Migrate tables from an HDFS data lake
This document shows you how to migrate your Apache Hadoop Distributed File System (HDFS) data lake tables to Google Cloud.
You can use the HDFS data lake migration connector in the BigQuery Data Transfer Service to migrate your Hive and Iceberg tables from various Hadoop distributions, both on-premises and cloud environments, into Google Cloud.
With the HDFS data lake connector, you can register your HDFS data lake tables with both Dataproc Metastore and BigLake metastore while using Cloud Storage as the underlying storage for your files.
The following diagram provides an overview of the table migration process from Hadoop cluster.
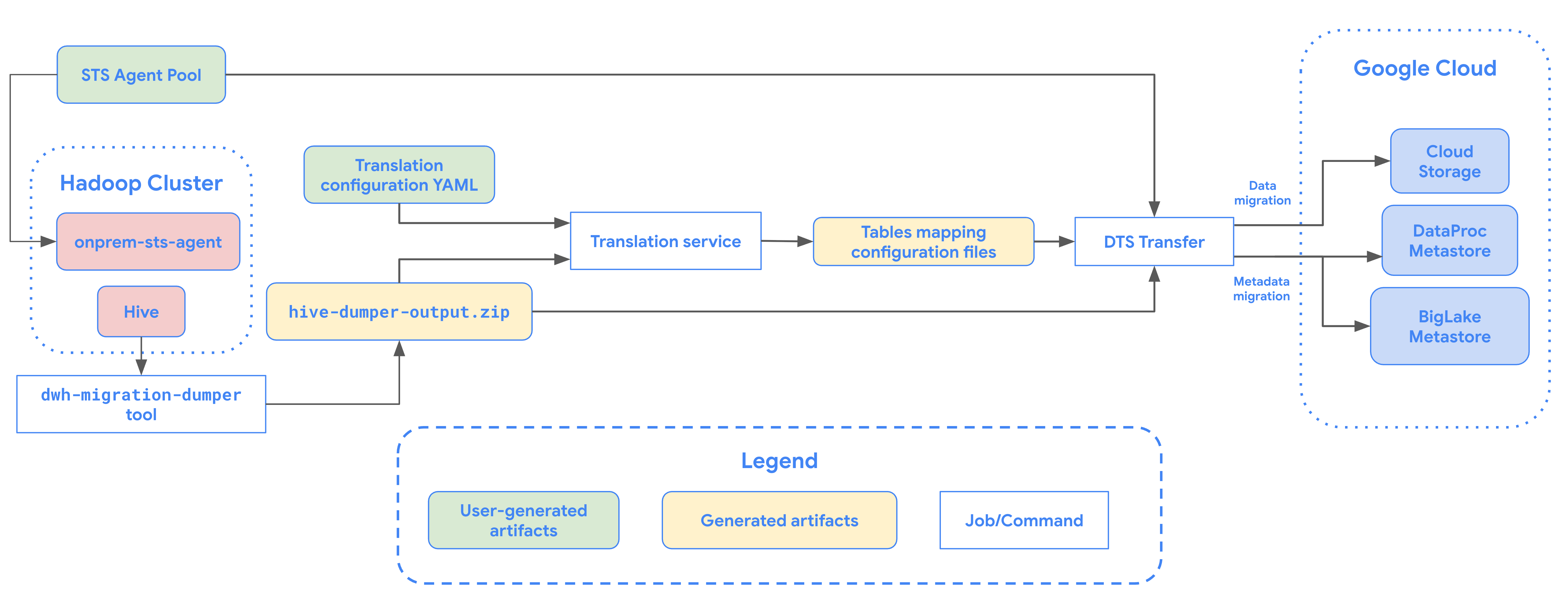
Limitations
HDFS data lake transfers are subject to the following limitations:
- To migrate Iceberg tables, you must register the tables with BigLake metastore to allow write access for open-source engines (such as Spark or Flink), and to allow read access for BigQuery.
- To migrate Hive tables, you must register the tables with DDataproc Metastore to allow write access for open-source engines, and to allow read access for BigQuery.
- You must use the bq command-line tool to migrate an HDFS data lake table to BigQuery.
Before you begin
Before you schedule an HDFS data lake transfer, you must perform the following:
Create a Cloud Storage bucket for migrated files
Create a Cloud Storage bucket that will be the
destination for your migrated data lake files. This bucket is
referred to in this document as MIGRATION_BUCKET.
Generate metadata file for Apache Hive
Run the dwh-migration-dumper tool to extract metadata
for Apache Hive. The tool generates a file named hive-dumper-output.zip
to a Cloud Storage bucket, referred to in this document as DUMPER_BUCKET.
Enable APIs
Enable the following APIs in your Google Cloud project:
- Data Transfer API
- Storage Transfer API
A service agent is created when you enable the Data Transfer API.
Configure permissions
- Create a service account and grant it the BigQuery Admin role (
roles/bigquery.admin). This service account is used to create the transfer configuration. - A service agent (P4SA) is created upon enabling the Data Transfer API. Grant
it the following roles:
roles/metastore.metadataOwnerroles/storagetransfer.adminroles/serviceusage.serviceUsageConsumerroles/storage.objectViewer- If you are migrating metadata for BigLake
Iceberg tables, grant it the
roles/storage.objectAdminandroles/bigquery.adminroles instead ofroles/storage.objectViewer.
- If you are migrating metadata for BigLake
Iceberg tables, grant it the
Grant the service agent the
roles/iam.serviceAccountTokenCreatorrole with the following command:gcloud iam service-accounts add-iam-policy-binding SERVICE_ACCOUNT --member serviceAccount:service-PROJECT_NUMBER@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com --role roles/iam.serviceAccountTokenCreator
Configure your Storage Transfer Agent
To set up the storage transfer agent required for an HDFS data lake transfer, do the following:
- Configure permissions to run the storage transfer agent on your Hadoop cluster.
- Install Docker on on-premises agent machines.
- Create a Storage Transfer Service agent pool in your Google Cloud project.
- Install agents on your on-premises agent machines.
Schedule an HDFS data lake transfer
To schedule an HDFS data lake transfer, enter the bq mk
command and supply the transfer creation flag --transfer_config:
bq mk --transfer_config --data_source=hadoop --display_name='TRANSFER_NAME' --service_account_name='SERVICE_ACCOUNT' --project_id='PROJECT_ID' --location='REGION' --params='{"table_name_patterns":"LIST_OF_TABLES", "agent_pool_name":"AGENT_POOL_NAME", "table_metadata_path":"gs://DUMPER_BUCKET/hive-dumper-output.zip", "target_gcs_file_path":"gs://MIGRATION_BUCKET", "destination_dataproc_metastore":"DATAPROC_METASTORE", "destination_bigquery_dataset":"BIGLAKE_METASTORE", "translation_output_gcs_path":"gs://TRANSLATION_OUTPUT_BUCKET/metadata/config/default_database/" }'
Replace the following:
TRANSFER_NAME: the display name for the transfer configuration. The transfer name can be any value that lets you identify the transfer if you need to modify it later.SERVICE_ACCOUNT: the service account name used to authenticate your transfer. The service account should be owned by the sameproject_idused to create the transfer and it should have all of the required permissions.PROJECT_ID: your Google Cloud project ID. If--project_idisn't supplied to specify a particular project, the default project is used.REGION: location of this transfer configuration.LIST_OF_TABLES: a list of entities to be transferred. Use a hierarchical naming spec -database.table. This field supports RE2 regular expression to specify tables. For example:db1..*: specifies all tables in the databasedb1.table1;db2.table2: a list of tables
AGENT_POOL_NAME: the name of the agent pool used for creating agents.DUMPER_BUCKET: the Cloud Storage bucket containing thehive-dumper-output.zipfile.MIGRATION_BUCKET: Destination GCS path to which all underlying files will be loaded.Metadata can be migrated to either Dataproc Metastore or BigLake metastore with the underlying data stored in Cloud Storage. You can specify the destination using one of the following parameters:
- To transfer metadata to Dataproc Metastore, use the
destination_dataproc_metastoreparameter and specify the URL to your metastore inDATAPROC_METASTORE. - To transfer metadata to BigLake metastore instead, use the
destination_bigquery_datasetparameter and specify the BigQuery dataset inBIGLAKE_METASTORE.
- To transfer metadata to Dataproc Metastore, use the
TRANSLATION_OUTPUT_BUCKET: (Optional) Specify a Cloud Storage bucket for the translation output. For more information, see Using Translation output.
Run this command to create the transfer configuration and start the HDFS data lake transfer. Transfers are scheduled to run every 24 hours by default, but can be configured with transfer scheduling options.
When the transfer is complete, your tables in Hadoop cluster will be
migrated to MIGRATION_BUCKET.
Data ingestion options
The following sections provide more information about how you can configure your HDFS data lake transfers.
Incremental transfers
When a transfer configuration is set up with a recurring schedule, every subsequent transfer updates the table on Google Cloud with the latest updates made to the source table. For example, all insert, delete, or update operations with schema changes are reflected in Google Cloud with each transfer.
Transfer scheduling options
By default, transfers are scheduled to
run every 24 hours by default. To configure how often transfers are run,
add the --schedule flag to the transfer configuration, and specify a transfer
schedule using the schedule syntax.
HDFS data lake transfers must have a minimum of 24 hours
between transfer runs.
For one-time transfers, you can add the
end_time flag to the transfer configuration to only run the
transfer once.
Configure Translation output
You can configure a unique Cloud Storage path and database for each migrated table. To do so, perform the following steps to generate a tables mapping YAML file that you can use in your transfer configuration.
Create a configuration YAML file (suffixed with
config.yaml) in theDUMPER_BUCKETthat contains the following:type: object_rewriter relation: - match: relationRegex: ".*" external: location_expression: "'gs://MIGRATION_BUCKET/' + table.schema + '/' + table.name"
- Replace
MIGRATION_BUCKETwith the name of the Cloud Storage bucket that is the destination for your migrated table files. Thelocation_expressionfield is a common expression language (CEL) expression.
- Replace
Create another configuration YAML file (suffixed with
config.yaml) in theDUMPER_BUCKETthat contains the following:type: experimental_object_rewriter relation: - match: schema: SOURCE_DATABASE outputName: database: null schema: TARGET_DATABASE
- Replace
SOURCE_DATABASEandTARGET_DATABASEwith the name of source database name and Dataproc Metastore database or BigQuery dataset depending on the chosen metastore. Ensure that the BigQuery dataset exists if you are configuring the database for BigLake metastore.
For more information about these configuration YAML, see Guidelines to create a configuration YAML file.
- Replace
Generate tables mapping YAML file using the following command:
curl -d '{ "tasks": { "string": { "type": "HiveQL2BigQuery_Translation", "translation_details": { "target_base_uri": "TRANSLATION_OUTPUT_BUCKET", "source_target_mapping": { "source_spec": { "base_uri": "DUMPER_BUCKET" } }, "target_types": ["metadata"] } } } }' \ -H "Content-Type:application/json" \ -H "Authorization: Bearer TOKEN" -X POST https://bigquerymigration.googleapis.com/v2alpha/projects/PROJECT_ID/locations/LOCATION/workflows
Replace the following:
TRANSLATION_OUTPUT_BUCKET: (Optional) Specify a Cloud Storage bucket for the translation output. For more information, see Using Translation output.DUMPER_BUCKET: the base URI for Cloud Storage bucket that contains thehive-dumper-output.zipand configuration YAML file.TOKEN: the OAuth token. You can generate this in the command line with the commandgcloud auth print-access-token.PROJECT_ID: the project to process the translation.LOCATION: the location where the job is processed. For example,euorus.
Monitor the status of this job. When completed, a mapping file is generated for each table in database within a predefined path in
TRANSLATION_OUTPUT_BUCKET.
Monitor HDFS data lake transfers
After you schedule an HDFS data lake transfer, you can monitor the transfer job with bq command-line tool commands. For information about monitoring your transfer jobs, see View your transfers.
Track table migration status
You can also run the
dwh-dts-status tool to monitor the status of all transferred tables within
a transfer configuration or a particular database. You can also use the dwh-dts-status
tool to list all transfer configurations in a project.
Before you begin
Before you can use the dwh-dts-status tool, do the following:
Get the
dwh-dts-statustool by downloading thedwh-migration-toolpackage from thedwh-migration-toolsGitHub repository.Authenticate your account to Google Cloud with the following command:
gcloud auth application-default loginFor more information, see How Application Default Credentials work.
Verify that the user has the
bigquery.adminandlogging.viewerrole. For more information about IAM roles, see Access control reference.
List all transfer configurations in a project
To list all transfer configurations in a project, use the following command:
./dwh-dts-status --list-transfer-configs --project-id=[PROJECT_ID] --location=[LOCATION]
Replace the following:
PROJECT_ID: the Google Cloud project ID that is running the transfers.LOCATION: the location where the transfer configuration was created.
This command outputs a table with a list of transfer configuration names and IDs.
View statuses of all tables in a configuration
To view the status of all tables included in a transfer configuration, use the following command:
./dwh-dts-status --list-status-for-config --project-id=[PROJECT_ID] --config-id=[CONFIG_ID] --location=[LOCATION]
Replace the following:
PROJECT_ID: the Google Cloud project ID that is running the transfers.LOCATION: the location where the transfer configuration was created.CONFIG_ID: the ID of the specified transfer configuration.
This command outputs a table with a list of tables, and their transfer status,
in the specified transfer configuration. The transfer status can be one of the
following values: PENDING, RUNNING, SUCCEEDED, FAILED, CANCELLED.
View statuses of all tables in a database
To view the status of all tables transferred from a specific database, use the following command:
./dwh-dts-status --list-status-for-database --project-id=[PROJECT_ID] --database=[DATABASE]
Replace the following:
PROJECT_ID: the Google Cloud project ID that is running the transfers.DATABASE:the name of the specified database.
This command outputs a table with a list of tables, and their transfer status,
in the specified database. The transfer status can be one of the
following values: PENDING, RUNNING, SUCCEEDED, FAILED, CANCELLED.