建立資料集
本文件說明如何在 BigQuery 中建立資料集。
您可以透過下列方式建立資料集:
- 使用 Google Cloud 控制台。
- 使用 SQL 查詢。
- 在 bq 指令列工具中使用
bq mk指令。 - 呼叫
datasets.insertAPI 方法 - 使用用戶端程式庫。
- 複製現有的資料集
如要查看複製資料集的步驟 (包括跨地區),請參閱複製資料集一文。
本文說明如何使用在 BigQuery 中儲存資料的一般資料集。如要瞭解如何使用 Spanner 外部資料集,請參閱「建立 Spanner 外部資料集」。如要瞭解如何使用 AWS Glue 聯合資料集,請參閱「建立 AWS Glue 聯合資料集」。
如要瞭解如何查詢公開資料集中的資料表,請參閱「透過控制台查詢公開資料集」。 Google Cloud
資料集的限制
BigQuery 資料集有下列限制:
- 資料集位置只能在建立時設定。資料集建立後,就無法變更位置。
- 查詢中參考的所有資料表,都必須儲存在同一個位置的資料集中。
外部資料集不支援資料表到期時間、副本、時空旅行、預設定序、預設捨入模式,以及啟用或停用不區分大小寫的資料表名稱。
複製資料表時,包含來源資料表和目的地資料表的資料集必須位於相同位置。
每個專案的資料集名稱皆不得重複。
變更資料集的儲存空間計費模式後,必須等待 14 天才能再次變更。
如果資料集所在的地區有任何現有的舊版固定費率配額承諾,您就無法為資料集啟用實體儲存空間計費。
事前準備
授予身分與存取權管理 (IAM) 角色,讓使用者取得必要權限,執行本文件中的各項工作。
所需權限
如要建立資料集,您需要 bigquery.datasets.create 身分與存取權管理 (IAM) 權限。
下列每個預先定義的 IAM 角色都包含建立資料集所需的權限:
roles/bigquery.dataEditorroles/bigquery.dataOwnerroles/bigquery.userroles/bigquery.admin
如要進一步瞭解 BigQuery 中的 IAM 角色,請參閱預先定義的角色與權限一文。
建立資料集
如何建立資料集:
主控台
- 在 Google Cloud 控制台中開啟 BigQuery 頁面。 前往 BigQuery 頁面
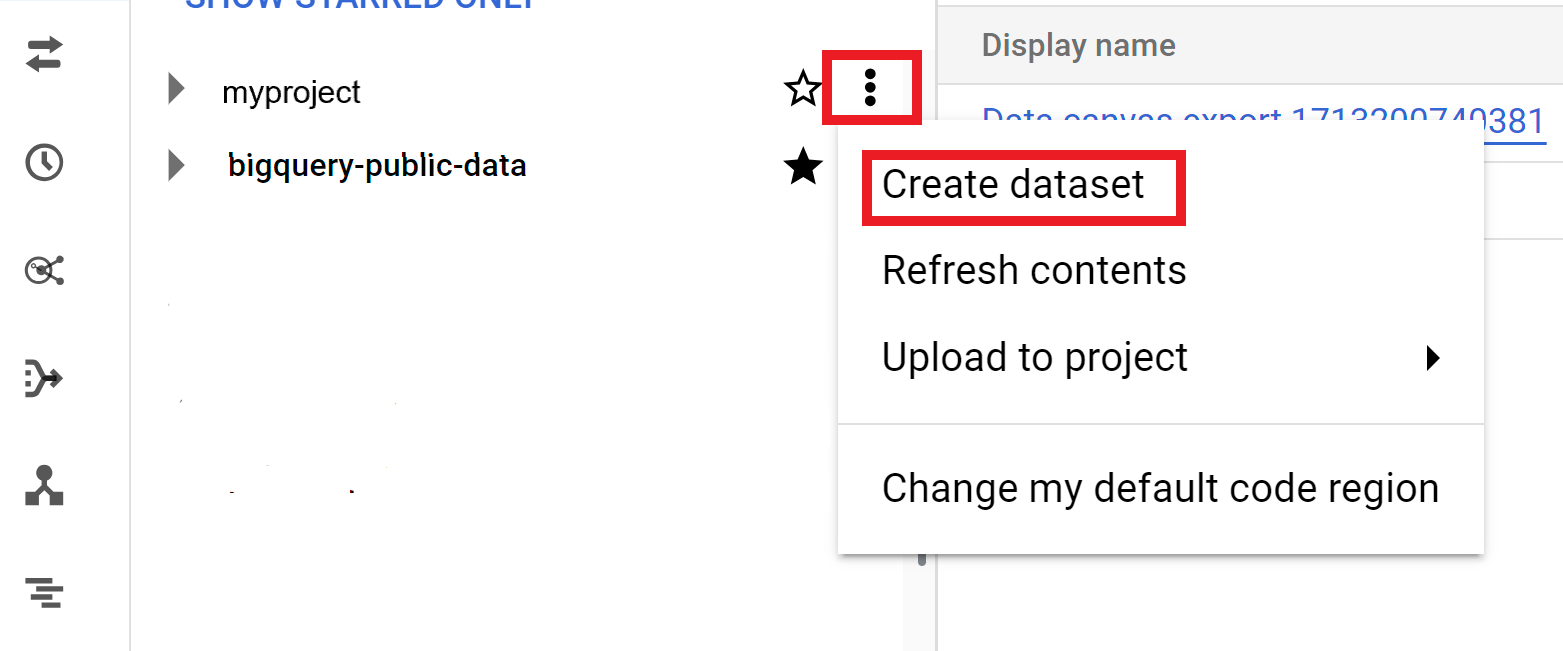
- 點選左側窗格中的「Explorer」。
- 選取要建立資料集的專案。
- 依序點選 「View actions」(查看動作) 和「Create dataset」(建立資料集)。
- 在「Create dataset」(建立資料集) 頁面:
- 針對「Dataset ID」(資料集 ID),輸入唯一的資料集名稱。
- 針對「Location type」(位置類型),選擇資料集的地理位置。資料集建立後即無法變更位置。
- 選用:如要建立外部資料集,請選取「外部資料集的連結」。
- 如不需設定其他選項 (例如標記和資料表到期時間),請按一下「建立資料集」。否則,請展開下節,設定其他資料集選項。
- 選用:展開「標記」部分,在資料集中新增標記。
- 如要套用現有標籤,請按照下列步驟操作:
- 按一下「選取範圍」旁的下拉式箭頭,然後選擇「目前範圍」,即「選取目前的機構」或「選取目前的專案」。
- 針對「鍵 1」和「值 1」,從清單中選擇適當的值。
- 如要手動輸入新標記,請按照下列步驟操作:
- 按一下「選取範圍」旁的下拉式箭頭,然後依序選擇「手動輸入 ID」>「機構」、「專案」或「標記」。
- 如要為專案或機構建立標記,請在對話方塊中輸入
PROJECT_ID或ORGANIZATION_ID,然後按一下「儲存」。 - 從清單中選擇「鍵 1」和「值 1」的適當值。
- 如要在表格中新增其他標記,請按一下「新增標記」,然後按照上述步驟操作。
- 選用:展開「進階選項」部分,設定下列一或多個選項。
- 如要變更「Encryption」(加密) 選項,以透過 Cloud Key Management Service 使用自己的加密金鑰,請選取「Cloud KMS key」(Cloud KMS 金鑰)。
- 如要使用不區分大小寫的資料表名稱,請選取「啟用不區分大小寫的資料表名稱」。
- 如要變更預設定序 規格,請從清單中選擇定序類型。
- 如要為資料集中的資料表設定到期時間,請選取「Enable table expiration」(啟用資料表到期時間),然後以天為單位指定「Default maximum table age」(預設資料表存在時間上限)。
- 如要設定預設捨入模式,請從清單中選擇捨入模式。
- 如要啟用實體儲存空間計費模式,請從清單中選擇計費模式。
- 如要設定資料集的時間回溯期,請從清單中選擇回溯期大小。
- 點選「建立資料集」。
資料集的其他選項
或者,按一下「選取範圍」,搜尋資源或查看目前資源清單。
變更資料集的計費模式後,最久需要 24 小時才會生效。
變更資料集的儲存空間計費模式後,必須等待 14 天才能再次變更。
SQL
如要在非預設專案中建立資料集,請採用下列格式將專案 ID 新增至資料集 ID:PROJECT_ID.DATASET_ID。
前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中輸入下列陳述式:
CREATE SCHEMA PROJECT_ID.DATASET_ID OPTIONS ( default_kms_key_name = 'KMS_KEY_NAME', default_partition_expiration_days = PARTITION_EXPIRATION, default_table_expiration_days = TABLE_EXPIRATION, description = 'DESCRIPTION', labels = [('KEY_1','VALUE_1'),('KEY_2','VALUE_2')], location = 'LOCATION', max_time_travel_hours = HOURS, storage_billing_model = BILLING_MODEL);
請替換下列項目:
PROJECT_ID:您的專案 IDDATASET_ID:您要建立的資料集 IDKMS_KEY_NAME:預設 Cloud Key Management Service 金鑰的名稱,用於保護這個資料集中新建立的資料表,除非在建立時提供其他金鑰。您無法在具有這組參數的資料集中,建立 Google 加密資料表。PARTITION_EXPIRATION:新建立的分區資料表中分區的預設生命週期 (以天為單位)。預設的分區到期時間沒有最小值。到期時間為分區日期加上整數值。在資料集的分區資料表中建立的任何分區,都會在分區日期後PARTITION_EXPIRATION天刪除。如果您在建立或更新分區資料表時使用time_partitioning_expiration選項,系統會優先採用資料表層級的分區到期時間,而不是資料集層級的預設分區到期時間。TABLE_EXPIRATION:新建立資料表的預設生命週期 (以天為單位)。最小值為 0.042 天 (1 小時)。到期時間為目前時間加整數值。在資料集中建立的任何資料表,都會在建立時間後TABLE_EXPIRATION天刪除。如果您在建立資料表時未設定資料表到期時間,系統就會套用這個值。DESCRIPTION:資料集的說明KEY_1:VALUE_1:您要設為這個資料集第一個標籤的鍵/值組合KEY_2:VALUE_2:您要設為第二個標籤的鍵/值組合LOCATION:資料集的位置。資料集建立後即無法變更位置。HOURS:新資料集的時間回溯期 (以小時為單位)。HOURS值必須是 24 的倍數 (48、72、96、120、144、168),且介於 48 (2 天) 和 168 (7 天) 之間的整數。如果未指定這個選項,預設值為 168 小時。BILLING_MODEL:為資料集設定儲存空間計費模式。將BILLING_MODEL值設為PHYSICAL,即可在計算儲存空間費用時使用實際位元組,設為LOGICAL則可使用邏輯位元組。預設值為LOGICAL。變更資料集的計費模式後,最久需要 24 小時才會生效。
變更資料集的儲存空間計費模式後,必須等待 14 天,才能再次變更儲存空間計費模式。
按一下「執行」。
如要進一步瞭解如何執行查詢,請參閱「執行互動式查詢」。
bq
如要建立新的資料集,請使用 bq mk 指令搭配 --location 旗標。如需可能的完整參數清單,請參閱 bq mk --dataset 指令參考資料。
如要在非預設專案中建立資料集,請採用下列格式將專案 ID 新增至資料集:PROJECT_ID:DATASET_ID。
bq --location=LOCATION mk \ --dataset \ --default_kms_key=KMS_KEY_NAME \ --default_partition_expiration=PARTITION_EXPIRATION \ --default_table_expiration=TABLE_EXPIRATION \ --description="DESCRIPTION" \ --label=KEY_1:VALUE_1 \ --label=KEY_2:VALUE_2 \ --add_tags=KEY_3:VALUE_3[,...] \ --max_time_travel_hours=HOURS \ --storage_billing_model=BILLING_MODEL \ PROJECT_ID:DATASET_ID
更改下列內容:
LOCATION:資料集的位置。 資料集在建立之後,該位置就無法改變。您可以使用.bigqueryrc檔案,設定該位置的預設值。KMS_KEY_NAME:預設 Cloud Key Management Service 金鑰的名稱,用於保護這個資料集中新建立的資料表,除非在建立時提供其他金鑰。您無法使用這組參數在資料集中建立 Google 加密資料表。PARTITION_EXPIRATION:新建分區資料表中分區的預設生命週期 (以秒為單位)。預設的分區到期時間沒有最小值。到期時間為分區日期加上整數值。在資料集的分區資料表中所建立的任何分區,都會以分區建立日期為起始點,在PARTITION_EXPIRATION秒後刪除。如果您在建立或更新分區資料表時使用--time_partitioning_expiration旗標,系統會優先採用資料表層級的分區到期時間,而不是資料集層級的預設分區到期時間。TABLE_EXPIRATION:新建立資料表的預設生命週期 (以秒為單位)。最小值是 3600 秒 (1 小時)。到期時間為目前時間加整數值。在資料集中建立的任何資料表都會在建立時間後TABLE_EXPIRATION秒刪除。如果您在建立資料表時未設定資料表到期時間,系統就會套用這個值。DESCRIPTION:資料集的說明KEY_1:VALUE_1:您要設為這個資料集第一個標籤的鍵值組,而KEY_2:VALUE_2則是您要設為第二個標籤的鍵值組。KEY_3:VALUE_3:您要在資料集上設定為標記的鍵值組。在相同標記下新增多個標記,並以逗號分隔鍵/值組合。HOURS:新資料集的時間旅行視窗時數。HOURS值必須是 24 的倍數 (48、72、96、120、144、168),且介於 48 (2 天) 和 168 (7 天) 之間。如果未指定這個選項,預設值為 168 小時。BILLING_MODEL:為資料集設定儲存空間計費模式。將BILLING_MODEL值設為PHYSICAL,即可在計算儲存空間費用時使用實體位元組;設為LOGICAL則可使用邏輯位元組。預設為LOGICAL。變更資料集的計費模式後,最久需要 24 小時才會生效。
變更資料集的儲存空間計費模式後,必須等待 14 天,才能再次變更儲存空間計費模式。
PROJECT_ID:您的專案 ID。DATASET_ID是您要建立的資料集 ID。
舉例來說,下列指令會建立名為 mydataset 的資料集,並將資料位置設定為 US,而預設的資料表到期時間為 3,600 秒 (1 小時),說明則為 This is my dataset。這個指令採用 -d 捷徑,而不是使用 --dataset 旗標。如果您省略 -d 和 --dataset,該指令預設會建立資料集。
bq --location=US mk -d \ --default_table_expiration 3600 \ --description "This is my dataset." \ mydataset
如要確認資料集是否已建立,請輸入 bq ls 指令。此外,您可以在建立新的資料集時,採用下列格式來建立資料表:bq mk -t dataset.table。如要進一步瞭解如何建立資料表,請參閱「建立資料表」。
Terraform
使用 google_bigquery_dataset 資源。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。詳情請參閱「設定用戶端程式庫的驗證機制」。
建立資料集
下列範例會建立名為 mydataset 的資料集:
使用 google_bigquery_dataset 資源建立資料集時,系統會自動將資料集存取權授予專案層級基本角色的所有帳戶。如果您在建立資料集後執行 terraform show 指令,資料集的 access 區塊會類似下列內容:
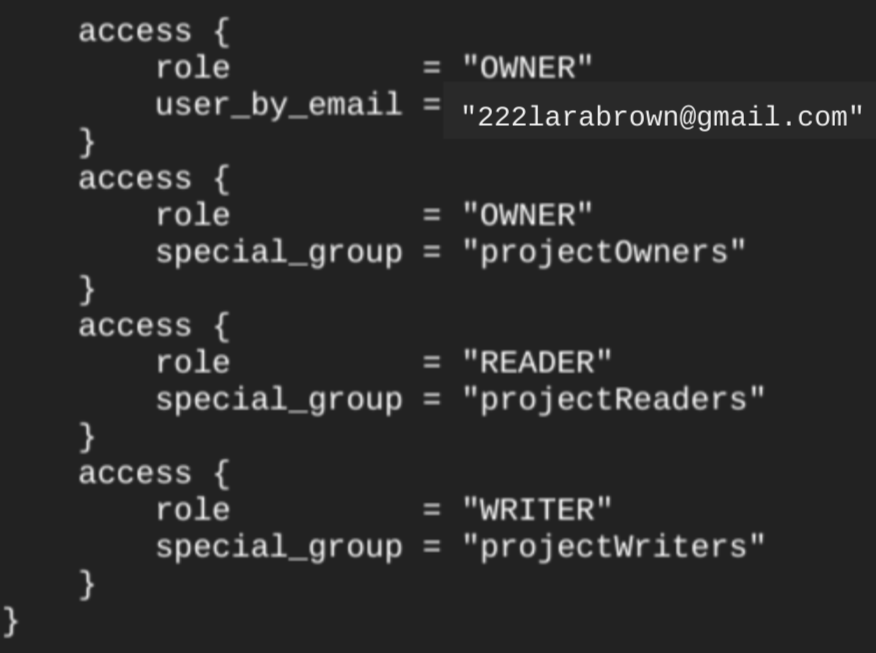
如要授予資料集存取權,建議您使用其中一個 google_bigquery_iam 資源,如下例所示,除非您打算在資料集中建立授權物件,例如授權檢視區塊。在這種情況下,請使用 google_bigquery_dataset_access 資源。如需範例,請參閱該說明文件。
建立資料集並授予存取權
以下範例會建立名為 mydataset 的資料集,然後使用 google_bigquery_dataset_iam_policy 資源授予存取權。
使用客戶自行管理的加密金鑰建立資料集
下列範例會建立名為 mydataset 的資料集,並使用 google_kms_crypto_key 和 google_kms_key_ring 資源,為資料集指定 Cloud Key Management Service 金鑰。您必須先啟用 Cloud Key Management Service API,才能執行這個範例。
如要在 Google Cloud 專案中套用 Terraform 設定,請完成下列各節的步驟。
準備 Cloud Shell
- 啟動 Cloud Shell。
-
設定要套用 Terraform 設定的預設 Google Cloud 專案。
每項專案只需要執行一次這個指令,且可以在任何目錄中執行。
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
如果您在 Terraform 設定檔中設定明確值,環境變數就會遭到覆寫。
準備目錄
每個 Terraform 設定檔都必須有自己的目錄 (也稱為根模組)。
-
在 Cloud Shell 中建立目錄,並在該目錄中建立新檔案。檔案名稱的副檔名必須是
.tf,例如main.tf。在本教學課程中,這個檔案稱為main.tf。mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
如果您正在學習教學課程,可以複製每個章節或步驟中的範例程式碼。
將範例程式碼複製到新建立的
main.tf。視需要從 GitHub 複製程式碼。如果 Terraform 代码片段是端對端解決方案的一部分,建議使用這個方法。
- 查看並修改範例參數,套用至您的環境。
- 儲存變更。
-
初始化 Terraform。每個目錄只需執行一次這項操作。
terraform init
如要使用最新版 Google 供應商,請加入
-upgrade選項:terraform init -upgrade
套用變更
-
檢查設定,確認 Terraform 即將建立或更新的資源符合您的預期:
terraform plan
視需要修正設定。
-
執行下列指令,並在提示中輸入
yes,即可套用 Terraform 設定:terraform apply
等待 Terraform 顯示「Apply complete!」訊息。
- 開啟 Google Cloud 專案即可查看結果。在 Google Cloud 控制台中,前往 UI 中的資源,確認 Terraform 已建立或更新這些資源。
API
請呼叫 datasets.insert 方法,搭配已定義的資料集資源。
C#
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 C# 設定說明進行操作。詳情請參閱 BigQuery C# API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Go
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Go 設定說明進行操作。詳情請參閱 BigQuery Go API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Java
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Java 設定說明進行操作。詳情請參閱 BigQuery Java API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Node.js
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Node.js 設定說明進行操作。詳情請參閱 BigQuery Node.js API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
PHP
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 PHP 設定說明進行操作。詳情請參閱 BigQuery PHP API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Python
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Python 設定說明進行操作。詳情請參閱 BigQuery Python API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Ruby
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Ruby 設定說明進行操作。詳情請參閱 BigQuery Ruby API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
為資料集命名
在 BigQuery 中建立資料集時,每個專案的資料集名稱不得重複。資料集名稱可包含下列項目:
- 最多 1,024 個字元。
- 字母 (大寫或小寫)、數字和底線。
資料集名稱預設會區分大小寫。mydataset 和 MyDataset 可在同一專案中並存,除非其中一個已關閉大小寫區分功能。如需範例,請參閱「建立不區分大小寫的資料集」和「資源:資料集」。
資料集名稱不得包含空格或特殊字元,例如 -、&、@ 或 %。
隱藏的資料集
隱藏資料集是指名稱以底線開頭的資料集。您可以查詢隱藏資料集中的資料表和檢視表,方式與查詢任何其他資料集相同。隱藏資料集有下列限制:
- 這些檔案會隱藏在 Google Cloud 控制台的「Explorer」面板中。
- 不會顯示在任何
INFORMATION_SCHEMA檢視畫面中。 - 無法與連結資料集搭配使用。
- 這些資料集無法做為下列授權資源的來源資料集:
- 不會顯示在 Data Catalog (已淘汰) 或 Dataplex Universal Catalog 中。
資料集安全性
如要在 BigQuery 中控管資料集存取權,請參閱「控管資料集存取權」。如要瞭解資料加密,請參閱「靜態加密」。
後續步驟
- 如要進一步瞭解如何列出專案中的資料集,請參閱列出資料集一文。
- 如要進一步瞭解資料集中繼資料,請參閱取得資料集相關資訊一文。
- 如要進一步瞭解如何變更資料集屬性,請參閱更新資料集。
- 如要進一步瞭解如何建立及管理標籤,請參閱建立及管理標籤。
歡迎試用
如果您未曾使用過 Google Cloud,歡迎建立帳戶,親自體驗實際使用 BigQuery 的成效。新客戶可以獲得價值 $300 美元的免費抵免額,可用於執行、測試及部署工作負載。
免費試用 BigQuery