In dieser Anleitung verwenden Sie ein lineares Regressionsmodell in BigQuery ML, um das Gewicht eines Pinguins basierend auf den demografischen Informationen des Pinguins vorherzusagen. Eine lineare Regression ist eine Art von Regressionsmodell, das aus einer linearen Kombination von Eingabemerkmalen einen kontinuierlichen Wert generiert.
In dieser Anleitung wird das Dataset bigquery-public-data.ml_datasets.penguins verwendet.
Ziele
Aufgaben in dieser Anleitung:
- Erstellen Sie ein lineares Regressionsmodell.
- Modell bewerten
- Vorhersagen mithilfe des Modells treffen.
Kosten
In dieser Anleitung werden kostenpflichtige Komponenten von Google Cloudverwendet, darunter:
- BigQuery
- BigQuery ML
Weitere Informationen zu den Kosten für BigQuery finden Sie auf der Seite BigQuery-Preise.
Weitere Informationen zu den Kosten für BigQuery ML finden Sie unter BigQuery ML-Preise.
Hinweise
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Erforderliche Berechtigungen
Zum Erstellen des Modells mit BigQuery ML benötigen Sie die folgenden IAM-Berechtigungen:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
Zum Ausführen von Inferenzen benötigen Sie die folgenden Berechtigungen:
bigquery.models.getDatafür das Modellbigquery.jobs.create
Dataset erstellen
Erstellen Sie ein BigQuery-Dataset zum Speichern Ihres ML-Modells.
Konsole
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Klicken Sie im Bereich Explorer auf den Namen Ihres Projekts.
Klicken Sie auf Aktionen ansehen > Dataset erstellen.
Führen Sie auf der Seite Dataset erstellen die folgenden Schritte aus:
Geben Sie unter Dataset-ID
bqml_tutorialein.Wählen Sie als Standorttyp die Option Mehrere Regionen und dann USA (mehrere Regionen in den USA) aus.
Übernehmen Sie die verbleibenden Standardeinstellungen unverändert und klicken Sie auf Dataset erstellen.
bq
Wenn Sie ein neues Dataset erstellen möchten, verwenden Sie den Befehl bq mk mit dem Flag --location. Eine vollständige Liste der möglichen Parameter finden Sie in der bq mk --dataset-Befehlsreferenz.
Erstellen Sie ein Dataset mit dem Namen
bqml_tutorial, wobei der Datenspeicherort aufUSund die Beschreibung aufBigQuery ML tutorial datasetfestgelegt ist:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Anstelle des Flags
--datasetverwendet der Befehl die verkürzte Form-d. Wenn Sie-dund--datasetauslassen, wird standardmäßig ein Dataset erstellt.Prüfen Sie, ob das Dataset erstellt wurde:
bq ls
API
Rufen Sie die Methode datasets.insert mit einer definierten Dataset-Ressource auf.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Modell erstellen
Erstellen Sie mithilfe des Analytics-Beispieldatasets für BigQuery ein lineares Regressionsmodell.
SQL
Sie können ein lineares Regressionsmodell durch Verwendung der Anweisung CREATE MODEL und Angabe von LINEAR_REG für den Modelltyp erstellen. Das Erstellen des Modells umfasst das Training des Modells.
Im Folgenden finden Sie nützliche Informationen zur CREATE MODEL-Anweisung:
- Die Option
input_label_colsgibt an, welche Spalte in derSELECT-Anweisung als Labelspalte verwendet werden soll. Hier lautet die Labelspaltebody_mass_g. Bei linearen Regressionsmodellen muss die Labelspalte reelle Zahlen als Werte enthalten. Die
SELECT-Anweisung dieser Abfrage verwendet die folgenden Spalten in der Tabellebigquery-public-data.ml_datasets.penguins, um das Gewicht eines Pinguins vorherzusagen:species: die Pinguinart.island: die Insel, auf der der Pinguin lebt.culmen_length_mm: die Länge des Schnabelrückens des Pinguins in Millimetern.culmen_depth_mm: die Tiefe des Schnabelrückens des Pinguins in Millimetern.flipper_length_mm: die Länge der Pinguinflosen in Millimetern.sex: das Geschlecht des Pinguins.
Die
WHERE-Klausel in derSELECT-Anweisung dieser Abfrage,WHERE body_mass_g IS NOT NULL, schließt Zeilen aus, in denen die Spaltebody_mass_gden WertNULLhat.
Führen Sie die Abfrage aus, mit der Ihr lineares Regressionsmodell erstellt wird:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Führen Sie im Abfrageeditor folgende Abfrage aus:
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS (model_type='linear_reg', input_label_cols=['body_mass_g']) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
Das Erstellen des
penguins_model-Modells dauert ungefähr 30 Sekunden. Wenn Sie das Modell ansehen möchten, öffnen Sie den Bereich Explorer, erweitern Sie das Datasetbqml_tutorialund maximieren Sie dann den Ordner Modelle.
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Das Erstellen des Modells dauert ungefähr 30 Sekunden. Wenn Sie das Modell ansehen möchten, öffnen Sie den Bereich Explorer, erweitern Sie das Dataset bqml_tutorial und maximieren Sie dann den Ordner Modelle.
Trainingsstatistiken abrufen
Mit der Funktion ML.TRAINING_INFO können Sie die Ergebnisse des Modelltrainings abrufen. Alternativ lassen sich die Statistiken auch in der Google Cloud -Konsole abrufen. In dieser Anleitung verwenden Sie die Google Cloud Console.
Ein maschineller Lernalgorithmus erstellt ein Modell durch Analyse vieler Beispiele. Ziel ist es, ein Modell zu finden, das den Verlust minimiert. Dieser Vorgang wird als empirische Risikominimierung bezeichnet.
Verlust ist der Strafwert für eine schlechte Vorhersage. Es ist eine Zahl, die angibt, wie schlecht die Vorhersage des Modells bei einem einzelnen Beispiel war. Wenn die Vorhersage des Modells genau ist, entspricht dies einem Verlust von null. Je ungenauer die Vorhersage ist, desto höher ist der Verlust. Ziel des Modelltrainings ist es, eine Reihe von Gewichtungen und Verzerrungen zu finden, die bei allen Beispielen im Schnitt einen geringen Verlust aufweisen.
Sehen Sie sich die Statistiken des Modelltrainings an, die beim Ausführen der CREATE MODEL-Abfrage generiert wurden:
Maximieren Sie im Bereich Explorer das Dataset
bqml_tutorialund dann den Ordner Modelle. Klicken Sie auf penguins_model, um den Informationsbereich für das Modell zu öffnen.Klicken Sie auf den Tab Training und dann auf Tabelle. Die Antwort sollte in etwa so aussehen:
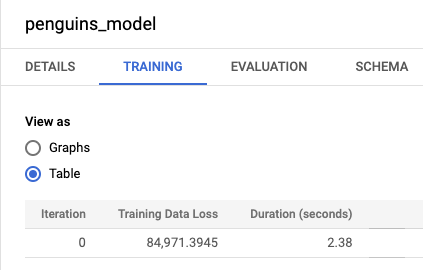
Die Spalte Trainingsdatenverlust enthält den Verlustmesswert, der berechnet wird, nachdem das Modell mit dem Trainings-Dataset trainiert wurde. Da Sie eine lineare Regression durchgeführt haben, wird in dieser Spalte der Wert für die mittlere quadratische Abweichung angezeigt. Für dieses Training wird automatisch eine Optimierungsstrategie "normal_equation" verwendet. Daher ist nur eine einzelne Iteration bis zum endgültigen Modell erforderlich. Weitere Informationen zum Festlegen der Modelloptimierungsstrategie finden Sie unter
optimize_strategy.
Modell bewerten
Nachdem Sie das Modell erstellt haben, können Sie die Leistung des Modells mit der Funktion ML.EVALUATE oder der BigQuery DataFrames-Funktion score bewerten, um die vom Modell generierten Vorhersagewerte anhand der tatsächlichen Daten auszuwerten.
SQL
Als Eingabe verwendet die Funktion ML.EVALUATE das trainierte Modell und ein Dataset, das mit dem Schema der Daten übereinstimmt, die Sie zum Trainieren des Modells verwendet haben. In einer Produktionsumgebung sollten Sie das Modell anhand anderer Daten als den Daten bewerten, die Sie zum Trainieren des Modells verwendet haben.
Wenn Sie ML.EVALUATE ausführen, ohne Eingabedaten anzugeben, ruft die Funktion die Bewertungsmesswerte ab, die während des Trainings berechnet wurden. Diese Messwerte werden mithilfe des automatisch reservierten Bewertungs-Datasets berechnet:
SELECT
*
FROM
ML.EVALUATE(MODEL bqml_tutorial.penguins_model);
Führen Sie die ML.EVALUATE-Abfrage aus:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Führen Sie im Abfrageeditor folgende Abfrage aus:
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL));
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Die Antwort sollte in etwa so aussehen:
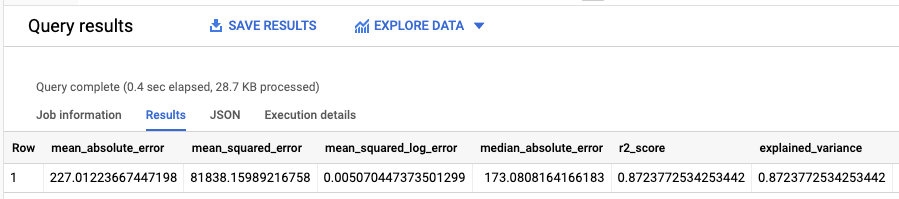
Da Sie eine lineare Regression durchgeführt haben, enthalten die Ergebnisse die folgenden Spalten:
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
Ein wichtiger Messwert in den Bewertungsergebnissen ist der R2-Wert.
Der R2-Wert ist ein statistisches Maß dafür, ob sich die Vorhersagen der linearen Regression den tatsächlichen Daten annähern. Der Wert 0 gibt an, dass das Modell keine der Abweichungen der Antwortdaten um den Mittelwert erklärt. Der Wert 1 gibt an, dass das Modell alle Abweichungen der Antwortdaten um den Mittelwert erklärt.
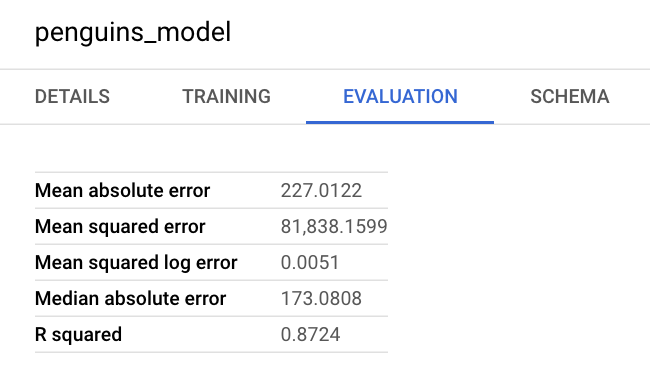
Sie können auch den Informationsbereich des Modells in der Google Cloud Console aufrufen, um die Bewertungsmesswerte anzuzeigen:
Modell verwenden, um Ergebnisse vorherzusagen
Nachdem Sie Ihr Modell ausgewertet haben, besteht der nächste Schritt darin, ein Ergebnis vorherzusagen. Sie können die ML.PREDICT-Funktion oder die predict-BigQuery-DataFrames-Funktion auf dem Modell ausführen, um die Körpermasse der auf den Biscoeinseln lebenden Pinguine in Gramm vorherzusagen.
SQL
Als Eingabe verwendet die Funktion ML.PREDICT das trainierte Modell und ein Dataset, das dem Schema der Daten entspricht, die Sie mit Ausnahme der Labelspalte zum Trainieren des Modells verwendet haben.
Führen Sie die ML.PREDICT-Abfrage aus:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Führen Sie im Abfrageeditor folgende Abfrage aus:
SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'));
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Die Antwort sollte in etwa so aussehen:

Vorhersageergebnisse erklären
SQL
Mit der Funktion ML.EXPLAIN_PREDICT können Sie ermitteln, warum das Modell diese Vorhersageergebnisse generiert.
ML.EXPLAIN_PREDICT ist eine erweiterte Version der Funktion ML.PREDICT.
ML.EXPLAIN_PREDICT gibt nicht nur Vorhersageergebnisse aus, sondern gibt auch zusätzliche Spalten aus, um die Vorhersageergebnisse zu erklären. In der Praxis können Sie ML.EXPLAIN_PREDICT anstelle von ML.PREDICT ausführen. Weitere Informationen finden Sie in der Übersicht zu BigQuery ML Explainable AI.
Führen Sie die ML.EXPLAIN_PREDICT-Abfrage aus:
- Öffnen Sie in der Google Cloud Console die Seite BigQuery.
- Führen Sie im Abfrageeditor folgende Abfrage aus:
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'), STRUCT(3 as top_k_features));
Die Antwort sollte in etwa so aussehen:
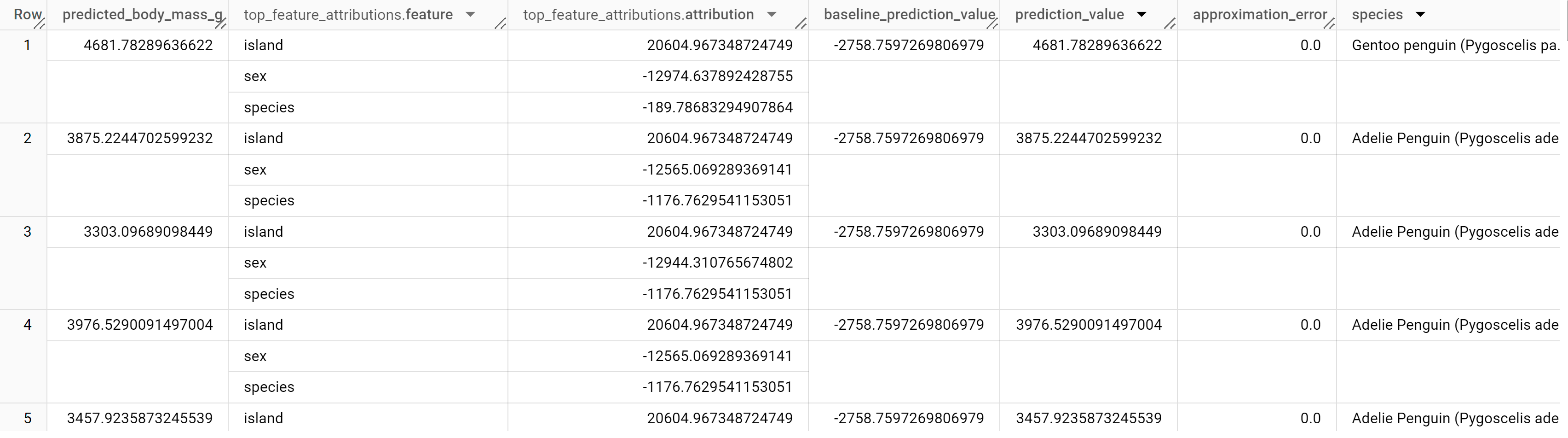
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Bei linearen Regressionsmodellen werden Shapley-Werte verwendet, um für jedes Feature im Modell Feature-Attributionswerte zu generieren. Die Ausgabe enthält die drei wichtigsten Featureattributionen pro Zeile der Tabelle penguins, da top_k_features auf 3 gesetzt wurde. Diese Zuordnungen werden nach dem absoluten Wert der Attribution in absteigender Reihenfolge sortiert. In allen Beispielen trägt die Funktion sex am meisten zur Gesamtvorhersage bei.
Modell global erklären
SQL
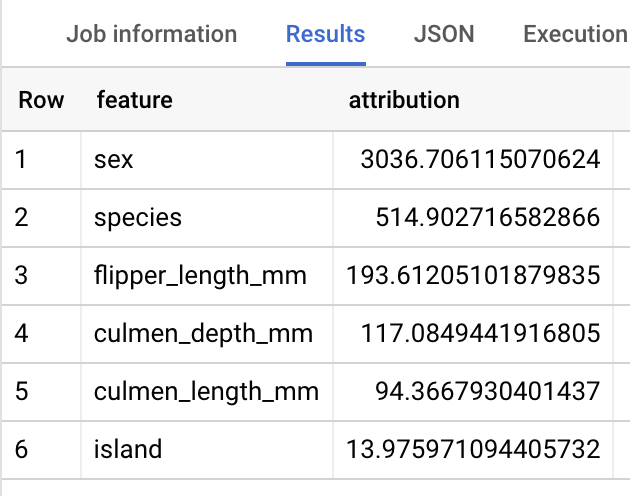
Mit der Funktion ML.GLOBAL_EXPLAIN können Sie ermitteln, welche Features im Allgemeinen am wichtigsten sind, um das Pinguingewicht zu bestimmen.
Zur Verwendung von ML.GLOBAL_EXPLAIN müssen Sie das Modell mit der Option ENABLE_GLOBAL_EXPLAIN auf TRUE neu trainieren.
Trainieren Sie das Modell neu und rufen Sie globale Erläuterungen für das Modell ab:
- Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Führen Sie im Abfrageeditor die folgende Abfrage aus, um das Modell neu zu trainieren:
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS ( model_type = 'linear_reg', input_label_cols = ['body_mass_g'], enable_global_explain = TRUE) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
Führen Sie im Abfrageeditor die folgende Abfrage aus, um globale Erläuterungen zu erhalten:
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `bqml_tutorial.penguins_model`)
Die Antwort sollte in etwa so aussehen:
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
- Sie können das von Ihnen erstellte Projekt löschen.
- Sie können das Projekt aber auch behalten und das Dataset löschen.
Dataset löschen
Wenn Sie Ihr Projekt löschen, werden alle Datasets und Tabellen entfernt. Wenn Sie das Projekt wieder verwenden möchten, können Sie das in dieser Anleitung erstellte Dataset löschen:
Rufen Sie, falls erforderlich, die Seite „BigQuery“ in derGoogle Cloud Console auf.
Wählen Sie im Navigationsbereich das Dataset bqml_tutorial aus, das Sie erstellt haben.
Klicken Sie rechts im Fenster auf Delete dataset (Dataset löschen). Dadurch werden das Dataset, die Tabelle und alle Daten gelöscht.
Bestätigen Sie im Dialogfeld Delete dataset (Dataset löschen) den Löschbefehl. Geben Sie dazu den Namen des Datasets (
bqml_tutorial) ein und klicken Sie auf Delete (Löschen).
Projekt löschen
So löschen Sie das Projekt:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Nächste Schritte
- Einführung in BigQuery ML
- Mehr zum Erstellen von Modellen auf der Seite zur
CREATE MODEL-Syntax