在本教學課程中,您將使用 BigQuery ML 中的線性迴歸模型,根據企鵝的人口統計資訊預測企鵝的體重。線性迴歸是一種迴歸模型,能夠從輸入特徵的線性組合產出一個連續值。
本教學課程使用 bigquery-public-data.ml_datasets.penguins 資料集。
目標
在本教學課程中,您將執行下列工作:
- 建立線性迴歸模型。
- 評估模型。
- 使用模型進行預測。
費用
本教學課程使用 Google Cloud的計費元件,包括:
- BigQuery
- BigQuery ML
如要進一步瞭解 BigQuery 費用,請參閱 BigQuery 定價頁面。
如要進一步瞭解 BigQuery ML 費用,請參閱 BigQuery ML 定價。
事前準備
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
所需權限
如要使用 BigQuery ML 建立模型,您需要下列 IAM 權限:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
如要執行推論,您需要下列權限:
- 模型上的
bigquery.models.getData bigquery.jobs.create
建立資料集
建立 BigQuery 資料集來儲存機器學習模型。
控制台
前往 Google Cloud 控制台的「BigQuery」頁面。
在「Explorer」窗格中,按一下專案名稱。
依序點按 「View actions」(查看動作) >「Create dataset」(建立資料集)。
在「建立資料集」頁面中,執行下列操作:
在「Dataset ID」(資料集 ID) 中輸入
bqml_tutorial。針對「Location type」(位置類型) 選取「Multi-region」(多區域),然後選取「US (multiple regions in United States)」(us (多個美國區域))。
其餘設定請保留預設狀態,然後按一下「Create dataset」(建立資料集)。
bq
如要建立新的資料集,請使用 bq mk 指令搭配 --location 旗標。如需可能的完整參數清單,請參閱 bq mk --dataset 指令參考資料。
建立名為「
bqml_tutorial」的資料集,並將資料位置設為「US」,以及說明設為「BigQuery ML tutorial dataset」:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
這個指令採用
-d捷徑,而不是使用--dataset旗標。如果您省略-d和--dataset,該指令預設會建立資料集。確認資料集已建立完成:
bq ls
API
請呼叫 datasets.insert 方法,搭配已定義的資料集資源。
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
在嘗試這個範例之前,請按照使用 BigQuery DataFrames 的 BigQuery 快速入門導覽課程中的 BigQuery DataFrames 設定說明操作。 詳情請參閱 BigQuery DataFrames 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定 ADC」。
建立模型
使用 BigQuery 專用的 Analytics 樣本資料集建立線性迴歸模型。
SQL
您可以使用 CREATE MODEL 陳述式建立線性迴歸模型,並指定模型類型為 LINEAR_REG。建立模型包括訓練模型。
以下是 CREATE MODEL 陳述式的重要資訊:
input_label_cols選項會指定SELECT陳述式中的哪個資料欄要當做標籤資料欄。這裡的標籤資料欄是body_mass_g。對線性迴歸模型而言,標籤欄必須為實值,也就是資料欄值必須為實數。這個查詢的
SELECT陳述式會使用bigquery-public-data.ml_datasets.penguins資料表中的下列資料欄,預測企鵝的體重:species:企鵝的物種。island:企鵝居住的島嶼。culmen_length_mm:企鵝的喙長,單位為公釐。culmen_depth_mm:企鵝喙的深度 (以公釐為單位)。flipper_length_mm:企鵝翅膀的長度 (以公釐為單位)。sex:企鵝的性別。
這項查詢的
SELECT陳述式中的WHERE子句WHERE body_mass_g IS NOT NULL會排除body_mass_g欄為NULL的資料列。
執行可建立線性迴歸模型的查詢:
前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中執行下列查詢:
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS (model_type='linear_reg', input_label_cols=['body_mass_g']) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
建立
penguins_model模型大約需要 30 秒。如要查看模型,請前往「Explorer」窗格,展開bqml_tutorial資料集,然後展開「Models」資料夾。
BigQuery DataFrames
在嘗試這個範例之前,請按照使用 BigQuery DataFrames 的 BigQuery 快速入門導覽課程中的 BigQuery DataFrames 設定說明操作。 詳情請參閱 BigQuery DataFrames 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定 ADC」。
建立模型大約需要 30 秒。如要查看模型,請前往「Explorer」窗格,展開 bqml_tutorial 資料集,然後展開「Models」資料夾。
取得訓練統計資料
如要查看模型訓練的結果,請使用 ML.TRAINING_INFO 函式,或是在 Google Cloud 控制台中查看統計資料。在本教學課程中,您會使用 Google Cloud 控制台。
機器學習演算法建構模型時,會檢視大量的例子,藉此找出能將損失降到最低的模型。這個過程稱為經驗風險最小化。
損失是指不良預測造成的負面影響。此數值可顯示模型在單一例子中的預測表現多差。如果這個模型的預測是完美的,則損失為 0,否則損失會大於 0。訓練模型的目的是從所有例子中找到平均損失分數低的一組權重和偏誤。
查看執行 CREATE MODEL 查詢時所產生的模型訓練統計資料:
在「Explorer」窗格中,展開
bqml_tutorial資料集,然後展開「Models」資料夾。按一下「penguins_model」penguins_model,開啟模型資訊窗格。點選「訓練」分頁標籤,然後點選「表格」。結果應如下所示:
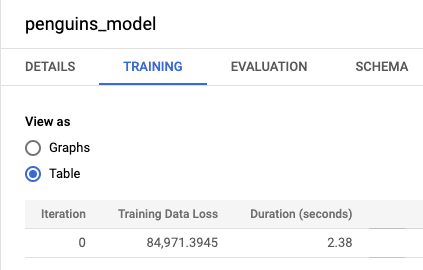
「Training Data Loss」資料欄代表在訓練資料集上訓練模型後計算出來的損失指標。由於您執行了線性迴歸,因此該資料欄會顯示均方誤差值。這項訓練會自動使用normal_equation最佳化策略,因此只需一次疊代,即可收斂至最終模型。如要進一步瞭解如何設定模型最佳化策略,請參閱
optimize_strategy。
評估模型
建立模型後,請使用 ML.EVALUATE 函式或 score BigQuery DataFrames 函式,根據實際資料評估模型產生的預測值,藉此評估模型效能。
SQL
ML.EVALUATE 函式會將訓練好的模型和資料集做為輸入,而資料集必須符合您用來訓練模型的資料結構定義。在正式環境中,您應使用與訓練模型不同的資料評估模型。如果您執行 ML.EVALUATE 時未提供輸入資料,函式會擷取訓練期間計算的評估指標。系統會使用自動保留的評估資料集計算這些指標:
SELECT
*
FROM
ML.EVALUATE(MODEL bqml_tutorial.penguins_model);
執行 ML.EVALUATE 查詢:
前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中執行下列查詢:
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL));
BigQuery DataFrames
在嘗試這個範例之前,請按照使用 BigQuery DataFrames 的 BigQuery 快速入門導覽課程中的 BigQuery DataFrames 設定說明操作。 詳情請參閱 BigQuery DataFrames 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定 ADC」。
結果應如下所示:
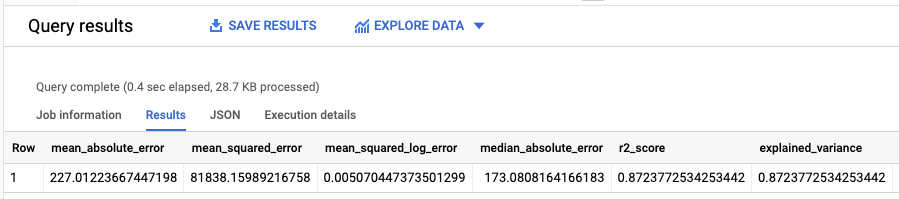
由於您執行了線性迴歸,因此結果包含以下資料欄:
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
評估結果中有個重要的指標,就是 R2 分數。R2 分數是種統計量具,用來確認線性迴歸的預測結果是否趨近於實際資料。0 值表示模型無法解釋平均值周圍之回應資料的變化。1 值代表模型能夠解釋所有平均值周圍之回應資料的所有變化。
您也可以在 Google Cloud 控制台 查看模型資訊窗格,瞭解評估指標:
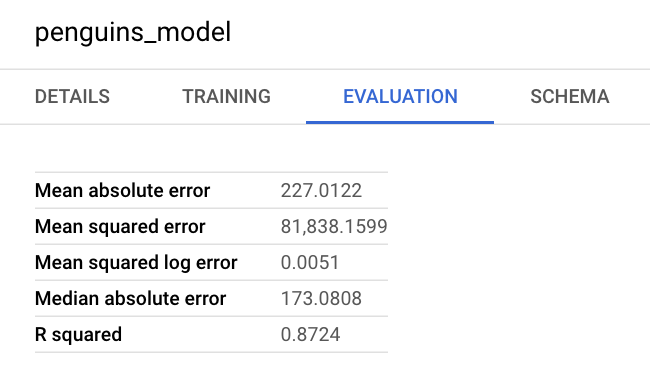
使用模型預測結果
現在您已評估了模型,下一步將要用此模型來預測結果,您可以在模型上執行 ML.PREDICT 函式或 predict BigQuery DataFrames 函式,預測比斯科群島所有企鵝的體重 (以公克為單位)。
SQL
ML.PREDICT 函式會採用已訓練的模型和資料集做為輸入,該資料集必須符合您用於訓練模型的資料結構定義,但標籤資料欄除外。
執行 ML.PREDICT 查詢:
前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中執行下列查詢:
SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'));
BigQuery DataFrames
在嘗試這個範例之前,請按照使用 BigQuery DataFrames 的 BigQuery 快速入門導覽課程中的 BigQuery DataFrames 設定說明操作。 詳情請參閱 BigQuery DataFrames 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定 ADC」。
結果應如下所示:

說明預測結果
SQL
如要瞭解模型產生這些預測結果的原因,可以使用 ML.EXPLAIN_PREDICT 函式。
ML.EXPLAIN_PREDICT 是 ML.PREDICT 函式的擴充版本。
ML.EXPLAIN_PREDICT 不僅會輸出預測結果,也會輸出額外資料欄來解釋預測結果。實務上,您可以執行 ML.EXPLAIN_PREDICT,而非 ML.PREDICT。詳情請參閱 BigQuery ML 可解釋 AI 總覽。
執行 ML.EXPLAIN_PREDICT 查詢:
- 前往 Google Cloud 控制台的「BigQuery」頁面。
- 在查詢編輯器中執行下列查詢:
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'), STRUCT(3 as top_k_features));
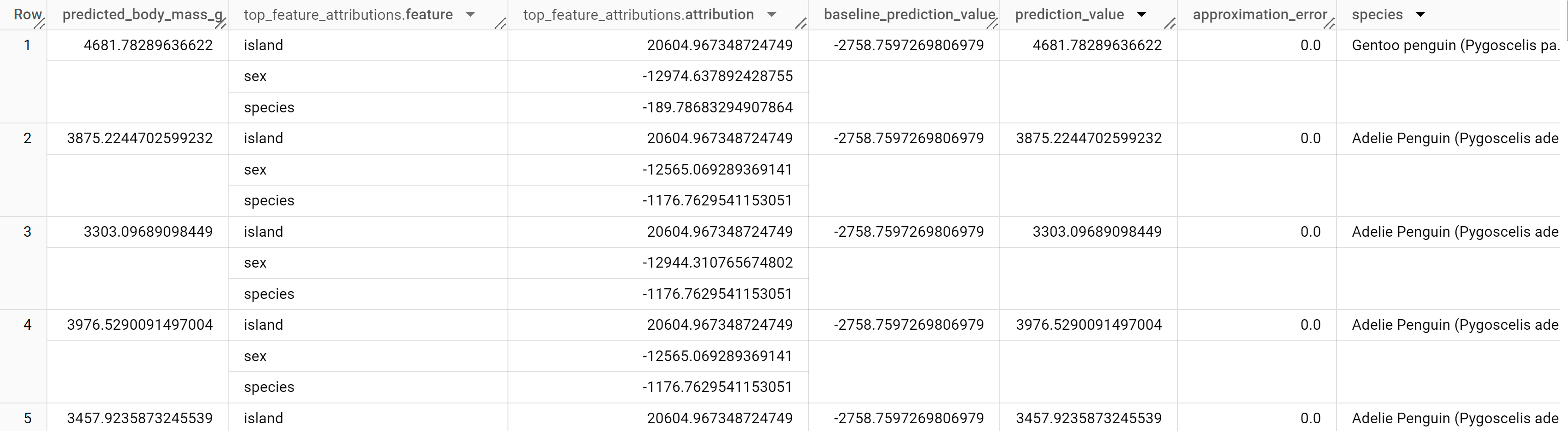
結果應如下所示:
BigQuery DataFrames
在嘗試這個範例之前,請按照使用 BigQuery DataFrames 的 BigQuery 快速入門導覽課程中的 BigQuery DataFrames 設定說明操作。 詳情請參閱 BigQuery DataFrames 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定 ADC」。
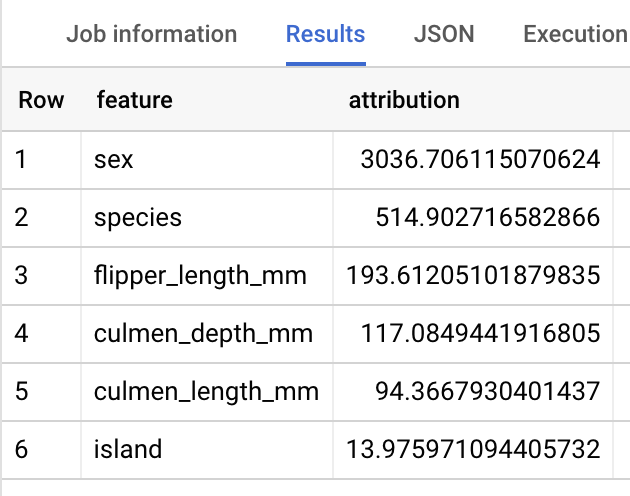
對於線性迴歸模型,系統會使用夏普利值,為模型中的每個特徵產生特徵歸因值。輸出內容會包含 penguins 表格中每列的前三項特徵歸因,因為 top_k_features 已設為 3。這些歸因會依歸因的絕對值遞減排序。在所有範例中,特徵 sex 對整體預測的影響最大。
從全域角度說明模型
SQL
如要瞭解哪些特徵通常最重要,可用於判斷企鵝體重,請使用 ML.GLOBAL_EXPLAIN 函式。如要使用 ML.GLOBAL_EXPLAIN,請務必將 ENABLE_GLOBAL_EXPLAIN 選項設為 TRUE,然後重新訓練模型。
重新訓練模型並取得全域說明:
- 前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中執行下列查詢,重新訓練模型:
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS ( model_type = 'linear_reg', input_label_cols = ['body_mass_g'], enable_global_explain = TRUE) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
在查詢編輯器中執行下列查詢,取得全域說明:
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `bqml_tutorial.penguins_model`)
結果應如下所示:
BigQuery DataFrames
在嘗試這個範例之前,請按照使用 BigQuery DataFrames 的 BigQuery 快速入門導覽課程中的 BigQuery DataFrames 設定說明操作。 詳情請參閱 BigQuery DataFrames 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定 ADC」。
清除所用資源
如要避免系統向您的 Google Cloud 帳戶收取本教學課程中所用資源的相關費用,請刪除含有該項資源的專案,或者保留專案但刪除個別資源。
- 您可以刪除建立的專案。
- 或者您可以保留專案並刪除資料集。
刪除資料集
刪除專案將移除專案中所有的資料集與資料表。若您希望重新使用專案,您可以刪除本教學課程中所建立的資料集。
如有必要,請在Google Cloud 控制台中開啟 BigQuery 頁面。
在導覽窗格中,按一下您建立的 bqml_tutorial 資料集。
按一下視窗右側的「刪除資料集」。 這個動作將會刪除資料集、資料表,以及所有資料。
在「Delete dataset」(刪除資料集) 對話方塊中,輸入資料集的名稱 (
bqml_tutorial),然後按一下 [Delete] (刪除) 來確認刪除指令。
刪除專案
如要刪除專案,請進行以下操作:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
後續步驟
- 如需 BigQuery ML 的總覽,請參閱 BigQuery ML 簡介。
- 如要瞭解如何建立模型,請參閱
CREATE MODEL語法頁面。