Tabelle BigLake per Apache Iceberg in BigQuery
Le tabelle BigLake per Apache Iceberg in BigQuery (di seguito, tabelle BigLake Iceberg in BigQuery) forniscono le basi per la creazione di lakehouse in formato aperto su Google Cloud. Le tabelle BigLake Iceberg in BigQuery offrono la stessa esperienza completamente gestita delle tabelle BigQuery standard, ma archiviano i dati in bucket di archiviazione di proprietà del cliente. Le tabelle BigLake Iceberg in BigQuery supportano il formato delle tabelle Iceberg open per una migliore interoperabilità con motori di calcolo open source e di terze parti su una singola copia dei dati.
Le tabelle BigLake per Apache Iceberg in BigQuery sono diverse dalle tabelle esterne Apache Iceberg. Le tabelle BigLake per Apache Iceberg in BigQuery sono tabelle completamente gestite e modificabili direttamente in BigQuery, mentre le tabelle esterne Apache Iceberg sono gestite dal cliente e offrono l'accesso in sola lettura da BigQuery.
Le tabelle BigLake Iceberg in BigQuery supportano le seguenti funzionalità:
- Mutazioni delle tabelle utilizzando data manipulation language (DML) GoogleSQL.
- Streaming unificato in batch e ad alta velocità effettiva utilizzando l'API Storage Write tramite i connettori BigLake come Spark, Dataflow e altri motori.
- Esportazione di snapshot Iceberg V2 e aggiornamento automatico a ogni mutazione della tabella per l'accesso diretto alle query con motori di query open source e di terze parti.
- Evoluzione dello schema, che consente di aggiungere, eliminare e rinominare le colonne in base alle tue esigenze. Questa funzionalità ti consente anche di modificare il tipo di dati di una colonna esistente e la modalità colonna. Per ulteriori informazioni, consulta le regole di conversione dei tipi.
- Ottimizzazione automatica dell'archiviazione, tra cui dimensionamento adattivo dei file, clustering automatico, garbage collection e ottimizzazione dei metadati.
- Time travel per l'accesso ai dati storici in BigQuery.
- Sicurezza a livello di colonna e mascheramento dei dati.
- Transazioni con più istruzioni (in anteprima).
Architettura
Le tabelle BigLake Iceberg in BigQuery offrono la comodità della gestione delle risorse BigQuery alle tabelle che si trovano nei tuoi bucket cloud. Puoi utilizzare BigQuery e motori di calcolo open source su queste tabelle senza spostare i dati dai bucket che controlli. Prima di iniziare a utilizzare le tabelle BigLake Iceberg in BigQuery, devi configurare un bucket Cloud Storage.
Le tabelle BigLake Iceberg in BigQuery utilizzano BigLake Metastore come metastore di runtime unificato per tutti i dati Iceberg. BigLake Metastore fornisce un'unica fonte di riferimento per la gestione dei metadati di più motori e consente l'interoperabilità dei motori.
Il seguente diagramma mostra l'architettura della tabella gestita a livello generale:
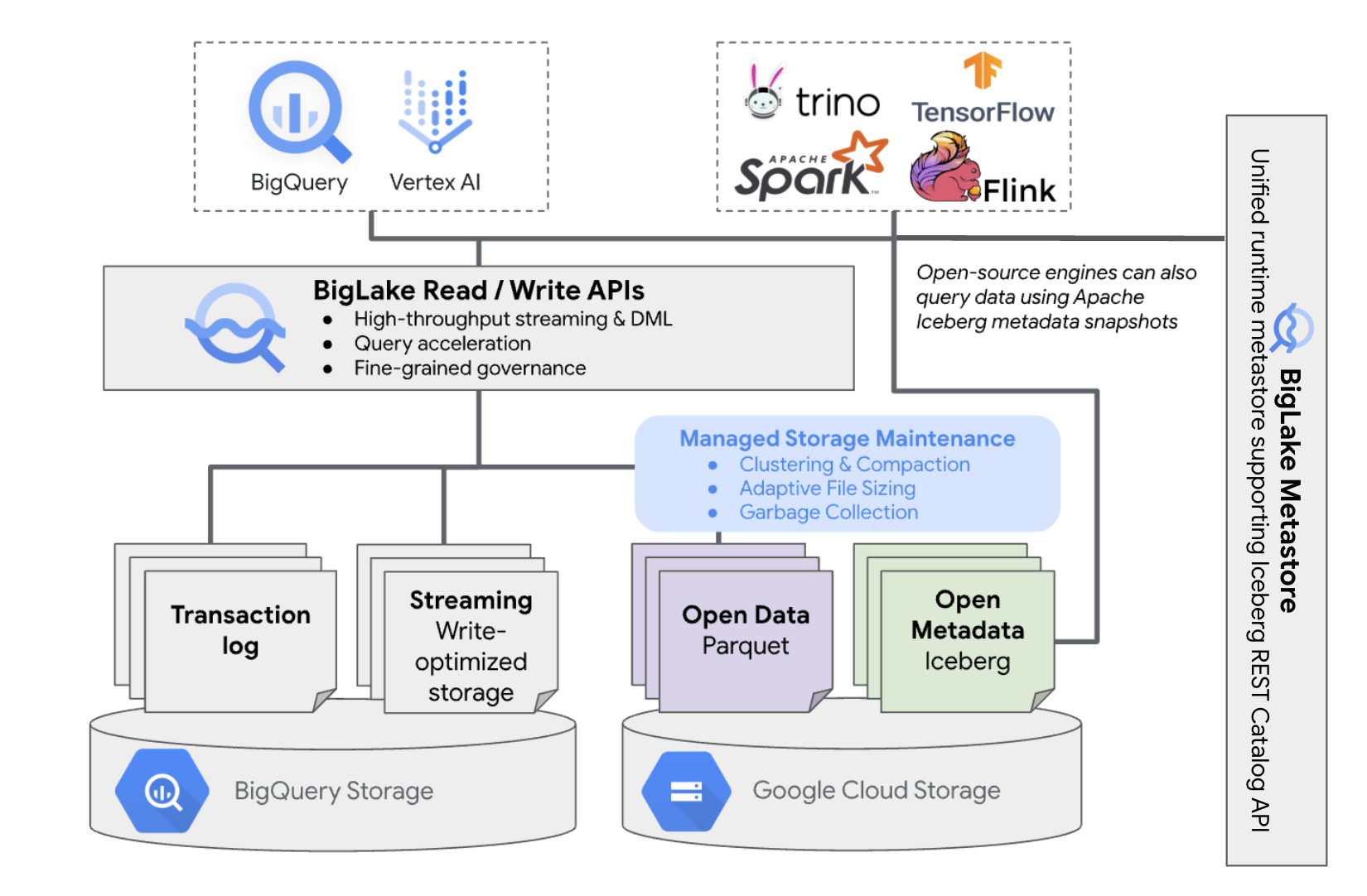
Questa gestione delle tabelle ha le seguenti implicazioni per il tuo bucket:
- BigQuery crea nuovi file di dati nel bucket in risposta a richieste di scrittura e ottimizzazioni dell'archiviazione in background, ad esempio istruzioni DML e streaming.
- Quando elimini una tabella gestita in BigQuery, BigQuery esegue la garbage collection dei file di dati associati in Cloud Storage dopo la scadenza del periodo di time travel.
La creazione di una tabella BigLake Iceberg in BigQuery è simile alla creazione di tabelle BigQuery. Poiché archivia i dati in formati aperti su Cloud Storage, devi eseguire le seguenti operazioni:
- Specifica la
connessione risorsa cloud
con
WITH CONNECTIONper configurare le credenziali di connessione per BigLake per accedere a Cloud Storage. - Specifica il formato file dell'archiviazione dei dati come
PARQUETcon l'istruzionefile_format = PARQUET. - Specifica il formato della tabella dei metadati open source come
ICEBERGcon l'istruzionetable_format = ICEBERG.
Best practice
La modifica o l'aggiunta diretta di file al bucket al di fuori di BigQuery può comportare la perdita di dati o errori non recuperabili. La tabella seguente descrive i possibili scenari:
| Operazione | Conseguenze | Prevenzione |
|---|---|---|
| Aggiungi nuovi file al bucket al di fuori di BigQuery. | Perdita di dati:i nuovi file o oggetti aggiunti al di fuori di BigQuery non vengono monitorati da BigQuery. I file non monitorati vengono eliminati dai processi di garbage collection in background. | Aggiungi dati esclusivamente tramite BigQuery. In questo modo BigQuery può tenere traccia dei file ed evitare che vengano sottoposti a garbage collection. Per evitare aggiunte accidentali e perdita di dati, ti consigliamo anche di limitare le autorizzazioni di scrittura degli strumenti esterni sui bucket contenenti tabelle BigLake Iceberg in BigQuery. |
| Crea una nuova tabella BigLake Iceberg in BigQuery in un prefisso non vuoto. | Perdita di dati:i dati esistenti non vengono monitorati da BigQuery, quindi questi file vengono considerati non monitorati ed eliminati dai processi di Garbage Collection in background. | Crea nuove tabelle BigLake Iceberg in BigQuery solo in prefissi vuoti. |
| Modifica o sostituisci la tabella BigLake Iceberg nei file di dati BigQuery. | Perdita di dati:in caso di modifica o sostituzione esterna,
la tabella non supera un controllo di coerenza e diventa illeggibile. Le query
sulla tabella non vanno a buon fine. Non esiste un modo self-service per eseguire il recupero da questo punto. Contatta l'assistenza per ricevere aiuto con il recupero dei dati. |
Modifica i dati esclusivamente tramite BigQuery. In questo modo BigQuery può tenere traccia dei file ed evitare che vengano sottoposti a garbage collection. Per evitare aggiunte accidentali e perdita di dati, ti consigliamo anche di limitare le autorizzazioni di scrittura degli strumenti esterni sui bucket contenenti tabelle BigLake Iceberg in BigQuery. |
| Crea due tabelle BigLake Iceberg in BigQuery sugli stessi URI o su URI sovrapposti. | Perdita di dati:BigQuery non collega istanze URI identiche di tabelle BigLake Iceberg in BigQuery. I processi di garbage collection in background per ogni tabella considereranno i file della tabella opposta come non monitorati ed elimineranno, causando la perdita di dati. | Utilizza URI univoci per ogni tabella BigLake Iceberg in BigQuery. |
Best practice per la configurazione dei bucket Cloud Storage
La configurazione del bucket Cloud Storage e la sua connessione a BigLake influiscono direttamente su prestazioni, costi, integrità, sicurezza e governance delle tabelle BigLake Iceberg in BigQuery. Di seguito sono riportate le best practice per facilitare questa configurazione:
Seleziona un nome che indichi chiaramente che il bucket è destinato solo alle tabelle BigLake Iceberg in BigQuery.
Scegli bucket Cloud Storage monoregionali che si trovano nella stessa regione del tuo dataset BigQuery. Questo coordinamento migliora le prestazioni e riduce i costi evitando le tariffe per il trasferimento di dati.
Per impostazione predefinita, Cloud Storage archivia i dati nella classe di archiviazione Standard, che offre prestazioni sufficienti. Per ottimizzare i costi di archiviazione dei dati, puoi attivare Autoclass per gestire automaticamente le transizioni delle classi di archiviazione. Autoclass inizia con la classe di archiviazione Standard e sposta gli oggetti a cui non si accede in classi progressivamente più fredde per ridurre i costi di archiviazione. Quando l'oggetto viene letto di nuovo, viene spostato di nuovo nella classe Standard.
Attiva l'accesso uniforme a livello di bucket e la prevenzione dell'accesso pubblico.
Verifica che i ruoli richiesti siano assegnati agli utenti e ai service account corretti.
Per evitare l'eliminazione o il danneggiamento accidentale dei dati Iceberg nel bucket Cloud Storage, limita le autorizzazioni di scrittura ed eliminazione per la maggior parte degli utenti della tua organizzazione. Puoi farlo impostando un criterio di autorizzazione bucket con condizioni che negano le richieste
PUTeDELETEper tutti gli utenti, tranne quelli che specifichi.Applica chiavi di crittografia gestite da Google o gestite dal cliente per una maggiore protezione dei dati sensibili.
Abilita l'audit logging per la trasparenza operativa, la risoluzione dei problemi e il monitoraggio dell'accesso ai dati.
Mantieni il criterio di eliminazione temporanea predefinito (conservazione di 7 giorni) per proteggerti da eliminazioni accidentali. Tuttavia, se noti che i dati Iceberg sono stati eliminati, contatta l'assistenza anziché ripristinare manualmente gli oggetti, poiché gli oggetti aggiunti o modificati al di fuori di BigQuery non vengono monitorati dai metadati BigQuery.
Il dimensionamento adattivo dei file, il clustering automatico e la garbage collection sono abilitati automaticamente e contribuiscono a ottimizzare le prestazioni e i costi dei file.
Evita le seguenti funzionalità di Cloud Storage, in quanto non sono supportate per le tabelle BigLake Iceberg in BigQuery:
- Spazi dei nomi gerarchici
- Due regioni e più regioni
- Elenchi di controllo dell'accesso (ACL) agli oggetti
- Chiavi di crittografia fornite dal cliente
- Controllo delle versioni degli oggetti
- Blocco oggetto
- Blocco di bucket
- Ripristino di oggetti eliminati temporaneamente con l'API BigQuery o lo strumento a riga di comando bq
Puoi implementare queste best practice creando il bucket con il seguente comando:
gcloud storage buckets create gs://BUCKET_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --enable-autoclass \ --public-access-prevention \ --uniform-bucket-level-access
Sostituisci quanto segue:
BUCKET_NAME: il nome del nuovo bucketPROJECT_ID: l'ID del progettoLOCATION: la posizione del nuovo bucket
Tabella BigLake Iceberg nei workflow BigQuery
Le sezioni seguenti descrivono come creare, caricare, gestire ed eseguire query sulle tabelle gestite.
Prima di iniziare
Prima di creare e utilizzare le tabelle BigLake Iceberg in BigQuery, assicurati di aver configurato una connessione a una risorsa cloud a un bucket di archiviazione. La connessione deve disporre delle autorizzazioni di scrittura sul bucket di archiviazione, come specificato nella seguente sezione Ruoli richiesti. Per ulteriori informazioni sui ruoli e sulle autorizzazioni richiesti per le connessioni, consulta Gestire le connessioni.
Ruoli obbligatori
Per ottenere le autorizzazioni necessarie per consentire a BigQuery di gestire le tabelle nel tuo progetto, chiedi all'amministratore di concederti i seguenti ruoli IAM:
-
Per creare tabelle BigLake Iceberg in BigQuery:
-
BigQuery Data Owner (
roles/bigquery.dataOwner) sul tuo progetto -
Amministratore connessione BigQuery (
roles/bigquery.connectionAdmin) sul tuo progetto
-
BigQuery Data Owner (
-
Per eseguire query sulle tabelle BigLake Iceberg in BigQuery:
-
Visualizzatore dati BigQuery (
roles/bigquery.dataViewer) sul tuo progetto -
Utente BigQuery (
roles/bigquery.user) sul tuo progetto
-
Visualizzatore dati BigQuery (
-
Concedi al account di servizio di connessione i seguenti ruoli in modo che possa leggere e scrivere dati in Cloud Storage:
-
Storage Object User (
roles/storage.objectUser) sul bucket -
Storage Legacy Bucket Reader (
roles/storage.legacyBucketReader) sul bucket
-
Storage Object User (
Per ulteriori informazioni sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.
Questi ruoli predefiniti contengono le autorizzazioni necessarie per consentire a BigQuery di gestire le tabelle nel tuo progetto. Per vedere quali sono esattamente le autorizzazioni richieste, espandi la sezione Autorizzazioni obbligatorie:
Autorizzazioni obbligatorie
Per consentire a BigQuery di gestire le tabelle nel tuo progetto sono necessarie le seguenti autorizzazioni:
-
bigquery.connections.delegatesul tuo progetto -
bigquery.jobs.createsul tuo progetto -
bigquery.readsessions.createsul tuo progetto -
bigquery.tables.createsul tuo progetto -
bigquery.tables.getsul tuo progetto -
bigquery.tables.getDatasul tuo progetto -
storage.buckets.getsul tuo bucket -
storage.objects.createsul tuo bucket -
storage.objects.deletesul tuo bucket -
storage.objects.getsul tuo bucket -
storage.objects.listsul tuo bucket
Potresti anche ottenere queste autorizzazioni con ruoli personalizzati o altri ruoli predefiniti.
Crea tabelle BigLake Iceberg in BigQuery
Per creare una tabella BigLake Iceberg in BigQuery, seleziona uno dei seguenti metodi:
SQL
CREATE TABLE [PROJECT_ID.]DATASET_ID.TABLE_NAME ( COLUMN DATA_TYPE[, ...] ) CLUSTER BY CLUSTER_COLUMN_LIST WITH CONNECTION {CONNECTION_NAME | DEFAULT} OPTIONS ( file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'STORAGE_URI');
Sostituisci quanto segue:
- PROJECT_ID: il progetto contenente il set di dati. Se non è definito, il comando presuppone il progetto predefinito.
- DATASET_ID: un set di dati esistente.
- TABLE_NAME: il nome della tabella che stai creando.
- DATA_TYPE: il tipo di dati delle informazioni contenute nella colonna.
- CLUSTER_COLUMN_LIST: un elenco separato da virgole contenente fino a quattro colonne. Devono essere colonne di primo livello non ripetute.
CONNECTION_NAME: il nome della connessione. Ad esempio,
myproject.us.myconnection.Per utilizzare una connessione predefinita, specifica
DEFAULTanziché la stringa di connessione contenente PROJECT_ID.REGION.CONNECTION_ID.STORAGE_URI: un URI Cloud Storage completo. Ad esempio:
gs://mybucket/table.
bq
bq --project_id=PROJECT_ID mk \ --table \ --file_format=PARQUET \ --table_format=ICEBERG \ --connection_id=CONNECTION_NAME \ --storage_uri=STORAGE_URI \ --schema=COLUMN_NAME:DATA_TYPE[, ...] \ --clustering_fields=CLUSTER_COLUMN_LIST \ DATASET_ID.MANAGED_TABLE_NAME
Sostituisci quanto segue:
- PROJECT_ID: il progetto contenente il set di dati. Se non è definito, il comando presuppone il progetto predefinito.
- CONNECTION_NAME: il nome della connessione. Ad esempio,
myproject.us.myconnection. - STORAGE_URI: un URI Cloud Storage completo.
Ad esempio:
gs://mybucket/table. - COLUMN_NAME: il nome della colonna.
- DATA_TYPE: il tipo di dati delle informazioni contenute nella colonna.
- CLUSTER_COLUMN_LIST: un elenco separato da virgole contenente fino a quattro colonne. Devono essere colonne di primo livello non ripetute.
- DATASET_ID: l'ID di un set di dati esistente.
- MANAGED_TABLE_NAME: il nome della tabella che stai creando.
API
Chiama il metodo
tables.insert'
con una risorsa tabella definita, simile alla seguente:
{ "tableReference": { "tableId": "TABLE_NAME" }, "biglakeConfiguration": { "connectionId": "CONNECTION_NAME", "fileFormat": "PARQUET", "tableFormat": "ICEBERG", "storageUri": "STORAGE_URI" }, "schema": { "fields": [ { "name": "COLUMN_NAME", "type": "DATA_TYPE" } [, ...] ] } }
Sostituisci quanto segue:
- TABLE_NAME: il nome della tabella che stai creando.
- CONNECTION_NAME: il nome della connessione. Ad esempio,
myproject.us.myconnection. - STORAGE_URI: un URI Cloud Storage completo.
Sono supportati anche i caratteri jolly. Ad esempio
gs://mybucket/table. - COLUMN_NAME: il nome della colonna.
- DATA_TYPE: il tipo di dati delle informazioni contenute nella colonna.
Importare i dati nelle tabelle BigLake Iceberg in BigQuery
Le seguenti sezioni descrivono come importare i dati da vari formati di tabella nelle tabelle BigLake Iceberg in BigQuery.
Carica i dati standard dai flat file
Le tabelle BigLake Iceberg in BigQuery utilizzano i job di caricamento BigQuery per caricare file esterni nelle tabelle BigLake Iceberg in BigQuery. Se hai una tabella BigLake Iceberg esistente in BigQuery, segui la guida della CLI bq load o la guida SQL LOAD per caricare i dati esterni. Dopo il caricamento dei dati, vengono scritti nuovi file Parquet
nella cartella STORAGE_URI/data.
Se le istruzioni precedenti vengono utilizzate senza una tabella BigLake Iceberg esistente in BigQuery, viene creata una tabella BigQuery.
Per esempi specifici dello strumento di caricamenti batch nelle tabelle gestite, consulta quanto segue:
SQL
LOAD DATA INTO MANAGED_TABLE_NAME FROM FILES ( uris=['STORAGE_URI'], format='FILE_FORMAT');
Sostituisci quanto segue:
- MANAGED_TABLE_NAME: il nome di una tabella BigLake Iceberg esistente in BigQuery.
- STORAGE_URI: un URI Cloud Storage completo o un elenco di URI separati da virgole.
Sono supportati anche i caratteri jolly. Ad esempio
gs://mybucket/table. - FILE_FORMAT: il formato della tabella di origine. Per i formati supportati, consulta la riga
formatdiload_option_list.
bq
bq load \ --source_format=FILE_FORMAT \ MANAGED_TABLE \ STORAGE_URI
Sostituisci quanto segue:
- FILE_FORMAT: il formato della tabella di origine. Per i formati supportati, consulta la riga
formatdiload_option_list. - MANAGED_TABLE_NAME: il nome di una tabella BigLake Iceberg esistente in BigQuery.
- STORAGE_URI: un URI Cloud Storage completo o un elenco di URI separati da virgole.
Sono supportati anche i caratteri jolly. Ad esempio
gs://mybucket/table.
Caricamento standard da file partizionati in Hive
Puoi caricare file partizionati Hive nelle tabelle BigLake Iceberg in BigQuery utilizzando i job di caricamento BigQuery standard. Per ulteriori informazioni, consulta la pagina relativa al caricamento di dati partizionati esternamente.
Carica i flussi di dati da Pub/Sub
Puoi caricare i dati di streaming nelle tabelle BigLake Iceberg in BigQuery utilizzando una sottoscrizione Pub/Sub BigQuery.
Esportare i dati dalle tabelle BigLake Iceberg in BigQuery
Le sezioni seguenti descrivono come esportare i dati dalle tabelle BigLake Iceberg in BigQuery in vari formati di tabella.
Esportare i dati in formati flat
Per esportare una tabella BigLake Iceberg in BigQuery in un formato piatto, utilizza l'istruzione
EXPORT DATA
e seleziona un formato di destinazione. Per saperne di più, consulta Esportazione di dati.
Crea una tabella BigLake Iceberg negli snapshot dei metadati BigQuery
Per creare una tabella BigLake Iceberg nello snapshot dei metadati BigQuery:
Esporta i metadati nel formato Iceberg V2 con l'istruzione SQL
EXPORT TABLE METADATA.(Facoltativo) Pianifica l'aggiornamento dello snapshot dei metadati Iceberg. Per aggiornare uno snapshot dei metadati Iceberg in base a un intervallo di tempo impostato, utilizza una query pianificata.
(Facoltativo) Attiva l'aggiornamento automatico dei metadati per il tuo progetto per aggiornare automaticamente lo snapshot dei metadati della tabella Iceberg a ogni modifica della tabella. Per attivare l'aggiornamento automatico dei metadati, contatta bigquery-tables-for-apache-iceberg-help@google.com. I costi di
EXPORT METADATAvengono applicati a ogni operazione di aggiornamento.
Il seguente esempio crea una query pianificata denominata My Scheduled Snapshot Refresh Query
utilizzando l'istruzione DDL EXPORT TABLE METADATA FROM mydataset.test. L'istruzione DDL
viene eseguita ogni 24 ore.
bq query \ --use_legacy_sql=false \ --display_name='My Scheduled Snapshot Refresh Query' \ --schedule='every 24 hours' \ 'EXPORT TABLE METADATA FROM mydataset.test'
Visualizzare la tabella BigLake Iceberg nello snapshot dei metadati BigQuery
Dopo aver aggiornato la tabella BigLake Iceberg nello snapshot dei metadati BigQuery, puoi trovare lo snapshot nell'URI Cloud Storage in cui è stata creata originariamente la tabella BigLake Iceberg in BigQuery. La cartella /data
contiene gli shard di dati dei file Parquet e la cartella /metadata contiene
lo snapshot dei metadati della tabella BigLake Iceberg in BigQuery.
SELECT table_name, REGEXP_EXTRACT(ddl, r"storage_uri\s*=\s*\"([^\"]+)\"") AS storage_uri FROM `mydataset`.INFORMATION_SCHEMA.TABLES;
Tieni presente che mydataset e table_name sono segnaposto per il set di dati e la tabella effettivi.
Leggere le tabelle BigLake Iceberg in BigQuery con Apache Spark
Il seguente esempio configura l'ambiente per utilizzare Spark SQL con Apache Iceberg, quindi esegue una query per recuperare i dati da una tabella BigLake Iceberg specificata in BigQuery.
spark-sql \ --packages org.apache.iceberg:iceberg-spark-runtime-ICEBERG_VERSION_NUMBER \ --conf spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.CATALOG_NAME.type=hadoop \ --conf spark.sql.catalog.CATALOG_NAME.warehouse='BUCKET_PATH' \ # Query the table SELECT * FROM CATALOG_NAME.FOLDER_NAME;
Sostituisci quanto segue:
- ICEBERG_VERSION_NUMBER: la versione attuale di Apache Spark Iceberg Runtime. Scarica l'ultima versione da Spark Releases.
- CATALOG_NAME: il catalogo a cui fare riferimento per la tabella BigLake Iceberg in BigQuery.
- BUCKET_PATH: il percorso del bucket contenente i file della tabella. Ad esempio,
gs://mybucket/. - FOLDER_NAME: la cartella contenente i file della tabella.
Ad esempio,
myfolder.
Modificare le tabelle BigLake Iceberg in BigQuery
Per modificare una tabella BigLake Iceberg in BigQuery, segui i passaggi descritti in Modifica degli schemi delle tabelle.
Utilizzare le transazioni con più istruzioni
Per ottenere l'accesso alle transazioni multi-istruzione per le tabelle BigLake Iceberg in BigQuery, compila il modulo di registrazione.
Prezzi
I prezzi delle tabelle BigLake Iceberg in BigQuery sono costituiti da spazio di archiviazione, ottimizzazione dello spazio di archiviazione e query e job.
Archiviazione
Le tabelle BigLake Iceberg in BigQuery archiviano tutti i dati in Cloud Storage. Ti vengono addebitati tutti i dati archiviati, inclusi i dati storici delle tabelle. Potrebbero essere applicati anche costi di elaborazione dei dati e di trasferimento di Cloud Storage. Alcune tariffe per le operazioni Cloud Storage potrebbero essere esenti per le operazioni elaborate tramite BigQuery o l'API BigQuery Storage. Non sono previste tariffe di archiviazione specifiche per BigQuery. Per maggiori informazioni, consulta la pagina Prezzi di Cloud Storage.
Ottimizzazione archiviazione
Le tabelle BigLake Iceberg in BigQuery eseguono l'ottimizzazione automatica dello spazio di archiviazione,
inclusi il dimensionamento adattivo dei file, il clustering automatico, la garbage collection e
l'ottimizzazione dei metadati. Queste operazioni di ottimizzazione utilizzano
slot pay as you go di Enterprise edition
e non utilizzano le prenotazioni BACKGROUND esistenti.
Le operazioni di esportazione dei dati eseguite durante lo streaming tramite l'API BigQuery Storage Write sono incluse nei prezzi dell'API Storage Write e non vengono addebitate come manutenzione in background. Per ulteriori informazioni, consulta Prezzi dell'importazione dati.
L'utilizzo dell'ottimizzazione dello spazio di archiviazione e di EXPORT TABLE METADATA è visibile nella visualizzazione INFORMATION_SCHEMA.JOBS.
Query e job
Analogamente alle tabelle BigQuery, ti vengono addebitati i costi per le query e i byte letti (per TiB) se utilizzi i prezzi on demand di BigQuery o il consumo di slot (per ora di slot) se utilizzi i prezzi di calcolo della capacità di BigQuery.
I prezzi di BigQuery si applicano anche all'API BigQuery Storage Read e all'API BigQuery Storage Write.
Le operazioni di caricamento ed esportazione (ad esempio EXPORT METADATA) utilizzano
slot con pagamento a consumo di Enterprise.
Ciò differisce dalle tabelle BigQuery, per le quali queste operazioni non vengono addebitate. Se sono disponibili prenotazioni PIPELINE con slot Enterprise o
Enterprise Plus, le operazioni di caricamento ed esportazione
utilizzano preferibilmente questi slot di prenotazione.
Limitazioni
Le tabelle BigLake Iceberg in BigQuery presentano le seguenti limitazioni:
- Le tabelle BigLake Iceberg in BigQuery non supportano le operazioni di ridenominazione o le istruzioni
ALTER TABLE RENAME TO. - Le tabelle BigLake Iceberg in BigQuery non supportano le copie delle tabelle o le istruzioni
CREATE TABLE COPY. - Le tabelle BigLake Iceberg in BigQuery non supportano
i cloni di tabelle o
le istruzioni
CREATE TABLE CLONE. - Le tabelle BigLake Iceberg in BigQuery non supportano gli snapshot delle tabelle né le istruzioni
CREATE SNAPSHOT TABLE. - Le tabelle BigLake Iceberg in BigQuery non supportano lo schema di tabella seguente:
- Schema vuoto
- Schema con tipi di dati
BIGNUMERIC,INTERVAL,JSON,RANGEoGEOGRAPHY. - Schema con collation dei campi.
- Schema con espressioni di valori predefiniti.
- Le tabelle BigLake Iceberg in BigQuery non supportano i seguenti casi di evoluzione dello schema:
NUMERICaFLOATcoercizioni di tipoINTaFLOATcoercizioni di tipo- Aggiunta di nuovi campi nidificati a colonne
RECORDesistenti utilizzando istruzioni DDL SQL
- Le tabelle BigLake Iceberg in BigQuery mostrano una dimensione di archiviazione di 0 byte quando vengono interrogate dalla console o dalle API.
- Le tabelle BigLake Iceberg in BigQuery non supportano le viste materializzate.
- Le tabelle BigLake Iceberg in BigQuery non supportano le viste autorizzate, ma è supportato il controllo dell'accesso a livello di colonna.
- Le tabelle BigLake Iceberg in BigQuery non supportano gli aggiornamenti di Change Data Capture (CDC).
- Le tabelle Iceberg BigLake in BigQuery non supportano il recupero di emergenza gestito.
- Le tabelle BigLake Iceberg in BigQuery non supportano il partizionamento. Valuta la possibilità di utilizzare il clustering come alternativa.
- Le tabelle BigLake Iceberg in BigQuery non supportano la sicurezza a livello di riga.
- Le tabelle BigLake Iceberg in BigQuery non supportano finestre di sicurezza.
- Le tabelle BigLake Iceberg in BigQuery non supportano i job di estrazione.
- La visualizzazione
INFORMATION_SCHEMA.TABLE_STORAGEnon include le tabelle BigLake Iceberg in BigQuery. - Le tabelle BigLake Iceberg in BigQuery non sono supportate come destinazioni dei risultati delle query. Puoi invece utilizzare l'istruzione
CREATE TABLEcon l'argomentoAS query_statementper creare una tabella come destinazione del risultato della query. CREATE OR REPLACEnon supporta la sostituzione delle tabelle standard con tabelle BigLake Iceberg in BigQuery o delle tabelle BigLake Iceberg in BigQuery con tabelle standard.- Le istruzioni batch loading e
LOAD DATAsupportano solo l'aggiunta di dati alle tabelle BigLake Iceberg esistenti in BigQuery. - Il caricamento batch e le
istruzioni
LOAD DATAnon supportano gli aggiornamenti dello schema. TRUNCATE TABLEnon supporta le tabelle BigLake Iceberg in BigQuery. Sono disponibili due alternative:CREATE OR REPLACE TABLE, utilizzando le stesse opzioni di creazione delle tabelle.DELETE FROMtableWHEREtrue
- La
APPENDSfunzione con valori di tabella (TVF) non supporta le tabelle BigLake Iceberg in BigQuery. - I metadati Iceberg potrebbero non contenere dati trasmessi in streaming a BigQuery dall'API Storage Write negli ultimi 90 minuti.
- L'accesso paginato basato sui record che utilizza
tabledata.listnon supporta le tabelle BigLake Iceberg in BigQuery. - Le tabelle BigLake Iceberg in BigQuery non supportano i set di dati collegati.
- Per ogni tabella BigLake Iceberg in BigQuery viene eseguita una sola istruzione DML mutante simultanea (
UPDATE,DELETEeMERGE). Sono in coda altre istruzioni DML di mutazione.