En este instructivo, se muestra cómo importar un modelo de Open Neural Network Exchange (ONNX) entrenado con scikit-learn. Importarás el modelo a un conjunto de datos de BigQuery y lo usarás para hacer predicciones con una consulta en SQL.
ONNX proporciona un formato uniforme diseñado para representar cualquier framework de aprendizaje automático (AA). La compatibilidad de BigQuery ML con ONNX te permite hacer lo siguiente:
- Entrenar un modelo con tu framework favorito.
- Convierte el modelo al formato de modelo ONNX.
- Importar el modelo ONNX a BigQuery y hacer predicciones con BigQuery ML.
Objetivos
- Crear y entrenar un modelo con scikit-learn
- Convierte el modelo al formato ONNX con sklearn-onnx.
- Usa la declaración
CREATE MODELpara importar el modelo ONNX a BigQuery. - Usa la función
ML.PREDICTpara hacer predicciones con el modelo ONNX importado.
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
Cuando completes las tareas que se describen en este documento, podrás borrar los recursos que creaste para evitar que se te siga facturando. Para obtener más información, consulta Realiza una limpieza.
Antes de comenzar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery and Cloud Storage APIs.
- Asegúrate de tener los permisos necesarios para realizar las tareas de este documento.
- BigQuery Studio Admin (
roles/bigquery.studioAdmin) - Storage Object Creator (
roles/storage.objectCreator) -
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
-
In the Google Cloud console, go to the IAM page.
Ir a IAM - Selecciona el proyecto.
- Haz clic en Otorgar acceso.
-
En el campo Principales nuevas, ingresa tu identificador de usuario. Esta suele ser la dirección de correo electrónico de una Cuenta de Google.
- En la lista Seleccionar un rol, elige uno.
- Para otorgar roles adicionales, haz clic en Agregar otro rol y agrega uno más.
- Haz clic en Guardar.
- Crea un bucket de Cloud Storage para almacenar el modelo.
- Sube el modelo ONNX a tu bucket de Cloud Storage.
En la consola de Google Cloud , ve a la página BigQuery.
En el panel Explorador, haz clic en el nombre de tu proyecto.
Haz clic en Ver acciones > Crear conjunto de datos.
En la página Crear conjunto de datos, haz lo siguiente:
En ID del conjunto de datos, ingresa
bqml_tutorial.En Tipo de ubicación, selecciona Multirregión y, luego, EE.UU. (varias regiones en Estados Unidos).
Deja la configuración predeterminada restante como está y haz clic en Crear conjunto de datos.
Crea un conjunto de datos llamado
bqml_tutorialcon la ubicación de los datos establecida enUSy una descripción deBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
En lugar de usar la marca
--dataset, el comando usa el acceso directo-d. Si omites-dy--dataset, el comando crea un conjunto de datos de manera predeterminada.Confirma que se haya creado el conjunto de datos:
bq lsEn la consola de Google Cloud , ve a la página BigQuery Studio.
En el editor de consultas, ingresa la siguiente sentencia
CREATE MODEL.CREATE OR REPLACE MODEL `bqml_tutorial.imported_onnx_model` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='BUCKET_PATH')
Reemplaza
BUCKET_PATHpor la ruta de acceso al modelo que subiste a Cloud Storage. Si usas el modelo de muestra, reemplazaBUCKET_PATHpor el siguiente valor:gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnx.Cuando se complete la operación, verás un mensaje similar al siguiente:
Successfully created model named imported_onnx_model.Tu nuevo modelo aparece en el panel Recursos. Los modelos se indican con el ícono de modelo:
 Si seleccionas el modelo nuevo en el panel Recursos, la información sobre el modelo aparecerá junto al Editor de consultas.
Si seleccionas el modelo nuevo en el panel Recursos, la información sobre el modelo aparecerá junto al Editor de consultas.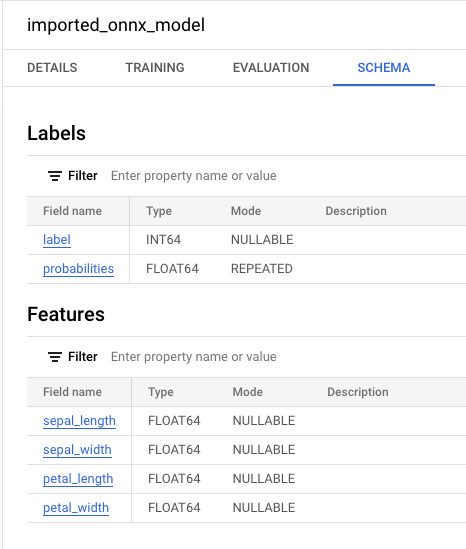
Importa el modelo ONNX desde Cloud Storage ingresando la siguiente declaración
CREATE MODEL.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.imported_onnx_model` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='BUCKET_PATH')"
Reemplaza
BUCKET_PATHpor la ruta de acceso al modelo que subiste a Cloud Storage. Si usas el modelo de muestra, reemplazaBUCKET_PATHpor el siguiente valor:gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnx.Cuando se complete la operación, verás un mensaje similar al siguiente:
Successfully created model named imported_onnx_model.Después de importar el modelo, verifica que aparezca en el conjunto de datos.
bq ls bqml_tutorial
El resultado es similar a este:
tableId Type --------------------- ------- imported_onnx_model MODEL
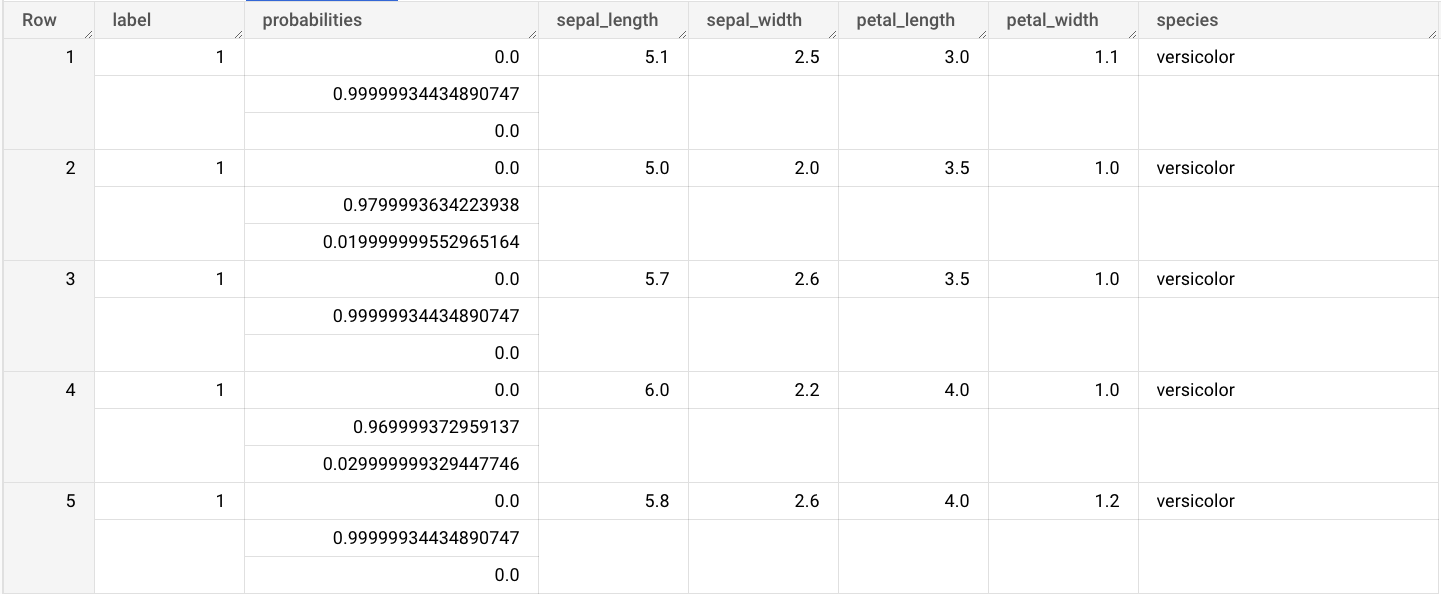
sepal_lengthsepal_widthpetal_lengthpetal_widthVe a la página de BigQuery Studio.
En el editor de consultas, ingresa esta consulta que usa la función
ML.PREDICT.SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.imported_onnx_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.iris` ) )
Los resultados de la búsqueda son similares a los siguientes:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Opcional: Borra el conjunto de datos.
- Para obtener más información sobre la importación de modelos ONNX, consulta la declaración
CREATE MODELpara modelos ONNX. - Para obtener más información sobre los instructivos y los convertidores de ONNX disponibles, consulta Convierte al formato ONNX.
- Para obtener una descripción general de BigQuery ML, consulta Introducción a BigQuery ML.
- Para comenzar a usar BigQuery ML, consulta Crea modelos de aprendizaje automático en BigQuery ML.
Roles requeridos
Si creas un proyecto nuevo, serás el propietario y se te otorgarán todos los permisos de Identity and Access Management (IAM) necesarios para completar este instructivo.
Si usas un proyecto existente, haz lo siguiente.
Make sure that you have the following role or roles on the project:
Check for the roles
Grant the roles
Para obtener más información sobre los permisos de IAM en BigQuery, consulta Permisos de IAM.
Opcional: Entrena un modelo y conviértelo al formato ONNX
En los siguientes ejemplos de código, se muestra cómo entrenar un modelo de clasificación con scikit-learn y cómo convertir la canalización resultante al formato ONNX. En este instructivo, se usa un modelo de ejemplo compilado previamente que se almacena en gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnx. No es necesario que completes estos pasos si usas el modelo de muestra.
Entrena un modelo de clasificación con scikit-learn
Usa el siguiente código de muestra para crear y entrenar una canalización de scikit-learn en el conjunto de datos de Iris. Para obtener instrucciones sobre cómo instalar y usar scikit-learn, consulta la guía de instalación de scikit-learn.
import numpy
from sklearn.datasets import load_iris
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
data = load_iris()
X = data.data[:, :4]
y = data.target
ind = numpy.arange(X.shape[0])
numpy.random.shuffle(ind)
X = X[ind, :].copy()
y = y[ind].copy()
pipe = Pipeline([('scaler', StandardScaler()),
('clr', RandomForestClassifier())])
pipe.fit(X, y)
Convierte la canalización en un modelo de ONNX
Usa el siguiente código de muestra en sklearn-onnx para convertir la canalización de scikit-learn en un modelo de ONNX llamado pipeline_rf.onnx.
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
# Disable zipmap as it is not supported in BigQuery ML.
options = {id(pipe): {'zipmap': False}}
# Define input features. scikit-learn does not store information about the
# training dataset. It is not always possible to retrieve the number of features
# or their types. That's why the function needs another argument called initial_types.
initial_types = [
('sepal_length', FloatTensorType([None, 1])),
('sepal_width', FloatTensorType([None, 1])),
('petal_length', FloatTensorType([None, 1])),
('petal_width', FloatTensorType([None, 1])),
]
# Convert the model.
model_onnx = convert_sklearn(
pipe, 'pipeline_rf', initial_types=initial_types, options=options
)
# And save.
with open('pipeline_rf.onnx', 'wb') as f:
f.write(model_onnx.SerializeToString())
Sube el modelo ONNX a Cloud Storage.
Después de guardar el modelo, haz lo siguiente:
Crea un conjunto de datos
Crea un conjunto de datos de BigQuery para almacenar tu modelo de AA.
Console
bq
Para crear un conjunto de datos nuevo, usa el comando bq mk con la marca --location. Para obtener una lista completa de los parámetros posibles, consulta la
referencia del
comando bq mk --dataset.
API
Llama al método datasets.insert con un recurso de conjunto de datos definido.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
Permite trabajar con BigQuery DataFrames.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
Importa el modelo ONNX a BigQuery
En los siguientes pasos, se muestra cómo importar el modelo de ONNX de ejemplo desde Cloud Storage con una instrucción CREATE MODEL.
Para importar el modelo de ONNX a tu conjunto de datos, selecciona una de las siguientes opciones:
Console
bq
Permite trabajar con BigQuery DataFrames.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
Importa el modelo con el objeto ONNXModel.
Para obtener más información sobre la importación de modelos ONNX a BigQuery, incluidos los requisitos de formato y almacenamiento, consulta la declaración CREATE MODEL para importar modelos ONNX.
Realiza predicciones con el modelo ONNX importado
Después de importar el modelo ONNX, usas la función ML.PREDICT para hacer predicciones con el modelo.
La consulta de los siguientes pasos usa imported_onnx_model para realizar predicciones con los datos de entrada de la tabla iris en el conjunto de datos públicos ml_datasets. El modelo ONNX espera cuatro valores de FLOAT como entrada:
Estas entradas coinciden con las initial_types que se definieron cuando convertiste el modelo al formato ONNX.
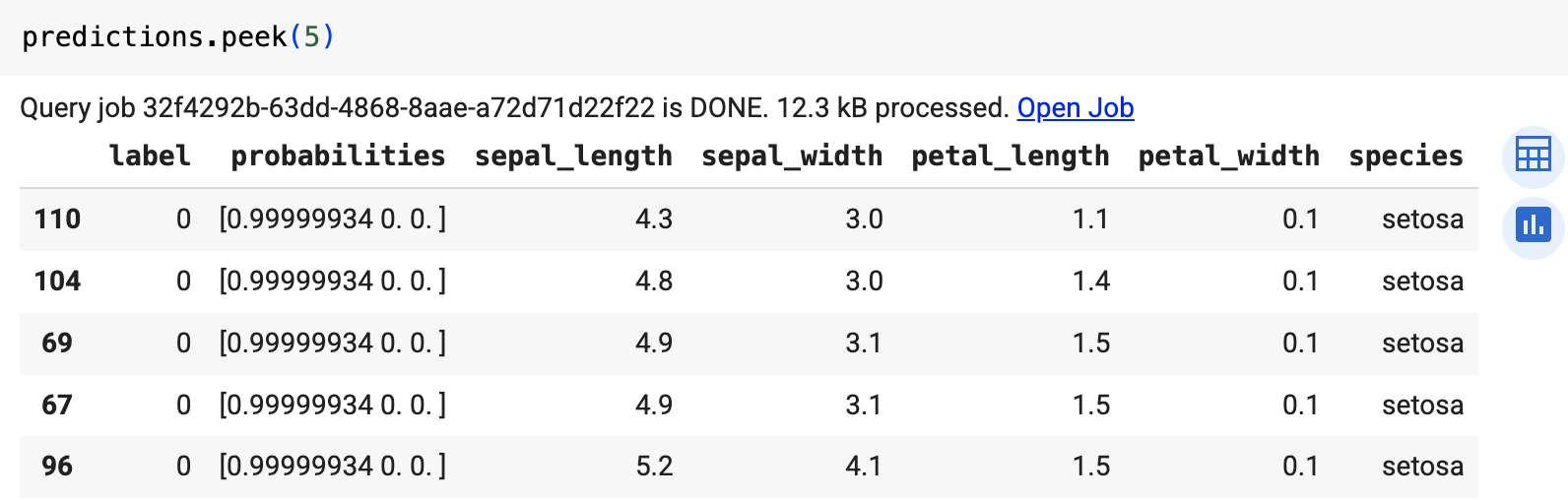
Los resultados incluyen las columnas label y probabilities, y las columnas de la tabla de entrada. label representa la etiqueta de clase prevista.
probabilities es un array de probabilidades que representan probabilidades para cada clase.
Para realizar predicciones con el modelo importado de TensorFlow, elige una de las siguientes opciones:
Console
bq
Ejecuta la consulta que usa ML.PREDICT.
bq query --use_legacy_sql=false \ 'SELECT * FROM ML.PREDICT( MODEL `example_dataset.imported_onnx_model`, (SELECT * FROM `bigquery-public-data.ml_datasets.iris`))'
Permite trabajar con BigQuery DataFrames.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
Usa la función predict para ejecutar el modelo remoto.
El resultado es similar al siguiente:
Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Borra el proyecto
Console
gcloud
Borra los recursos individuales
Como alternativa, para quitar los recursos individuales que se usan en este instructivo, haz lo siguiente: