Verwaltete Notfallwiederherstellung
Dieses Dokument bietet einen Überblick über die von BigQuery verwaltete Notfallwiederherstellung und deren Implementierung für Ihre Daten und Arbeitslasten.
Übersicht
BigQuery unterstützt Szenarien der Notfallwiederherstellung im Falle eines Gesamtausfalls der Region. Die BigQuery-Notfallwiederherstellung basiert auf der regionenübergreifenden Dataset-Replikation, um den Speicher-Failover zu verwalten. Nachdem Sie ein Dataset-Replikat in einer sekundären Region erstellt haben, können Sie das Failover-Verhalten für Computing und Speicher steuern, um die Geschäftskontinuität während eines Ausfalls aufrechtzuerhalten. Nach einem Failover können Sie auf Rechenkapazität (Slots) und replizierte Datasets in der hochgestuften Region zugreifen. Die Notfallwiederherstellung wird nur in Enterprise Plus unterstützt.
Die verwaltete Notfallwiederherstellung bietet zwei Failover-Optionen: hartes Failover und weiches Failover. Bei einem harten Failover werden die Reservierungs- und Dataset-Replikate der sekundären Region sofort zum primären Knoten hochgestuft. Diese Aktion wird auch dann ausgeführt, wenn die aktuelle primäre Region offline ist. Es wird nicht auf die Replikation nicht replizierter Daten gewartet. Aus diesem Grund kann es bei einem harten Failover zu Datenverlusten kommen.
Alle Jobs, für die ein Commit für Daten in der Quellregion vor dem Wert von replication_time des Replikats durchgeführt wurde, müssen nach dem Failover in der Zielregion evtl. noch einmal ausgeführt werden.
Im Gegensatz zu einem harten Failover wird bei einem weichen Failover gewartet, bis alle in der primären Region ausgeführten Änderungen an Reservierungen und Datasets in die sekundäre Region repliziert wurden, bevor der Failover abgeschlossen wird. Für ein Soft-Failover müssen sowohl die primäre als auch die sekundäre Region verfügbar sein.
Wenn Sie ein Soft-Failover initiieren, wird die softFailoverStartTime für die Reservierung festgelegt. Der softFailoverStartTime wird nach Abschluss des vorläufigen Failovers gelöscht.
Zur Aktivierung der Notfallwiederherstellung müssen Sie eine Enterprise Plus-Reservierung in der primären Region erstellen. Das ist die Region, in der sich das Dataset vor dem Failover befindet. Die Standby-Rechenkapazität in der gekoppelten Region ist in der Enterprise Plus-Reservierung enthalten. Anschließend hängen Sie ein Dataset an diese Reservierung an, um den Failover für dieses Dataset zu aktivieren. Sie können ein Dataset nur dann an eine Reservierung anhängen, wenn ein Backfill für das Dataset durchgeführt wurde und es dieselben gekoppelten primären und sekundären Standorte wie die Reservierung hat. Nachdem ein Dataset an eine Failover-Reservierung angehängt wurde, können nur Enterprise Plus-Reservierungen in diese Datasets schreiben und Sie können keine regionenübergreifende Replikationshochstufung für das Dataset durchführen. Sie können mit jedem Kapazitätsmodell Daten aus Datasets lesen, die an eine Failover-Reservierung angehängt sind. Weitere Informationen zu Reservierungen finden Sie unter Einführung in die Arbeitslastverwaltung.
Die Rechenkapazität Ihrer primären Region ist in der sekundären Region unmittelbar nach einem Failover verfügbar. Diese Verfügbarkeit gilt für Ihre Reservierungsreferenz, unabhängig davon, ob sie verwendet wird oder nicht.
Sie müssen das Failover aktiv im Rahmen von Tests oder als Reaktion auf einen echten Notfall auswählen. Sie sollten in einem 10-Minuten-Fenster nicht mehr als einmal Failover ausführen. In Szenarien der Datenreplikation bezieht sich Backfill auf den Vorgang, bei dem ein Replikat eines Datasets mit Verlaufsdaten gefüllt wird, die vor dem Erstellen oder Aktivieren des Replikats vorhanden waren. Datasets müssen ihren Backfill abschließen, bevor ein Failover auf das Dataset möglich ist.
Das folgende Diagramm zeigt die Architektur der verwalteten Notfallwiederherstellung:
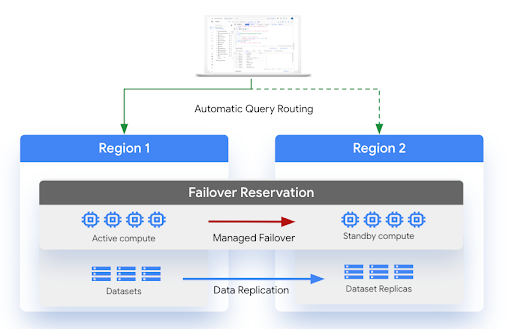
Beschränkungen
Für die BigQuery-Notfallwiederherstellung gelten die folgenden Einschränkungen:
Die BigQuery-Notfallwiederherstellung unterliegt den gleichen Einschränkungen wie die regionenübergreifende Dataset-Replikation.
Das Autoscaling nach einem Failover hängt von der Verfügbarkeit der Rechenkapazität in der sekundären Region ab. In der sekundären Region ist nur die Reservierungsreferenz verfügbar.
Die
INFORMATION_SCHEMA.RESERVATIONS-Ansicht enthält keine Failover-Details.Wenn Sie mehrere Failover-Reservierungen mit demselben Administrationsprojekt haben, deren angehängte Datasets jedoch unterschiedliche sekundäre Standorte verwenden, sollten Sie keine Failover-Reservierung mit den Datasets verwenden, die an eine andere Failover-Reservierung angehängt sind.
Wenn Sie eine vorhandene Reservierung in eine Failover-Reservierung umwandeln möchten, darf die vorhandene Reservierung nicht mehr als 1.000 Reservierungszuweisungen haben.
Einer Failover-Reservierung dürfen nicht mehr als 1.000 Datasets zugeordnet sein.
Ein Soft-Failover kann nur ausgelöst werden, wenn sowohl die Quell- als auch die Zielregion verfügbar sind.
Ein Soft-Failover kann nicht ausgelöst werden, wenn während der Reservierungsreplikation vorübergehende oder andere Fehler auftreten. Beispiel: Wenn in der sekundären Region nicht genügend Kontingent für Slots für die Reservierungsaktualisierung vorhanden ist.
Die Reservierung und die zugehörigen Datasets können während eines aktiven Soft-Failovers nicht aktualisiert werden, sie können aber weiterhin gelesen werden.
Jobs, die während eines aktiven Soft-Failovers auf einer Failover-Reservierung ausgeführt werden, können aufgrund vorübergehender Änderungen im Dataset und im Reservierungsrouting während des Failover-Vorgangs möglicherweise nicht auf der Reservierung ausgeführt werden. Bei diesen Jobs werden jedoch die Reservierungsslots vor und nach einem Soft-Failover verwendet.
Standorte
Die folgenden Regionen sind beim Erstellen einer Failover-Reservierung verfügbar:
| Positionscode | Name der Region | Beschreibung der Region |
|---|---|---|
ASIA |
||
ASIA-EAST1 |
Taiwan | |
ASIA-SOUTHEAST1 |
Singapur | |
AU |
||
AUSTRALIA-SOUTHEAST1 |
Sydney | |
AUSTRALIA-SOUTHEAST2 |
Melbourne | |
CA |
||
NORTHAMERICA-NORTHEAST1 |
Montreal | |
NORTHAMERICA-NORTHEAST2 |
Toronto | |
DE |
||
EUROPE-WEST3 |
Frankfurt | |
EUROPE-WEST10 |
Berlin | |
EU |
||
EU |
EU (mehrere Regionen) | |
EUROPE-CENTRAL2 |
Warschau | |
EUROPE-NORTH1 |
Finnland | |
EUROPE-SOUTHWEST1 |
Madrid | |
EUROPE-WEST1 |
Belgien | |
EUROPE-WEST3 |
Frankfurt | |
EUROPE-WEST4 |
Niederlande | |
EUROPE-WEST8 |
Mailand | |
EUROPE-WEST9 |
Paris | |
IN |
||
ASIA-SOUTH1 |
Mumbai | |
ASIA-SOUTH2 |
Delhi | |
US |
||
US |
USA (mehrere Regionen) | |
US-CENTRAL1 |
Iowa | |
US-EAST1 |
South Carolina | |
US-EAST4 |
Northern Virginia | |
US-EAST5 |
Columbus | |
US-SOUTH1 |
Dallas | |
US-WEST1 |
Oregon | |
US-WEST2 |
Los Angeles | |
US-WEST3 |
Salt Lake City | |
US-WEST4 |
Las Vegas |
Regionenpaare müssen in ASIA, AU, CA, DE, EU, IN oder US ausgewählt werden. So kann beispielsweise eine Region innerhalb von US nicht mit einer Region innerhalb von EU gekoppelt werden.
Wenn sich Ihr BigQuery-Dataset an einem multiregionalen Standort befindet, können Sie die folgenden Regionspaare nicht verwenden. Diese Einschränkung ist erforderlich, damit Ihre Failover-Reservierung und Ihre Daten nach der Replikation geografisch getrennt sind. Weitere Informationen zu Regionen, die in Standorten mit mehreren Regionen enthalten sind, finden Sie unter Standorte mit mehreren Regionen.
- Multiregion
us-central1-us - Multiregion
us-west1-us - Multiregion
eu-west1-eu - Multiregion
eu-west4-eu
Hinweise
- Prüfen Sie, ob Sie die IAM-Berechtigung (Identity and Access Management)
bigquery.reservations.updatezum Aktualisieren von Reservierungen haben. - Prüfen Sie, ob bereits Datasets für die Replikation konfiguriert sind. Weitere Informationen finden Sie unter Dataset replizieren.
Schnelle Replikation
Bei der Notfallwiederherstellung wird die Turboreplikation für eine schnellere Datenreplikation über Regionen hinweg verwendet, was das Risiko eines Datenverlusts verringert, die Dienstausfallzeiten minimiert und einen unterbrechungsfreien Dienst nach einem regionalen Ausfall unterstützt.
Die Turboreplikation gilt nicht für den anfänglichen Backfill-Vorgang. Nach Abschluss des ersten Backfill-Vorgangs werden Datasets mit der Turboreplikation innerhalb von 15 Minuten in einem einzelnen Failover-Regionen-Paar mit einer sekundären Replik repliziert, sofern das Bandbreitenkontingent nicht überschritten wird und keine Nutzerfehler auftreten.
Recovery Time Objective
Ein Recovery Time Objective (RTO) ist die Zielzeit, die für die Wiederherstellung in BigQuery im Falle eines Notfalls zulässig ist. Weitere Informationen zu RTO finden Sie unter Grundlagen der Planung der Notfallwiederherstellung.Die verwaltete Notfallwiederherstellung hat eine RTO von fünf Minuten, nachdem Sie ein Failover initiiert haben. Aufgrund des RTO ist die Kapazität in der sekundären Region innerhalb von fünf Minuten nach Beginn des Failover-Prozesses verfügbar.
Recovery Point Objective
Das Recovery Point Objective (RPO) ist der letzte Zeitpunkt, ab dem Daten wiederhergestellt werden können. Weitere Informationen zum RPO finden Sie unter Grundlagen der Planung der Notfallwiederherstellung. Die verwaltete Notfallwiederherstellung hat einen RPO, der pro Dataset definiert wird. Das RPO soll das sekundäre Replikat innerhalb von 15 Minuten nach dem primären Replikat halten. Um dieses RPO zu erreichen, dürfen Sie das Bandbreitenkontingent nicht überschreiten und es darf keine Nutzerfehler geben.
Kontingent
Sie müssen die ausgewählte Rechenkapazität in der sekundären Region haben, bevor Sie eine Failover-Reservierung konfigurieren. Wenn in der sekundären Region kein Kontingent verfügbar ist, können Sie die Reservierung nicht konfigurieren oder aktualisieren. Weitere Informationen finden Sie unter Kontingente und Limits.
Für die Bandbreite der schnellen Replikation gilt ein Kontingent. Weitere Informationen finden Sie unter Kontingente und Limits.
Preise
Für die Konfiguration einer verwalteten Notfallwiederherstellung sind die folgenden Preismodelle erforderlich:
Rechenkapazität: Sie müssen die Enterprise Plus-Version erwerben.
Turboreplikation: Die Notfallwiederherstellung basiert auf der Turboreplikation während der Replikation. Die Gebühren richten sich nach physischen Byte und den replizierten physischen GiB. Weitere Informationen finden Sie unter Preise für die Datenübertragung bei der Datenreplikation für die Turbo-Replikation.
Speicher: Speicherbyte in der sekundären Region werden zum gleichen Preis wie Speicherbyte in der primären Region abgerechnet. Weitere Informationen finden Sie unter Speicherpreise.
Kunden müssen nur für die Rechenkapazität in der primären Region bezahlen. Die sekundäre Rechenkapazität (basierend auf der Reservierungsreferenz) ist in der sekundären Region ohne zusätzliche Kosten verfügbar. Inaktive Slots können die sekundäre Rechenkapazität nur verwenden, wenn für die Reservierung ein Failover durchgeführt wurde.
Wenn Sie veraltete Lesevorgänge in der sekundären Region ausführen müssen, müssen Sie zusätzliche Rechenkapazität erwerben.
Enterprise Plus-Reservierung erstellen oder ändern
Bevor Sie ein Dataset an eine Reservierung anhängen, müssen Sie eine Enterprise Plus-Reservierung erstellen oder eine vorhandene Reservierung ändern und für die Notfallwiederherstellung konfigurieren.
Reservierung erstellen
Entscheiden Sie sich für eine der folgenden Möglichkeiten:
Console
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Klicken Sie im Navigationsmenü auf Kapazitätsverwaltung und dann auf Reservierung erstellen.
Geben Sie im Feld Name der Reservierung einen Namen für die Reservierung ein.
Wählen Sie in der Liste Standort einen Standort aus.
Wählen Sie in der Liste Version die Enterprise Plus-Version aus.
Wählen Sie in der Liste Maximale Reservierungsgröße die maximale Reservierungsgröße aus.
Optional: Geben Sie im Feld Referenz-Slots die Anzahl der Referenz-Slots für die Reservierung ein.
Die Anzahl der verfügbaren Autoscaling-Slots wird bestimmt, indem der Wert für Referenz-Slots vom Wert Maximale Reservierungsgröße abgezogen wird. Wenn Sie beispielsweise eine Reservierung mit 100 Referenz-Slots und einer maximalen Reservierungsgröße von 400 erstellen, hat Ihre Reservierung 300 Autoscaling-Slots. Weitere Informationen zu Referenz-Slots finden Sie unter Reservierungen mit Slots für Referenz und Autoscaling verwenden.
Wählen Sie in der Liste Sekundärer Standort den sekundären Standort aus.
Wenn Sie die Freigabe inaktiver Slots deaktivieren und nur die angegebene Slotkapazität verwenden möchten, klicken Sie auf die Schaltfläche Inaktive Slots ignorieren.
Klicken Sie zum Erweitern des Abschnitts Erweiterte Einstellungen auf den Erweiterungspfeil.
Optional: Um die Zielnebenläufigkeit von Jobs festzulegen, klicken und aktivieren Sie die Schaltfläche Automatische Zielnebenläufigkeit von Jobs überschreiben und geben Sie einen Wert für die Zielnebenläufigkeit von Jobs ein. Die Aufschlüsselung der Slots wird in der Tabelle Kostenschätzung angezeigt. In der Tabelle Kapazitätsübersicht wird eine Zusammenfassung der Reservierung angezeigt.
Klicken Sie auf Speichern.
Die neue Reservierung ist auf dem Tab Slot-Reservierungen zu sehen.
SQL
Verwenden Sie zum Erstellen einer Reservierung die DDL-Anweisung CREATE RESERVATION.
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende Anweisung ein:
CREATE RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` OPTIONS ( slot_capacity = NUMBER_OF_BASELINE_SLOTS, edition = ENTERPRISE_PLUS, secondary_location = SECONDARY_LOCATION);
Ersetzen Sie Folgendes:
ADMIN_PROJECT_ID: die Projekt-ID des Administrationsprojekts, dem die Reservierungsressource gehörtLOCATION: Der Standort der Reservierung. Wenn Sie einen BigQuery Omni-Standort auswählen, ist Ihre Versionsoption auf die Enterprise-Version beschränkt.RESERVATION_NAME: der Name der ReservierungDer Name muss mit einem Kleinbuchstaben oder einer Zahl beginnen und enden. Er darf nur Kleinbuchstaben, Ziffern und Bindestriche enthalten.
NUMBER_OF_BASELINE_SLOTS: die Anzahl der Slots, die der Reservierung zugewiesen werden sollen. Sie können die Optionenslot_capacityundeditionnicht in derselben Reservierung festlegen.SECONDARY_LOCATION: der sekundäre Standort der Reservierung. Bei einem Ausfall wird für alle mit dieser Reservierung verknüpften Datasets ein Failover zu diesem Standort ausgeführt.
Klicken Sie auf Ausführen.
Informationen zum Ausführen von Abfragen finden Sie unter Interaktive Abfrage ausführen.
Vorhandene Reservierung ändern
Entscheiden Sie sich für eine der folgenden Möglichkeiten:
Console
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Klicken Sie im Navigationsmenü auf Kapazitätsverwaltung.
Klicken Sie auf den Tab Slot-Reservierungen.
Suchen Sie die Reservierung, die Sie aktualisieren möchten.
Klicken Sie auf Reservierungsaktionen und dann auf Bearbeiten.
Geben Sie im Feld Sekundärer Standort den sekundären Standort ein.
Klicken Sie auf Speichern.
SQL
Mit der DDL-Anweisung ALTER RESERVATION SET OPTIONS können Sie einen sekundären Standort zu einer Reservierung hinzufügen oder ändern.
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende Anweisung ein:
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( secondary_location = SECONDARY_LOCATION);
Ersetzen Sie Folgendes:
ADMIN_PROJECT_ID: die Projekt-ID des Administrationsprojekts, dem die Reservierungsressource gehörtLOCATION: der Standort der Reservierung, z. B.europe-west9.RESERVATION_NAME: der Name der Reservierung Der Name muss mit einem Kleinbuchstaben oder einer Zahl beginnen und enden. Er darf nur Kleinbuchstaben, Ziffern und Bindestriche enthalten.SECONDARY_LOCATION: der sekundäre Standort der Reservierung. Bei einem Ausfall wird für alle mit dieser Reservierung verknüpften Datasets ein Failover zu diesem Standort ausgeführt.
Klicken Sie auf Ausführen.
Informationen zum Ausführen von Abfragen finden Sie unter Interaktive Abfrage ausführen.
Dataset an eine Reservierung anhängen
Führen Sie die folgenden Schritte aus, um die Notfallwiederherstellung für die zuvor erstellte Reservierung zu aktivieren. Das Dataset muss bereits für die Replikation in derselben primären und sekundären Region wie die Reservierung konfiguriert sein. Weitere Informationen finden Sie unter Regionenübergreifende Dataset-Replikation.
Console
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Klicken Sie im Navigationsmenü auf Kapazitätsverwaltung und dann auf den Tab Slot-Reservierungen.
Klicken Sie auf die Reservierung, an die Sie ein Dataset anhängen möchten.
Klicken Sie auf den Tab Notfallwiederherstellung.
Klicken Sie auf Failover-Dataset hinzufügen.
Geben Sie den Namen des Datasets ein, das Sie mit der Reservierung verknüpfen möchten.
Klicken Sie auf Hinzufügen.
SQL
Mit der DDL-Anweisung ALTER SCHEMA SET OPTIONS können Sie ein Dataset an eine Reservierung anhängen.
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende Anweisung ein:
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = ADMIN_PROJECT_ID.RESERVATION_NAME);
Ersetzen Sie Folgendes:
DATASET_NAME: der Name des DatasetsADMIN_PROJECT_ID.RESERVATION_NAME: der Name der Reservierung, der Sie das Dataset zuordnen möchten.
Klicken Sie auf Ausführen.
Informationen zum Ausführen von Abfragen finden Sie unter Interaktive Abfrage ausführen.
Dataset von einer Reservierung trennen
Wenn Sie das Failover-Verhalten eines Datasets nicht mehr über eine Reservierung verwalten möchten, trennen Sie das Dataset von der Reservierung. Das aktuelle primäre Replikat für das Dataset wird dadurch nicht geändert und vorhandene Dataset-Replikate werden nicht entfernt. Weitere Informationen zum Entfernen von Dataset-Replikaten nach dem Trennen eines Datasets finden Sie unter Dataset-Replikat entfernen.
Console
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Klicken Sie im Navigationsmenü auf Kapazitätsverwaltung und dann auf den Tab Slot-Reservierungen.
Klicken Sie auf die Reservierung, von der Sie ein Dataset trennen möchten.
Klicken Sie auf den Tab Notfallwiederherstellung.
Maximieren Sie die Option Aktionen für das primäre Replikat des Datasets.
Klicken Sie auf Entfernen.
SQL
Mit der DDL-Anweisung ALTER SCHEMA SET OPTIONS können Sie ein Dataset von einer Reservierung trennen.
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende Anweisung ein:
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = NULL);
Ersetzen Sie Folgendes:
DATASET_NAME: der Name des Datasets
Klicken Sie auf Ausführen.
Informationen zum Ausführen von Abfragen finden Sie unter Interaktive Abfrage ausführen.
Failover auslösen
Bei einem regionalen Ausfall müssen Sie Ihre Reservierung manuell an den Standort übertragen, der vom Replikat verwendet wird. Das Failover der Reservierung umfasst auch alle zugehörigen Datasets. So führen Sie ein manuelles Failover für eine Reservierung aus:
Console
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Klicken Sie im Navigationsmenü auf Notfallwiederherstellung.
Klicken Sie auf den Namen der Reservierung, für die Sie ein Failover ausführen möchten.
Wählen Sie entweder Modus für harten Failover (Standardeinstellung) oder Modus für weichen Failover aus.
Klicken Sie auf Failover.
SQL
Verwenden Sie die DDL-Anweisung ALTER RESERVATION SET OPTIONS und setzen Sie is_primary auf TRUE, um einen sekundären Standort zu einer Reservierung hinzuzufügen oder zu ändern.
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende Anweisung ein:
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( is_primary = TRUE, failover_mode=FAILOVER_MODE);
Ersetzen Sie Folgendes:
ADMIN_PROJECT_ID: die Projekt-ID des Administrationsprojekts, dem die Reservierungsressource gehörtLOCATION: der neue primäre Standort der Reservierung, d. h. der aktuelle sekundäre Standort vor dem Failover, z. B.europe-west9.RESERVATION_NAME: der Name der Reservierung Der Name muss mit einem Kleinbuchstaben oder einer Zahl beginnen und enden. Er darf nur Kleinbuchstaben, Ziffern und Bindestriche enthalten.PRIMARY_STATUS: ein boolescher Status, der angibt, ob die Reservierung das primäre Replikat ist.FAILOVER_MODE: Ein optionaler Parameter, der zur Beschreibung des Failover-Modus verwendet wird. Dies kann entweder aufHARDoderSOFTfestgelegt werden. Wenn dieser Parameter nicht angegeben ist, wird standardmäßigHARDverwendet.
Klicken Sie auf Ausführen.
Informationen zum Ausführen von Abfragen finden Sie unter Interaktive Abfrage ausführen.
Monitoring
Fragen Sie die Ansicht INFORMATION_SCHEMA.SCHEMATA_REPLICAS ab, um den Status der Replikate zu ermitteln. Beispiel:
SELECT schema_name, replica_name, creation_complete, replica_primary_assigned, replica_primary_assignment_complete FROM `region-LOCATION`.INFORMATION_SCHEMA.SCHEMATA_REPLICAS WHERE schema_name="my_dataset"
Die folgende Abfrage gibt die Jobs der letzten sieben Tage zurück, die fehlschlagen würden, wenn ihre Datasets Failover-Datasets wären:
WITH non_epe_reservations AS ( SELECT project_id, reservation_name FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.RESERVATIONS WHERE edition != 'ENTERPRISE_PLUS' ) SELECT * FROM ( SELECT job_id FROM ( SELECT job_id, reservation_id, ARRAY_CONCAT(referenced_tables, [destination_table]) AS all_referenced_tables, query FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.JOBS WHERE creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP() ) A, UNNEST(all_referenced_tables) AS referenced_table ) jobs LEFT OUTER JOIN non_epe_reservations ON ( jobs.reservation_id = CONCAT( non_epe_reservations.project_id, ':', 'LOCATION', '.', non_epe_reservations.reservation_name)) WHERE CONCAT(jobs.project_id, ':', jobs.dataset_id) IN UNNEST( [ 'PROJECT_ID:DATASET_ID', 'PROJECT_ID:DATASET_ID']);
Ersetzen Sie Folgendes:
PROJECT_ID: Projekt-ID.DATASET_ID: Die Dataset-ID.LOCATION: der Standort.
Nächste Schritte
Weitere Informationen zur regionenübergreifenden Dataset-Replikation
Weitere Informationen zur Zuverlässigkeit.