Export models
This page shows you how to export BigQuery ML models. You can export BigQuery ML models to Cloud Storage, and use them for online prediction, or edit them in Python. You can export a BigQuery ML model by:
- Using the Google Cloud console.
- Using the
EXPORT MODELstatement. - Using the
bq extractcommand in the bq command-line tool. - Submitting an
extractjob through the API or client libraries.
You can export the following model types:
AUTOENCODERAUTOML_CLASSIFIERAUTOML_REGRESSORBOOSTED_TREE_CLASSIFIERBOOSTED_TREE_REGRESSORDNN_CLASSIFIERDNN_REGRESSORDNN_LINEAR_COMBINED_CLASSIFIERDNN_LINEAR_COMBINED_REGRESSORKMEANSLINEAR_REGLOGISTIC_REGMATRIX_FACTORIZATIONRANDOM_FOREST_CLASSIFIERRANDOM_FOREST_REGRESSORTENSORFLOW(imported TensorFlow models)PCATRANSFORM_ONLY
Export model formats and samples
The following table shows the export destination formats for each BigQuery ML model type and provides a sample of files that get written in the Cloud Storage bucket.
| Model type | Export model format | Exported files sample |
|---|---|---|
| AUTOML_CLASSIFIER | TensorFlow SavedModel (TF 2.1.0) | gcs_bucket/
|
| AUTOML_REGRESSOR | ||
| AUTOENCODER | TensorFlow SavedModel (TF 1.15 or higher) | |
| DNN_CLASSIFIER | ||
| DNN_REGRESSOR | ||
| DNN_LINEAR_COMBINED_CLASSIFIER | ||
| DNN_LINEAR_COMBINED_REGRESSOR | ||
| KMEANS | ||
| LINEAR_REGRESSOR | ||
| LOGISTIC_REG | ||
| MATRIX_FACTORIZATION | ||
| PCA | ||
| TRANSFORM_ONLY | ||
| BOOSTED_TREE_CLASSIFIER | Booster (XGBoost 0.82) | gcs_bucket/
main.py is for local run. See Model deployment for more details.
|
| BOOSTED_TREE_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| TENSORFLOW (imported) | TensorFlow SavedModel | Exactly the same files that were present when importing the model |
Export model trained with TRANSFORM
If the model is trained with the
TRANSFORM clause,
then an additional preprocessing model performs the same logic in the
TRANSFORM clause and is saved in the
TensorFlow SavedModel format under the subdirectory transform.
You can deploy a model trained with the TRANSFORM clause
to Vertex AI as well as locally. For more information, see
model deployment.
| Export model format | Exported files sample |
|---|---|
|
Prediction model: TensorFlow SavedModel or Booster (XGBoost 0.82).
Preprocessing model for TRANSFORM clause: TensorFlow SavedModel (TF 2.5 or higher) |
gcs_bucket/
|
The model doesn't contain the information about the feature engineering
performed outside the TRANSFORM clause
during training. For example, anything in the SELECT statement . So you would
need to manually convert the input data before feeding into the preprocessing
model.
Supported data types
When exporting models trained with the TRANSFORM clause,
the following data types are supported for feeding into the
TRANSFORM clause.
| TRANSFORM input type | TRANSFORM input samples | Exported preprocessing model input samples |
|---|---|---|
| INT64 |
10,
|
tf.constant(
|
| NUMERIC |
NUMERIC 10,
|
tf.constant(
|
| BIGNUMERIC |
BIGNUMERIC 10,
|
tf.constant(
|
| FLOAT64 |
10.0,
|
tf.constant(
|
| BOOL |
TRUE,
|
tf.constant(
|
| STRING |
'abc',
|
tf.constant(
|
| BYTES |
b'abc',
|
tf.constant(
|
| DATE |
DATE '2020-09-27',
|
tf.constant(
|
| DATETIME |
DATETIME '2023-02-02 02:02:01.152903',
|
tf.constant(
|
| TIME |
TIME '16:32:36.152903',
|
tf.constant(
|
| TIMESTAMP |
TIMESTAMP '2017-02-28 12:30:30.45-08',
|
tf.constant(
|
| ARRAY |
['a', 'b'],
|
tf.constant(
|
| ARRAY< STRUCT< INT64, FLOAT64>> |
[(1, 1.0), (2, 1.0)],
|
tf.sparse.from_dense(
|
| NULL |
NULL,
|
tf.constant(
|
Supported SQL functions
When exporting models trained with the TRANSFORM clause,
you can use the following SQL functions inside the TRANSFORM clause
.
- Operators
+,-,*,/,=,<,>,<=,>=,!=,<>,[NOT] BETWEEN,[NOT] IN,IS [NOT] NULL,IS [NOT] TRUE,IS [NOT] FALSE,NOT,AND,OR.
- Conditional expressions
CASE expr,CASE,COALESCE,IF,IFNULL,NULLIF.
- Mathematical functions
ABS,ACOS,ACOSH,ASINH,ATAN,ATAN2,ATANH,CBRT,CEIL,CEILING,COS,COSH,COT,COTH,CSC,CSCH,EXP,FLOOR,IS_INF,IS_NAN,LN,LOG,LOG10,MOD,POW,POWER,SEC,SECH,SIGN,SIN,SINH,SQRT,TAN,TANH.
- Conversion functions
CAST AS INT64,CAST AS FLOAT64,CAST AS NUMERIC,CAST AS BIGNUMERIC,CAST AS STRING,SAFE_CAST AS INT64,SAFE_CAST AS FLOAT64
- String functions
CONCAT,LEFT,LENGTH,LOWER,REGEXP_REPLACE,RIGHT,SPLIT,SUBSTR,SUBSTRING,TRIM,UPPER.
- Date functions
Date,DATE_ADD,DATE_SUB,DATE_DIFF,DATE_TRUNC,EXTRACT,FORMAT_DATE,PARSE_DATE,SAFE.PARSE_DATE.
- Datetime functions
DATETIME,DATETIME_ADD,DATETIME_SUB,DATETIME_DIFF,DATETIME_TRUNC,EXTRACT,PARSE_DATETIME,SAFE.PARSE_DATETIME.
- Time functions
TIME,TIME_ADD,TIME_SUB,TIME_DIFF,TIME_TRUNC,EXTRACT,FORMAT_TIME,PARSE_TIME,SAFE.PARSE_TIME.
- Timestamp functions
TIMESTAMP,TIMESTAMP_ADD,TIMESTAMP_SUB,TIMESTAMP_DIFF,TIMESTAMP_TRUNC,FORMAT_TIMESTAMP,PARSE_TIMESTAMP,SAFE.PARSE_TIMESTAMP,TIMESTAMP_MICROS,TIMESTAMP_MILLIS,TIMESTAMP_SECONDS,EXTRACT,STRING,UNIX_MICROS,UNIX_MILLIS,UNIX_SECONDS.
- Manual preprocessing functions
ML.IMPUTER,ML.HASH_BUCKETIZE,ML.LABEL_ENCODER,ML.MULTI_HOT_ENCODER,ML.NGRAMS,ML.ONE_HOT_ENCODER,ML.BUCKETIZE,ML.MAX_ABS_SCALER,ML.MIN_MAX_SCALER,ML.NORMALIZER,ML.QUANTILE_BUCKETIZE,ML.ROBUST_SCALER,ML.STANDARD_SCALER.
Limitations
The following limitations apply when exporting models:
Model export is not supported if any of the following features were used during training:
ARRAY,TIMESTAMP, orGEOGRAPHYfeature types were present in the input data.
Exported models for model types
AUTOML_REGRESSORandAUTOML_CLASSIFIERdo not support Vertex AI deployment for online prediction.The model size limit is 1 GB for matrix factorization model export. The model size is roughly proportional to
num_factors, so you can reducenum_factorsduring training to shrink the model size if you reach the limit.For models trained with the BigQuery ML
TRANSFORMclause for manual feature preprocessing, see the data types and functions supported for exporting.Models trained with the BigQuery ML
TRANSFORMclause before 18 September 2023 must be re-trained before they can be deployed through Model Registry for online prediction.During model export,
ARRAY<STRUCT<INT64, FLOAT64>>,ARRAYandTIMESTAMPare supported as pre-transformed data, but are not supported as post-transformed data.
Export BigQuery ML models
To export a model:
Console
Open the BigQuery page in the Google Cloud console.
In the navigation panel, in the Resources section, expand your project and click your dataset to expand it. Find and click the model that you're exporting.
On the right side of the window, click Export Model.
In the Export model to Cloud Storage dialog:
- For Select Cloud Storage location, browse for the bucket or folder location where you want to to export the model.
- Click Export to export the model.
To check on the progress of the job, look near the top of the navigation for Job history for an Export job.
SQL
The EXPORT MODEL statement lets you export BigQuery ML models
to Cloud Storage using GoogleSQL
query syntax.
To export a BigQuery ML model in the Google Cloud console by
using the EXPORT MODEL statement, follow these steps:
In the Google Cloud console, open the BigQuery page.
Click Compose new query.
In the Query editor field, type your
EXPORT MODELstatement.The following query exports a model named
myproject.mydataset.mymodelto a Cloud Storage bucket with URIgs://bucket/path/to/saved_model/.EXPORT MODEL `myproject.mydataset.mymodel` OPTIONS(URI = 'gs://bucket/path/to/saved_model/')
Click Run. When the query is complete, the following appears in the Query results pane:
Successfully exported model.
bq
Use the bq extract command with the --model flag.
(Optional) Supply the --destination_format flag and pick the format of the
model exported.
(Optional) Supply the --location flag and set the value to
your location.
bq --location=location extract \ --destination_format format \ --model project_id:dataset.model \ gs://bucket/model_folder
Where:
- location is the name of your location. The
--locationflag is optional. For example, if you are using BigQuery in the Tokyo region, you can set the flag's value toasia-northeast1. You can set a default value for the location using the .bigqueryrc file. - destination_format is the format for the exported model:
ML_TF_SAVED_MODEL(default), orML_XGBOOST_BOOSTER. - project_id is your project ID.
- dataset is the name of the source dataset.
- model is the model you're exporting.
- bucket is the name of the Cloud Storage bucket to which you're exporting the data. The BigQuery dataset and the Cloud Storage bucket must be in the same location.
- model_folder is the name of the folder where the exported model files will be written.
Examples:
For example, the following command exports mydataset.mymodel in TensorFlow SavedModel
format to a Cloud Storage bucket named mymodel_folder.
bq extract --model \ 'mydataset.mymodel' \ gs://example-bucket/mymodel_folder
The default value of destination_format is ML_TF_SAVED_MODEL.
The following command exports mydataset.mymodel in XGBoost Booster format
to a Cloud Storage bucket named mymodel_folder.
bq extract --model \ --destination_format ML_XGBOOST_BOOSTER \ 'mydataset.mytable' \ gs://example-bucket/mymodel_folder
API
To export model, create an extract job and populate the job configuration.
(Optional) Specify your location in the location property in the
jobReference section of the
job resource.
Create an extract job that points to the BigQuery ML model and the Cloud Storage destination.
Specify the source model by using the
sourceModelconfiguration object that contains the project ID, dataset ID, and model ID.The
destination URI(s)property must be fully-qualified, in the format gs://bucket/model_folder.Specify the destination format by setting the
configuration.extract.destinationFormatproperty. For example, to export a boosted tree model, set this property to the valueML_XGBOOST_BOOSTER.To check the job status, call jobs.get(job_id) with the ID of the job returned by the initial request.
- If
status.state = DONE, the job completed successfully. - If the
status.errorResultproperty is present, the request failed, and that object will include information describing what went wrong. - If
status.errorResultis absent, the job finished successfully, although there might have been some non-fatal errors. Non-fatal errors are listed in the returned job object'sstatus.errorsproperty.
- If
API notes:
As a best practice, generate a unique ID and pass it as
jobReference.jobIdwhen callingjobs.insertto create a job. This approach is more robust to network failure because the client can poll or retry on the known job ID.Calling
jobs.inserton a given job ID is idempotent; in other words, you can retry as many times as you like on the same job ID, and at most one of those operations will succeed.
Java
Before trying this sample, follow the Java setup instructions in the BigQuery quickstart using client libraries. For more information, see the BigQuery Java API reference documentation.
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up authentication for client libraries.
Model deployment
You can deploy the exported model to Vertex AI as well as locally. If the
model's TRANSFORM clause contains Date
functions, Datetime functions, Time functions or Timestamp functions, you must
use bigquery-ml-utils library
in the container. The exception is if you are deploying through Model Registry,
which does not need exported models or serving containers.
Vertex AI deployment
| Export model format | Deployment |
|---|---|
| TensorFlow SavedModel (non-AutoML models) | Deploy a TensorFlow SavedModel. You must create the SavedModel file using a supported version of TensorFlow. |
| TensorFlow SavedModel (AutoML models) | Not supported. |
| XGBoost Booster |
Use a custom prediction routine. For XGBoost Booster models, preprocessing and postprocessing
information is saved in the exported files, and a custom
prediction routine lets you deploy the model with the extra exported
files.
You must create the model files using a supported version of XGBoost. |
Local deployment
| Export model format | Deployment |
|---|---|
| TensorFlow SavedModel (non-AutoML models) |
SavedModel is a standard format, and you can deploy them in TensorFlow Serving docker container. You can also leverage the local run of Vertex AI online prediction. |
| TensorFlow SavedModel (AutoML models) | Containerize and run the model. |
| XGBoost Booster |
To run XGBoost Booster models locally, you can use the exported main.py
file:
|
Prediction output format
This section provides the prediction output format of the exported models for each model type. All exported models support batch prediction; they can handle multiple input rows at a time. For example, there are two input rows in each of the following output format examples.
AUTOENCODER
| Prediction output format | Output sample |
|---|---|
+------------------------+------------------------+------------------------+
| LATENT_COL_1 | LATENT_COL_2 | ... |
+------------------------+------------------------+------------------------+
| [FLOAT] | [FLOAT] | ... |
+------------------------+------------------------+------------------------+
|
+------------------+------------------+------------------+------------------+
| LATENT_COL_1 | LATENT_COL_2 | LATENT_COL_3 | LATENT_COL_4 |
+------------------------+------------+------------------+------------------+
| 0.21384512 | 0.93457112 | 0.64978097 | 0.00480489 |
+------------------+------------------+------------------+------------------+
|
AUTOML_CLASSIFIER
| Prediction output format | Output sample |
|---|---|
+------------------------------------------+
| predictions |
+------------------------------------------+
| [{"scores":[FLOAT], "classes":[STRING]}] |
+------------------------------------------+
|
+---------------------------------------------+
| predictions |
+---------------------------------------------+
| [{"scores":[1, 2], "classes":['a', 'b']}, |
| {"scores":[3, 0.2], "classes":['a', 'b']}] |
+---------------------------------------------+
|
AUTOML_REGRESSOR
| Prediction output format | Output sample |
|---|---|
+-----------------+
| predictions |
+-----------------+
| [FLOAT] |
+-----------------+
|
+-----------------+
| predictions |
+-----------------+
| [1.8, 2.46] |
+-----------------+
|
BOOSTED_TREE_CLASSIFIER and RANDOM_FOREST_CLASSIFIER
| Prediction output format | Output sample |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
BOOSTED_TREE_REGRESSOR AND RANDOM_FOREST_REGRESSOR
| Prediction output format | Output sample |
|---|---|
+-----------------+
| predicted_label |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| predicted_label |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_CLASSIFIER
| Prediction output format | Output sample |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_REGRESSOR
| Prediction output format | Output sample |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_LINEAR_COMBINED_CLASSIFIER
| Prediction output format | Output sample |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_LINEAR_COMBINED_REGRESSOR
| Prediction output format | Output sample |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
KMEANS
| Prediction output format | Output sample |
|---|---|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [FLOAT] | [INT64] | INT64 |
+--------------------+--------------+---------------------+
|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [1.2, 1.3] | [1, 2] | [1] |
+--------------------+--------------+---------------------+
| [0.4, 0.1] | [1, 2] | [2] |
+--------------------+--------------+---------------------+
|
LINEAR_REG
| Prediction output format | Output sample |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
LOGISTIC_REG
| Prediction output format | Output sample |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
MATRIX_FACTORIZATION
Note: We currently only support taking an input user and output top 50 (predicted_rating, predicted_item) pairs sorted by predicted_rating in descending order.
| Prediction output format | Output sample |
|---|---|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [FLOAT] | [STRING] |
+------------------+----------------+
|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [5.5, 1.7] | ['A', 'B'] |
+------------------+----------------+
| [7.2, 2.7] | ['B', 'A'] |
+------------------+----------------+
|
TENSORFLOW (imported)
| Prediction output format |
|---|
| Same as the imported model |
PCA
| Prediction output format | Output sample |
|---|---|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [INT64] | [FLOAT] |
+-------------------------+---------------------------------+
|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [1, 2] | [1.2, 5.0] |
+-------------------------+---------------------------------+
|
TRANSFORM_ONLY
| Prediction output format |
|---|
Same as the columns specified in the model's TRANSFORM
clause
|
XGBoost model visualization
You can visualize the boosted trees using the plot_tree Python API after model export. For example, you can leverage Colab without installing the dependencies:
- Export the boosted tree model to a Cloud Storage bucket.
- Download the
model.bstfile from the Cloud Storage bucket. - In a Colab noteboook,
upload the
model.bstfile toFiles. Run the following code in the notebook:
import xgboost as xgb import matplotlib.pyplot as plt model = xgb.Booster(model_file="model.bst") num_iterations = <iteration_number> for tree_num in range(num_iterations): xgb.plot_tree(model, num_trees=tree_num) plt.show
This example plots multiple trees (one tree per iteration):
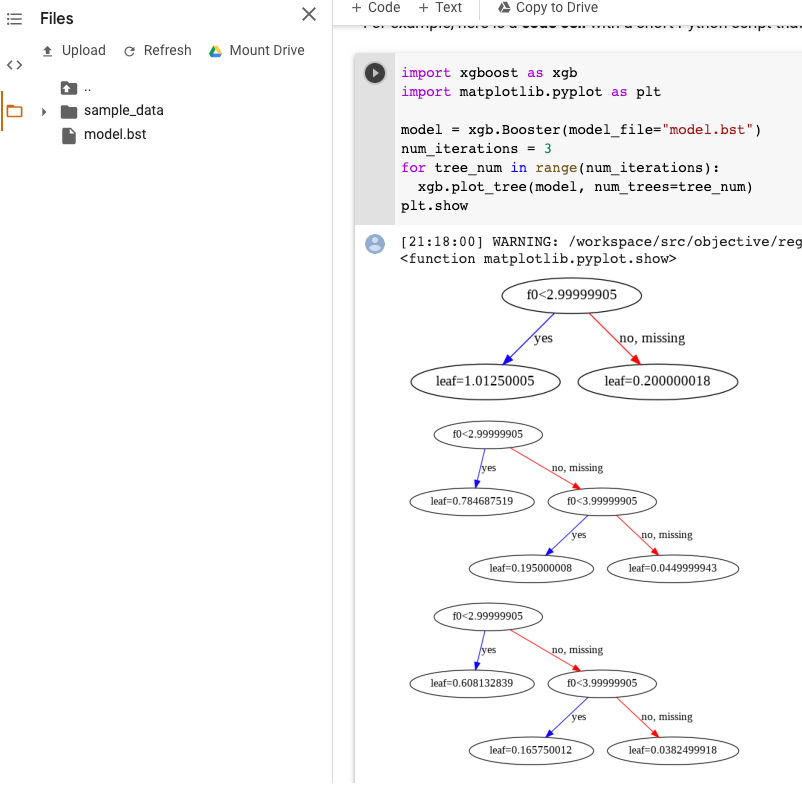
Currently, we don't save feature names in the model, so you will see names
such as "f0", "f1", and so on. You can find the corresponding feature names in
the assets/model_metadata.json exported file using these names (such as "f0")
as indexes.
Required permissions
To export a BigQuery ML model to Cloud Storage, you need permissions to access the BigQuery ML model, permissions to run an export job, and permissions to write the data to the Cloud Storage bucket.
BigQuery permissions
At a minimum, to export model, you must be granted
bigquery.models.exportpermissions. The following predefined Identity and Access Management (IAM) roles are grantedbigquery.models.exportpermissions:bigquery.dataViewerbigquery.dataOwnerbigquery.dataEditorbigquery.admin
At a minimum, to run an export job, you must be granted
bigquery.jobs.createpermissions. The following predefined IAM roles are grantedbigquery.jobs.createpermissions:bigquery.userbigquery.jobUserbigquery.admin
Cloud Storage permissions
To write the data to an existing Cloud Storage bucket, you must be granted
storage.objects.createpermissions. The following predefined IAM roles are grantedstorage.objects.createpermissions:storage.objectCreatorstorage.objectAdminstorage.admin
For more information on IAM roles and permissions in BigQuery ML, see Access control.
Move BigQuery data between locations
You cannot change the location of a dataset after it is created, but you can make a copy of the dataset.
Quota policy
For information on export job quotas, see Export jobs on the Quotas and limits page.
Pricing
There is no charge for exporting BigQuery ML models, but exports are subject to BigQuery's Quotas and limits. For more information on BigQuery pricing, see the Pricing page.
After the data is exported, you are charged for storing the data in Cloud Storage. For more information on Cloud Storage pricing, see the Cloud Storage Pricing page.
What's next
- Walk through the Export a BigQuery ML model for online prediction tutorial.