관리형 재해 복구
이 문서에서는 BigQuery 관리 재해 복구에 대한 개요와 데이터 및 워크로드에 이를 구현하는 방법을 설명합니다.
개요
BigQuery는 전체 리전 중단이 발생할 경우를 대비한 재해 복구 시나리오를 지원합니다. BigQuery 재해 복구는 리전 간 데이터 세트 복제를 사용하여 스토리지 장애 조치를 관리합니다. 보조 리전에 데이터 세트 복제본을 만든 후에 서비스 중단 시 비즈니스 연속성을 유지하도록 컴퓨팅 및 스토리지의 장애 조치 동작을 제어할 수 있습니다. 장애 조치 후 승격된 리전에서 컴퓨팅 용량(슬롯)과 복제된 데이터 세트에 액세스할 수 있습니다. 재해 복구는 Enterprise Plus 버전에서만 지원됩니다.
관리형 재해 복구는 하드 장애 조치와 소프트 장애 조치라는 두 가지 장애 조치 옵션을 제공합니다. 하드 장애 조치는 보조 리전의 예약 및 데이터 세트 복제본을 즉시 승격하여 기본 리전이 되도록 합니다. 이 작업은 현재 기본 리전이 오프라인 상태인 경우에도 진행되며 복제되지 않은 데이터의 복제를 기다리지 않습니다. 이로 인해 강제 장애 조치 중에 데이터 손실이 발생할 수 있습니다.
복제본의 replication_time 값 전에 소스 리전에서 데이터를 커밋한 모든 작업은 장애 조치 후 대상 리전에서 다시 실행해야 할 수 있습니다.
하드 장애 조치와 달리 소프트 장애 조치는 기본 리전에서 커밋된 모든 예약 및 데이터 세트 변경사항이 보조 리전으로 복제될 때까지 기다린 후 장애 조치 프로세스를 완료합니다. 소프트 장애 조치를 사용하려면 기본 리전과 보조 리전이 모두 사용 가능해야 합니다.
소프트 장애 조치를 시작하면 예약의 softFailoverStartTime가 설정됩니다. softFailoverStartTime은 소프트 장애 조치 완료 시 삭제됩니다.
재해 복구를 사용 설정하려면 장애 조치 전에 데이터 세트가 있는 리전인 기본 리전에 Enterprise Plus 버전 예약을 만들어야 합니다. 페어링된 리전의 대기 컴퓨팅 용량은 Enterprise Plus 예약에 포함됩니다. 그런 다음 데이터 세트를 이 예약에 연결하여 해당 데이터 세트의 장애 조치를 사용 설정합니다. 데이터 세트가 백필되고 예약과 동일한 페어링된 기본 및 보조 위치가 있는 경우에만 데이터 세트를 예약에 연결할 수 있습니다. 데이터 세트가 장애 조치 예약에 연결된 후에 Enterprise Plus 예약만 해당 데이터 세트를 쓸 수 있으며 데이터 세트에서 리전 간 복제 승격을 수행할 수 없습니다. 모든 용량 모델을 사용하여 장애 조치 예약에 연결된 데이터 세트에서 읽을 수 있습니다. 예약에 대한 자세한 내용은 워크로드 관리 소개를 참조하세요.
기본 리전의 컴퓨팅 용량은 장애 조치 직후 보조 리전에서 사용할 수 있습니다. 이 가용성은 사용 여부에 관계없이 예약 기준에 적용됩니다.
테스트의 일환으로 또는 실제 재해에 대응하여 장애 조치를 적극적으로 선택해야 합니다. 장애 조치를 10분 안에 두 번 이상 수행하지 않아야 합니다. 데이터 복제 시나리오에서 백필은 복제본이 생성되거나 활성화되기 전에 존재했던 이전 데이터로 데이터 세트의 복제본을 채우는 프로세스를 의미합니다. 데이터 세트로 장애 조치하려면 데이터 세트의 백필이 완료되어야 합니다.
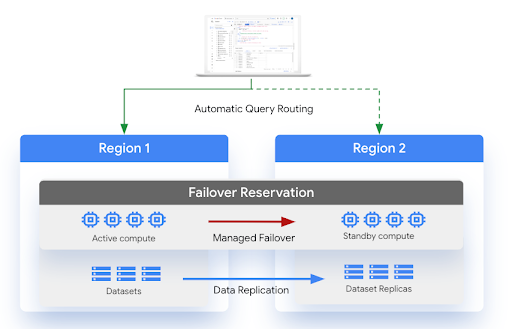
다음 다이어그램은 관리형 재해 복구의 아키텍처를 보여줍니다.
제한사항
BigQuery 재해 복구에는 다음 제한사항이 적용됩니다.
BigQuery 재해 복구에는 리전 간 데이터 세트 복제와 동일한 제한사항이 적용됩니다.
장애 조치 후 자동 확장은 보조 리전의 컴퓨팅 용량 가용성에 따라 달라집니다. 보조 리전에서는 예약 기준만 사용할 수 있습니다.
INFORMATION_SCHEMA.RESERVATIONS뷰에는 장애 조치 세부정보가 없습니다.동일한 관리 프로젝트에 속하지만 연결된 데이터 세트가 서로 다른 보조 위치를 사용하는 장애 복구 예약이 여러 개 있는 경우, 다른 장애 복구 예약에 연결된 데이터 세트가 있는 장애 복구 예약을 사용하지 마세요.
기존 예약을 장애 조치 예약으로 변환하려면 기존 예약에 예약 할당이 1,000개를 초과할 수 없습니다.
장애 조치 예약에는 1,000개가 넘는 데이터 세트를 연결할 수 없습니다.
소프트 장애 조치는 소스 및 대상 리전을 모두 사용할 수 있는 경우에만 트리거할 수 있습니다.
예약 복제 중에 일시적이거나 그 밖의 오류가 있는 경우 소프트 장애 조치를 트리거할 수 없습니다. 예를 들어 예약 업데이트를 위한 보조 리전의 슬롯 할당량이 부족한 경우입니다.
활성 소프트 장애 조치 중에는 예약 및 연결된 데이터 세트를 업데이트할 수 없지만 계속 읽을 수는 있습니다.
활성 소프트 장애 조치 중에 장애 조치 예약에서 실행되는 작업은 장애 조치 작업 중에 데이터 세트 및 예약 라우팅이 일시적으로 변경되어 예약에서 실행되지 않을 수 있습니다. 하지만 이러한 작업은 소프트 장애 조치가 시작되기 전과 완료된 후에 예약 슬롯을 사용합니다.
위치
장애 조치 예약 생성 시 사용할 수 있는 리전은 다음과 같습니다.
| 위치 코드 | 리전 이름 | 리전 설명 |
|---|---|---|
ASIA |
||
ASIA-EAST1 |
타이완 | |
ASIA-SOUTHEAST1 |
싱가포르 | |
AU |
||
AUSTRALIA-SOUTHEAST1 |
시드니 | |
AUSTRALIA-SOUTHEAST2 |
멜버른 | |
CA |
||
NORTHAMERICA-NORTHEAST1 |
몬트리올 | |
NORTHAMERICA-NORTHEAST2 |
토론토 | |
DE |
||
EUROPE-WEST3 |
프랑크푸르트 | |
EUROPE-WEST10 |
베를린 | |
EU |
||
EU |
EU 멀티 리전 | |
EUROPE-CENTRAL2 |
바르샤바 | |
EUROPE-NORTH1 |
핀란드 | |
EUROPE-SOUTHWEST1 |
마드리드 | |
EUROPE-WEST1 |
벨기에 | |
EUROPE-WEST3 |
프랑크푸르트 | |
EUROPE-WEST4 |
네덜란드 | |
EUROPE-WEST8 |
밀라노 | |
EUROPE-WEST9 |
파리 | |
IN |
||
ASIA-SOUTH1 |
뭄바이 | |
ASIA-SOUTH2 |
델리 | |
US |
||
US |
미국 멀티 리전 | |
US-CENTRAL1 |
아이오와 | |
US-EAST1 |
사우스캐롤라이나 | |
US-EAST4 |
북버지니아 | |
US-EAST5 |
콜럼버스 | |
US-SOUTH1 |
댈러스 | |
US-WEST1 |
오리건 | |
US-WEST2 |
로스앤젤레스 | |
US-WEST3 |
솔트레이크시티 | |
US-WEST4 |
라스베이거스 |
리전 쌍은 ASIA, AU, CA, DE, EU, IN 또는 US 내에서 선택해야 합니다. 예를 들어 US 내의 리전은 EU 내의 리전과 페어링할 수 없습니다.
BigQuery 데이터 세트가 멀티 리전 위치에 있으면 다음 리전 쌍을 사용할 수 없습니다. 이 제한사항은 복제 후 장애 조치 예약 및 데이터가 지리적으로 분리되도록 하기 위해 필요합니다. 멀티 리전에 포함된 리전에 관한 자세한 내용은 멀티 리전을 참고하세요.
us-central1-us멀티 리전us-west1-us멀티 리전eu-west1-eu멀티 리전eu-west4-eu멀티 리전
시작하기 전에
- 예약을 업데이트할 수 있는
bigquery.reservations.updateIdentity and Access Management (IAM) 권한이 있는지 확인합니다. - 복제용으로 구성된 기존 데이터 세트가 있는지 확인합니다. 자세한 내용은 데이터 세트 복제를 참조하세요.
터보 복제
재해 복구는 터보 복제를 사용하여 리전 간 데이터를 더 빠르게 복제하므로 데이터 손실 노출 위험을 줄이고 서비스 다운타임을 최소화하며 리전 서비스 중단 후 중단 없는 서비스 지원을 돕습니다.
터보 복제는 초기 백필 작업에 적용되지 않습니다. 초기 백필 작업이 완료된 후 터보 복제는 대역폭 할당량이 초과되지 않고 사용자 오류가 없는 한 15분 이내에 보조 복제본이 있는 단일 장애 조치 리전 쌍에 데이터 세트를 복제하는 것을 목표로 합니다.
복구 시간 목표
복구 시간 목표 (RTO)는 재해 발생 시 BigQuery에서 복구에 허용되는 목표 시간입니다. RTO에 대한 자세한 내용은 DR 계획의 기본사항을 참고하세요.관리형 재해 복구는 장애 조치를 시작한 후 RTO가 5분입니다. RTO로 인해 장애 조치 프로세스를 시작한 후 5분 이내에 보조 리전에서 용량을 사용할 수 있습니다.
복구 지점 목표
복구 지점 목표 (RPO)는 데이터를 복원할 수 있어야 하는 가장 최근 시점입니다. RPO에 대한 자세한 내용은 DR 계획의 기본사항을 참고하세요. 관리형 재해 복구의 RPO는 데이터 세트별로 정의됩니다. RPO는 보조 복제본을 기본 복제본에서 15분 이내로 유지하는 것을 목표로 합니다. 이 RPO를 충족하려면 대역폭 할당량을 초과할 수 없으며 사용자 오류가 없어야 합니다.
할당량
장애 조치 예약 구성 전에 보조 리전에 선택한 컴퓨팅 용량이 있어야 합니다. 보조 리전에 사용 가능한 할당량이 없으면 예약을 구성하거나 업데이트할 수 없습니다. 자세한 내용은 할당량 및 한도를 참조하세요.
터보 복제 대역폭에는 할당량이 있습니다. 자세한 내용은 할당량 및 한도를 참조하세요.
가격 책정
관리형 재해 복구를 구성하려면 다음 요금제가 필요합니다.
컴퓨팅 용량: Enterprise Plus 버전을 구매해야 합니다.
터보 복제: 재해 복구는 복제 중에 터보 복제를 사용합니다. 물리적 바이트 및 복제된 실제 GiB당 요금이 청구됩니다. 자세한 내용은 터보 복제를 위한 데이터 복제 데이터 전송 가격 책정을 참고하세요.
스토리지: 보조 리전의 스토리지 바이트는 기본 리전의 스토리지 바이트와 동일한 가격으로 청구됩니다. 자세한 내용은 스토리지 가격 책정을 참조하세요.
고객은 기본 리전의 컴퓨팅 용량에 대해서만 비용을 지불하면 됩니다. (예약 기준에 따른) 보조 컴퓨팅 용량은 추가 비용 없이 보조 리전에서 사용할 수 있습니다. 유휴 슬롯은 예약이 장애 조치되지 않는 한 보조 컴퓨팅 용량을 사용할 수 없습니다.
보조 리전에서 비활성 읽기를 수행해야 하는 경우 추가 컴퓨팅 용량을 구매해야 합니다.
Enterprise Plus 예약 만들기 또는 변경
데이터 세트를 예약에 연결하기 전에 Enterprise Plus 예약을 만들거나 기존 예약을 변경하여 재해 복구를 위해 구성해야 합니다.
예약 만들기
다음 중 하나를 선택합니다.
콘솔
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
탐색 메뉴에서 용량 관리를 클릭한 다음 예약 만들기를 클릭합니다.
예약 이름 필드에 예약 이름을 입력합니다.
위치 목록에서 위치를 선택합니다.
버전 목록에서 Enterprise Plus 버전을 선택합니다.
최대 예약 크기 선택기 목록에서 최대 예약 크기를 선택합니다.
선택사항: 기준 슬롯 필드에 예약의 기준 슬롯 수를 입력합니다.
사용 가능한 자동 확장 슬롯 수는 최대 예약 크기 값에서 기준 슬롯 값을 빼서 구합니다. 예를 들어 기준 슬롯이 100개이고 최대 예약 크기가 400개인 예약을 만들면 예약의 자동 확장 슬롯은 300개입니다. 기준 슬롯에 대한 자세한 내용은 기준 및 자동 확장 슬롯이 있는 예약 사용을 참조하세요.
보조 위치 목록에서 보조 위치를 선택합니다.
유휴 슬롯 공유를 사용 중지하고 지정된 슬롯 용량만 사용하려면 유휴 슬롯 무시 전환 버튼을 클릭합니다.
고급 설정 섹션을 펼치려면 펼치기 화살표를 클릭합니다.
(선택사항): 대상 작업 동시 실행을 설정하려면 자동 대상 작업 동시 실행 재정의 전환 버튼을 클릭하여 사용 설정한 후 대상 작업 동시 실행 값을 입력합니다. 슬롯 분석은 예상 비용 테이블에 표시됩니다. 예약 요약은 용량 요약 테이블에 표시됩니다.
저장을 클릭합니다.
새 예약이 슬롯 예약 탭에 표시됩니다.
SQL
예약을 만들려면 CREATE RESERVATION 데이터 정의 언어(DDL) 문을 사용합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음 문을 입력합니다.
CREATE RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` OPTIONS ( slot_capacity = NUMBER_OF_BASELINE_SLOTS, edition = ENTERPRISE_PLUS, secondary_location = SECONDARY_LOCATION);
다음을 바꿉니다.
ADMIN_PROJECT_ID: 예약 리소스를 소유하는 관리 프로젝트의 프로젝트 ID입니다.LOCATION: 예약 위치입니다. BigQuery Omni 위치를 선택하면 버전 옵션이 Enterprise 버전으로 제한됩니다.RESERVATION_NAME: 예약 이름입니다.이름은 소문자 또는 숫자로 시작하고 끝나야 하며 소문자, 숫자, 대시만 포함할 수 있습니다.
NUMBER_OF_BASELINE_SLOTS: 예약에 할당할 기준 슬롯 수. 동일한 예약에slot_capacity옵션 및edition옵션을 설정할 수 없습니다.SECONDARY_LOCATION: 예약의 보조 위치입니다. 정전이 발생하면 이 예약에 연결된 모든 데이터 세트가 이 위치로 장애 조치됩니다.
실행을 클릭합니다.
쿼리를 실행하는 방법에 대한 자세한 내용은 대화형 쿼리 실행을 참조하세요.
기존 예약 변경
다음 중 하나를 선택합니다.
콘솔
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
탐색 메뉴에서 용량 관리를 클릭합니다.
슬롯 예약 탭을 클릭합니다.
업데이트할 예약을 찾습니다.
예약 작업을 클릭한 다음 수정을 클릭합니다.
보조 위치 필드에 보조 위치를 입력합니다.
저장을 클릭합니다.
SQL
예약에 보조 위치를 추가하거나 변경하려면 ALTER RESERVATION SET OPTIONS DDL 문을 사용합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음 문을 입력합니다.
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( secondary_location = SECONDARY_LOCATION);
다음을 바꿉니다.
실행을 클릭합니다.
쿼리를 실행하는 방법에 대한 자세한 내용은 대화형 쿼리 실행을 참조하세요.
예약에 데이터 세트 연결
이전에 만든 예약에 재해 복구를 사용 설정하려면 다음 단계를 완료하세요. 데이터 세트가 예약과 동일한 기본 및 보조 리전에서 복제되도록 이미 구성되어 있어야 합니다. 자세한 내용은 지역 간 데이터 세트 복제를 참고하세요.
콘솔
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
탐색 메뉴에서 용량 관리를 클릭한 다음 슬롯 예약 탭을 클릭합니다.
데이터 세트를 연결할 예약을 클릭합니다.
재해 복구 탭을 클릭합니다.
장애 조치 데이터 세트 추가를 클릭합니다.
예약과 연결할 데이터 세트의 이름을 입력합니다.
추가를 클릭합니다.
SQL
예약에 데이터 세트를 연결하려면 ALTER SCHEMA SET OPTIONS DDL 문을 사용합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음 문을 입력합니다.
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = ADMIN_PROJECT_ID.RESERVATION_NAME);
다음을 바꿉니다.
DATASET_NAME: 데이터 세트의 이름ADMIN_PROJECT_ID.RESERVATION_NAME: 데이터 세트를 연결할 예약의 이름입니다.
실행을 클릭합니다.
쿼리를 실행하는 방법에 대한 자세한 내용은 대화형 쿼리 실행을 참조하세요.
예약에서 데이터 세트 분리
예약을 통해 데이터 세트의 장애 조치 동작을 관리하지 않으려면 데이터 세트를 예약에서 분리합니다. 이렇게 해도 데이터 세트의 현재 기본 복제본은 변경되지 않으며 기존 데이터 세트 복제본은 삭제되지 않습니다. 데이터 세트를 분리한 후 데이터 세트 복제본을 삭제하는 방법에 관한 자세한 내용은 데이터 세트 복제본 삭제를 참조하세요.
콘솔
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
탐색 메뉴에서 용량 관리를 클릭한 다음 슬롯 예약 탭을 클릭합니다.
데이터 세트를 분리하려는 예약을 클릭합니다.
재해 복구 탭을 클릭합니다.
데이터 세트의 기본 복제본에 대해 작업 옵션을 펼칩니다.
삭제를 클릭합니다.
SQL
예약에서 데이터 세트를 분리하려면 ALTER SCHEMA SET OPTIONS DDL 문을 사용합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음 문을 입력합니다.
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = NULL);
다음을 바꿉니다.
DATASET_NAME: 데이터 세트의 이름
실행을 클릭합니다.
쿼리를 실행하는 방법에 대한 자세한 내용은 대화형 쿼리 실행을 참조하세요.
장애 조치 시작
리전 서비스 중단이 발생하면 복제본에서 사용하는 위치로 예약을 수동으로 장애 조치해야 합니다. 예약 장애 조치에는 연결된 데이터 세트도 포함됩니다. 예약을 수동으로 장애 조치하려면 다음 단계를 따르세요.
콘솔
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
탐색 메뉴에서 재해 복구를 클릭합니다.
장애 조치할 예약의 이름을 클릭합니다.
하드 장애 조치 모드 (기본값) 또는 소프트 장애 조치 모드를 선택합니다.
장애 조치를 클릭합니다.
SQL
예약에 보조 위치를 추가하거나 변경하려면 ALTER RESERVATION SET OPTIONS DDL 문을 사용하고 is_primary을 TRUE로 설정합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음 문을 입력합니다.
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( is_primary = TRUE, failover_mode=FAILOVER_MODE);
다음을 바꿉니다.
ADMIN_PROJECT_ID: 예약 리소스를 소유하는 관리 프로젝트의 프로젝트 ID입니다.LOCATION: 예약의 새 기본 위치입니다. 장애 조치 전의 현재 보조 위치입니다(예:europe-west9).RESERVATION_NAME: 예약 이름. 이름은 소문자 또는 숫자로 시작하고 끝나야 하며 소문자, 숫자, 대시만 포함할 수 있습니다.PRIMARY_STATUS: 예약이 기본 복제본인지 선언하는 불리언 상태입니다.FAILOVER_MODE: 장애 조치 모드를 설명하는 데 사용되는 선택적 매개변수입니다.HARD또는SOFT로 설정할 수 있습니다. 이 매개변수를 지정하지 않으면 기본적으로HARD이 사용됩니다.
실행을 클릭합니다.
쿼리를 실행하는 방법에 대한 자세한 내용은 대화형 쿼리 실행을 참조하세요.
모니터링
복제본의 상태를 확인하려면 INFORMATION_SCHEMA.SCHEMATA_REPLICAS 뷰를 쿼리합니다. 예를 들면 다음과 같습니다.
SELECT schema_name, replica_name, creation_complete, replica_primary_assigned, replica_primary_assignment_complete FROM `region-LOCATION`.INFORMATION_SCHEMA.SCHEMATA_REPLICAS WHERE schema_name="my_dataset"
다음 쿼리는 데이터 세트가 장애 조치 데이터 세트인 경우 실패할 수 있는 지난 7일간의 작업을 반환합니다.
WITH non_epe_reservations AS ( SELECT project_id, reservation_name FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.RESERVATIONS WHERE edition != 'ENTERPRISE_PLUS' ) SELECT * FROM ( SELECT job_id FROM ( SELECT job_id, reservation_id, ARRAY_CONCAT(referenced_tables, [destination_table]) AS all_referenced_tables, query FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.JOBS WHERE creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP() ) A, UNNEST(all_referenced_tables) AS referenced_table ) jobs LEFT OUTER JOIN non_epe_reservations ON ( jobs.reservation_id = CONCAT( non_epe_reservations.project_id, ':', 'LOCATION', '.', non_epe_reservations.reservation_name)) WHERE CONCAT(jobs.project_id, ':', jobs.dataset_id) IN UNNEST( [ 'PROJECT_ID:DATASET_ID', 'PROJECT_ID:DATASET_ID']);
다음을 바꿉니다.
PROJECT_ID: 프로젝트 IDDATASET_ID: 데이터 세트 IDLOCATION: 위치
다음 단계
리전 간 데이터 세트 복제에 대해 자세히 알아보세요.
신뢰성에 대해 자세히 알아보세요.