Dans ce tutoriel, vous allez utiliser un modèle de régression linéaire dans BigQuery ML pour prédire le poids d'un manchot en fonction de ses données démographiques. Une régression linéaire est un type de modèle de régression qui génère une valeur continue à partir d'une combinaison linéaire de caractéristiques d'entrée.
Ce tutoriel utilise l'ensemble de données bigquery-public-data.ml_datasets.penguins.
Objectifs
Dans ce tutoriel, vous allez effectuer les tâches suivantes :
- Créer un modèle de régression linéaire.
- évaluer le modèle ;
- Effectuer des prédictions à l'aide du modèle.
Coûts
Ce tutoriel utilise des composants facturables de Google Cloud, y compris :
- BigQuery
- BigQuery ML
Pour en savoir plus sur le coût de BigQuery, consultez la page Tarifs de BigQuery.
Pour en savoir plus sur les coûts associés à BigQuery ML, consultez la page Tarifs de BigQuery ML.
Avant de commencer
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Autorisations requises
Pour créer le modèle à l'aide de BigQuery ML, vous devez disposer des autorisations IAM suivantes :
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
Pour exécuter une inférence, vous devez disposer des autorisations suivantes :
bigquery.models.getDatasur le modèlebigquery.jobs.create
Créer un ensemble de données
Créez un ensemble de données BigQuery pour stocker votre modèle de ML.
Console
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le volet Explorateur, cliquez sur le nom de votre projet.
Cliquez sur Afficher les actions > Créer un ensemble de données.
Sur la page Créer un ensemble de données, procédez comme suit :
Dans le champ ID de l'ensemble de données, saisissez
bqml_tutorial.Pour Type d'emplacement, sélectionnez Multirégional, puis sélectionnez US (plusieurs régions aux États-Unis).
Conservez les autres paramètres par défaut, puis cliquez sur Créer un ensemble de données.
bq
Pour créer un ensemble de données, exécutez la commande bq mk en spécifiant l'option --location. Pour obtenir la liste complète des paramètres possibles, consultez la documentation de référence sur la commande bq mk --dataset.
Créez un ensemble de données nommé
bqml_tutorialavec l'emplacement des données défini surUSet une description deBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Au lieu d'utiliser l'option
--dataset, la commande utilise le raccourci-d. Si vous omettez-det--dataset, la commande crée un ensemble de données par défaut.Vérifiez que l'ensemble de données a été créé :
bq ls
API
Appelez la méthode datasets.insert avec une ressource d'ensemble de données définie.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer les ADC pour un environnement de développement local.
Créer le modèle
Créez un modèle de régression linéaire à l'aide de l'exemple d'ensemble de données Analytics pour BigQuery.
SQL
Pour créer un modèle de régression linéaire, utilisez l'instruction CREATE MODEL et spécifiez LINEAR_REG pour le type de modèle. La création du modèle comprend l'entraînement du modèle.
Voici quelques points utiles à connaître concernant l'instruction CREATE MODEL :
- L'option
input_label_colsspécifie la colonne de l'instructionSELECTà utiliser comme colonne d'étiquette. Ici, la colonne d'étiquette estbody_mass_g. Pour les modèles de régression linéaire, la colonne d'étiquette doit être renseignée avec des valeurs réelles (les valeurs de colonne doivent être des nombres réels). L'instruction
SELECTde cette requête utilise les colonnes suivantes de la tablebigquery-public-data.ml_datasets.penguinspour prédire le poids d'un manchot :species: espèces de manchots.island: île sur laquelle vit le manchot.culmen_length_mm: longueur du culmen du manchot en millimètres.culmen_depth_mm: profondeur du culmen du manchot en millimètres.flipper_length_mm: longueur des nageoires du manchot en millimètres.sex: sexe du manchot.
La clause
WHEREde l'instructionSELECTde cette requête,WHERE body_mass_g IS NOT NULL, exclut les lignes dont la colonnebody_mass_gcontientNULL.
Exécutez la requête permettant de créer le modèle de régression linéaire :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez la requête suivante :
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS (model_type='linear_reg', input_label_cols=['body_mass_g']) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
La création du modèle
penguins_modelprend environ 30 secondes. Pour afficher le modèle, accédez au volet Explorateur, développez l'ensemble de donnéesbqml_tutorial, puis le dossier Modèles.
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer les ADC pour un environnement de développement local.
La création du modèle prend environ 30 secondes. Pour afficher le modèle, accédez au volet Explorateur, développez l'ensemble de données bqml_tutorial, puis le dossier Modèles.
Obtenir des statistiques d'entraînement
Pour afficher les résultats de l'entraînement du modèle, vous pouvez utiliser la fonction ML.TRAINING_INFO ou afficher les statistiques dans la console Google Cloud . Dans ce tutoriel, vous allez utiliser la console Google Cloud .
Pour créer un modèle, un algorithme de machine learning examine de nombreux exemples et essaie de trouver un modèle qui minimise la perte. Ce processus est appelé "minimisation du risque empirique".
La perte est la pénalité liée à une mauvaise prédiction, exprimée sous la forme d'un nombre qui indique à quel point la prédiction du modèle est fausse pour un exemple donné. Si la prédiction du modèle est parfaite, la perte est nulle. Sinon, la perte est supérieure à zéro. L'objectif de l'entraînement d'un modèle est de trouver un ensemble de pondérations et de biais présentant une faible perte pour tous les exemples (en moyenne).
Pour afficher les statistiques d'entraînement du modèle qui ont été générées lors de l'exécution de la requête CREATE MODEL, procédez comme suit :
Dans le volet Explorateur, développez l'ensemble de données
bqml_tutorial, puis le dossier Modèles. Cliquez sur penguins_model pour ouvrir le volet d'informations du modèle.Cliquez sur l'onglet Entraînement, puis sur Table. Le résultat doit ressembler à ce qui suit :
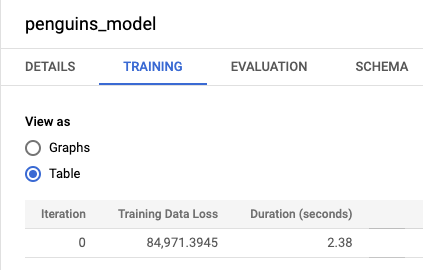
La colonne Training Data Loss (Perte de données d'entraînement) représente la métrique de perte calculée après entraînement du modèle dans l'ensemble de données d'entraînement. Étant donné que vous avez effectué une régression linéaire, cette colonne affiche la valeur de l'erreur quadratique moyenne. Une stratégie d'optimisation normal_equation est automatiquement utilisée pour cet entraînement. Une seule itération suffit donc pour converger vers le modèle final. Pour en savoir plus sur la définition de la stratégie d'optimisation des modèles, consultez la page
optimize_strategy.
Évaluer le modèle
Après avoir créé le modèle, évaluez ses performances à l'aide de la fonction ML.EVALUATE ou de la fonction BigQuery DataFrames score pour comparer les valeurs prédites générées par le modèle aux données réelles.
SQL
En entrée, la fonction ML.EVALUATE utilise le modèle entraîné et un ensemble de données correspondant au schéma des données que vous avez utilisé pour entraîner le modèle. Dans un environnement de production, vous devez évaluer le modèle sur des données différentes de celles que vous avez utilisées pour l'entraîner.
Si vous exécutez ML.EVALUATE sans fournir de données d'entrée, la fonction récupère les métriques d'évaluation calculées pendant l'entraînement. Ces métriques sont calculées à l'aide de l'ensemble de données d'évaluation réservé automatiquement :
SELECT
*
FROM
ML.EVALUATE(MODEL bqml_tutorial.penguins_model);
Exécutez la requête ML.EVALUATE :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez la requête suivante :
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL));
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer les ADC pour un environnement de développement local.
Le résultat doit ressembler à ce qui suit :
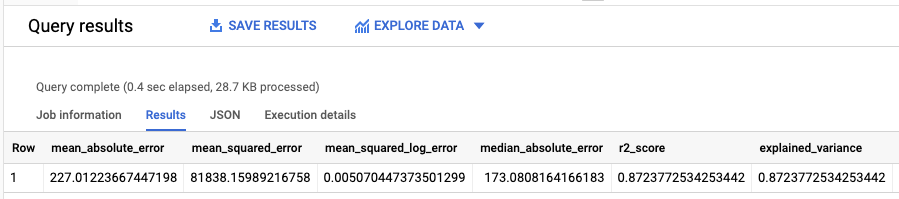
Étant donné que vous avez effectué une régression linéaire, les résultats incluent les colonnes suivantes :
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
Le score R2 est une métrique importante dans les résultats de l'évaluation.
Le score R2 est une mesure statistique qui détermine si les prédictions de la régression linéaire se rapprochent des données réelles. Une valeur 0 indique que le modèle n'apporte aucune explication sur la variabilité des données de réponse autour de la moyenne. Une valeur 1 indique que le modèle explique toute la variabilité des données de réponse autour de la moyenne.
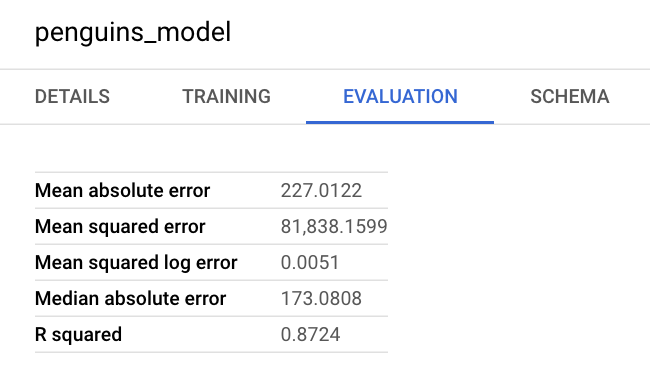
Vous pouvez également consulter le volet d'informations du modèle dans la console Google Cloud pour afficher les métriques d'évaluation :
Utiliser le modèle pour prédire les résultats
Maintenant que vous avez évalué le modèle, l'étape suivante consiste à vous en servir pour prédire un résultat. Vous pouvez exécuter la fonction ML.PREDICT ou la fonction DataFrames BigQuery predict sur le modèle pour prédire la masse corporelle en grammes de tous les manchots vivant sur les îles Biscoe.
SQL
En entrée, la fonction ML.PREDICT prend le modèle entraîné et un ensemble de données correspondant au schéma de données que vous avez utilisé pour entraîner le modèle, à l'exclusion de la colonne d'étiquette.
Exécutez la requête ML.PREDICT :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez la requête suivante :
SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'));
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer les ADC pour un environnement de développement local.
Le résultat doit ressembler à ce qui suit :

Expliquer les résultats des prédictions
SQL
Pour comprendre pourquoi votre modèle génère ces résultats de prédiction, vous pouvez utiliser la fonction ML.EXPLAIN_PREDICT.
ML.EXPLAIN_PREDICT est une version étendue de la fonction ML.PREDICT.
La fonction ML.EXPLAIN_PREDICT génère non seulement des résultats de prédiction, mais elle produit également des colonnes supplémentaires servant à expliquer ces résultats. En pratique, vous pouvez exécuter ML.EXPLAIN_PREDICT au lieu de ML.PREDICT. Pour en savoir plus, consultez la présentation d'Explainable AI dans BigQuery ML.
Exécutez la requête ML.EXPLAIN_PREDICT :
- Dans la console Google Cloud , accédez à la page BigQuery.
- Dans l'éditeur de requête, saisissez la requête suivante :
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'), STRUCT(3 as top_k_features));
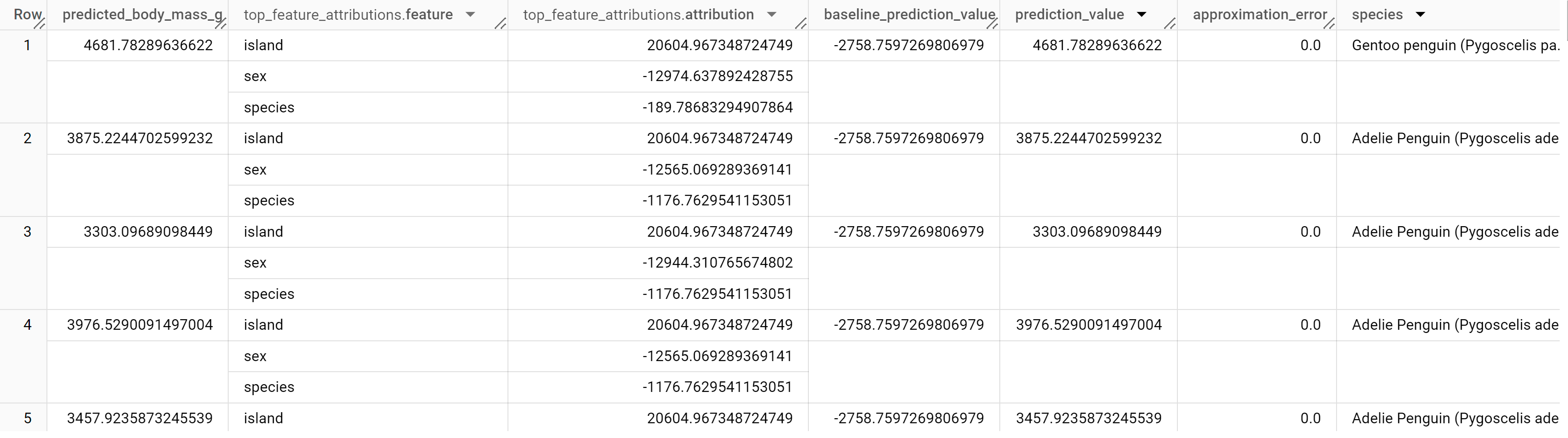
Le résultat doit ressembler à ce qui suit :
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer les ADC pour un environnement de développement local.
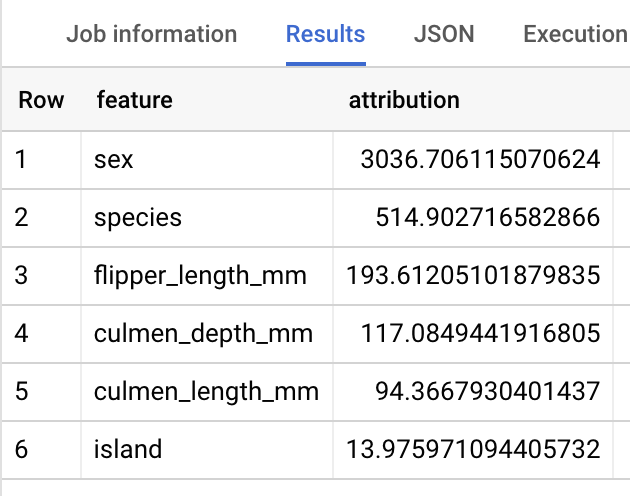
Pour les modèles de régression linéaire, les valeurs de Shapley sont utilisées pour générer les valeurs d'attribution des caractéristiques pour chaque caractéristique du modèle. Le résultat inclut les trois premières attributions de caractéristiques par ligne de la table penguins, car top_k_features a été défini sur 3. Ces attributions sont triées en fonction de la valeur absolue de l'attribution par ordre décroissant. Dans tous les exemples, la caractéristique sex a le plus contribué à la prédiction globale.
Expliquer globalement le modèle
SQL
Afin d'identifier les caractéristiques les plus importantes pour déterminer le poids des manchots en général, vous pouvez utiliser la fonction ML.GLOBAL_EXPLAIN.
Pour utiliser ML.GLOBAL_EXPLAIN, vous devez réentraîner le modèle avec l'option ENABLE_GLOBAL_EXPLAIN définie sur TRUE.
Ré-entraînez le modèle et obtenez des explications globales :
- Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, exécutez la requête suivante pour réentraîner le modèle :
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS ( model_type = 'linear_reg', input_label_cols = ['body_mass_g'], enable_global_explain = TRUE) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
Dans l'éditeur de requête, exécutez la requête suivante pour obtenir des explications globales :
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `bqml_tutorial.penguins_model`)
Le résultat doit ressembler à ce qui suit :
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer les ADC pour un environnement de développement local.
Effectuer un nettoyage
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
- Supprimez le projet que vous avez créé.
- Ou conservez le projet et supprimez l'ensemble de données.
Supprimer l'ensemble de données
Si vous supprimez votre projet, tous les ensembles de données et toutes les tables qui lui sont associés sont également supprimés. Si vous préférez réutiliser le projet, vous pouvez supprimer l'ensemble de données que vous avez créé dans ce tutoriel :
Si nécessaire, ouvrez la page BigQuery dans la consoleGoogle Cloud .
Dans le panneau de navigation, cliquez sur l'ensemble de données bqml_tutorial que vous avez créé.
Cliquez sur Delete dataset (Supprimer l'ensemble de données) dans la partie droite de la fenêtre. Cette action supprime l'ensemble de données, la table et toutes les données.
Dans la boîte de dialogue Supprimer l'ensemble de données, confirmez la commande de suppression en saisissant le nom de votre ensemble de données (
bqml_tutorial), puis cliquez sur Supprimer.
Supprimer votre projet
Pour supprimer le projet :
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Étapes suivantes
- Pour obtenir plus d'informations sur BigQuery ML, consultez la page Présentation de BigQuery ML.
- Pour plus d'informations sur la création de modèles, consultez la page sur la syntaxe de
CREATE MODEL.