Recuperación tras fallos gestionada
En este documento se ofrece una descripción general de la recuperación tras fallos gestionada de BigQuery y se explica cómo implementarla en sus datos y cargas de trabajo.
Información general
BigQuery proporciona recuperación tras fallos en caso de que se produzca un fallo total en una región. La recuperación tras fallos de BigQuery se basa en la replicación de conjuntos de datos entre regiones para gestionar la conmutación por error del almacenamiento. Después de crear una réplica de un conjunto de datos en una región secundaria, puedes controlar el comportamiento de la conmutación por error de la computación y el almacenamiento para mantener la continuidad de la actividad empresarial durante una interrupción del servicio. Después de una conmutación por error, puede acceder a la capacidad de computación (slots) y a los conjuntos de datos replicados en la región promocionada. La recuperación tras desastres solo se admite en la edición Enterprise Plus.
La recuperación tras fallos gestionada ofrece dos opciones de conmutación por error: conmutación por error completa y conmutación por error parcial. Una conmutación por error completa convierte inmediatamente en principales las réplicas de reserva y de conjunto de datos de la región secundaria. Esta acción se lleva a cabo
aunque la región principal actual esté sin conexión y no espera a que se repliquen los datos que no se hayan replicado. Por este motivo, se pueden perder datos durante una conmutación por error completa.
Es posible que sea necesario volver a ejecutar en la región de destino los trabajos que hayan confirmado datos en la región de origen antes de que el valor de la réplica sea replication_time después de la conmutación por error.
A diferencia de una conmutación por error completa, una conmutación por error parcial espera hasta que todos los cambios de reservas y conjuntos de datos confirmados en la región principal se repliquen en la región secundaria antes de completar el proceso de conmutación por error. Para realizar una conmutación por error suave, es necesario que tanto la región principal como la secundaria estén disponibles.
Si inicias una conmutación por error con reservas, se definirá el softFailoverStartTime de la reserva. El softFailoverStartTime
se borra cuando se completa la conmutación por error con reservas.
Para habilitar la recuperación ante desastres, debe crear una reserva de la edición Enterprise Plus en la región principal, que es la región en la que se encuentra el conjunto de datos antes de la conmutación por error. La capacidad de computación de reserva de la región emparejada se incluye en la reserva de Enterprise Plus. Después, adjunta un conjunto de datos a esta reserva para habilitar la conmutación por error de ese conjunto de datos. Solo puedes asociar un conjunto de datos a una reserva si el conjunto de datos se ha rellenado y tiene las mismas ubicaciones primarias y secundarias emparejadas que la reserva. Una vez que se ha asociado un conjunto de datos a una reserva de conmutación por error, solo las reservas de Enterprise Plus pueden escribir en esos conjuntos de datos y no se puede realizar una promoción de replicación entre regiones en el conjunto de datos. Puede leer datos de conjuntos de datos asociados a una reserva de conmutación por error con cualquier modelo de capacidad. Para obtener más información sobre las reservas, consulta el artículo Introducción a la gestión de cargas de trabajo.
La capacidad de computación de tu región principal estará disponible en la secundaria poco después de la conmutación por error. Esta disponibilidad se aplica a tu referencia de reserva, tanto si se usa como si no.
Debes elegir activamente la conmutación por error como parte de las pruebas o en respuesta a un desastre real. No deberías hacer failover más de una vez en un periodo de 10 minutos. En los casos de replicación de datos, la reposición de datos se refiere al proceso de rellenar una réplica de un conjunto de datos con datos históricos que existían antes de que se creara o activara la réplica. Los conjuntos de datos deben completar el relleno antes de que puedas conmutar por error al conjunto de datos.
En el siguiente diagrama se muestra la arquitectura de la recuperación tras desastres gestionada:
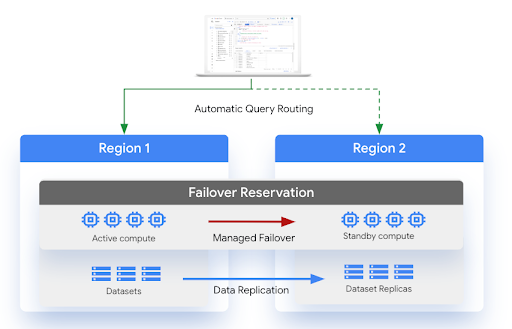
Limitaciones
Se aplican las siguientes limitaciones a la recuperación ante desastres de BigQuery:
La recuperación tras fallos de BigQuery está sujeta a las mismas limitaciones que la replicación de conjuntos de datos entre regiones.
El autoescalado después de una conmutación por error depende de la disponibilidad de capacidad de computación en la región secundaria. En la región secundaria solo está disponible la configuración de referencia de la reserva.
La
INFORMATION_SCHEMA.RESERVATIONSvista no tiene detalles de conmutación por error.Si tienes varias reservas de conmutación por error con el mismo proyecto de administración, pero cuyos conjuntos de datos adjuntos usan ubicaciones secundarias diferentes, no utilices una reserva de conmutación por error con los conjuntos de datos adjuntos a otra reserva de conmutación por error.
Si quieres convertir una reserva en una reserva de conmutación por error, la reserva no puede tener más de 1000 asignaciones de reserva.
Una reserva de conmutación por error no puede tener más de 1000 conjuntos de datos asociados.
La conmutación por error suave solo se puede activar si las regiones de origen y de destino están disponibles.
No se puede activar la conmutación por error suave si se produce algún error transitorio o de otro tipo durante la replicación de reservas. Por ejemplo, si no hay suficiente cuota de ranuras en la región secundaria para actualizar la reserva.
La reserva y los conjuntos de datos adjuntos no se pueden actualizar durante una conmutación por error suave activa, pero se pueden seguir leyendo.
Es posible que los trabajos que se ejecuten en una reserva de conmutación por error durante una conmutación por error no definitiva activa no se ejecuten en la reserva debido a cambios transitorios en la ruta de la reserva y del conjunto de datos durante la operación de conmutación por error. Sin embargo, estas tareas usarán las ranuras de reserva antes de que se inicie cualquier conmutación por error temporal y después de que se complete.
Ubicaciones
Puede seleccionar las siguientes regiones al crear una reserva de conmutación por error:
| Código de ubicación | Nombre de la región | Descripción de la región |
|---|---|---|
ASIA |
||
ASIA-EAST1 |
Taiwán | |
ASIA-SOUTHEAST1 |
Singapur | |
AU |
||
AUSTRALIA-SOUTHEAST1 |
Sídney | |
AUSTRALIA-SOUTHEAST2 |
Melbourne | |
CA |
||
NORTHAMERICA-NORTHEAST1 |
Montreal | |
NORTHAMERICA-NORTHEAST2 |
Toronto | |
DE |
||
EUROPE-WEST3 |
Fráncfort | |
EUROPE-WEST10 |
Berlín | |
EU |
||
EU |
Multirregional de la UE | |
EUROPE-CENTRAL2 |
Varsovia | |
EUROPE-NORTH1 |
Finlandia | |
EUROPE-SOUTHWEST1 |
Madrid | |
EUROPE-WEST1 |
Bélgica | |
EUROPE-WEST3 |
Fráncfort | |
EUROPE-WEST4 |
Países Bajos | |
EUROPE-WEST8 |
Milán | |
EUROPE-WEST9 |
París | |
IN |
||
ASIA-SOUTH1 |
Bombay | |
ASIA-SOUTH2 |
Deli | |
US |
||
US |
Multirregional de EE. UU. | |
US-CENTRAL1 |
Iowa | |
US-EAST1 |
Carolina del Sur | |
US-EAST4 |
Norte de Virginia | |
US-EAST5 |
Columbus | |
US-SOUTH1 |
Dallas | |
US-WEST1 |
Oregón | |
US-WEST2 |
Los Ángeles | |
US-WEST3 |
Salt Lake City | |
US-WEST4 |
Las Vegas |
Los pares de regiones deben seleccionarse en ASIA, AU, CA, DE, EU, IN o US. Por ejemplo, una región de US no se puede emparejar con una región de EU.
Si tu conjunto de datos de BigQuery está en una ubicación multirregional, no puedes usar los siguientes pares de regiones. Esta limitación es necesaria para asegurarse de que tu reserva y tus datos de conmutación por error estén separados geográficamente después de la replicación. Para obtener más información sobre las regiones que se incluyen en las multirregiones, consulta Multirregiones.
us-central1-usmultirregiónus-west1-usmultirregióneu-west1-eumultirregióneu-west4-eumultirregión
Antes de empezar
- Verifica que tienes el permiso
bigquery.reservations.updateGestión de Identidades y Accesos (IAM) para actualizar reservas. - Comprueba que tienes conjuntos de datos configurados para la replicación. Para obtener más información, consulta Replicar un conjunto de datos.
Replicación turbo
La recuperación tras desastres usa la replicación turbo para replicar los datos más rápido entre regiones, lo que reduce el riesgo de pérdida de datos, minimiza el tiempo de inactividad del servicio y ayuda a mantener el servicio ininterrumpido tras una interrupción regional.
La replicación turbo no se aplica a la operación de relleno inicial. Una vez que se haya completado la operación de relleno inicial, la replicación turbo replicará los conjuntos de datos en un único par de regiones de conmutación por error con una réplica secundaria en un plazo de 15 minutos, siempre que no se supere la cuota de ancho de banda y no haya errores del usuario.
Objetivo de tiempo de recuperación
El objetivo de tiempo de recuperación (RTO) es el tiempo objetivo permitido para la recuperación en BigQuery en caso de desastre. Para obtener más información sobre el RTO, consulta el artículo Conceptos básicos de la planificación de recuperación tras desastres.La recuperación tras desastres gestionada tiene un RTO de cinco minutos después de iniciar una conmutación por error. Debido al RTO, la capacidad está disponible en la región secundaria en un plazo de cinco minutos desde que se inicia el proceso de conmutación por error.
Objetivo de punto de recuperación
El objetivo de punto de recuperación (RPO) es el momento más reciente a partir del cual se deben poder restaurar los datos. Para obtener más información sobre el RPO, consulta Aspectos básicos de la planificación de recuperación ante desastres. La recuperación tras fallos gestionada tiene un RPO definido por conjunto de datos. El RPO tiene como objetivo mantener la réplica secundaria a 15 minutos de la principal. Para cumplir este RPO, no puedes superar la cuota de ancho de banda y no puede haber errores de usuario.
Cuota
Debes tener la capacidad de computación que hayas elegido en la región secundaria antes de configurar una reserva de conmutación por error. Si no hay cuota disponible en la región secundaria, no podrás configurar ni actualizar la reserva. Para obtener más información, consulta Cuotas y límites.
El ancho de banda de la replicación turbo tiene una cuota. Para obtener más información, consulta el artículo Cuotas y límites.
Precios
Para configurar la recuperación tras fallos gestionada, se necesitan los siguientes planes de precios:
Capacidad de computación: debes comprar la edición Enterprise Plus.
Replicación turbo: la recuperación tras fallos se basa en la replicación turbo durante la replicación. Se te cobra en función de los bytes físicos y por cada GiB físico replicado. Para obtener más información, consulta los precios de transferencia de datos de replicación de datos para la replicación turbo.
Almacenamiento: los bytes de almacenamiento de la región secundaria se facturan al mismo precio que los de la región principal. Para obtener más información, consulta los precios de almacenamiento.
Los clientes solo tienen que pagar por la capacidad de computación de la región principal. La capacidad de computación secundaria (basada en la base de la reserva) está disponible en la región secundaria sin coste adicional. Las ranuras inactivas no pueden usar la capacidad de computación secundaria a menos que la reserva haya fallado.
Si necesitas realizar lecturas obsoletas en la región secundaria, debes comprar capacidad de computación adicional.
Crear o modificar una reserva de Enterprise Plus
Antes de adjuntar un conjunto de datos a una reserva, debes crear una reserva Enterprise Plus o modificar una reserva ya creada y configurarla para la recuperación ante desastres.
Crear una reserva
Selecciona una de las opciones siguientes:
Consola
En la Google Cloud consola, ve a la página BigQuery.
En el menú de navegación, haga clic en Gestión de la capacidad y, a continuación, en Crear reserva.
En el campo Nombre de la reserva, introduce un nombre para la reserva.
En la lista Ubicación, selecciona la ubicación.
En la lista Edition (Edición), selecciona Enterprise Plus.
En la lista Selector de tamaño máximo de reserva, selecciona el tamaño máximo de reserva.
Opcional: En el campo Espacios publicitarios de referencia, introduce el número de espacios publicitarios de referencia de la reserva.
El número de ranuras de escalado automático disponibles se determina restando el valor de Ranuras de referencia del valor de Tamaño máximo de reserva. Por ejemplo, si creas una reserva con 100 espacios de base y un tamaño máximo de reserva de 400, tu reserva tendrá 300 espacios de escalado automático. Para obtener más información sobre los intervalos de referencia, consulta el artículo Usar reservas con intervalos de referencia y de autoescalado.
En la lista Ubicación secundaria, selecciona la ubicación secundaria.
Para inhabilitar la función de compartir espacios inactivos y usar solo la capacidad de espacio especificada, haga clic en el interruptor Ignorar espacios inactivos.
Para desplegar la sección Configuración avanzada, haz clic en la flecha de expansión.
Opcional: Para definir la simultaneidad de trabajos objetivo, activa el interruptor Anular simultaneidad de trabajos objetivo automática y, a continuación, introduce un valor en Simultaneidad de trabajos objetivo. El desglose de los espacios se muestra en la tabla Estimación de costes. En la tabla Resumen de la capacidad se muestra un resumen de la reserva.
Haz clic en Guardar.
La nueva reserva se muestra en la pestaña Reservas de espacios.
SQL
Para crear una reserva, usa la instrucción del lenguaje de definición de datos (DDL) CREATE RESERVATION.
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, introduce la siguiente instrucción:
CREATE RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` OPTIONS ( slot_capacity = NUMBER_OF_BASELINE_SLOTS, edition = ENTERPRISE_PLUS, secondary_location = SECONDARY_LOCATION);
Haz los cambios siguientes:
ADMIN_PROJECT_ID: el ID del proyecto de administración que posee el recurso de reserva.LOCATION: la ubicación de la reserva. Si seleccionas una ubicación de BigQuery Omni, la opción de edición se limitará a la edición Enterprise.RESERVATION_NAME: el nombre de la reserva.El nombre debe empezar y terminar con una letra minúscula o un número, y solo puede contener letras minúsculas, números y guiones.
NUMBER_OF_BASELINE_SLOTS: número de espacios de referencia que se asignarán a la reserva. No puedes definir las opcionesslot_capacityyeditionen la misma reserva.SECONDARY_LOCATION: la ubicación secundaria de la reserva. En caso de interrupción, los conjuntos de datos asociados a esta reserva se transferirán a esta ubicación.
Haz clic en Ejecutar.
Para obtener más información sobre cómo ejecutar consultas, consulta Ejecutar una consulta interactiva.
Modificar una reserva
Selecciona una de las opciones siguientes:
Consola
En la Google Cloud consola, ve a la página BigQuery.
En el menú de navegación, haz clic en Gestión de la capacidad.
Haz clic en la pestaña Reservas de espacios.
Busca la reserva que quieras actualizar.
Haz clic en Acciones de reserva y, a continuación, en Editar.
En el campo Ubicación secundaria, introduce la ubicación secundaria.
Haz clic en Guardar.
SQL
Para añadir o cambiar una ubicación secundaria en una reserva, utiliza la declaración de DDL ALTER RESERVATION SET OPTIONS.
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, introduce la siguiente instrucción:
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( secondary_location = SECONDARY_LOCATION);
Haz los cambios siguientes:
ADMIN_PROJECT_ID: el ID del proyecto de administración que posee el recurso de reserva.LOCATION: la ubicación de la reserva, por ejemplo,europe-west9.RESERVATION_NAME: el nombre de la reserva. El nombre debe empezar y terminar con una letra minúscula o un número, y solo puede contener letras minúsculas, números y guiones.SECONDARY_LOCATION: la ubicación secundaria de la reserva. En caso de interrupción, los conjuntos de datos asociados a esta reserva se transferirán a esta ubicación.
Haz clic en Ejecutar.
Para obtener más información sobre cómo ejecutar consultas, consulta Ejecutar una consulta interactiva.
Adjuntar un conjunto de datos a una reserva
Para habilitar la recuperación ante desastres en la reserva que has creado, sigue estos pasos. El conjunto de datos ya debe estar configurado para la replicación en las mismas regiones primaria y secundaria que la reserva. Para obtener más información, consulta Réplica de conjuntos de datos entre regiones.
Consola
En la Google Cloud consola, ve a la página BigQuery.
En el menú de navegación, haga clic en Gestión de la capacidad y, a continuación, en la pestaña Reservas de espacio.
Haz clic en la reserva a la que quieras adjuntar un conjunto de datos.
Haz clic en la pestaña Recuperación ante desastres.
Haz clic en Añadir conjunto de datos de conmutación por error.
Introduce el nombre del conjunto de datos que quieras asociar a la reserva.
Haz clic en Añadir.
SQL
Para adjuntar un conjunto de datos a una reserva, usa la declaración de DDL ALTER SCHEMA SET OPTIONS.
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, introduce la siguiente instrucción:
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = ADMIN_PROJECT_ID.RESERVATION_NAME);
Haz los cambios siguientes:
DATASET_NAME: el nombre del conjunto de datos.ADMIN_PROJECT_ID.RESERVATION_NAME: el nombre de la reserva a la que quieres asociar el conjunto de datos.
Haz clic en Ejecutar.
Para obtener más información sobre cómo ejecutar consultas, consulta Ejecutar una consulta interactiva.
Desasociar un conjunto de datos de una reserva
Para dejar de gestionar el comportamiento de conmutación por error de un conjunto de datos a través de una reserva, desvincula el conjunto de datos de la reserva. Esta acción no cambia la réplica principal actual del conjunto de datos ni elimina ninguna réplica del conjunto de datos. Para obtener más información sobre cómo eliminar réplicas de conjuntos de datos después de separar un conjunto de datos, consulta Eliminar réplicas de conjuntos de datos.
Consola
En la Google Cloud consola, ve a la página BigQuery.
En el menú de navegación, haga clic en Gestión de la capacidad y, a continuación, en la pestaña Reservas de espacio.
Haz clic en la reserva de la que quieras separar un conjunto de datos.
Haz clic en la pestaña Recuperación ante desastres.
Abre la opción Acciones de la réplica principal del conjunto de datos.
Haz clic en Quitar.
SQL
Para separar un conjunto de datos de una reserva, usa la declaración de DDL ALTER SCHEMA SET OPTIONS.
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, introduce la siguiente instrucción:
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = NULL);
Haz los cambios siguientes:
DATASET_NAME: el nombre del conjunto de datos.
Haz clic en Ejecutar.
Para obtener más información sobre cómo ejecutar consultas, consulta Ejecutar una consulta interactiva.
Iniciar una conmutación por error
En caso de interrupción regional, debes conmutar por error manualmente tu reserva a la ubicación que utiliza la réplica. Al conmutar por error la reserva, también se incluyen los conjuntos de datos asociados. Para conmutar por error manualmente una reserva, siga estos pasos:
Consola
En la Google Cloud consola, ve a la página BigQuery.
En el menú de navegación, haga clic en Recuperación ante desastres.
Haga clic en el nombre de la reserva a la que quiera conmutar por error.
Selecciona Modo de conmutación por error estricto (predeterminado) o Modo de conmutación por error flexible.
Haz clic en Conmutación por error.
SQL
Para añadir o cambiar una ubicación secundaria en una reserva, usa la declaración de DDL ALTER RESERVATION SET OPTIONS y asigna el valor TRUE a is_primary.
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, introduce la siguiente instrucción:
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( is_primary = TRUE, failover_mode=FAILOVER_MODE);
Haz los cambios siguientes:
ADMIN_PROJECT_ID: el ID del proyecto de administración que posee el recurso de reserva.LOCATION: la nueva ubicación principal de la reserva, es decir, la ubicación secundaria actual antes de la conmutación por error. Por ejemplo,europe-west9.RESERVATION_NAME: el nombre de la reserva. El nombre debe empezar y terminar con una letra minúscula o un número, y solo puede contener letras minúsculas, números y guiones.PRIMARY_STATUS: estado booleano que declara si la reserva es la réplica principal.FAILOVER_MODE: parámetro opcional que se usa para describir el modo de conmutación por error. Puede tener el valorHARDoSOFT. Si no se especifica este parámetro, se usaHARDde forma predeterminada.
Haz clic en Ejecutar.
Para obtener más información sobre cómo ejecutar consultas, consulta Ejecutar una consulta interactiva.
Supervisión
Para determinar el estado de tus réplicas, consulta la vista INFORMATION_SCHEMA.SCHEMATA_REPLICAS. Por ejemplo:
SELECT schema_name, replica_name, creation_complete, replica_primary_assigned, replica_primary_assignment_complete FROM `region-LOCATION`.INFORMATION_SCHEMA.SCHEMATA_REPLICAS WHERE schema_name="my_dataset"
La siguiente consulta devuelve los trabajos de los últimos siete días que fallarían si sus conjuntos de datos fueran conjuntos de datos de conmutación por error:
WITH non_epe_reservations AS ( SELECT project_id, reservation_name FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.RESERVATIONS WHERE edition != 'ENTERPRISE_PLUS' ) SELECT * FROM ( SELECT job_id FROM ( SELECT job_id, reservation_id, ARRAY_CONCAT(referenced_tables, [destination_table]) AS all_referenced_tables, query FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.JOBS WHERE creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP() ) A, UNNEST(all_referenced_tables) AS referenced_table ) jobs LEFT OUTER JOIN non_epe_reservations ON ( jobs.reservation_id = CONCAT( non_epe_reservations.project_id, ':', 'LOCATION', '.', non_epe_reservations.reservation_name)) WHERE CONCAT(jobs.project_id, ':', jobs.dataset_id) IN UNNEST( [ 'PROJECT_ID:DATASET_ID', 'PROJECT_ID:DATASET_ID']);
Haz los cambios siguientes:
PROJECT_ID: el ID del proyecto.DATASET_ID: el ID del conjunto de datos.LOCATION: la ubicación.