Recuperación ante desastres administrada
En este documento, se proporciona una descripción general de la recuperación ante desastres administrada de BigQuery y cómo implementarla para tus datos y cargas de trabajo.
Descripción general
BigQuery admite situaciones de recuperación ante desastres en el caso de una interrupción regional total. La recuperación ante desastres de BigQuery depende de la replicación de conjuntos de datos entre regiones para administrar la conmutación por error del almacenamiento. Después de crear una réplica de un conjunto de datos en una región secundaria, puedes controlar el comportamiento de la conmutación por error para el procesamiento y el almacenamiento a fin de mantener la continuidad del negocio durante una interrupción. Después de una conmutación por error, puedes acceder a la capacidad de procesamiento (ranuras) y a los conjuntos de datos replicados en la región promocionada. La recuperación ante desastres solo es compatible con la edición Enterprise Plus.
La recuperación ante desastres administrada ofrece dos opciones de conmutación por error: conmutación por error completa y conmutación por error parcial. Una conmutación por error completa promueve de inmediato las réplicas de reserva y del conjunto de datos de la región secundaria para que se conviertan en la principal. Esta acción continúa incluso si la región principal actual está sin conexión y no espera la replicación de ningún dato no replicado. Debido a esto, puede haber pérdida de datos durante una conmutación por error completa.
Es posible que cualquier trabajo que haya confirmado los datos en la región de origen antes del valor de replication_time de la réplica deba volver a ejecutarse en la región de destino después de la conmutación por error.
A diferencia de una conmutación por error completa, una conmutación por error parcial espera hasta que todos los cambios de reserva y del conjunto de datos confirmados en la región principal se repliquen en la región secundaria antes de completar el proceso de conmutación por error. Una conmutación por error parcial requiere que tanto la región principal como la secundaria estén disponibles.
Iniciar una conmutación por error parcial establece el softFailoverStartTime para la reserva. El objeto softFailoverStartTime se borra cuando se completa la conmutación por error no definitiva.
Para habilitar la recuperación ante desastres, debes crear una reserva de edición de Enterprise Plus en la región principal, que es la región en la que se encuentra el conjunto de datos antes de la conmutación por error. La capacidad de procesamiento en espera en la región vinculada se incluye en la reserva de Enterprise Plus. Luego, debes conectar un conjunto de datos a esta reserva para habilitar la conmutación por error en él. Solo puedes adjuntar un conjunto de datos a una reserva si el conjunto de datos se reabastece y tiene las mismas ubicaciones principales y secundarias vinculadas que la reserva. Después de que un conjunto de datos se adjunta a una reserva de conmutación por error, solo las reservas de Enterprise Plus pueden escribir en esos conjuntos de datos y no puedes realizar una promoción de replicación entre regiones en el conjunto de datos. Puedes leer desde conjuntos de datos conectados a una reserva de conmutación por error con cualquier modelo de capacidad. Para obtener más información sobre las reservas, consulta Introducción a la administración de cargas de trabajo.
La capacidad de procesamiento de tu región principal estará disponible en la región secundaria inmediatamente después de una conmutación por error. Esta disponibilidad se aplica al modelo de referencia de la reserva, ya sea que se use o no.
Debes elegir directamente la conmutación por error como parte de las pruebas o como respuesta a un desastre real. No deberías realizar más de una conmutación por error en un período de 10 minutos. En situaciones de replicación de datos, el reabastecimiento se refiere al proceso de propagación de una réplica de un conjunto de datos con datos históricos que existían antes de que la réplica se creara o se activara. Los conjuntos de datos deben completar su reabastecimiento antes de que puedas realizar la conmutación por error al conjunto de datos.
En el siguiente diagrama, se muestra la arquitectura de la recuperación ante desastres administrada:
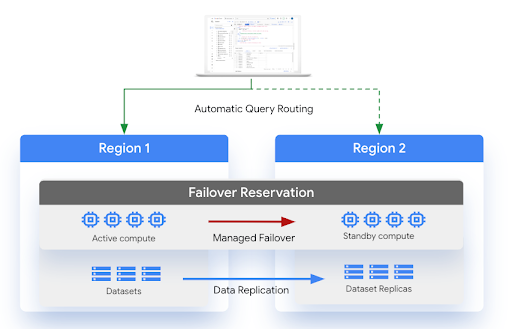
Limitaciones
Las siguientes limitaciones se aplican a la recuperación ante desastres de BigQuery:
La recuperación ante desastres de BigQuery está sujeta a las mismas limitaciones que la replicación de conjuntos de datos entre regiones.
El ajuste de escala automático después de una conmutación por error depende de la disponibilidad de la capacidad de procesamiento en la región secundaria. Solo el modelo de referencia de la reserva está disponible en la región secundaria.
La vista
INFORMATION_SCHEMA.RESERVATIONSno tiene detalles de conmutación por error.Si tienes varias reservas de conmutación por error con el mismo proyecto de administración, pero los conjuntos de datos adjuntos de este usan diferentes ubicaciones secundarias, no uses una reserva de conmutación por error con los conjuntos de datos adjuntos a otras reservas de conmutación por error.
Si deseas convertir una reserva existente en una reserva de conmutación por error, la reserva existente no puede tener más de 1,000 asignaciones de reserva.
Una reserva de conmutación por error no puede tener más de 1,000 conjuntos de datos adjuntos.
La conmutación por error parcial solo se puede activar si las regiones de origen y destino están disponibles.
No se puede activar la conmutación por error parcial si se producen errores transitorios o de otro tipo durante la replicación de la reserva. Por ejemplo, si no hay suficiente cuota de ranuras en la región secundaria para la actualización de la reserva.
La reserva y los conjuntos de datos adjuntos no se pueden actualizar durante una conmutación por error parcial activa, pero se pueden seguir leyendo.
Es posible que los trabajos que se ejecutan en una reserva de conmutación por error durante una conmutación por error temporal activa no se ejecuten en la reserva debido a cambios transitorios en el conjunto de datos y el enrutamiento de la reserva durante la operación de conmutación por error. Sin embargo, estos trabajos usarán las ranuras de reserva antes de que se inicie cualquier conmutación por error temporal y después de que se complete.
Ubicaciones
Las siguientes regiones están disponibles cuando se crea una reserva de conmutación por error:
| Código de ubicación | Nombre de la región | Descripción de la región |
|---|---|---|
ASIA |
||
ASIA-EAST1 |
Taiwán | |
ASIA-SOUTHEAST1 |
Singapur | |
AU |
||
AUSTRALIA-SOUTHEAST1 |
Sídney | |
AUSTRALIA-SOUTHEAST2 |
Melbourne | |
CA |
||
NORTHAMERICA-NORTHEAST1 |
Montreal | |
NORTHAMERICA-NORTHEAST2 |
Toronto | |
DE |
||
EUROPE-WEST3 |
Fráncfort | |
EUROPE-WEST10 |
Berlín | |
EU |
||
EU |
UE multirregión | |
EUROPE-CENTRAL2 |
Varsovia | |
EUROPE-NORTH1 |
Finlandia | |
EUROPE-SOUTHWEST1 |
Madrid | |
EUROPE-WEST1 |
Bélgica | |
EUROPE-WEST3 |
Fráncfort | |
EUROPE-WEST4 |
Países Bajos | |
EUROPE-WEST8 |
Milán | |
EUROPE-WEST9 |
París | |
IN |
||
ASIA-SOUTH1 |
Bombay | |
ASIA-SOUTH2 |
Delhi | |
US |
||
US |
EE.UU. multirregión | |
US-CENTRAL1 |
Iowa | |
US-EAST1 |
Carolina del Sur | |
US-EAST4 |
Virginia del Norte | |
US-EAST5 |
Columbus | |
US-SOUTH1 |
Dallas | |
US-WEST1 |
Oregón | |
US-WEST2 |
Los Ángeles | |
US-WEST3 |
Salt Lake City | |
US-WEST4 |
Las Vegas |
Los pares de regiones se deben seleccionar dentro de ASIA, AU, CA, DE, EU, IN o US. Por ejemplo, una región dentro de US no se puede vincular con una región dentro de EU.
Si tu conjunto de datos de BigQuery está en una ubicación multirregional, no puedes usar los siguientes pares de regiones. Esta limitación es necesaria para garantizar que tu reserva de conmutación por error y tus datos estén separados geográficamente después de la replicación. Para obtener más información sobre las regiones que se encuentran dentro de las multirregiones, consulta Multirregiones.
us-central1-usmultirregionalus-west1-usmultirregionaleu-west1-eumultirregionaleu-west4-eumultirregional
Antes de comenzar
- Verifica que tengas el permiso
bigquery.reservations.updatede Identity and Access Management (IAM) para actualizar reservas. - Verifica que tengas conjuntos de datos existentes configurados para la replicación. Para obtener más información, consulta Replica un conjunto de datos.
Replicación turbo
La recuperación ante desastres usa la replicación turbo para replicar los datos más rápido entre las regiones, lo que reduce el riesgo de exposición a la pérdida de datos, minimiza el tiempo de inactividad del servicio y ayuda a permitir un servicio sin interrupciones después de una interrupción regional.
La replicación turbo no se aplica a la operación de carga inicial. Después de que se completa la operación de reabastecimiento inicial, la replicación turbo tiene como objetivo replicar conjuntos de datos en un solo par de regiones de conmutación por error con una réplica secundaria en un plazo de 15 minutos, siempre que no se supere la cuota de ancho de banda y no haya errores del usuario.
Objetivo de tiempo de recuperación
Un objetivo de tiempo de recuperación (RTO) es el tiempo objetivo permitido para la recuperación en BigQuery en caso de un desastre. Para obtener más información sobre el RTO, consulta Conceptos básicos de la planificación de DR.La recuperación ante desastres administrada tiene un RTO de cinco minutos después de que inicias una conmutación por error. Debido al RTO, la capacidad está disponible en la región secundaria en un plazo de cinco minutos después de que se inicia el proceso de conmutación por error.
Objetivo de punto de recuperación
Un objetivo de punto de recuperación (RPO) es el punto más reciente en el tiempo desde el cual se deben poder restablecer los datos. Para obtener más información sobre el RPO, consulta Conceptos básicos de la planificación de DR. La recuperación ante desastres administrada tiene un RPO que se define por conjunto de datos. El RPO tiene como objetivo mantener la réplica secundaria a 15 minutos de la principal. Para cumplir con este RPO, no puedes exceder la cuota de ancho de banda y no puede haber errores del usuario.
Cuota
Debes tener la capacidad de procesamiento elegida en la región secundaria antes de configurar una reserva de conmutación por error. Si no hay una cuota disponible en la región secundaria, no puedes configurar ni actualizar la reserva. Para obtener más información, consulta Cuotas y límites.
El ancho de banda de replicación turbo tiene una cuota. Para obtener más información, consulta Cuotas y límites.
Precios
La configuración de la recuperación ante desastres administrada requiere los siguientes planes de precios:
Capacidad de procesamiento: Debes comprar la edición Enterprise Plus.
Replicación turbo: La recuperación ante desastres se basa en la replicación turbo durante la replicación. Se te cobra en función de bytes físicos y por GiB físicos replicados. Para obtener más información, consulta Precios de la transferencia de datos de replicación de datos para la replicación turbo.
Almacenamiento: Los bytes de almacenamiento en la región secundaria se facturan al mismo precio que los bytes de almacenamiento en la región principal. Para obtener más información, consulta los precios de almacenamiento.
Los clientes solo deben pagar por la capacidad de procesamiento en la región principal. La capacidad de procesamiento secundaria (según el modelo de referencia de la reserva) está disponible en la región secundaria sin costo adicional. Las ranuras inactivas no pueden usar la capacidad de procesamiento secundaria, a menos que la reserva haya fallado.
Si necesitas realizar operaciones de lectura inactiva en la región secundaria, debes comprar capacidad de procesamiento adicional.
Crea o modifica una reserva de Enterprise Plus
Antes de conectar un conjunto de datos a una reserva, debes crear una reserva de Enterprise Plus o modificar una reserva existente y configurarla para la recuperación ante desastres.
Crea una reserva
Seleccione una de las siguientes opciones:
Console
En la consola de Google Cloud , ve a la página BigQuery.
En el menú de navegación, haz clic en Administración de la capacidad y, luego, en Crear reserva.
En el campo Nombre de la reserva, ingresa un nombre para la reserva.
En la lista Ubicación, selecciona ubicación.
En la lista Edición, selecciona la edición Enterprise Plus.
En la lista Selector de tamaño máximo de reserva, selecciona el tamaño máximo de reserva.
En el campo Ranuras de referencia, ingresa la cantidad de ranuras del modelo de referencia para la reserva (opcional).
La cantidad de ranuras disponibles con ajuste de escala automático se determina restando el valor de las ranuras del modelo de referencia del valor del tamaño máximo de la reserva. Por ejemplo, si creas una reserva con 100 ranuras de referencia y un tamaño máximo de reserva de 400, la reserva tiene 300 ranuras de ajuste de escala automático. Para obtener más información sobre las ranuras de referencia, consulta Usa reservas con ranuras de referencia y de ajuste de escala automático.
En la lista Ubicación secundaria, selecciona la ubicación secundaria.
Para inhabilitar el uso compartido de ranuras inactivas y utilizar solamente la capacidad de ranura especificada, haz clic en el botón de activación Ignorar ranuras inactivas.
Para expandir la sección Configuración avanzada, haz clic en la flecha de expansión .
Opcional: Para configurar la simultaneidad de los trabajos de destino, haz clic en el botón de activación Anular la simultaneidad automática del trabajo de destino y, luego, ingresa un valor para la simultaneidad de los trabajos de destino. El desglose de ranuras se muestra en la tabla Estimación de costos. Se muestra un resumen de la reserva en la tabla Resumen de capacidad.
Haz clic en Guardar.
La reserva nueva se puede ver en la pestaña Reservas de ranuras.
SQL
Para crear una reserva, usa la sentencia del lenguaje de definición de datos CREATE RESERVATION (DDL).
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, escribe la siguiente oración:
CREATE RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` OPTIONS ( slot_capacity = NUMBER_OF_BASELINE_SLOTS, edition = ENTERPRISE_PLUS, secondary_location = SECONDARY_LOCATION);
Reemplaza lo siguiente:
ADMIN_PROJECT_IDpor el ID del proyecto de administración que posee el recurso de reservaLOCATION: Es la ubicación de la reserva. Si seleccionas una ubicación de BigQuery Omni, la opción de edición se limita a Enterprise Edition.RESERVATION_NAMEpor el nombre de la reserva.El nombre comenzar y terminar con una letra minúscula o un número, y contener solo letras minúsculas, números y guiones.
NUMBER_OF_BASELINE_SLOTS: es la cantidad de ranuras del modelo de referencia que asignarás a la reserva. No puedes configurar las opcionesslot_capacityyeditionen la misma reserva.SECONDARY_LOCATION: Es la ubicación secundaria de la reserva. En caso de una interrupción, los conjuntos de datos conectados a esta reserva conmutarán por error a esta ubicación.
Haz clic en Ejecutar.
Si deseas obtener información sobre cómo ejecutar consultas, visita Ejecuta una consulta interactiva.
Modifica una reserva existente
Seleccione una de las siguientes opciones:
Console
En la consola de Google Cloud , ve a la página BigQuery.
En el menú de navegación, haz clic en Administración de la capacidad.
Haz clic en la pestaña Reservas de ranuras.
Busca la reserva que deseas actualizar.
Haz clic en Acciones de reservaciones y, luego, en Editar.
En el campo Ubicación secundaria, ingresa la ubicación secundaria.
Haz clic en Guardar.
SQL
Para agregar o cambiar una ubicación secundaria a una reserva, usa la declaración DDL ALTER RESERVATION SET OPTIONS.
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, escribe la siguiente oración:
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( secondary_location = SECONDARY_LOCATION);
Reemplaza lo siguiente:
ADMIN_PROJECT_IDpor el ID del proyecto de administración que posee el recurso de reservaLOCATIONpor la ubicación de la reserva, por ejemplo,europe-west9.RESERVATION_NAMEpor el nombre de la reserva. El nombre comenzar y terminar con una letra minúscula o un número, y contener solo letras minúsculas, números y guiones.SECONDARY_LOCATION: Es la ubicación secundaria de la reserva. En caso de una interrupción, los conjuntos de datos conectados a esta reserva conmutarán por error a esta ubicación.
Haz clic en Ejecutar.
Si deseas obtener información sobre cómo ejecutar consultas, visita Ejecuta una consulta interactiva.
Adjunta un conjunto de datos a una reserva
Si deseas habilitar la recuperación ante desastres para la reserva que creaste antes, completa los siguientes pasos. El conjunto de datos ya debe estar configurado para la replicación en las mismas regiones principales y secundarias de la reserva. Para obtener más información, consulta Replicación de conjuntos de datos entre regiones.
Console
En la consola de Google Cloud , ve a la página BigQuery.
En el menú de navegación, haz clic en Administración de capacidad y, luego, en la pestaña Reservas de ranuras.
Haz clic en la reserva a la que deseas conectar un conjunto de datos.
Haz clic en la pestaña Recuperación ante desastres.
Haz clic en Agregar conjunto de datos de conmutación por error.
Ingresa el nombre del conjunto de datos que deseas asociar a la reserva.
Haz clic en Agregar.
SQL
Para adjuntar un conjunto de datos a una reserva, usa la sentencia de DDL ALTER SCHEMA SET OPTIONS.
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, escribe la siguiente oración:
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = ADMIN_PROJECT_ID.RESERVATION_NAME);
Reemplaza lo siguiente:
DATASET_NAME: El nombre del conjunto de datos.ADMIN_PROJECT_ID.RESERVATION_NAME: Es el nombre de la reserva a la que deseas asociar el conjunto de datos.
Haz clic en Ejecutar.
Para obtener más información sobre cómo ejecutar consultas, visita Ejecuta una consulta interactiva.
Desconecta un conjunto de datos de una reserva
Para dejar de administrar el comportamiento de conmutación por error de un conjunto de datos a través de una reserva, desconecta el conjunto de datos de la reserva. Esto no cambia la réplica principal actual del conjunto de datos ni quita las réplicas existentes del conjunto de datos. Para obtener más información sobre cómo quitar réplicas de conjuntos de datos después de desconectar un conjunto de datos, consulta Quita réplicas de conjuntos de datos.
Console
En la consola de Google Cloud , ve a la página BigQuery.
En el menú de navegación, haz clic en Administración de capacidad y, luego, en la pestaña Reservas de ranuras.
Haz clic en la reserva de la que deseas desconectar un conjunto de datos.
Haz clic en la pestaña Recuperación ante desastres.
Expande la opción Acciones de la réplica principal del conjunto de datos.
Haz clic en Quitar.
SQL
Para desconectar un conjunto de datos de una reserva, usa la sentencia DDL ALTER SCHEMA SET OPTIONS.
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, escribe la siguiente oración:
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = NULL);
Reemplaza lo siguiente:
DATASET_NAME: El nombre del conjunto de datos.
Haz clic en Ejecutar.
Si deseas obtener información sobre cómo ejecutar consultas, visita Ejecuta una consulta interactiva.
Inicia una conmutación por error
Si se produce una interrupción regional, debes conmutar por error la reserva de forma manual a la ubicación que usa la réplica. En la conmutación por error de la reserva, también se incluyen los conjuntos de datos asociados. Para realizar una conmutación por error manual en una reserva, haz lo siguiente:
Console
En la consola de Google Cloud , ve a la página BigQuery.
En el menú de navegación, haga clic en Recuperación ante desastres.
Haz clic en el nombre de la reserva a la que deseas realizar una conmutación por error.
Selecciona Modo de conmutación por error forzada (predeterminado) o Modo de conmutación por error suave.
Haz clic en Conmutación por error.
SQL
Para agregar o cambiar una ubicación secundaria a una reserva, usa la sentencia de DDL ALTER RESERVATION SET OPTIONS y establece is_primary en TRUE.
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, escribe la siguiente oración:
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( is_primary = TRUE, failover_mode=FAILOVER_MODE);
Reemplaza lo siguiente:
ADMIN_PROJECT_IDpor el ID del proyecto de administración que posee el recurso de reservaLOCATION: Es la nueva ubicación principal de la reserva, es decir, la ubicación secundaria actual antes de la conmutación por error, por ejemplo,europe-west9.RESERVATION_NAMEpor el nombre de la reserva. El nombre comenzar y terminar con una letra minúscula o un número, y contener solo letras minúsculas, números y guiones.PRIMARY_STATUS: Es un estado booleano que declara si la reserva es la réplica principal.FAILOVER_MODE: Es un parámetro opcional que se usa para describir el modo de conmutación por error. Se puede establecer enHARDoSOFT. Si no se especifica este parámetro, se usaHARDde forma predeterminada.
Haz clic en Ejecutar.
Si deseas obtener información sobre cómo ejecutar consultas, visita Ejecuta una consulta interactiva.
Supervisión
Para determinar el estado de tus réplicas, consulta la vista INFORMATION_SCHEMA.SCHEMATA_REPLICAS. Por ejemplo:
SELECT schema_name, replica_name, creation_complete, replica_primary_assigned, replica_primary_assignment_complete FROM `region-LOCATION`.INFORMATION_SCHEMA.SCHEMATA_REPLICAS WHERE schema_name="my_dataset"
En la siguiente consulta, se muestran los trabajos de los últimos siete días que fallarían si sus conjuntos de datos fueran conjuntos de datos de conmutación por error:
WITH non_epe_reservations AS ( SELECT project_id, reservation_name FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.RESERVATIONS WHERE edition != 'ENTERPRISE_PLUS' ) SELECT * FROM ( SELECT job_id FROM ( SELECT job_id, reservation_id, ARRAY_CONCAT(referenced_tables, [destination_table]) AS all_referenced_tables, query FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.JOBS WHERE creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP() ) A, UNNEST(all_referenced_tables) AS referenced_table ) jobs LEFT OUTER JOIN non_epe_reservations ON ( jobs.reservation_id = CONCAT( non_epe_reservations.project_id, ':', 'LOCATION', '.', non_epe_reservations.reservation_name)) WHERE CONCAT(jobs.project_id, ':', jobs.dataset_id) IN UNNEST( [ 'PROJECT_ID:DATASET_ID', 'PROJECT_ID:DATASET_ID']);
Reemplaza lo siguiente:
PROJECT_ID: El ID del proyecto.DATASET_ID: El ID del conjunto de datos.LOCATION: La ubicación.
¿Qué sigue?
Obtén más información sobre la replicación de conjuntos de datos entre regiones.
Obtén más información sobre la confiabilidad.