero a buon fine se i relativi set di dati fossero set di dati di failover:
WITH non_epe_reservations AS ( SELECT project_id, reservation_name FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.RESERVATIONS WHERE edition != 'ENTERPRISE_PLUS' ) SELECT * FROM ( SELECT job_id FROM ( SELECT job_id, reservation_id, ARRAY_CONCAT(referenced_tables, [destination_table]) AS all_referenced_tables, query FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.JOBS WHERE creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP() ) A, UNNEST(all_referenced_tables) AS referenced_table ) jobs LEFT OUTER JOIN non_epe_reservations ON ( jobs.reservation_id = CONCAT( non_epe_reservations.project_id, ':', 'LOCATION', '.', non_epe_reservations.reservation_name)) WHERE CONCAT(jobs.project_id, ':', jobs.dataset_id) IN UNNEST( [ 'PROJECT_ID:DATASET_ID', 'PROJECT_ID:DATASET_ID']);
Sostituisci quanto segue:
PROJECT_ID: l'ID progettoDATASET_ID: l'ID set di dati.LOCATION: la posizione.
Passaggi successivi
Scopri di più sulla replica dei set di dati tra regioni.
Scopri di più sull'affidabilità.