Neste tutorial, você usa um modelo de regressão linear no BigQuery ML para prever o peso de um pinguim com base nas informações demográficas dele. A regressão linear é um tipo de modelo de regressão que gera um valor contínuo a partir de uma combinação linear de recursos de entrada.
Neste tutorial, usamos o conjunto de dados bigquery-public-data.ml_datasets.penguins.
Objetivos
Neste tutorial, você realizará as seguintes tarefas:
- Criar um modelo de regressão linear.
- Avaliar o modelo.
- Fazer previsões usando o modelo.
Custos
Neste tutorial, usamos componentes faturáveis do Google Cloud, incluindo:
- BigQuery
- BigQuery ML
Para mais informações sobre os custos do BigQuery, consulte a página de preços do BigQuery.
Para mais informações sobre os custos do BigQuery ML, consulte os preços do BigQuery ML.
Antes de começar
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Permissões necessárias
Para criar o modelo usando o BigQuery ML, você precisa das seguintes permissões do IAM:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
Para executar a inferência, você precisa das seguintes permissões:
bigquery.models.getDatano modelobigquery.jobs.create
crie um conjunto de dados
Crie um conjunto de dados do BigQuery para armazenar seu modelo de ML.
Console
No console do Google Cloud , acesse a página BigQuery.
No painel Explorer, clique no nome do seu projeto.
Clique em Conferir ações > Criar conjunto de dados.
Na página Criar conjunto de dados, faça o seguinte:
Para o código do conjunto de dados, insira
bqml_tutorial.Em Tipo de local, selecione Multirregião e EUA (várias regiões nos Estados Unidos).
Mantenha as configurações padrão restantes e clique em Criar conjunto de dados.
bq
Para criar um novo conjunto de dados, utilize o
comando bq mk
com a sinalização --location. Para obter uma lista completa de parâmetros, consulte a
referência
comando bq mk --dataset.
Crie um conjunto de dados chamado
bqml_tutorialcom o local dos dados definido comoUSe uma descrição deBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Em vez de usar a flag
--dataset, o comando usa o atalho-d. Se você omitir-de--dataset, o comando vai criar um conjunto de dados por padrão.Confirme se o conjunto de dados foi criado:
bq ls
API
Chame o método datasets.insert com um recurso de conjunto de dados definido.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local.
Criar o modelo
Crie um modelo de regressão linear usando a amostra do conjunto de dados do Google Analytics no BigQuery.
SQL
Crie um modelo de regressão linear usando a CREATE MODELinstrução e especificando LINEAR_REG para o tipo de modelo. A criação do modelo inclui treiná-lo.
Confira abaixo informações úteis sobre a instrução CREATE MODEL:
- A opção
input_label_colsespecifica qual coluna na instruçãoSELECTdeve ser usada como a coluna de rótulo. Aqui, a coluna de rótulos ébody_mass_g. Para modelos de regressão linear, é preciso que a coluna de rótulo tenha valor real. Ou seja, os valores da coluna precisam ser números reais. A instrução
SELECTdessa consulta usa as seguintes colunas na tabelabigquery-public-data.ml_datasets.penguinspara prever o peso de um pinguim:species: a espécie do pinguim.island: a ilha que o pinguim habita.culmen_length_mm: o comprimento do cúlmen do pinguim em milímetros.culmen_depth_mm: a profundidade do cúlmen do pinguim em milímetros.flipper_length_mm: o comprimento das nadadeiras do pinguim em milímetros.sex: o sexo do pinguim.
A cláusula
WHEREna instruçãoSELECTdessa consulta,WHERE body_mass_g IS NOT NULL, exclui as linhas em que a colunabody_mass_géNULL.
Execute a consulta que cria seu modelo de regressão linear:
No console do Google Cloud , acesse a página BigQuery.
No Editor de consultas, execute esta consulta:
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS (model_type='linear_reg', input_label_cols=['body_mass_g']) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
A criação do modelo
penguins_modelleva cerca de 30 segundos. Para acessar o modelo, acesse o painel Explorer, expanda o conjunto de dadosbqml_tutoriale, em seguida, expanda a pasta Modelos.
BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local.
A criação do modelo leva cerca de 30 segundos. Para acessar o modelo, acesse o painel Explorer, expanda o conjunto de dados bqml_tutorial e, em seguida, expanda a pasta Modelos.
Ver estatísticas de treinamento
Para ver os resultados do treinamento de modelo, use a função ML.TRAINING_INFO ou consulte as estatísticas no console do Google Cloud . Neste
tutorial, você usa o console Google Cloud .
Para criar um modelo, um algoritmo de machine learning examina vários exemplos e tenta encontrar um modelo que minimize a perda. Esse processo é chamado de "minimização de riscos empíricos".
Perda é a penalidade para uma previsão ruim. É um número que indica a qualidade da previsão do modelo em um único exemplo. Para uma previsão de modelo perfeita, a perda é zero. Caso contrário, a perda é maior. O treinamento de um modelo visa encontrar um conjunto de ponderações e tendências com uma média de perda menor em todos os exemplos.
Veja as estatísticas do treinamento de modelo que foram geradas ao executar a consulta CREATE MODEL:
No painel Explorer, expanda o conjunto de dados
bqml_tutoriale, em seguida, a pasta Modelos. Clique em penguins_model para abrir o painel de informações do modelo.Clique na guia Treinamento e depois em Tabela. Os resultados devem ficar assim:
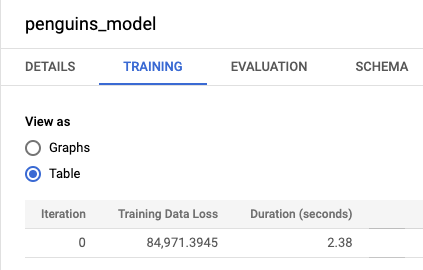
A coluna Perda de dados de treinamento representa métrica da perda, calculada depois de o modelo ser treinado no conjunto de dados de treinamento. Como você executou uma regressão linear, essa coluna mostra o valor do erro quadrático médio. Uma estratégia de otimização normal_equation é usada automaticamente neste treinamento. Portanto, apenas uma iteração precisa convergir para o modelo final. Para mais informações sobre como definir a estratégia de otimização do modelo, consulte
optimize_strategy.
Avaliar o modelo
Depois de criar o modelo, avalie o desempenho dele usando a função ML.EVALUATE ou a função score do BigQuery DataFrames para comparar os valores previstos gerados pelo modelo com os dados reais.
SQL
Para entrada, a função ML.EVALUATE usa o modelo treinado e um conjunto de dados que corresponde ao esquema dos dados usados para treinar o modelo. Em um ambiente de produção, avalie o modelo com dados diferentes daqueles usados para treiná-lo.
Quando você executa ML.EVALUATE sem fornecer dados de entrada, a função recupera as métricas de avaliação calculadas durante o treinamento. Essas métricas são calculadas usando o conjunto de dados de avaliação reservado automaticamente:
SELECT
*
FROM
ML.EVALUATE(MODEL bqml_tutorial.penguins_model);
Execute a consulta ML.EVALUATE:
No console do Google Cloud , acesse a página BigQuery.
No Editor de consultas, execute esta consulta:
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL));
BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local.
A resposta deve ficar assim:
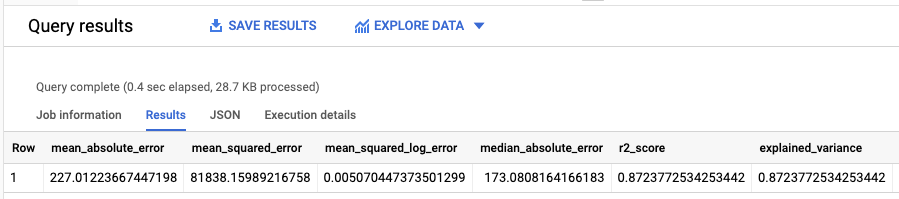
Como você executou uma regressão linear, os resultados incluem as seguintes colunas:
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
Uma métrica importante nos resultados da avaliação é a pontuação R2.
A pontuação R2 é uma medida estatística que determina se as previsões de regressão linear se aproximam dos dados reais. Um valor 0 indica que o modelo não explica qualquer variabilidade dos dados de resposta em torno da média. Um valor 1 indica que o modelo explica toda a variabilidade dos dados de resposta em torno da média.
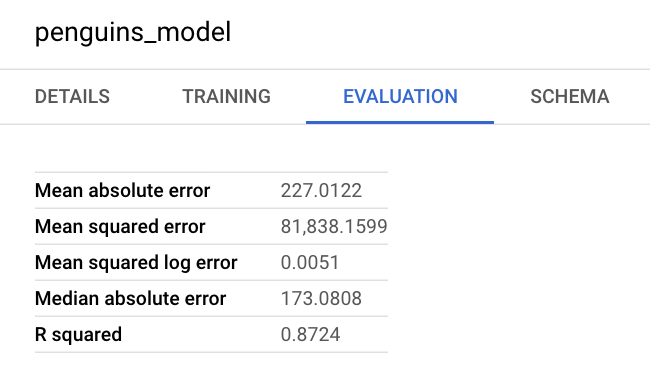
Também é possível consultar o painel de informações do modelo no Google Cloud console para conferir as métricas de avaliação:
Usar o modelo para prever resultados
Agora seu modelo foi avaliado, a próxima etapa é usá-lo para prever um resultado. Execute a função ML.PREDICT ou a função predict DataFrames do BigQuery no modelo para prever a massa corporal em gramas de todos os pinguins que habitam as Ilhas Biscoe.
SQL
Para entrada, a função ML.PREDICT usa o modelo treinado e um conjunto de dados que corresponde ao esquema dos dados que você usou para treinar o modelo, excluindo a coluna de rótulos.
Execute a consulta ML.PREDICT:
No console do Google Cloud , acesse a página BigQuery.
No Editor de consultas, execute esta consulta:
SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'));
BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local.
A resposta deve ficar assim:

Explicar os resultados da previsão
SQL
Para entender por que o modelo está gerando esses resultados de previsão, use a função ML.EXPLAIN_PREDICT.
ML.EXPLAIN_PREDICT é uma versão estendida da função ML.PREDICT.
ML.EXPLAIN_PREDICT não apenas gera resultados de previsão, mas também gera colunas extras para explicar os resultados da previsão. Na prática, é possível executar ML.EXPLAIN_PREDICT no lugar de ML.PREDICT. Para mais informações, consulte Visão geral da Explainable AI no BigQuery ML.
Execute a consulta ML.EXPLAIN_PREDICT:
- No console do Google Cloud , acesse a página BigQuery.
- No Editor de consultas, execute esta consulta:
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'), STRUCT(3 as top_k_features));
A resposta deve ficar assim:
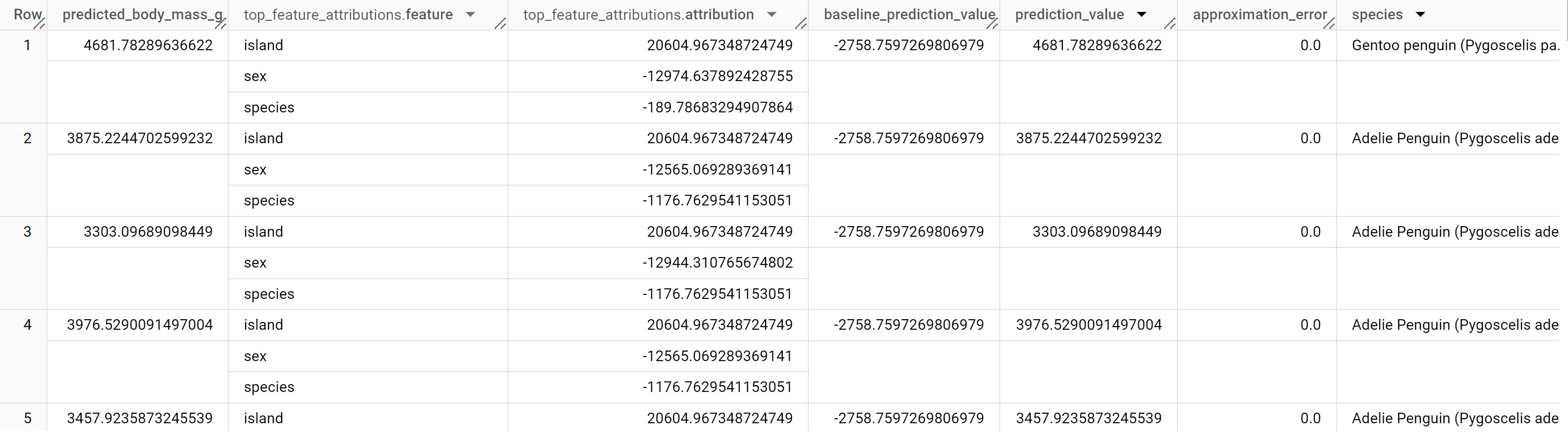
BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local.
Para modelos de regressão linear, os valores de Shapley são usados para gerar valores de atribuição de recursos para cada recurso no modelo. A saída inclui as três principais atribuições de recursos por linha da tabela penguins porque top_k_features foi definido como 3. Essas atribuições são classificadas pelo valor absoluto da atribuição, em ordem decrescente. Em todos os exemplos, o recurso sex contribuiu mais com a previsão geral.
Explicar o modelo globalmente
SQL
Para saber quais recursos geralmente são os mais importantes para determinar o peso do pinguim, use a função ML.GLOBAL_EXPLAIN.
Para usar ML.GLOBAL_EXPLAIN, treine novamente o modelo com a opção ENABLE_GLOBAL_EXPLAIN definida como TRUE.
Treine novamente e receba explicações globais para o modelo:
- No console do Google Cloud , acesse a página BigQuery.
No editor de consultas, execute a seguinte consulta para treinar novamente o modelo:
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS ( model_type = 'linear_reg', input_label_cols = ['body_mass_g'], enable_global_explain = TRUE) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
No editor de consultas, execute a seguinte consulta para receber explicações globais:
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `bqml_tutorial.penguins_model`)
A resposta deve ficar assim:
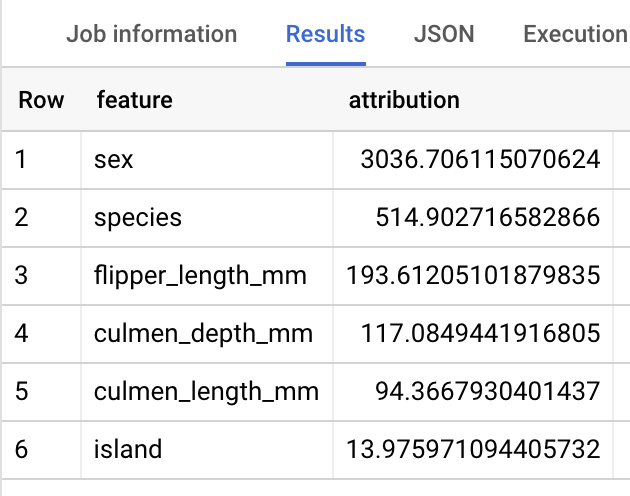
BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local.
Limpeza
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
- exclua o projeto que você criou; ou
- Mantenha o projeto e exclua o conjunto de dados.
Excluir o conjunto de dados
A exclusão do seu projeto removerá todos os conjuntos de dados e tabelas no projeto. Caso prefira reutilizá-lo, exclua o conjunto de dados criado neste tutorial:
Se necessário, abra a página do BigQuery no console doGoogle Cloud .
Na navegação, clique no conjunto de dados bqml_tutorial criado.
Clique em Excluir conjunto de dados no lado direito da janela. Essa ação exclui o conjunto, a tabela e todos os dados.
Na caixa de diálogo Excluir conjunto de dados, confirme o comando de exclusão digitando o nome do seu conjunto de dados (
bqml_tutorial) e clique em Excluir.
Excluir o projeto
Para excluir o projeto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
A seguir
- Para uma visão geral sobre ML do BigQuery, consulte Introdução ao ML do BigQuery.
- Para mais informações sobre como criar modelos, consulte a página de sintaxe
CREATE MODEL.