Dans ce tutoriel, vous allez utiliser un modèle de régression logistique binaire dans BigQuery ML pour prédire la plage de revenus des personnes en fonction de leurs données démographiques. Un modèle de régression logistique binaire permet de prédire si une valeur tombe dans l'une des deux catégories, soit dans le cas présent prédire si le revenu annuel d'une personne est supérieur ou inférieur à 50 000 $.
Ce tutoriel utilise l'ensemble de données bigquery-public-data.ml_datasets.census_adult_income. Cet ensemble de données contient les informations relatives à la démographie et aux revenus des résidents américains à partir de 2000 et de 2010.
Objectifs
Dans ce tutoriel, vous allez effectuer les tâches suivantes :- Créer un modèle de régression logistique.
- Évaluer le modèle.
- Effectuer des prédictions à l'aide du modèle.
- Expliquer les résultats générés par le modèle.
Coûts
Ce tutoriel utilise des composants facturables de Google Cloud, y compris :
- BigQuery
- BigQuery ML
Pour en savoir plus sur le coût de BigQuery, consultez la page Tarifs de BigQuery.
Pour en savoir plus sur les coûts associés à BigQuery ML, consultez la page Tarifs de BigQuery ML.
Avant de commencer
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
Autorisations requises
Pour créer le modèle à l'aide de BigQuery ML, vous devez disposer des autorisations IAM suivantes :
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
Pour exécuter une inférence, vous devez disposer des autorisations suivantes :
bigquery.models.getDatasur le modèlebigquery.jobs.create
Introduction
Dans le cadre du machine learning, il est souvent nécessaire de classer les données dans l'un des deux types possibles, aussi appelés libellés. Par exemple, un marchand peut souhaiter prédire si un client donné achètera un nouveau produit, en se basant sur d'autres informations concernant ce client. Dans ce cas, les deux libellés peuvent être will buy et won't buy. Le revendeur peut créer un ensemble de données de sorte qu'une colonne représente les deux libellés et contient également des informations sur le client, telles que son emplacement, ses achats précédents et ses préférences déclarées. Le marchand peut ensuite utiliser un modèle de régression logistique binaire qui exploite ces informations client pour prédire l'étiquette qui représente le mieux chaque client.
Dans ce tutoriel, vous allez créer un modèle de régression logistique binaire permettant de prédire si le revenu d'une personne interrogée lors du recensement se situe dans l'une des deux plages possibles en fonction des attributs démographiques de cette personne.
Créer un ensemble de données
Créez un ensemble de données BigQuery pour stocker votre modèle :
Dans la console Google Cloud, accédez à la page BigQuery.
Dans le volet Explorateur, cliquez sur le nom de votre projet.
Cliquez sur Afficher les actions > Créer un ensemble de données.
Sur la page Créer un ensemble de données, procédez comme suit :
Dans le champ ID de l'ensemble de données, saisissez
census.Pour Type d'emplacement, sélectionnez Multirégional, puis sélectionnez US (plusieurs régions aux États-Unis).
Les ensembles de données publics sont stockés dans l'emplacement multirégional
US. Par souci de simplicité, stockez votre ensemble de données dans le même emplacement.Conservez les autres paramètres par défaut, puis cliquez sur Créer un ensemble de données.
Examiner les données
Examinez l'ensemble de données et identifier les colonnes à utiliser comme données d'entraînement pour le modèle de régression logistique. Sélectionnez 100 lignes dans la table census_adult_income :
SQL
Dans la console Google Cloud, accédez à la page BigQuery.
Dans l'éditeur de requête, exécutez la requête GoogleSQL suivante :
SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, functional_weight FROM `bigquery-public-data.ml_datasets.census_adult_income` LIMIT 100;
Les résultats ressemblent à ce qui suit :

BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour un environnement de développement local.
Les résultats de la requête montrent que la colonne income_bracket de la table census_adult_income ne présente que l'une des deux valeurs suivantes : <=50K ou >50K. La colonne functional_weight correspond au nombre de personnes représentées par une ligne particulière selon l'organisation de recensement. Les valeurs de cette colonne semblent ne pas avoir de lien avec la valeur de income_bracket pour une ligne particulière.
Préparer les exemples de données
Dans ce tutoriel, vous allez prédire le revenu du participant au recensement en fonction des attributs suivants :
- Âge
- Type de travail réalisé
- Statut marital
- Niveau d'études
- Profession
- Heures travaillées par semaine
Pour créer cette prédiction, vous allez extraire des informations à partir de données sur les personnes interrogées lors du recensement, issues de la table census_adult_income. Sélectionnez des colonnes de caractéristiques, y compris :
education_num, qui représente le niveau d'études de la personne interrogée ;workclass, qui représente la catégorie socioprofessionnelle de la personne interrogée.
Excluez les colonnes qui entraîneraient une duplication des données. Exemple :
education, careducationeteducation_numexpriment les mêmes données, mais dans des formats différents.
Séparez les données en ensembles d'entraînement, d'évaluation et de prédiction en créant une colonne dataframe dérivée de la colonne functional_weight.
Étiquetez 80 % de la source de données pour l'entraînement du modèle, et réservez les 20 % de données restants à des fins d'évaluation et de prédiction.
SQL
Pour préparer vos exemples de données, créez une vue contenant les données d'entraînement. Cette vue est utilisée par l'instruction CREATE MODEL plus loin dans ce tutoriel.
Exécutez la requête qui prépare les exemples de données :
Dans la console Google Cloud, accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez la requête suivante :
CREATE OR REPLACE VIEW `census.input_data` AS SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, CASE WHEN MOD(functional_weight, 10) < 8 THEN 'training' WHEN MOD(functional_weight, 10) = 8 THEN 'evaluation' WHEN MOD(functional_weight, 10) = 9 THEN 'prediction' END AS dataframe FROM `bigquery-public-data.ml_datasets.census_adult_income`
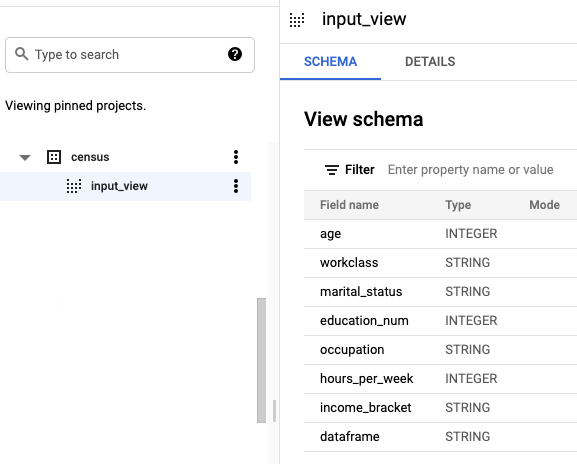
Dans le volet Explorateur, développez l'ensemble de données
censuset localisez la vueinput_data.Cliquez sur le nom de la vue pour ouvrir le volet d'informations. Le schéma de la vue s'affiche dans l'onglet Schéma.
BigQuery DataFrames
Créez un DataFrame appelé input_data. Vous utiliserez input_data plus loin dans ce tutoriel pour entraîner le modèle, l'évaluer et effectuer des prédictions.
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour un environnement de développement local.
Créer un modèle de régression logistique
Vous allez créer un modèle de régression logistique avec les données d'entraînement que vous avez étiquetées dans la section précédente.
SQL
Utilisez l'instruction CREATE MODEL et spécifiez LOGISTIC_REG pour le type de modèle.
Voici quelques points utiles à connaître concernant l'instruction CREATE MODEL :
L'option
input_label_colsspécifie la colonne de l'instructionSELECTà utiliser comme colonne d'étiquette. Ici, la colonne d'étiquette indiqueincome_bracket. Le modèle détermine donc laquelle des deux valeurs deincome_bracketest la plus probable pour cette ligne en fonction des autres valeurs présentes dans cette ligne.Il n'est pas nécessaire de spécifier si un modèle de régression logistique est binaire ou multiclasse. BigQuery peut déterminer le type de modèle à entraîner en fonction du nombre de valeurs uniques dans la colonne de libellé.
L'option
auto_class_weightsest définie surTRUEafin d'équilibrer les libellés de classe dans les données d'entraînement. Par défaut, les données d'entraînement ne sont pas pondérées. Si les étiquettes des données d'entraînement sont déséquilibrées, le modèle peut apprendre à prédire en priorité la classe d'étiquettes la plus populaire. Dans ce cas, la plupart des personnes interrogées de l'ensemble de données se situent dans la tranche de revenu inférieure. Cela peut conduire à un modèle qui favorise trop la tranche de revenu inférieure. Les pondérations des classes équilibrent les étiquettes de classe en calculant des pondérations pour chaque classe de manière inversement proportionnelle à la fréquence de celle-ci.L'instruction
SELECTinterroge la vueinput_dataqui contient les données d'entraînement. La clauseWHEREfiltre les lignes deinput_dataafin que seules les lignes libellées en tant que données d'entraînement soient utilisées pour entraîner le modèle.
Exécutez la requête permettant de créer le modèle de régression logistique :
Dans la console Google Cloud, accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez la requête suivante :
CREATE OR REPLACE MODEL `census.census_model` OPTIONS ( model_type='LOGISTIC_REG', auto_class_weights=TRUE, data_split_method='NO_SPLIT', input_label_cols=['income_bracket'], max_iterations=15) AS SELECT * EXCEPT(dataframe) FROM `census.input_data` WHERE dataframe = 'training'
Dans le volet Explorateur, développez l'ensemble de données
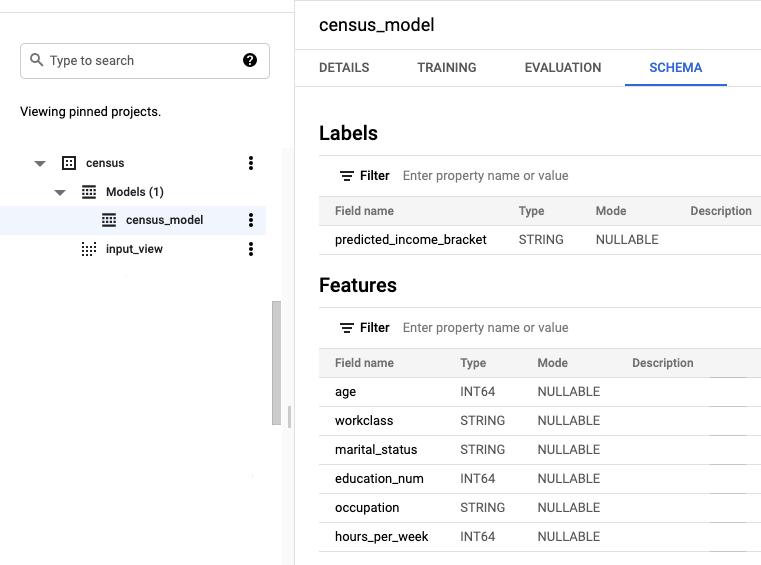
census, puis le dossier Modèles.Cliquez sur le modèle census_model pour ouvrir le volet d'informations.
Cliquez sur l'onglet Schema (Schéma). Le schéma de modèle répertorie les attributs que BigQuery ML a utilisés pour effectuer une régression logistique. Le résultat doit ressembler à ce qui suit :
BigQuery DataFrames
Utilisez la méthode fit pour entraîner le modèle et la méthode to_gbq pour l'enregistrer dans votre ensemble de données.
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour un environnement de développement local.
Évaluer les performances du modèle
Après avoir créé le modèle, vous allez évaluer ses performances par rapport aux données réelles.
SQL
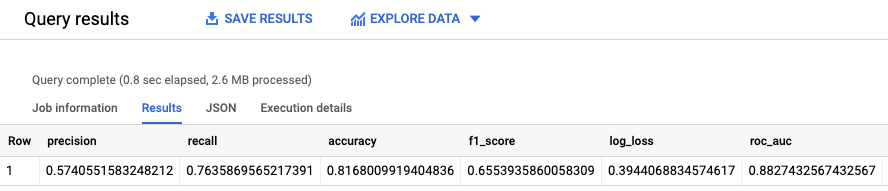
La fonction ML.EVALUATE compare les valeurs de prédiction générées par le modèle aux données réelles.
En entrée, la fonction ML.EVALUATE prend le modèle entraîné et les lignes de la vue input_data qui ont evaluation comme valeur pour la colonne dataframe. La fonction renvoie une seule ligne de statistiques concernant le modèle.
Exécutez la requête ML.EVALUATE :
Dans la console Google Cloud, accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez la requête suivante :
SELECT * FROM ML.EVALUATE (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation' ) )
Les résultats ressemblent à ce qui suit :
BigQuery DataFrames
Vous allez utiliser la méthode score pour évaluer le modèle par rapport aux données réelles.
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour un environnement de développement local.
Vous pouvez également consulter le volet d'informations du modèle dans la console Google Cloud pour afficher les métriques d'évaluation calculées pendant l'entraînement :
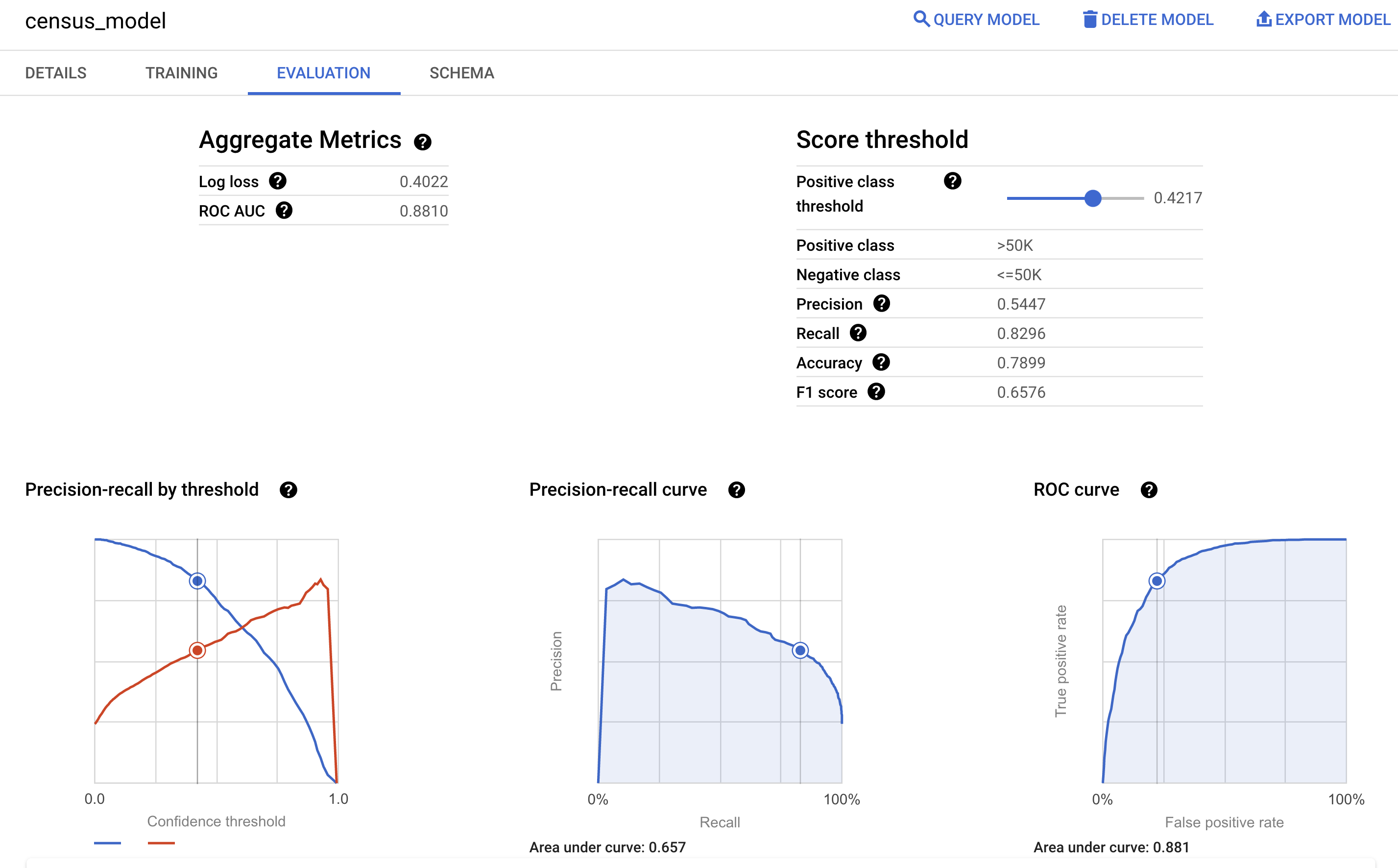
Prédire la tranche de revenu
À l'aide du modèle, vous allez identifier la tranche de revenu la plus probablement associée à une personne interrogée.
SQL
Utilisez la fonction ML.PREDICT pour effectuer des prédictions sur la tranche de revenu probable. Spécifiez le modèle entraîné et les lignes de la vue input_data dont la colonne dataframe contient la valeur prediction.
Exécutez la requête ML.PREDICT :
Dans la console Google Cloud, accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez la requête suivante :
SELECT * FROM ML.PREDICT (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'prediction' ) )
Les résultats ressemblent à ce qui suit :
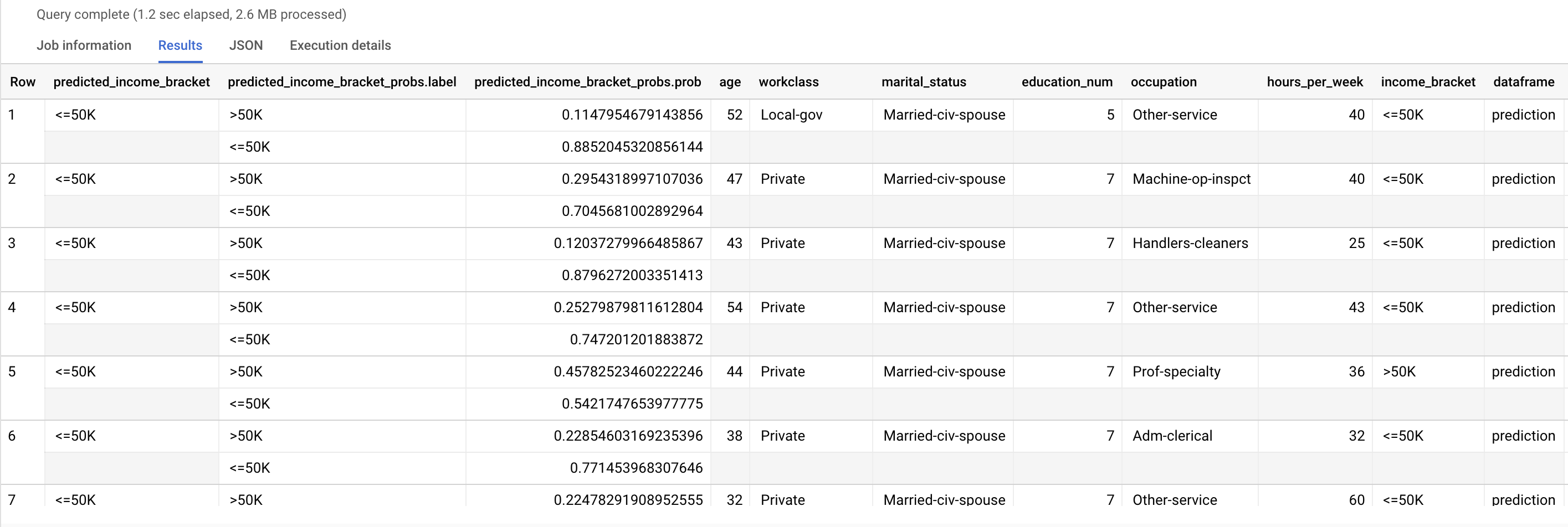
predicted_income_bracket correspond à la valeur estimée de income_bracket.
BigQuery DataFrames
Utilisez la méthode predict pour effectuer des prédictions sur la tranche de revenu probable.
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour un environnement de développement local.
Expliquer les résultats des prédictions
Pour comprendre pourquoi votre modèle génère ces résultats de prédiction, vous pouvez utiliser la fonction ML.EXPLAIN_PREDICT.
ML.EXPLAIN_PREDICT est une version étendue de la fonction ML.PREDICT.
La fonction ML.EXPLAIN_PREDICT génère non seulement des résultats de prédiction, mais elle produit également des colonnes supplémentaires servant à expliquer ces résultats. En pratique, vous pouvez exécuter ML.EXPLAIN_PREDICT au lieu de ML.PREDICT. Pour en savoir plus, consultez la présentation d'Explainable AI dans BigQuery ML.
Exécutez la requête ML.EXPLAIN_PREDICT :
Dans la console Google Cloud, accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez la requête suivante :
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation'), STRUCT(3 as top_k_features))
Les résultats ressemblent à ce qui suit :
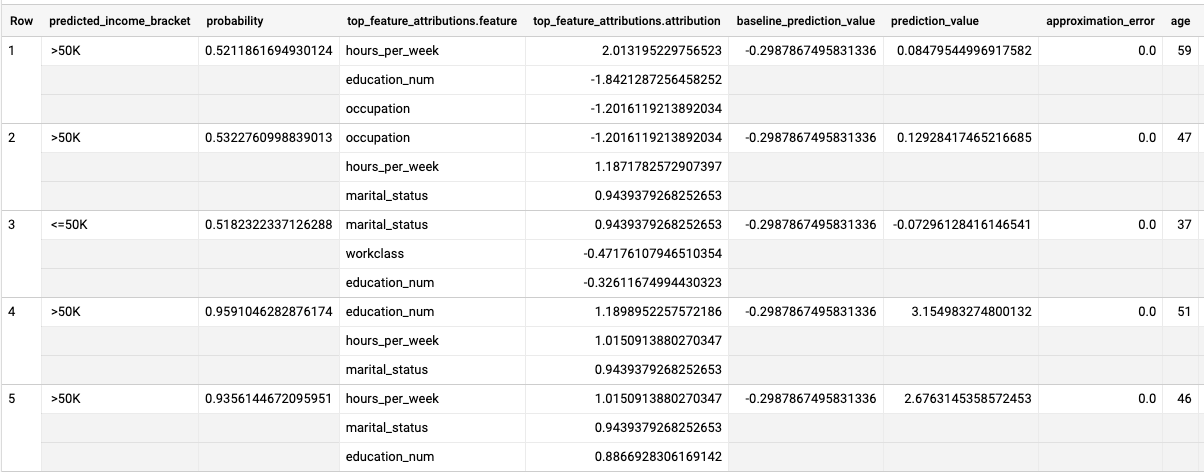
Pour les modèles de régression logistique, les valeurs de Shapley sont utilisées pour générer les valeurs d'attribution des caractéristiques pour chaque caractéristique du modèle. ML.EXPLAIN_PREDICT génère les trois premières attributions de caractéristiques par ligne de la vue input_data, car top_k_features a été défini sur 3 dans la requête. Ces attributions sont triées en fonction de la valeur absolue de l'attribution par ordre décroissant. Dans la ligne 1 de cet exemple, la caractéristique hours_per_week a contribué le plus à la prédiction globale, mais dans la ligne 2, occupation a contribué le plus à la prédiction globale.
Expliquer globalement le modèle
Pour identifier les caractéristiques généralement les plus importantes pour déterminer la tranche de revenu, vous pouvez utiliser la fonction ML.GLOBAL_EXPLAIN.
Pour utiliser ML.GLOBAL_EXPLAIN, vous devez réentraîner le modèle avec l'option ENABLE_GLOBAL_EXPLAIN définie sur TRUE.
Ré-entraînez le modèle et obtenez des explications globales :
Dans la console Google Cloud, accédez à la page BigQuery.
Dans l'éditeur de requête, exécutez la requête suivante pour réentraîner le modèle :
CREATE OR REPLACE MODEL `census.census_model` OPTIONS ( model_type='LOGISTIC_REG', auto_class_weights=TRUE, enable_global_explain=TRUE, input_label_cols=['income_bracket'] ) AS SELECT * EXCEPT(dataframe) FROM `census.input_data` WHERE dataframe = 'training'
Dans l'éditeur de requête, exécutez la requête suivante pour obtenir des explications globales :
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `census.census_model`)
Les résultats ressemblent à ce qui suit :
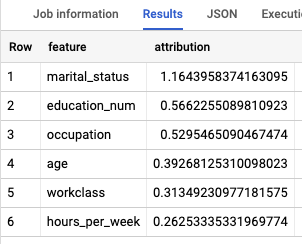
Effectuer un nettoyage
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
Supprimer l'ensemble de données
Si vous supprimez votre projet, tous les ensembles de données et toutes les tables qui lui sont associés sont également supprimés. Si vous préférez réutiliser le projet, vous pouvez supprimer l'ensemble de données que vous avez créé dans ce tutoriel :
Si nécessaire, ouvrez la page BigQuery dans Cloud Console.
Dans le panneau de navigation, cliquez sur l'ensemble de données census que vous avez créé.
Cliquez sur Delete dataset (Supprimer l'ensemble de données) dans la partie droite de la fenêtre. Cette action supprime l'ensemble de données et le modèle.
Dans la boîte de dialogue Supprimer l'ensemble de données, confirmez la commande de suppression en saisissant le nom de votre ensemble de données (
census), puis cliquez sur Supprimer.
Supprimer votre projet
Pour supprimer le projet :
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Étapes suivantes
- Pour obtenir plus d'informations sur BigQuery ML, consultez la page Présentation de BigQuery ML.
- Pour plus d'informations sur la création de modèles, consultez la page sur la syntaxe de
CREATE MODEL.