Ce tutoriel vous explique comment importer un modèle Open Neural Network Exchange (ONNX) entraîné avec scikit-learn. Vous importez le modèle dans un ensemble de données BigQuery et l'utilisez pour effectuer des prédictions à l'aide d'une requête SQL.
ONNX fournit un format uniforme conçu pour représenter tous les frameworks de machine learning (ML). La compatibilité de BigQuery ML avec ONNX vous permet d'effectuer les opérations suivantes :
- Entraîner un modèle à l'aide du framework de votre choix
- Convertir le modèle au format ONNX
- Importer le modèle ONNX dans BigQuery et effectuer des prédictions à l'aide de BigQuery ML
Objectifs
- créer et entraîner un modèle à l'aide de scikit-learn ;
- Convertissez le modèle au format ONNX à l'aide de sklearn-onnx.
- Utilisez l'instruction
CREATE MODELpour importer le modèle ONNX dans BigQuery. - Utilisez la fonction
ML.PREDICTpour effectuer des prédictions avec le modèle ONNX importé.
Coûts
Dans ce document, vous utilisez les composants facturables de Google Cloudsuivants :
Vous pouvez obtenir une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Une fois que vous avez terminé les tâches décrites dans ce document, supprimez les ressources que vous avez créées pour éviter que des frais vous soient facturés. Pour en savoir plus, consultez la section Effectuer un nettoyage.
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Assurez-vous de disposer des autorisations nécessaires pour effectuer les tâches décrites dans ce document.
- BigQuery Studio Admin (
roles/bigquery.studioAdmin) - Storage Object Creator (
roles/storage.objectCreator) -
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
-
In the Google Cloud console, go to the IAM page.
Accéder à IAM - Sélectionnez le projet.
- Cliquez sur Accorder l'accès.
-
Dans le champ Nouveaux comptes principaux, saisissez votre identifiant utilisateur. Il s'agit généralement de l'adresse e-mail d'un compte Google.
- Dans la liste Sélectionner un rôle, sélectionnez un rôle.
- Pour attribuer des rôles supplémentaires, cliquez sur Ajouter un autre rôle et ajoutez tous les rôles supplémentaires.
- Cliquez sur Enregistrer.
- Créez un bucket Cloud Storage pour stocker le modèle.
- Importez le modèle ONNX dans votre bucket Cloud Storage.
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le volet Explorateur, cliquez sur le nom de votre projet.
Cliquez sur Afficher les actions > Créer un ensemble de données.
Sur la page Créer un ensemble de données, procédez comme suit :
Dans le champ ID de l'ensemble de données, saisissez
bqml_tutorial.Pour Type d'emplacement, sélectionnez Multirégional, puis sélectionnez US (plusieurs régions aux États-Unis).
Conservez les autres paramètres par défaut, puis cliquez sur Créer un ensemble de données.
Créez un ensemble de données nommé
bqml_tutorialavec l'emplacement des données défini surUSet une description deBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Au lieu d'utiliser l'option
--dataset, la commande utilise le raccourci-d. Si vous omettez-det--dataset, la commande crée un ensemble de données par défaut.Vérifiez que l'ensemble de données a été créé :
bq lsDans la console Google Cloud , accédez à la page BigQuery Studio.
Dans l'éditeur de requête, saisissez l'instruction
CREATE MODELsuivante.CREATE OR REPLACE MODEL `bqml_tutorial.imported_onnx_model` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='BUCKET_PATH')
Remplacez
BUCKET_PATHpar le chemin d'accès au modèle que vous avez importé dans Cloud Storage. Si vous utilisez le modèle d'exemple, remplacezBUCKET_PATHpar la valeur suivante :gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnx.Une fois l'opération terminée, un message semblable à celui-ci s'affiche :
Successfully created model named imported_onnx_model.Votre nouveau modèle apparaît dans le panneau Ressources. Les modèles sont indiqués par l'icône :
 Si vous sélectionnez le nouveau modèle dans le panneau Ressources, les informations relatives au modèle s'affichent à côté de l'éditeur de requête.
Si vous sélectionnez le nouveau modèle dans le panneau Ressources, les informations relatives au modèle s'affichent à côté de l'éditeur de requête.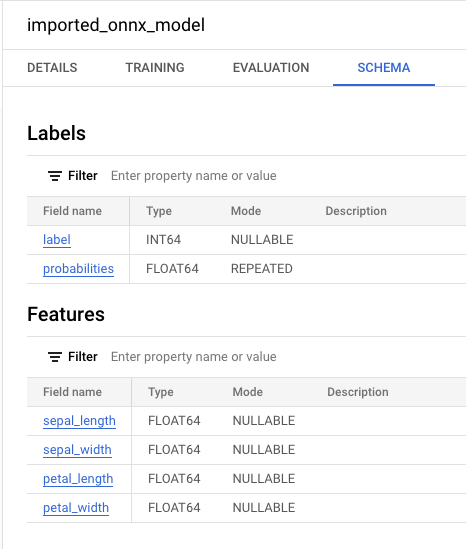
Importez le modèle ONNX depuis Cloud Storage en saisissant l'instruction
CREATE MODELsuivante.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.imported_onnx_model` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='BUCKET_PATH')"
Remplacez
BUCKET_PATHpar le chemin d'accès au modèle que vous avez importé dans Cloud Storage. Si vous utilisez le modèle d'exemple, remplacezBUCKET_PATHpar la valeur suivante :gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnx.Une fois l'opération terminée, un message semblable à celui-ci s'affiche :
Successfully created model named imported_onnx_model.Une fois le modèle importé, vérifiez qu'il apparaît dans l'ensemble de données.
bq ls bqml_tutorial
Le résultat ressemble à ce qui suit :
tableId Type --------------------- ------- imported_onnx_model MODEL
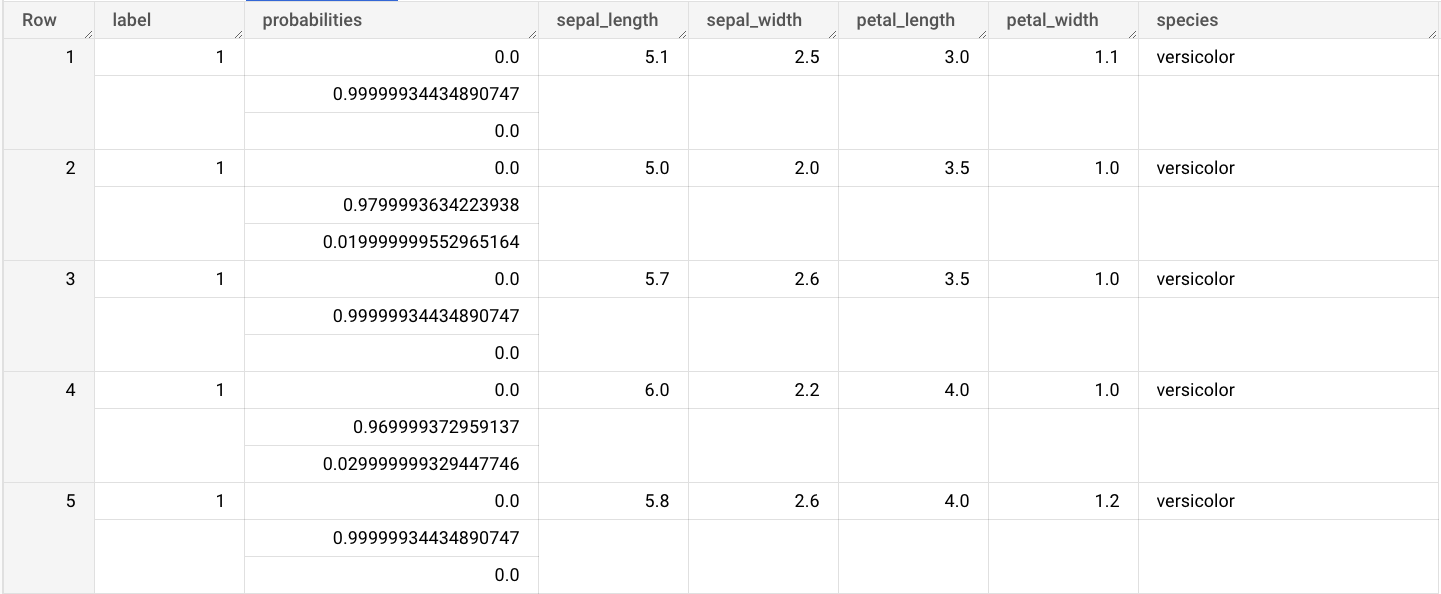
sepal_lengthsepal_widthpetal_lengthpetal_widthAccédez à la page BigQuery Studio.
Dans l'éditeur de requête, saisissez la requête qui utilise la fonction
ML.PREDICT.SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.imported_onnx_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.iris` ) )
Les résultats de la requête sont semblables à ceux-ci :
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Facultatif : supprimez l'ensemble de données.
- Pour en savoir plus sur l'importation de modèles ONNX, consultez la page Instruction
CREATE MODELpour les modèles ONNX. - Pour en savoir plus sur les convertisseurs ONNX disponibles et les tutoriels, consultez la page Convertir au format ONNX.
- Pour obtenir plus d'informations sur BigQuery ML, consultez la page Présentation de BigQuery ML.
- Pour commencer à utiliser BigQuery ML, consultez la page Créer des modèles de machine learning dans BigQuery ML.
Rôles requis
Si vous créez un projet, vous en êtes le propriétaire et vous disposez de toutes les autorisations IAM (Identity and Access Management) requises pour suivre ce tutoriel.
Si vous utilisez un projet existant, procédez comme suit.
Make sure that you have the following role or roles on the project:
Check for the roles
Grant the roles
Pour en savoir plus sur les autorisations IAM dans BigQuery, consultez Autorisations IAM.
(Facultatif) Entraîner un modèle et le convertir au format ONNX
Les exemples de code suivants vous montrent comment entraîner un modèle de classification avec scikit-learn et comment convertir le pipeline obtenu au format ONNX. Ce tutoriel utilise un exemple de modèle prédéfini stocké à l'emplacement gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnx. Vous n'avez pas besoin de suivre ces étapes si vous utilisez l'exemple de modèle.
Entraîner un modèle de classification à l'aide de scikit-learn
Utilisez l'exemple de code suivant pour créer et entraîner un pipeline scikit-learn sur l'ensemble de données Iris. Pour savoir comment installer et utiliser scikit-learn, consultez le guide d'installation de scikit-learn.
import numpy
from sklearn.datasets import load_iris
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
data = load_iris()
X = data.data[:, :4]
y = data.target
ind = numpy.arange(X.shape[0])
numpy.random.shuffle(ind)
X = X[ind, :].copy()
y = y[ind].copy()
pipe = Pipeline([('scaler', StandardScaler()),
('clr', RandomForestClassifier())])
pipe.fit(X, y)
Convertir le pipeline en modèle ONNX
Utilisez l'exemple de code suivant dans sklearn-onnx pour convertir le pipeline scikit-learn en un modèle ONNX nommé pipeline_rf.onnx.
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
# Disable zipmap as it is not supported in BigQuery ML.
options = {id(pipe): {'zipmap': False}}
# Define input features. scikit-learn does not store information about the
# training dataset. It is not always possible to retrieve the number of features
# or their types. That's why the function needs another argument called initial_types.
initial_types = [
('sepal_length', FloatTensorType([None, 1])),
('sepal_width', FloatTensorType([None, 1])),
('petal_length', FloatTensorType([None, 1])),
('petal_width', FloatTensorType([None, 1])),
]
# Convert the model.
model_onnx = convert_sklearn(
pipe, 'pipeline_rf', initial_types=initial_types, options=options
)
# And save.
with open('pipeline_rf.onnx', 'wb') as f:
f.write(model_onnx.SerializeToString())
Importer le modèle ONNX dans Cloud Storage
Après avoir enregistré votre modèle, procédez comme suit :
Créer un ensemble de données
Créez un ensemble de données BigQuery pour stocker votre modèle de ML.
Console
bq
Pour créer un ensemble de données, exécutez la commande bq mk en spécifiant l'option --location. Pour obtenir la liste complète des paramètres possibles, consultez la documentation de référence sur la commande bq mk --dataset.
API
Appelez la méthode datasets.insert avec une ressource d'ensemble de données définie.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer les ADC pour un environnement de développement local.
Importer le modèle ONNX dans BigQuery
Les étapes suivantes vous montrent comment importer l'exemple de modèle ONNX depuis Cloud Storage à l'aide d'une instruction CREATE MODEL.
Pour importer le modèle ONNX dans votre ensemble de données, sélectionnez l'une des options suivantes :
Console
bq
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer les ADC pour un environnement de développement local.
Importez le modèle à l'aide de l'objet ONNXModel.
Pour en savoir plus sur l'importation de modèles ONNX dans BigQuery, y compris sur les exigences en matière de format et de stockage, consultez la page Instruction CREATE MODEL pour l'importation de modèles ONNX.
Effectuer des prédictions à l'aide du modèle ONNX importé
Après avoir importé le modèle ONNX, vous utilisez la fonction ML.PREDICT pour effectuer des prédictions avec le modèle.
La requête des étapes suivantes utilise imported_onnx_model pour effectuer des prédictions à l'aide des données d'entrée de la table iris dans l'ensemble de données public ml_datasets. Le modèle ONNX attend quatre valeurs FLOAT en entrée :
Ces entrées correspondent aux initial_types qui ont été définis lorsque vous avez converti le modèle au format ONNX.
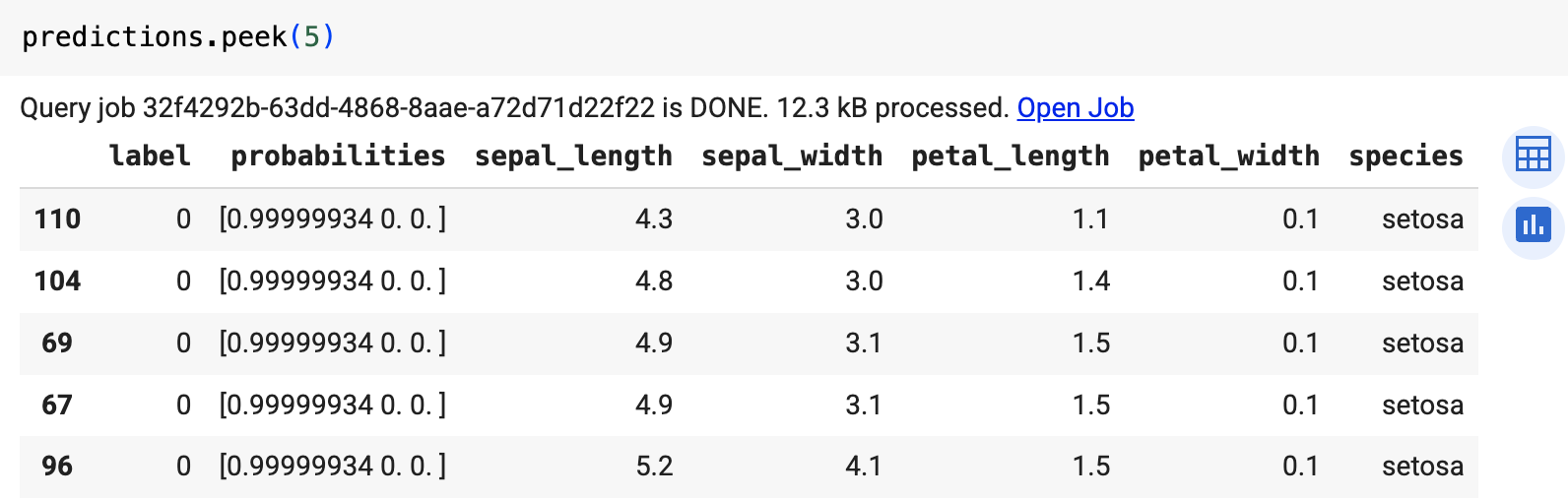
Les sorties incluent les colonnes label et probabilities, ainsi que les colonnes de la table d'entrée. label représente l'étiquette de classe prédite.
probabilities est un tableau de probabilités représentant les probabilités de chaque classe.
Pour effectuer des prédictions avec le modèle TensorFlow importé, choisissez l'une des options suivantes :
Console
bq
Exécutez la requête qui utilise ML.PREDICT.
bq query --use_legacy_sql=false \ 'SELECT * FROM ML.PREDICT( MODEL `example_dataset.imported_onnx_model`, (SELECT * FROM `bigquery-public-data.ml_datasets.iris`))'
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer les ADC pour un environnement de développement local.
Utilisez la fonction predict pour exécuter le modèle distant.
Le résultat ressemble à ce qui suit :
Effectuer un nettoyage
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
Supprimer le projet
Console
gcloud
Supprimer des ressources individuelles
Vous pouvez également supprimer les ressources individuelles utilisées dans ce tutoriel :