In this tutorial, you use a binary logistic regression model in BigQuery ML to predict the income range of individuals based on their demographic data. A binary logistic regression model predicts whether a value falls into one of two categories, in this case whether an individual's annual income falls above or below $50,000.
This tutorial uses the
bigquery-public-data.ml_datasets.census_adult_income
dataset. This dataset contains the demographic and income information of US
residents from 2000 and 2010.
Objectives
In this tutorial you will perform the following tasks:- Create a logistic regression model.
- Evaluate the model.
- Make predictions by using the model.
- Explain the results produced by the model.
Costs
This tutorial uses billable components of Google Cloud, including the following:
- BigQuery
- BigQuery ML
For more information on BigQuery costs, see the BigQuery pricing page.
For more information on BigQuery ML costs, see BigQuery ML pricing.
Before you begin
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Required permissions
To create the model using BigQuery ML, you need the following IAM permissions:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
To run inference, you need the following permissions:
bigquery.models.getDataon the modelbigquery.jobs.create
Introduction
A common task in machine learning is to classify data into one of two types,
known as labels. For example, a retailer might want to predict whether a given
customer will purchase a new product, based on other information about that
customer. In that case, the two labels might be will buy and won't buy. The
retailer can construct a dataset such that one column represents both labels,
and also contains customer information such as the customer's location, their
previous purchases, and their reported preferences. The retailer can then use a
binary logistic regression model that uses this customer information to predict
which label best represents each customer.
In this tutorial, you create a binary logistic regression model that predicts whether a US Census respondent's income falls into one of two ranges based on the respondent's demographic attributes.
Create a dataset
Create a BigQuery dataset to store your model:
In the Google Cloud console, go to the BigQuery page.
In the Explorer pane, click your project name.
Click View actions > Create dataset.
On the Create dataset page, do the following:
For Dataset ID, enter
census.For Location type, select Multi-region, and then select US (multiple regions in United States).
The public datasets are stored in the
USmulti-region. For simplicity, store your dataset in the same location.Leave the remaining default settings as they are, and click Create dataset.
Examine the data
Examine the dataset and identify which columns to use as
training data for the logistic regression model. Select 100 rows from the
census_adult_income table:
SQL
In the Google Cloud console, go to the BigQuery page.
In the query editor, run the following GoogleSQL query:
SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, functional_weight FROM `bigquery-public-data.ml_datasets.census_adult_income` LIMIT 100;
The results look similar to the following:

BigQuery DataFrames
Before trying this sample, follow the BigQuery DataFrames setup instructions in the BigQuery quickstart using BigQuery DataFrames. For more information, see the BigQuery DataFrames reference documentation.
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up ADC for a local development environment.
The query results show that the income_bracket column in the
census_adult_income table has only one of two values: <=50K or >50K.
Prepare the sample data
In this tutorial, you predict census respondent income based on values of the
following columns in the census_adult_income table:
age: the age of the respondent.workclass: class of work performed. For example local government, private, or self-employed.marital_statuseducation_num: the respondent's higheset level of education.occupationhours_per_week: hours worked per week.
You exclude columns that duplicate data. For example, the education column,
because the education and education_num column values express the
same data in different formats.
The functional_weight column is the number of individuals that the census
organization believes a particular row represents. Because the value of this
column is unrelated to the value of the income_bracket for any given row, you
use the value in this column to separate the data into training, evaluation,
and prediction sets by creating a new dataframe column that is derived from
the functional_weight column. You label 80% of the data for training the
model, 10% of data for evaluation, and 10% of the data for prediction.
SQL
Create a view a view with the sample data.
This view is used by the CREATE MODEL statement later in this tutorial.
Run the query that prepares the sample data:
In the Google Cloud console, go to the BigQuery page.
In the query editor, run the following query:
CREATE OR REPLACE VIEW `census.input_data` AS SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, CASE WHEN MOD(functional_weight, 10) < 8 THEN 'training' WHEN MOD(functional_weight, 10) = 8 THEN 'evaluation' WHEN MOD(functional_weight, 10) = 9 THEN 'prediction' END AS dataframe FROM `bigquery-public-data.ml_datasets.census_adult_income`;
View the sample data:
SELECT * FROM `census.input_data`;
BigQuery DataFrames
Create a DataFrame called input_data. You use input_data later in
this tutorial to use to train the model, evaluate it, and make predictions.
Before trying this sample, follow the BigQuery DataFrames setup instructions in the BigQuery quickstart using BigQuery DataFrames. For more information, see the BigQuery DataFrames reference documentation.
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up ADC for a local development environment.
Create a logistic regression model
Create a logistic regression model with the training data you labeled in the previous section.
SQL
Use the
CREATE MODEL statement
and specify LOGISTIC_REG for the model type.
The following are useful things to know about the CREATE MODEL statement:
The
input_label_colsoption specifies which column in theSELECTstatement to use as the label column. Here, the label column isincome_bracket, so the model learns which of the two values ofincome_bracketis most likely for a given row based on the other values present in that row.It is not necessary to specify whether a logistic regression model is binary or multiclass. BigQuery ML determines which type of model to train based on the number of unique values in the label column.
The
auto_class_weightsoption is set toTRUEin order to balance the class labels in the training data. By default, the training data is unweighted. If the labels in the training data are imbalanced, the model may learn to predict the most popular class of labels more heavily. In this case, most of the respondents in the dataset are in the lower income bracket. This may lead to a model that predicts the lower income bracket too heavily. Class weights balance the class labels by calculating the weights for each class in inverse proportion to the frequency of that class.The
enable_global_explainoption is set toTRUEin order to let you use theML.GLOBAL_EXPLAINfunction on the model later in the tutorial.The
SELECTstatement queries theinput_dataview that contains the sample data. TheWHEREclause filters the rows so that only those rows labeled as training data are used to train the model.
Run the query that creates your logistic regression model:
In the Google Cloud console, go to the BigQuery page.
In the query editor, run the following query:
CREATE OR REPLACE MODEL `census.census_model` OPTIONS ( model_type='LOGISTIC_REG', auto_class_weights=TRUE, enable_global_explain=TRUE, data_split_method='NO_SPLIT', input_label_cols=['income_bracket'], max_iterations=15) AS SELECT * EXCEPT(dataframe) FROM `census.input_data` WHERE dataframe = 'training'
In the Explorer pane, click Datasets.
In the Datasets pane, click
census.Click the Models pane.
Click
census_model.The Details tab lists the attributes that BigQuery ML used to perform logistic regression.
BigQuery DataFrames
Use the
fit
method to train the model and the
to_gbq
method to save it to your dataset.
Before trying this sample, follow the BigQuery DataFrames setup instructions in the BigQuery quickstart using BigQuery DataFrames. For more information, see the BigQuery DataFrames reference documentation.
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up ADC for a local development environment.
Evaluate the model's performance
After creating the model, evaluate the model's performance against the evaluation data.
SQL
The
ML.EVALUATE function
function evaluates the predicted values generated by the model against the
evaluation data.
For input, the ML.EVALUATE function takes the trained model and the rows
from theinput_data view that have evaluation as the dataframe column
value. The function returns a single row of statistics about the model.
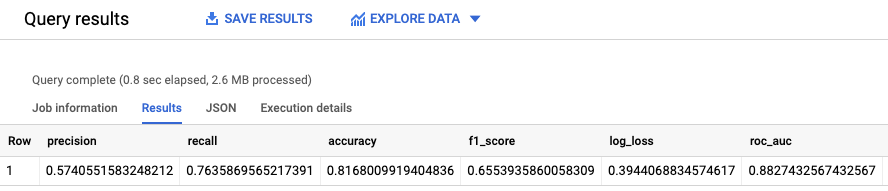
Run the ML.EVALUATE query:
In the Google Cloud console, go to the BigQuery page.
In the query editor, run the following query:
SELECT * FROM ML.EVALUATE (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation' ) );
The results look similar to the following:
BigQuery DataFrames
Use the
score
method to evaluate model against the actual data.
Before trying this sample, follow the BigQuery DataFrames setup instructions in the BigQuery quickstart using BigQuery DataFrames. For more information, see the BigQuery DataFrames reference documentation.
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up ADC for a local development environment.
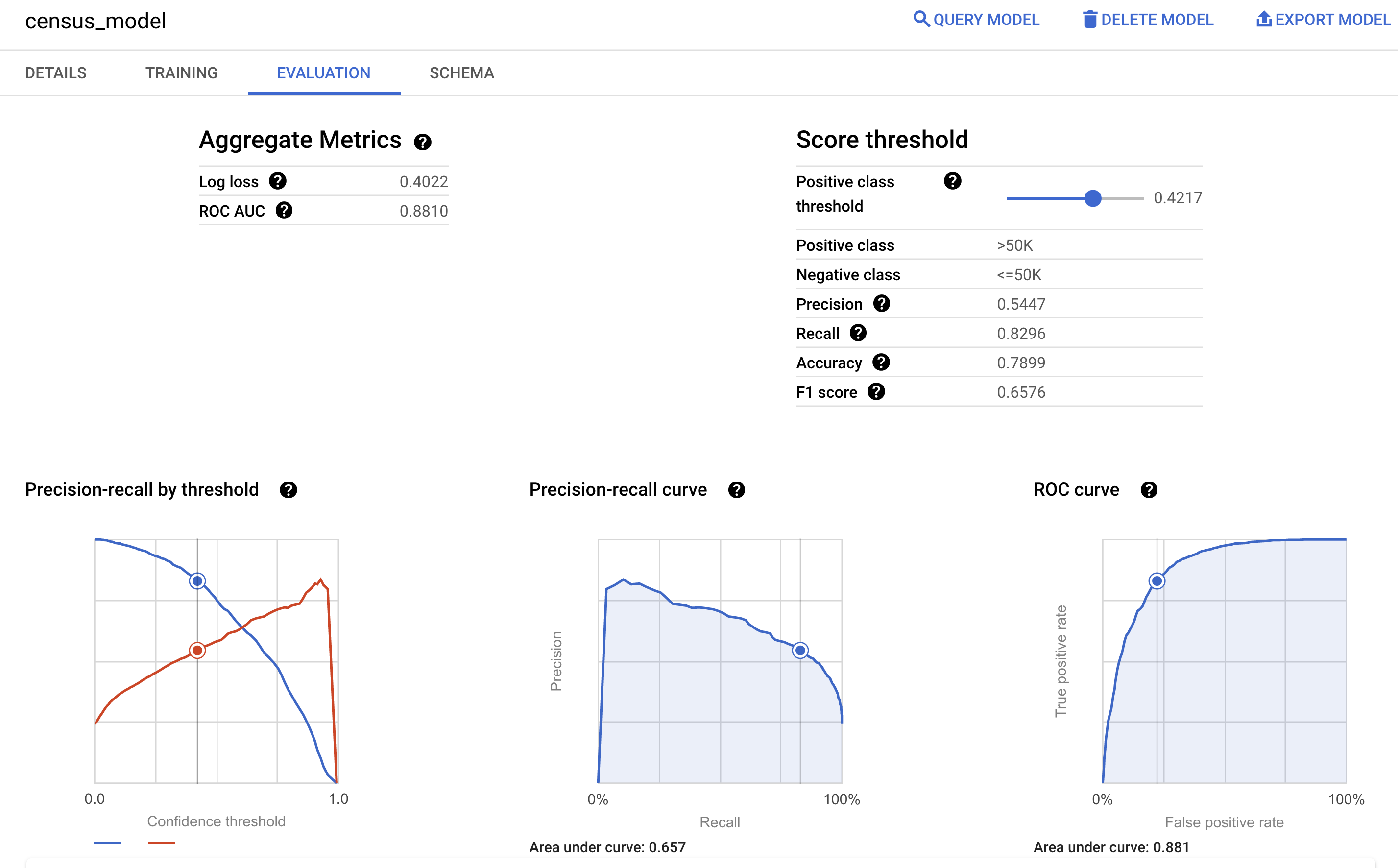
You can also look at the model's Evaluation pane in the Google Cloud console to view the evaluation metrics calculated during the training:
Predict the income bracket
Use the model to predict the most likely income bracket for each respondent.
SQL
Use the
ML.PREDICT function
to make predictions about the likely income bracket. For input, the
ML.PREDICT function takes the trained model and the rows from the
input_data view that have prediction as the dataframe column value.
Run the ML.PREDICT query:
In the Google Cloud console, go to the BigQuery page.
In the query editor, run the following query:
SELECT * FROM ML.PREDICT (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'prediction' ) );
The results look similar to the following:
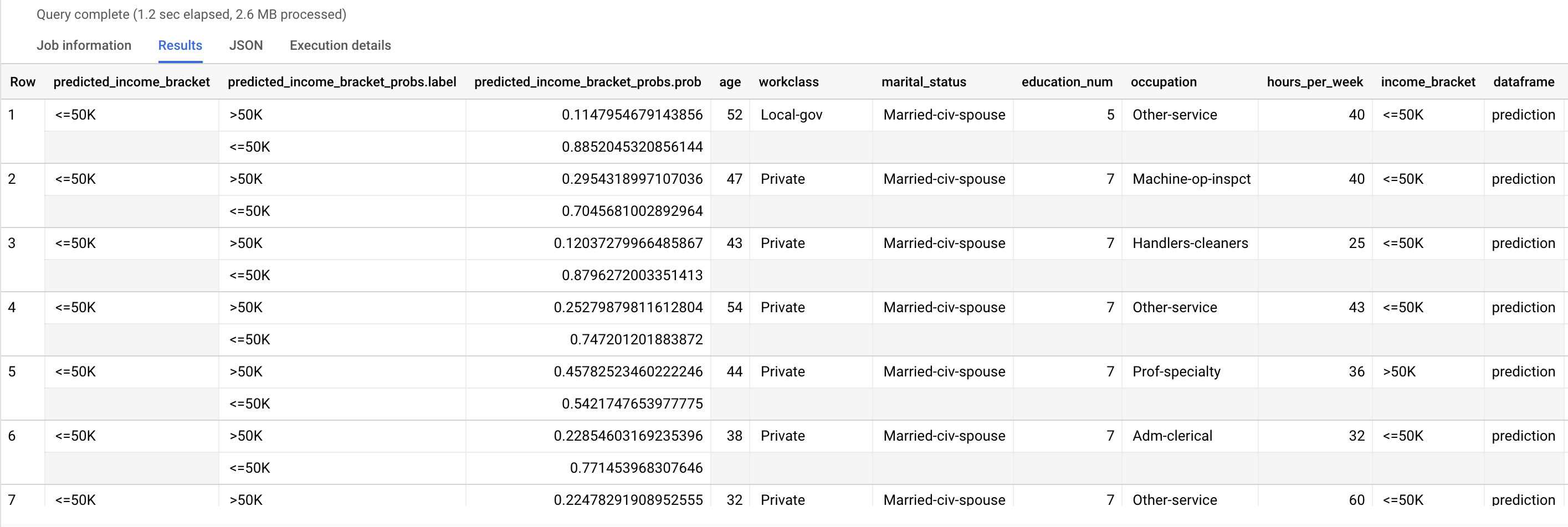
The predicted_income_bracket column contains the predicted income bracket
for the respondent.
BigQuery DataFrames
Use the
predict
method to make predictions about the likely income bracket.
Before trying this sample, follow the BigQuery DataFrames setup instructions in the BigQuery quickstart using BigQuery DataFrames. For more information, see the BigQuery DataFrames reference documentation.
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up ADC for a local development environment.
Explain the prediction results
To understand why the model is generating these prediction results, you can use
the
ML.EXPLAIN_PREDICT function.
ML.EXPLAIN_PREDICT is an extended version of the ML.PREDICT function.
ML.EXPLAIN_PREDICT not only outputs prediction results, but also outputs
additional columns to explain the prediction results. For more information
about explainability, see
BigQuery ML explainable AI overview.
Run the ML.EXPLAIN_PREDICT query:
In the Google Cloud console, go to the BigQuery page.
In the query editor, run the following query:
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation'), STRUCT(3 as top_k_features));
The results look similar to the following:
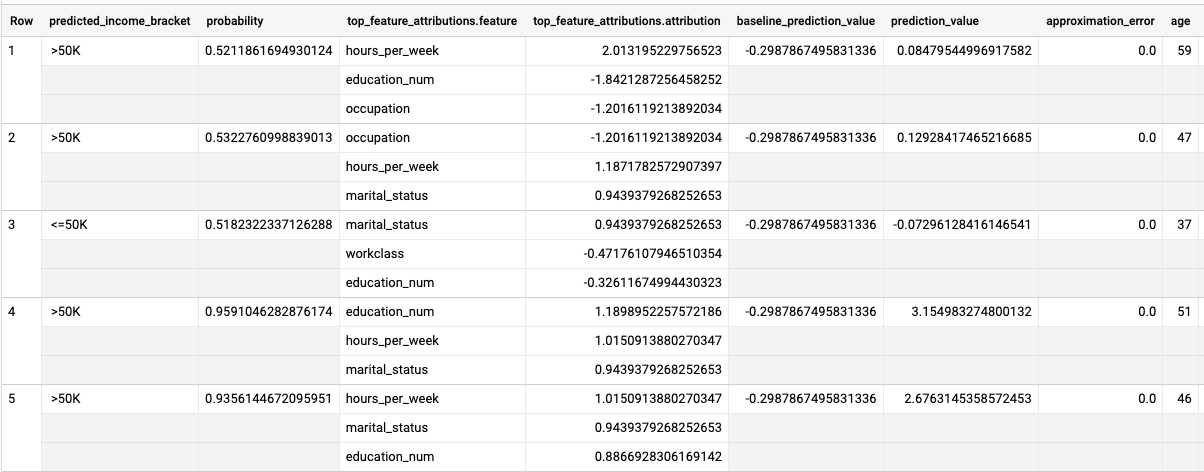
For logistic regression models, Shapley
values are used to determine relative
feature attribution for each feature in the model. Because the top_k_features
option was set to 3 in the query, ML.EXPLAIN_PREDICT outputs the top three
feature attributions for each row of the input_data view. These attributions
are shown in descending order by the absolute value of the attribution.
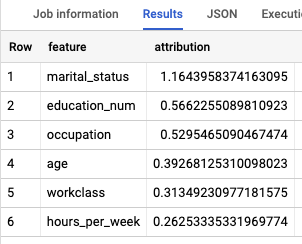
Globally explain the model
To know which features are the most important to determine the income bracket,
use the
ML.GLOBAL_EXPLAIN function.
Get global explanations for the model:
In the Google Cloud console, go to the BigQuery page.
In the query editor, run the following query to get global explanations:
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `census.census_model`)
The results look similar to the following:
Clean up
To avoid incurring charges to your Google Cloud account for the resources used in this tutorial, either delete the project that contains the resources, or keep the project and delete the individual resources.
Delete your dataset
Deleting your project removes all datasets and all tables in the project. If you prefer to reuse the project, you can delete the dataset you created in this tutorial:
If necessary, open the BigQuery page in the Google Cloud console.
In the navigation, click the census dataset you created.
Click Delete dataset on the right side of the window. This action deletes the dataset and the model.
In the Delete dataset dialog, confirm the delete command by typing the name of your dataset (
census) and then click Delete.
Delete your project
To delete the project:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
What's next
- For an overview of BigQuery ML, see Introduction to BigQuery ML.
- For information on creating models, see the
CREATE MODELsyntax page.