Neste tutorial, vai usar um modelo de regressão linear no BigQuery ML para prever o peso de um pinguim com base nas informações demográficas do pinguim. Uma regressão linear é um tipo de modelo de regressão que gera um valor contínuo a partir de uma combinação linear de caraterísticas de entrada.
Este tutorial usa o conjunto de dados
bigquery-public-data.ml_datasets.penguins.
Objetivos
Neste tutorial, vai realizar as seguintes tarefas:
- Crie um modelo de regressão linear.
- Avalie o modelo.
- Faça previsões com o modelo.
Custos
Este tutorial usa componentes faturáveis do Google Cloud, incluindo o seguinte:
- BigQuery
- BigQuery ML
Para mais informações sobre os custos do BigQuery, consulte a página de preços do BigQuery.
Para mais informações sobre os custos do BigQuery ML, consulte os preços do BigQuery ML.
Antes de começar
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Autorizações necessárias
Para criar o modelo com o BigQuery ML, precisa das seguintes autorizações de IAM:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
Para executar a inferência, precisa das seguintes autorizações:
bigquery.models.getDatano modelobigquery.jobs.create
Crie um conjunto de dados
Crie um conjunto de dados do BigQuery para armazenar o seu modelo de ML.
Consola
Na Google Cloud consola, aceda à página BigQuery.
No painel Explorador, clique no nome do projeto.
Clique em Ver ações > Criar conjunto de dados
Na página Criar conjunto de dados, faça o seguinte:
Para o ID do conjunto de dados, introduza
bqml_tutorial.Em Tipo de localização, selecione Várias regiões e, de seguida, selecione EUA (várias regiões nos Estados Unidos).
Deixe as restantes predefinições como estão e clique em Criar conjunto de dados.
bq
Para criar um novo conjunto de dados, use o comando
bq mk com a flag --location. Para uma lista completa de parâmetros possíveis, consulte a referência do comando bq mk --dataset.
Crie um conjunto de dados com o nome
bqml_tutorialcom a localização dos dados definida comoUSe uma descrição deBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Em vez de usar a flag
--dataset, o comando usa o atalho-d. Se omitir-de--dataset, o comando cria um conjunto de dados por predefinição.Confirme que o conjunto de dados foi criado:
bq ls
API
Chame o método datasets.insert
com um recurso de conjunto de dados definido.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
DataFrames do BigQuery
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
Crie o modelo
Crie um modelo de regressão linear com o conjunto de dados de exemplo do Analytics para o BigQuery.
SQL
Pode criar um modelo de regressão linear usando a declaração
CREATE MODEL
e especificando LINEAR_REG para o tipo de modelo. A criação do modelo inclui a preparação do mesmo.
Seguem-se aspetos úteis a ter em conta acerca da declaração CREATE MODEL:
- A opção
input_label_colsespecifica que coluna na declaraçãoSELECTusar como coluna de etiqueta. Aqui, a coluna de etiquetas ébody_mass_g. Para os modelos de regressão linear, a coluna de etiqueta tem de ter valores reais, ou seja, os valores da coluna têm de ser números reais. A declaração
SELECTdesta consulta usa as seguintes colunas na tabelabigquery-public-data.ml_datasets.penguinspara prever o peso de um pinguim:species: a espécie de pinguim.island: a ilha onde o pinguim reside.culmen_length_mm: o comprimento do culmen do pinguim em milímetros.culmen_depth_mm: a profundidade do culmen do pinguim em milímetros.flipper_length_mm: o comprimento das barbatanas do pinguim em milímetros.sex: o sexo do pinguim.
A cláusula
WHEREna declaraçãoSELECTdesta consulta,WHERE body_mass_g IS NOT NULL, exclui as linhas onde a colunabody_mass_géNULL.
Execute a consulta que cria o modelo de regressão linear:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, execute a seguinte consulta:
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS (model_type='linear_reg', input_label_cols=['body_mass_g']) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
A criação do modelo
penguins_modeldemora cerca de 30 segundos. Para ver o modelo, aceda ao painel Explorador, expanda o conjunto de dadosbqml_tutoriale, em seguida, expanda a pasta Modelos.
DataFrames do BigQuery
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
A criação do modelo demora cerca de 30 segundos. Para ver o modelo, aceda ao painel Explorador, expanda o conjunto de dados bqml_tutorial e, de seguida, expanda a pasta Modelos.
Obtenha estatísticas de treino
Para ver os resultados da preparação do modelo, pode usar a função ML.TRAINING_INFO ou ver as estatísticas na Google Cloud consola. Neste tutorial, vai usar a Google Cloud consola.
Um algoritmo de aprendizagem automática cria um modelo examinando muitos exemplos e tentando encontrar um modelo que minimize a perda. Este processo é denominado minimização de risco empírico.
A perda é a penalização por uma má previsão. É um número que indica o quão má foi a previsão do modelo num único exemplo. Se a previsão do modelo for perfeita, a perda é zero; caso contrário, a perda é superior. O objetivo da preparação de um modelo é encontrar um conjunto de ponderações e desvios que tenham uma perda baixa, em média, em todos os exemplos.
Veja as estatísticas de preparação do modelo que foram geradas quando executou a consulta
CREATE MODEL:
No painel Explorador, expanda o conjunto de dados
bqml_tutoriale, em seguida, a pasta Modelos. Clique em penguins_model para abrir o painel de informações do modelo.Clique no separador Formação e, de seguida, clique em Tabela. Os resultados devem ser semelhantes aos seguintes:
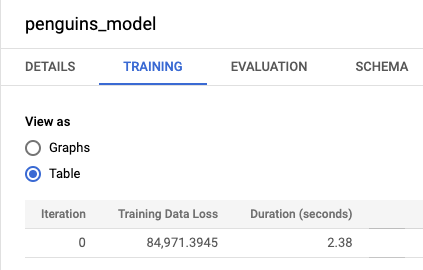
A coluna Perda de dados de preparação representa a métrica de perda calculada após a preparação do modelo no conjunto de dados de preparação. Uma vez que fez uma regressão linear, esta coluna mostra o valor do erro quadrático médio. É usada automaticamente uma estratégia de otimização de normal_equation para esta preparação, pelo que só é necessária uma iteração para convergir para o modelo final. Para mais informações sobre como definir a estratégia de otimização do modelo, consulte
optimize_strategy.
Avalie o modelo
Depois de criar o modelo, avalie o respetivo desempenho através da ML.EVALUATE função ou da score função BigQuery DataFrames para avaliar os valores previstos gerados pelo modelo em comparação com os dados reais.
SQL
Para a entrada, a função ML.EVALUATE usa o modelo preparado e um conjunto de dados que corresponde ao esquema dos dados que usou para preparar o modelo. Num ambiente de produção, deve avaliar o modelo com dados diferentes dos dados que usou para preparar o modelo.
Se executar ML.EVALUATE sem fornecer dados de entrada, a função obtém as métricas de avaliação calculadas durante a preparação. Estas métricas são calculadas
com o conjunto de dados de avaliação reservado automaticamente:
SELECT
*
FROM
ML.EVALUATE(MODEL bqml_tutorial.penguins_model);
Execute a consulta ML.EVALUATE:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, execute a seguinte consulta:
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL));
DataFrames do BigQuery
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
Os resultados devem ter um aspeto semelhante ao seguinte:
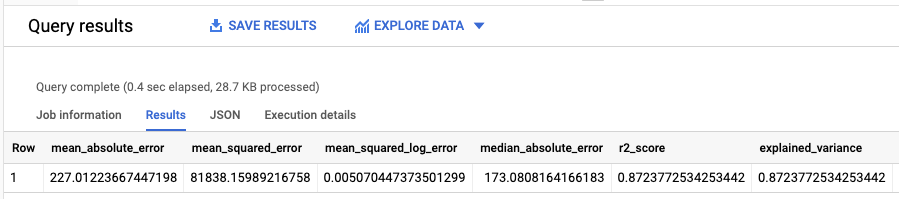
Como fez uma regressão linear, os resultados incluem as seguintes colunas:
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
Uma métrica importante nos resultados da avaliação é a
classificação R2.
A pontuação R2 é uma medida estatística que determina se as previsões de regressão linear se aproximam dos dados reais. Um valor de 0 indica que o modelo não explica nenhuma da variabilidade dos dados de resposta em torno da média. Um valor de 1 indica que o modelo explica toda a variabilidade dos dados de resposta em torno da média.
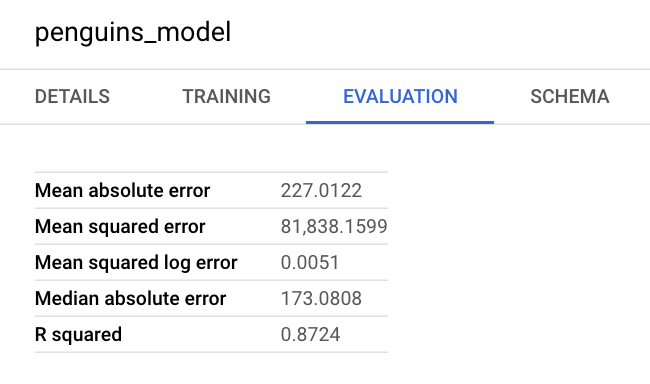
Também pode consultar o painel de informações do modelo na Google Cloud consola para ver as métricas de avaliação:
Use o modelo para prever resultados
Agora que avaliou o seu modelo, o passo seguinte é usá-lo para prever
um resultado. Pode executar a função predictBigQuery DataFrames no modelo para prever a massa corporal em gramas de todos os pinguins que residem nas ilhas Biscoe.ML.PREDICT
SQL
Para a entrada, a função ML.PREDICT usa o modelo preparado e um conjunto de dados que corresponde ao esquema dos dados que usou para preparar o modelo, excluindo a coluna de etiqueta.
Execute a consulta ML.PREDICT:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, execute a seguinte consulta:
SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'));
DataFrames do BigQuery
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
Os resultados devem ter um aspeto semelhante ao seguinte:

Explique os resultados da previsão
SQL
Para compreender por que motivo o modelo está a gerar estes resultados de previsão, pode usar a função ML.EXPLAIN_PREDICT.
ML.EXPLAIN_PREDICT é uma versão expandida da função ML.PREDICT.
ML.EXPLAIN_PREDICT não só produz resultados de previsão, como também produz colunas adicionais para explicar os resultados de previsão. Na prática, pode executar ML.EXPLAIN_PREDICT em vez de ML.PREDICT. Para mais informações, consulte a
Vista geral da IA explicável do BigQuery ML.
Execute a consulta ML.EXPLAIN_PREDICT:
- Na Google Cloud consola, aceda à página BigQuery.
- No editor de consultas, execute a seguinte consulta:
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'), STRUCT(3 as top_k_features));
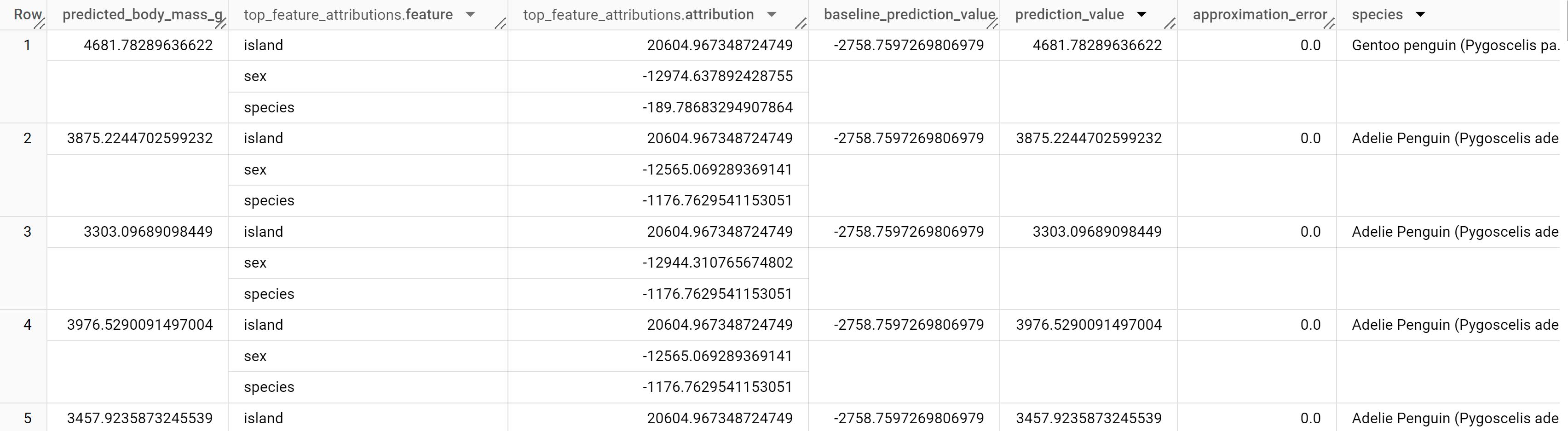
Os resultados devem ter um aspeto semelhante ao seguinte:
DataFrames do BigQuery
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
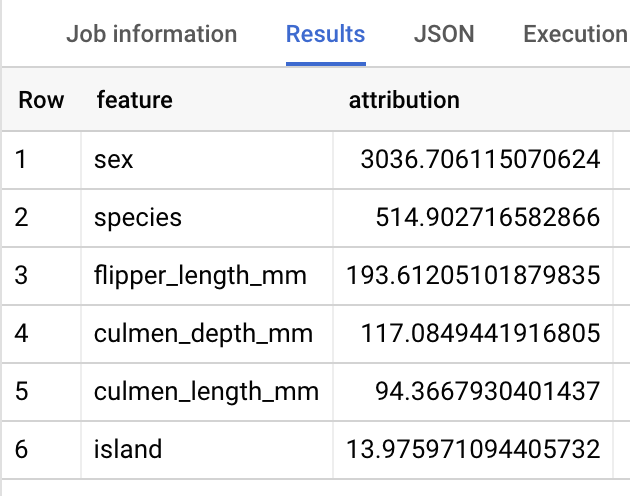
Para modelos de regressão linear, os valores de Shapley são usados para gerar valores de atribuição de funcionalidades para cada funcionalidade no modelo. O resultado inclui as três principais atribuições de funcionalidades por linha da tabela penguins porque top_k_features foi definido como 3. Estas atribuições são ordenadas pelo valor absoluto da atribuição por ordem descendente. Em todos os exemplos, a funcionalidade sex foi a que mais contribuiu para a previsão geral.
Explicar o modelo globalmente
SQL
Para saber que funcionalidades são geralmente as mais importantes para determinar o peso dos pinguins, pode usar a função ML.GLOBAL_EXPLAIN.
Para usar o ML.GLOBAL_EXPLAIN, tem de voltar a preparar o modelo com a opção ENABLE_GLOBAL_EXPLAIN definida como TRUE.
Treine novamente e receba explicações globais para o modelo:
- Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, execute a seguinte consulta para voltar a preparar o modelo:
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS ( model_type = 'linear_reg', input_label_cols = ['body_mass_g'], enable_global_explain = TRUE) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
No editor de consultas, execute a seguinte consulta para obter explicações globais:
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `bqml_tutorial.penguins_model`)
Os resultados devem ter um aspeto semelhante ao seguinte:
DataFrames do BigQuery
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
Limpar
Para evitar incorrer em custos na sua conta do Google Cloud pelos recursos usados neste tutorial, elimine o projeto que contém os recursos ou mantenha o projeto e elimine os recursos individuais.
- Pode eliminar o projeto que criou.
- Em alternativa, pode manter o projeto e eliminar o conjunto de dados.
Elimine o conjunto de dados
A eliminação do projeto remove todos os conjuntos de dados e todas as tabelas no projeto. Se preferir reutilizar o projeto, pode eliminar o conjunto de dados que criou neste tutorial:
Se necessário, abra a página do BigQuery na Google Cloud consola.
Na navegação, clique no conjunto de dados bqml_tutorial que criou.
Clique em Eliminar conjunto de dados no lado direito da janela. Esta ação elimina o conjunto de dados, a tabela e todos os dados.
Na caixa de diálogo Eliminar conjunto de dados, confirme o comando de eliminação escrevendo o nome do conjunto de dados (
bqml_tutorial) e, de seguida, clique em Eliminar.
Elimine o projeto
Para eliminar o projeto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
O que se segue?
- Para uma vista geral do BigQuery ML, consulte o artigo Introdução ao BigQuery ML.
- Para obter informações sobre como criar modelos, consulte a página de sintaxe
CREATE MODEL.