Dalam tutorial ini, Anda akan menggunakan model regresi linier di BigQuery ML untuk memprediksi berat penguin berdasarkan informasi demografis penguin. Regresi linear adalah jenis model regresi yang menghasilkan nilai berkelanjutan dari kombinasi linear fitur input.
Tutorial ini menggunakan set data
bigquery-public-data.ml_datasets.penguins.
Tujuan
Dalam tutorial ini, Anda akan melakukan tugas-tugas berikut:
- Buat model regresi linear.
- Mengevaluasi model.
- Buat prediksi menggunakan model.
Biaya
Tutorial ini menggunakan komponen yang dapat ditagih dari Google Cloud, termasuk:
- BigQuery
- BigQuery ML
Untuk informasi selengkapnya tentang biaya BigQuery, lihat halaman harga BigQuery.
Untuk informasi selengkapnya tentang biaya BigQuery ML, lihat harga BigQuery ML.
Sebelum memulai
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Izin yang diperlukan
Untuk membuat model menggunakan BigQuery ML, Anda memerlukan izin IAM berikut:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
Untuk menjalankan inferensi, Anda memerlukan izin berikut:
bigquery.models.getDatapada modelbigquery.jobs.create
Membuat set data
Buat set data BigQuery untuk menyimpan model ML Anda.
Konsol
Di konsol Google Cloud , buka halaman BigQuery.
Di panel Explorer, klik nama project Anda.
Klik View actions > Create dataset.
Di halaman Create dataset, lakukan hal berikut:
Untuk Dataset ID, masukkan
bqml_tutorial.Untuk Location type, pilih Multi-region, lalu pilih US (multiple regions in United States).
Jangan ubah setelan default yang tersisa, lalu klik Create dataset.
bq
Untuk membuat set data baru, gunakan perintah bq mk dengan flag --location. Untuk daftar lengkap kemungkinan parameter, lihat referensi
perintah bq mk --dataset.
Buat set data bernama
bqml_tutorialdengan lokasi data yang ditetapkan keUSdan deskripsiBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Perintah ini menggunakan pintasan
-d, bukan flag--dataset. Jika Anda menghapus-ddan--dataset, perintah defaultnya adalah membuat set data.Pastikan set data telah dibuat:
bq ls
API
Panggil metode datasets.insert dengan resource set data yang ditentukan.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di Panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Buat model
Buat model regresi linear menggunakan set data contoh Analytics untuk BigQuery.
SQL
Anda dapat membuat model regresi linear menggunakan
pernyataan CREATE MODEL
dan menentukan LINEAR_REG untuk jenis model. Pembuatan model mencakup
pelatihan model.
Berikut adalah hal-hal berguna yang perlu diketahui tentang pernyataan CREATE MODEL:
- Opsi
input_label_colsmenentukan kolom mana dalam pernyataanSELECTyang akan digunakan sebagai kolom label. Di sini, kolom labelnya adalahbody_mass_g. Untuk model regresi linear, kolom label harus bernilai riil, yaitu, nilai kolom harus berupa bilangan riil. Pernyataan
SELECTkueri ini menggunakan kolom berikut dalam tabelbigquery-public-data.ml_datasets.penguinsuntuk memprediksi berat penguin:species: spesies penguin.island: pulau tempat penguin tinggal.culmen_length_mm: panjang paruh penguin dalam milimeter.culmen_depth_mm: kedalaman paruh penguin dalam milimeter.flipper_length_mm: panjang sirip penguin dalam milimeter.sex: jenis kelamin penguin.
Klausa
WHEREdalam pernyataanSELECTkueri ini,WHERE body_mass_g IS NOT NULL, mengecualikan baris dengan kolombody_mass_gadalahNULL.
Jalankan kueri yang membuat model regresi linear Anda:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, jalankan kueri berikut:
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS (model_type='linear_reg', input_label_cols=['body_mass_g']) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
Pembuatan model
penguins_modelmemerlukan waktu sekitar 30 detik. Untuk melihat model, buka panel Explorer, luaskan set databqml_tutorial, lalu luaskan folder Models.
DataFrame BigQuery
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di Panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Pembuatan model memerlukan waktu sekitar 30 detik. Untuk melihat model, buka panel Explorer, luaskan set data bqml_tutorial, lalu luaskan folder Models.
Mendapatkan statistik pelatihan
Untuk melihat hasil pelatihan model, Anda dapat menggunakan
fungsi ML.TRAINING_INFO,
atau Anda dapat melihat statistik di konsol Google Cloud . Dalam tutorial ini, Anda akan menggunakan konsol Google Cloud .
Algoritma machine learning membuat model dengan memeriksa banyak contoh dan mencoba menemukan model yang meminimalkan kerugian. Proses ini disebut minimalisasi risiko empiris.
Kerugian merupakan akibat dari prediksi yang buruk. Loss adalah angka yang menunjukkan seberapa buruk prediksi model pada satu contoh. Jika prediksi model sempurna, kerugiannya nol. Jika tidak, kerugiannya akan lebih besar. Tujuan pelatihan model adalah untuk menemukan set bobot dan bias yang memiliki kerugian rendah, secara rata-rata, di semua contoh.
Lihat statistik pelatihan model yang dihasilkan saat Anda menjalankan kueri CREATE MODEL:
Di panel Explorer, luaskan set data
bqml_tutorial, lalu luaskan folder Models. Klik penguins_model untuk membuka panel informasi model.Klik tab Pelatihan, lalu klik Tabel. Hasilnya akan terlihat mirip dengan berikut ini:
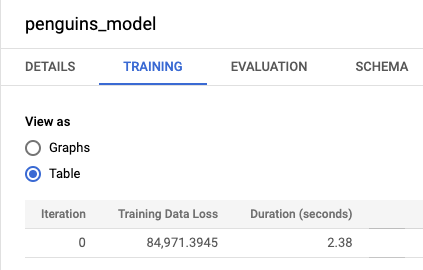
Kolom Training Data Loss menunjukkan metrik kerugian yang dihitung setelah model dilatih menggunakan set data pelatihan. Karena Anda melakukan regresi linear, kolom ini menampilkan nilai rataan kuadrat galat (RKG). Strategi pengoptimalan normal_equation otomatis digunakan untuk pelatihan ini, sehingga hanya satu iterasi yang diperlukan untuk digabungkan ke model akhir. Untuk mengetahui informasi selengkapnya tentang cara menyetel strategi pengoptimalan model, lihat
optimize_strategy.
Mengevaluasi model
Setelah membuat model, evaluasi performa model menggunakan
fungsi ML.EVALUATE atau fungsi BigQuery DataFrames score untuk mengevaluasi nilai prediksi yang dihasilkan oleh model terhadap data sebenarnya.
SQL
Untuk input, fungsi ML.EVALUATE menggunakan model terlatih dan set data yang cocok dengan skema data yang Anda gunakan untuk melatih model. Di lingkungan produksi, Anda harus mengevaluasi model pada data yang berbeda dengan data yang Anda gunakan untuk melatih model.
Jika Anda menjalankan ML.EVALUATE tanpa memberikan data input, fungsi akan mengambil
metrik evaluasi yang dihitung selama pelatihan. Metrik ini dihitung
menggunakan set data evaluasi yang dicadangkan secara otomatis:
SELECT
*
FROM
ML.EVALUATE(MODEL bqml_tutorial.penguins_model);
Jalankan kueri ML.EVALUATE:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, jalankan kueri berikut:
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL));
DataFrame BigQuery
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di Panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Hasilnya akan terlihat seperti berikut:
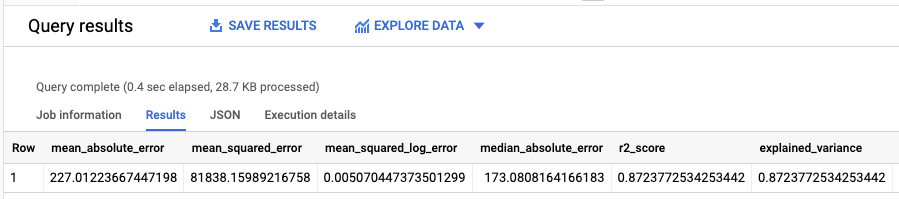
Karena Anda melakukan regresi linear, hasilnya mencakup kolom berikut:
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
Metrik penting dalam hasil evaluasi adalah
skor R2.
Skor R2 adalah ukuran statistik yang menentukan apakah prediksi regresi
linear memperkirakan data sebenarnya. Nilai 0 menunjukkan
bahwa model tidak menjelaskan variabilitas data respons di sekitar
nilai rata-rata. Nilai 1 menunjukkan bahwa model menjelaskan semua variabilitas
data respons di sekitar nilai rata-rata.
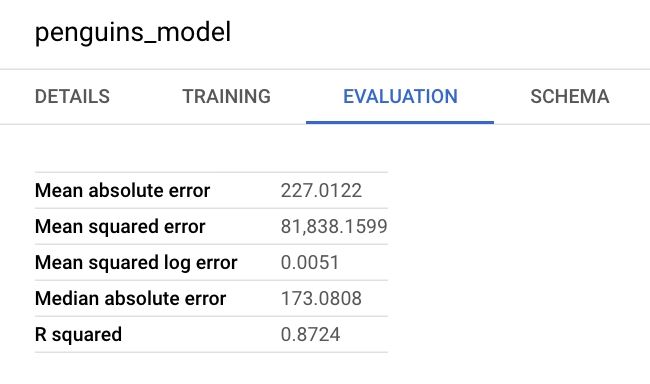
Anda juga dapat melihat panel informasi model di Google Cloud konsol untuk melihat metrik evaluasi:
Menggunakan model untuk memprediksi hasil
Setelah mengevaluasi model, langkah berikutnya adalah menggunakannya untuk memprediksi
hasil. Anda dapat menjalankan
fungsi ML.PREDICT atau fungsi BigQuery DataFrames predict
pada model untuk memprediksi massa tubuh dalam gram semua penguin yang berada di
Kepulauan Biscoe.
SQL
Untuk input, fungsi ML.PREDICT menggunakan model terlatih dan set data yang cocok dengan skema data yang Anda gunakan untuk melatih model, tidak termasuk kolom label.
Jalankan kueri ML.PREDICT:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, jalankan kueri berikut:
SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'));
DataFrame BigQuery
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di Panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Hasilnya akan terlihat seperti berikut:

Menjelaskan hasil prediksi
SQL
Untuk memahami alasan model menghasilkan hasil prediksi ini, Anda dapat menggunakan
fungsi
ML.EXPLAIN_PREDICT.
ML.EXPLAIN_PREDICT adalah versi yang diperluas dari fungsi ML.PREDICT.
ML.EXPLAIN_PREDICT tidak hanya menghasilkan output hasil prediksi, tetapi juga menghasilkan
kolom tambahan untuk menjelaskan hasil prediksi. Dalam praktiknya, Anda dapat menjalankan
ML.EXPLAIN_PREDICT, bukan ML.PREDICT. Untuk mengetahui informasi selengkapnya, lihat Ringkasan Explainable AI BigQuery ML.
Jalankan kueri ML.EXPLAIN_PREDICT:
- Di konsol Google Cloud , buka halaman BigQuery.
- Di editor kueri, jalankan kueri berikut:
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'), STRUCT(3 as top_k_features));
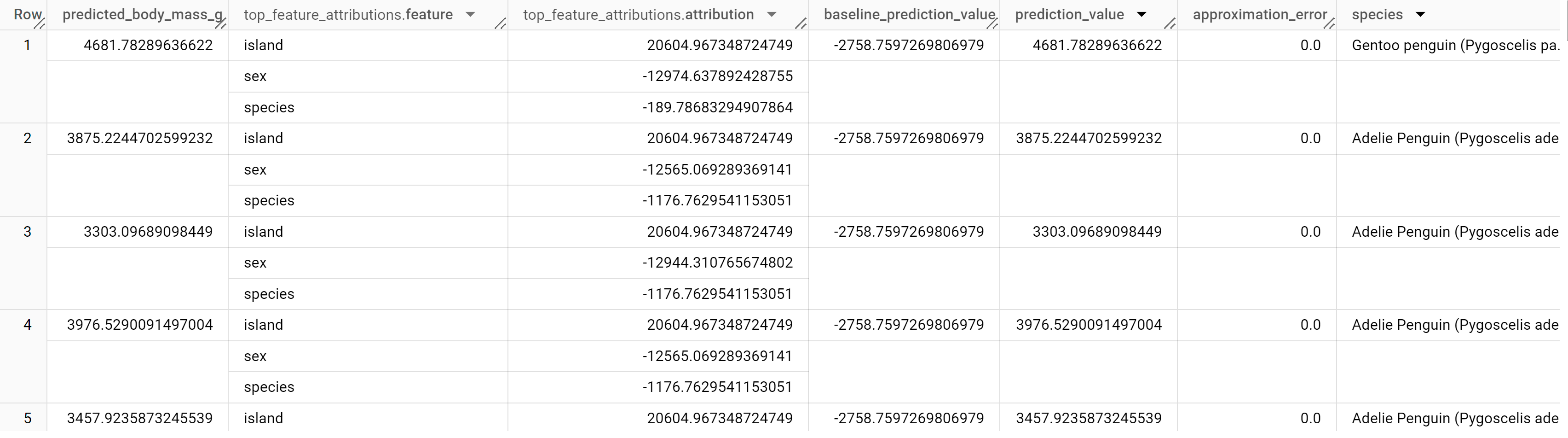
Hasilnya akan terlihat seperti berikut:
DataFrame BigQuery
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di Panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Untuk model regresi linear, nilai Shapley digunakan untuk menghasilkan nilai atribusi fitur untuk setiap fitur dalam model. Output mencakup
tiga atribusi fitur teratas per baris tabel penguins karena
top_k_features ditetapkan ke 3. Atribusi ini diurutkan menurut nilai absolut atribusi dalam urutan menurun. Pada semua contoh, fitur sex berkontribusi paling besar terhadap prediksi keseluruhan.
Menjelaskan model secara global
SQL
Untuk mengetahui fitur mana yang umumnya paling penting untuk menentukan bobot penguin, Anda dapat menggunakan
ML.GLOBAL_EXPLAIN fungsi.
Untuk menggunakan ML.GLOBAL_EXPLAIN, Anda harus melatih ulang model dengan opsi
ENABLE_GLOBAL_EXPLAIN yang disetel ke TRUE.
Latih ulang dan dapatkan penjelasan global untuk model:
- Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, jalankan kueri berikut untuk melatih ulang model:
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS ( model_type = 'linear_reg', input_label_cols = ['body_mass_g'], enable_global_explain = TRUE) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
Di editor kueri, jalankan kueri berikut untuk mendapatkan penjelasan global:
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `bqml_tutorial.penguins_model`)
Hasilnya akan terlihat seperti berikut:
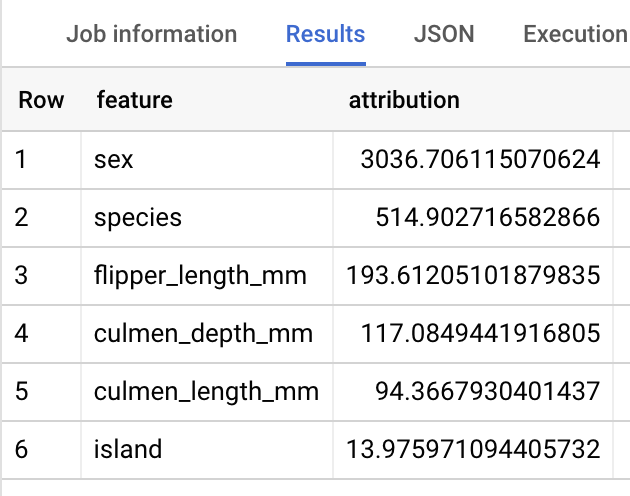
DataFrame BigQuery
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di Panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Pembersihan
Agar akun Google Cloud Anda tidak dikenai biaya untuk resource yang digunakan dalam tutorial ini, hapus project yang berisi resource tersebut, atau simpan project dan hapus resource satu per satu.
- Anda dapat menghapus project yang dibuat.
- Atau, Anda dapat menyimpan project dan menghapus set data.
Menghapus set data
Jika project Anda dihapus, semua set data dan semua tabel dalam project akan dihapus. Jika ingin menggunakan kembali project tersebut, Anda dapat menghapus set data yang dibuat dalam tutorial ini:
Jika perlu, buka halaman BigQuery di konsolGoogle Cloud .
Di navigasi, klik set data bqml_tutorial yang telah Anda buat.
Klik Delete dataset di sisi kanan jendela. Tindakan ini akan menghapus set data, tabel, dan semua data.
Di kotak dialog Delete dataset, konfirmasi perintah hapus dengan mengetikkan nama set data Anda (
bqml_tutorial), lalu klik Delete.
Menghapus project Anda
Untuk menghapus project:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Langkah berikutnya
- Untuk ringkasan BigQuery ML, lihat Pengantar BigQuery ML.
- Untuk informasi tentang cara membuat model, lihat halaman sintaksis
CREATE MODEL.