Crear conjuntos de datos
En este documento se describe cómo crear conjuntos de datos en BigQuery.
Puede crear conjuntos de datos de las siguientes formas:
- Con la Google Cloud consola.
- Usando una consulta de SQL.
- Usando el comando
bq mken la herramienta de línea de comandos bq. - Llamar al método de API
datasets.insert. - Usar las bibliotecas de cliente.
- Copia de un conjunto de datos.
Para ver los pasos que debes seguir para copiar un conjunto de datos, incluso entre regiones, consulta Copiar conjuntos de datos.
En este documento se describe cómo trabajar con conjuntos de datos normales que almacenan datos en BigQuery. Para saber cómo trabajar con conjuntos de datos externos de Spanner, consulta Crear conjuntos de datos externos de Spanner. Para saber cómo trabajar con conjuntos de datos federados de AWS Glue, consulta Crear conjuntos de datos federados de AWS Glue.
Para aprender a consultar tablas de un conjunto de datos público, consulta Consulta un conjunto de datos público con la consola Google Cloud .
Limitaciones de los conjuntos de datos
Los conjuntos de datos de BigQuery están sujetos a las siguientes limitaciones:
- La ubicación del conjunto de datos solo se puede definir en el momento de la creación. Una vez creado un conjunto de datos, no se puede cambiar su ubicación.
- Todas las tablas a las que se haga referencia en una consulta deben almacenarse en conjuntos de datos de la misma ubicación.
Los conjuntos de datos externos no admiten la caducidad de tablas, las réplicas, el viaje en el tiempo, la ordenación predeterminada, el modo de redondeo predeterminado ni la opción de habilitar o inhabilitar los nombres de tabla que no distinguen entre mayúsculas y minúsculas.
Cuando copias una tabla, los conjuntos de datos que contienen la tabla de origen y la de destino deben estar en la misma ubicación.
Los nombres de los conjuntos de datos deben ser únicos en cada proyecto.
Si cambia el modelo de facturación del almacenamiento de un conjunto de datos, debe esperar 14 días para poder volver a cambiarlo.
No puedes registrar un conjunto de datos en la facturación del almacenamiento físico si tienes compromisos de slots de tarifa plana antiguos en la misma región que el conjunto de datos.
Antes de empezar
Concede roles de gestión de identidades y accesos (IAM) que proporcionen a los usuarios los permisos necesarios para realizar cada tarea de este documento.
Permisos obligatorios
Para crear un conjunto de datos, necesitas el permiso bigquery.datasets.create de gestión de identidades y accesos.
Cada uno de los siguientes roles de gestión de identidades y accesos predefinidos incluye los permisos que necesitas para crear un conjunto de datos:
roles/bigquery.dataEditorroles/bigquery.dataOwnerroles/bigquery.userroles/bigquery.admin
Para obtener más información sobre los roles de gestión de identidades y accesos en BigQuery, consulta el artículo sobre roles y permisos predefinidos.
Crear conjuntos de datos
Para crear un conjunto de datos, sigue estos pasos:
Consola
- Abre la página de BigQuery en la Google Cloud consola. Ir a la página de BigQuery
- En el panel Explorador, selecciona el proyecto en el que quieras crear el conjunto de datos.
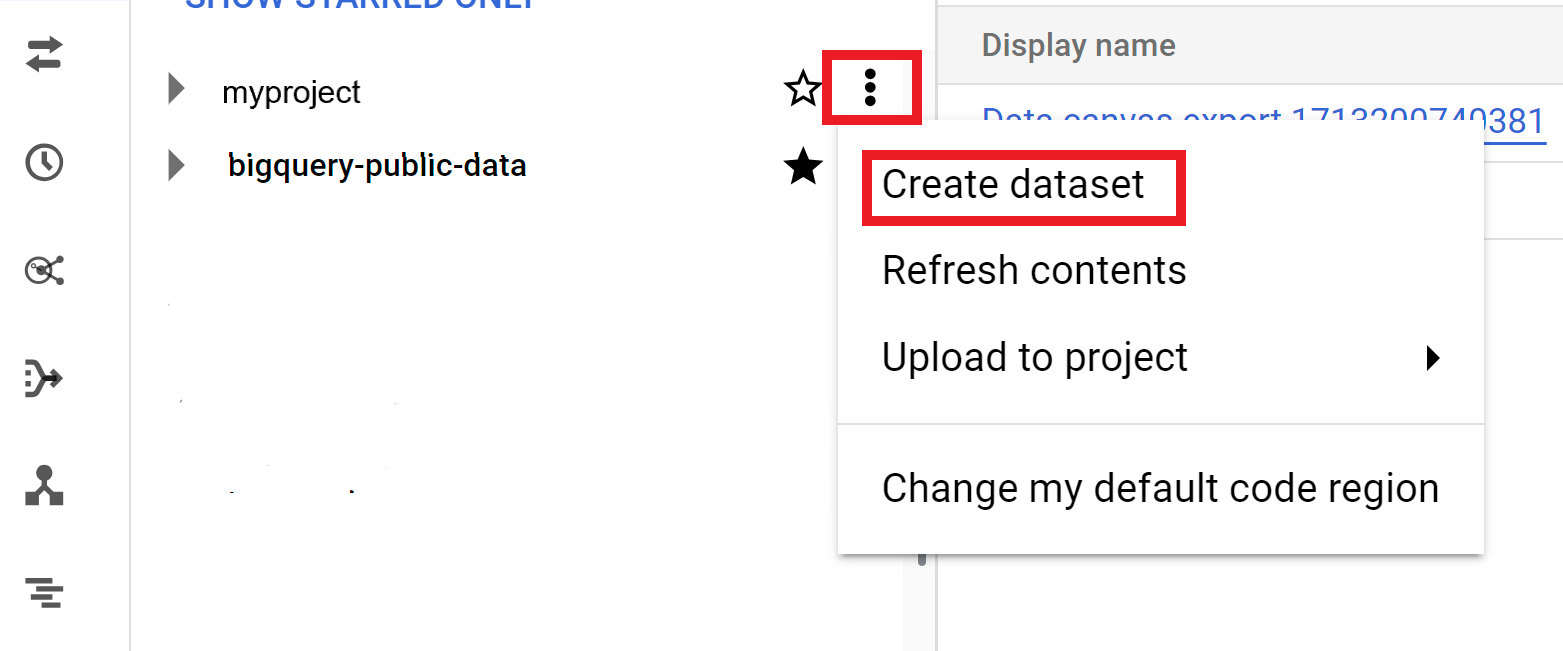
- Abre la opción Ver acciones y haz clic en Crear conjunto de datos.
- En la página Crear conjunto de datos, haz lo siguiente:
- En ID del conjunto de datos, introduce un nombre único para el conjunto de datos.
- En Tipo de ubicación, elija una ubicación geográfica para el conjunto de datos. Una vez creado el conjunto de datos, la ubicación no se puede cambiar.
- Opcional: Selecciona Enlazar con un conjunto de datos externo si vas a crear un conjunto de datos externo.
- Si no necesitas configurar opciones adicionales, como etiquetas y vencimientos de tablas, haz clic en Crear conjunto de datos. De lo contrario, despliega la sección siguiente para configurar las opciones adicionales del conjunto de datos.
- Opcional: Despliega la sección Etiquetas para añadir etiquetas a tu conjunto de datos.
- Para aplicar una etiqueta ya creada, sigue estos pasos:
- Haga clic en la flecha desplegable situada junto a Seleccionar ámbito y elija Ámbito actual > Seleccionar organización actual o Seleccionar proyecto actual.
- En Clave 1 y Valor 1, elige los valores adecuados de las listas.
- Para introducir manualmente una etiqueta nueva, sigue estos pasos:
- Haga clic en la flecha hacia abajo situada junto a Seleccionar un ámbito y elija Introducir IDs manualmente > Organización, Proyecto o Etiquetas.
- Si vas a crear una etiqueta para tu proyecto u organización, introduce el
PROJECT_IDo elORGANIZATION_IDen el cuadro de diálogo y, a continuación, haz clic en Guardar. - En Clave 1 y Valor 1, elige los valores adecuados de las listas.
- Para añadir más etiquetas a la tabla, haz clic en Añadir etiqueta y sigue los pasos anteriores.
- Opcional: Expanda la sección Opciones avanzadas para configurar una o varias de las siguientes opciones.
- Para cambiar la opción Encriptado y usar tu propia clave criptográfica con Cloud Key Management Service, selecciona Clave de Cloud KMS.
- Para usar nombres de tabla que no distinguen entre mayúsculas y minúsculas, selecciona Habilitar nombres de tabla que no distinguen entre mayúsculas y minúsculas.
- Para cambiar la especificación de la ordenación predeterminada, elige el tipo de ordenación en la lista.
- Para definir una fecha de vencimiento para las tablas del conjunto de datos, selecciona Habilitar vencimiento de tabla y, a continuación, especifica la Antigüedad máxima predeterminada de la tabla en días.
- Para definir un modo de redondeo predeterminado, elige el modo de redondeo de la lista.
- Para habilitar el modelo de facturación de almacenamiento físico, elige el modelo de facturación de la lista.
- Para definir el periodo de retroceso del conjunto de datos, elija el tamaño del periodo en la lista.
- Haz clic en Crear conjunto de datos.
Opciones adicionales para conjuntos de datos
También puedes hacer clic en Seleccionar ámbito para buscar un recurso o ver una lista de los recursos actuales.
Cuando cambias el modelo de facturación de un conjunto de datos, el cambio tarda 24 horas en aplicarse.
Una vez que cambies el modelo de facturación del almacenamiento de un conjunto de datos, tendrás que esperar 14 días para volver a cambiarlo.
SQL
Usa la instrucción CREATE SCHEMA.
Para crear un conjunto de datos en un proyecto que no sea el predeterminado, añade el ID del proyecto al ID del conjunto de datos con el siguiente formato: PROJECT_ID.DATASET_ID.
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, introduce la siguiente instrucción:
CREATE SCHEMA PROJECT_ID.DATASET_ID OPTIONS ( default_kms_key_name = 'KMS_KEY_NAME', default_partition_expiration_days = PARTITION_EXPIRATION, default_table_expiration_days = TABLE_EXPIRATION, description = 'DESCRIPTION', labels = [('KEY_1','VALUE_1'),('KEY_2','VALUE_2')], location = 'LOCATION', max_time_travel_hours = HOURS, storage_billing_model = BILLING_MODEL);
Haz los cambios siguientes:
PROJECT_ID: tu ID de proyectoDATASET_ID: ID del conjunto de datos que vas a crearKMS_KEY_NAME: el nombre de la clave predeterminada de Cloud Key Management Service que se usa para proteger las tablas recién creadas en este conjunto de datos, a menos que se proporcione otra clave en el momento de la creación. No puedes crear una tabla cifrada por Google en un conjunto de datos con este parámetro.PARTITION_EXPIRATION: el tiempo de vida predeterminado (en días) de las particiones de las tablas particionadas que se creen. La caducidad de la partición predeterminada no tiene ningún valor mínimo. La hora de vencimiento se evalúa como la fecha de la partición más el valor entero. Las particiones que se creen en una tabla particionada del conjunto de datos se eliminaránPARTITION_EXPIRATIONdías después de la fecha de la partición. Si proporciona la opcióntime_partitioning_expirational crear o actualizar una tabla con particiones, la fecha de vencimiento de la partición a nivel de tabla tendrá prioridad sobre la fecha de vencimiento de la partición predeterminada a nivel de conjunto de datos.TABLE_EXPIRATION: el tiempo de vida predeterminado (en días) de las tablas recién creadas. El valor mínimo es 0,042 días (una hora). La hora de vencimiento se calcula sumando el valor entero a la hora actual. Las tablas creadas en el conjunto de datos se eliminanTABLE_EXPIRATIONdías después de su creación. Este valor se aplica si no defines una caducidad de la tabla al crearla.DESCRIPTION: una descripción del conjunto de datosKEY_1:VALUE_1: el par clave-valor que quieras definir como la primera etiqueta de este conjunto de datos.KEY_2:VALUE_2: el par clave-valor que quieres definir como segunda etiqueta.LOCATION: la ubicación del conjunto de datos. Una vez creado el conjunto de datos, la ubicación no se puede cambiar.HOURS: la duración en horas de la ventana de viaje en el tiempo del nuevo conjunto de datos. El valor deHOURSdebe ser un número entero expresado en múltiplos de 24 (48, 72, 96, 120, 144 y 168) entre 48 (2 días) y 168 (7 días). Si no se especifica esta opción, el valor predeterminado es 168 horas.BILLING_MODEL: define el modelo de facturación del almacenamiento del conjunto de datos. Asigna el valorBILLING_MODELaPHYSICALpara usar bytes físicos al calcular los cargos de almacenamiento o aLOGICALpara usar bytes lógicos.LOGICALes el valor predeterminado.Cuando cambias el modelo de facturación de un conjunto de datos, el cambio tarda 24 horas en aplicarse.
Una vez que cambies el modelo de facturación del almacenamiento de un conjunto de datos, deberás esperar 14 días para volver a cambiarlo.
Haz clic en Ejecutar.
Para obtener más información sobre cómo ejecutar consultas, consulta Ejecutar una consulta interactiva.
bq
Para crear un conjunto de datos, usa el comando
bq mk
con la marca --location. Para ver una lista completa de los parámetros posibles, consulta la referencia del comando bq mk --dataset.
Para crear un conjunto de datos en un proyecto que no sea el predeterminado, añade el ID del proyecto al nombre del conjunto de datos con el siguiente formato: PROJECT_ID:DATASET_ID.
bq --location=LOCATION mk \ --dataset \ --default_kms_key=KMS_KEY_NAME \ --default_partition_expiration=PARTITION_EXPIRATION \ --default_table_expiration=TABLE_EXPIRATION \ --description="DESCRIPTION" \ --label=KEY_1:VALUE_1 \ --label=KEY_2:VALUE_2 \ --add_tags=KEY_3:VALUE_3[,...] \ --max_time_travel_hours=HOURS \ --storage_billing_model=BILLING_MODEL \ PROJECT_ID:DATASET_ID
Haz los cambios siguientes:
LOCATION: la ubicación del conjunto de datos. Una vez creado un conjunto de datos, no se puede cambiar su ubicación. Puedes definir un valor predeterminado para la ubicación mediante el archivo.bigqueryrc.KMS_KEY_NAME: el nombre de la clave predeterminada de Cloud Key Management Service que se usa para proteger las tablas recién creadas en este conjunto de datos, a menos que se proporcione otra clave en el momento de la creación. No puedes crear una tabla cifrada por Google en un conjunto de datos con este parámetro.PARTITION_EXPIRATION: el tiempo de vida predeterminado (en segundos) de las particiones de las tablas particionadas recién creadas. La partición predeterminada no tiene ningún valor mínimo de vencimiento. La hora de vencimiento se evalúa como la fecha de la partición más el valor entero. Las particiones que se creen en una tabla particionada del conjunto de datos se eliminaránPARTITION_EXPIRATIONsegundos después de la fecha de la partición. Si proporcionas la marca--time_partitioning_expirational crear o actualizar una tabla con particiones, la fecha de vencimiento de las particiones a nivel de tabla tendrá prioridad sobre la fecha de vencimiento de las particiones predeterminada a nivel de conjunto de datos.TABLE_EXPIRATION: el tiempo de vida predeterminado (en segundos) de las tablas recién creadas. El valor mínimo es de 3600 segundos (una hora). El tiempo de vencimiento se evalúa como la hora actual más el valor entero. Las tablas creadas en el conjunto de datos se eliminanTABLE_EXPIRATIONsegundos después de su creación. Este valor se aplica si no defines una fecha de vencimiento para la tabla al crearla.DESCRIPTION: una descripción del conjunto de datosKEY_1:VALUE_1: el par clave-valor que quieres definir como primera etiqueta de este conjunto de datos yKEY_2:VALUE_2: el par clave-valor que quieres definir como segunda etiqueta.KEY_3:VALUE_3: el par clave-valor que quiere definir como etiqueta en el conjunto de datos. Añade varias etiquetas con la misma marca separando los pares clave:valor con comas.HOURS: duración en horas del periodo de retroceso en el tiempo del nuevo conjunto de datos. El valor deHOURSdebe ser un número entero expresado en múltiplos de 24 (48, 72, 96, 120, 144 y 168) entre 48 (2 días) y 168 (7 días). Si no se especifica esta opción, el valor predeterminado es 168 horas.BILLING_MODEL: define el modelo de facturación del almacenamiento del conjunto de datos. Asigna el valorBILLING_MODELaPHYSICALpara usar bytes físicos al calcular los cargos de almacenamiento o aLOGICALpara usar bytes lógicos.LOGICALes el valor predeterminado.Cuando cambias el modelo de facturación de un conjunto de datos, el cambio tarda 24 horas en aplicarse.
Una vez que cambies el modelo de facturación del almacenamiento de un conjunto de datos, deberás esperar 14 días para volver a cambiarlo.
PROJECT_ID: tu ID de proyecto.DATASET_IDes el ID del conjunto de datos que vas a crear.
Por ejemplo, el siguiente comando crea un conjunto de datos llamado mydataset con la ubicación de los datos definida como US, un tiempo de vencimiento de tabla predeterminado de 3600 segundos (1 hora) y una descripción de This is my dataset. En lugar de usar la marca --dataset, el comando usa el acceso directo -d. Si omite -d y --dataset, el comando
creará un conjunto de datos de forma predeterminada.
bq --location=US mk -d \ --default_table_expiration 3600 \ --description "This is my dataset." \ mydataset
Para confirmar que se ha creado el conjunto de datos, introduce el comando bq ls. También puedes crear una tabla al crear un conjunto de datos con el siguiente formato: bq mk -t dataset.table.
Para obtener más información sobre cómo crear tablas, consulta el artículo Crear una tabla.
Terraform
Usa el recurso google_bigquery_dataset.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta Configurar la autenticación para bibliotecas de cliente.
Crear un conjunto de datos
En el siguiente ejemplo se crea un conjunto de datos llamado mydataset:
Cuando creas un conjunto de datos con el recurso google_bigquery_dataset, se concede automáticamente acceso al conjunto de datos a todas las cuentas que sean miembros de los roles básicos a nivel de proyecto.
Si ejecutas el comando terraform show después de crear el conjunto de datos, el bloque access del conjunto de datos tendrá un aspecto similar al siguiente:
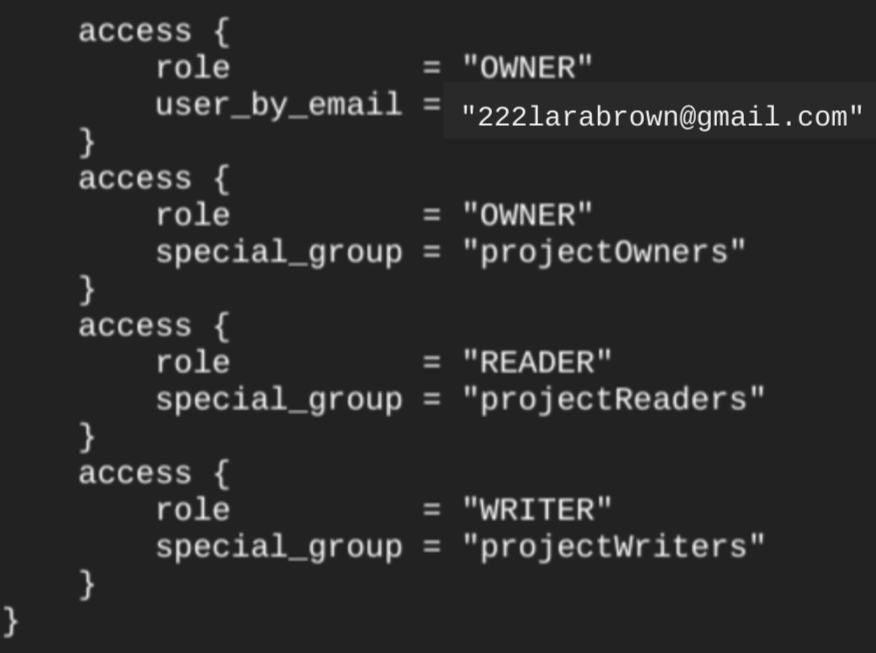
Para conceder acceso al conjunto de datos, le recomendamos que utilice uno de los google_bigquery_iamrecursos, como se muestra en el siguiente ejemplo, a menos que tenga previsto crear objetos autorizados, como vistas autorizadas, en el conjunto de datos.
En ese caso, usa el recurso google_bigquery_dataset_access. Consulta esa documentación para ver ejemplos.
Crear un conjunto de datos y conceder acceso a él
En el siguiente ejemplo se crea un conjunto de datos llamado mydataset y, a continuación, se usa el recurso google_bigquery_dataset_iam_policy para conceder acceso a él.
Crear un conjunto de datos con una clave de encriptado gestionada por el cliente
En el siguiente ejemplo se crea un conjunto de datos llamado mydataset y también se usan los recursos
google_kms_crypto_key
y
google_kms_key_ring
para especificar una clave de Cloud Key Management Service para el conjunto de datos. Para ejecutar este ejemplo, debes habilitar la API Cloud Key Management Service.
Para aplicar la configuración de Terraform en un proyecto, sigue los pasos que se indican en las siguientes secciones. Google Cloud
Preparar Cloud Shell
- Abre Cloud Shell.
-
Define el Google Cloud proyecto Google Cloud predeterminado en el que quieras aplicar tus configuraciones de Terraform.
Solo tiene que ejecutar este comando una vez por proyecto y puede hacerlo en cualquier directorio.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Las variables de entorno se anulan si defines valores explícitos en el archivo de configuración de Terraform.
Preparar el directorio
Cada archivo de configuración de Terraform debe tener su propio directorio (también llamado módulo raíz).
-
En Cloud Shell, crea un directorio y un archivo nuevo en ese directorio. El nombre del archivo debe tener la extensión
.tf. Por ejemplo,main.tf. En este tutorial, nos referiremos al archivo comomain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
Si estás siguiendo un tutorial, puedes copiar el código de ejemplo de cada sección o paso.
Copia el código de ejemplo en el archivo
main.tfque acabas de crear.También puedes copiar el código de GitHub. Se recomienda cuando el fragmento de Terraform forma parte de una solución integral.
- Revisa y modifica los parámetros de ejemplo para aplicarlos a tu entorno.
- Guarda los cambios.
-
Inicializa Terraform. Solo tienes que hacerlo una vez por directorio.
terraform init
Si quieres usar la versión más reciente del proveedor de Google, incluye la opción
-upgrade:terraform init -upgrade
Aplica los cambios
-
Revisa la configuración y comprueba que los recursos que va a crear o actualizar Terraform se ajustan a tus expectativas:
terraform plan
Haga las correcciones necesarias en la configuración.
-
Aplica la configuración de Terraform ejecutando el siguiente comando e introduciendo
yesen la petición:terraform apply
Espera hasta que Terraform muestre el mensaje "Apply complete!".
- Abre tu Google Cloud proyecto para ver los resultados. En la Google Cloud consola, ve a tus recursos en la interfaz de usuario para asegurarte de que Terraform los ha creado o actualizado.
API
Llama al método datasets.insert con un recurso de conjunto de datos definido.
C#
Antes de probar este ejemplo, sigue las C#instrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API C# de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Go
Antes de probar este ejemplo, sigue las Goinstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Go de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Java
Antes de probar este ejemplo, sigue las Javainstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Java de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Node.js
Antes de probar este ejemplo, sigue las Node.jsinstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Node.js de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
PHP
Antes de probar este ejemplo, sigue las PHPinstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API PHP de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Python
Antes de probar este ejemplo, sigue las Pythoninstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Python de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Ruby
Antes de probar este ejemplo, sigue las Rubyinstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Ruby de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Asignar nombres a los conjuntos de datos
Cuando creas un conjunto de datos en BigQuery, el nombre del conjunto de datos debe ser único en cada proyecto. El nombre del conjunto de datos puede incluir lo siguiente:
- Hasta 1024 caracteres.
- Letras (mayúsculas o minúsculas), números y guiones bajos.
Los nombres de los conjuntos de datos distinguen entre mayúsculas y minúsculas de forma predeterminada. mydataset y MyDataset pueden coexistir en el mismo proyecto, a menos que uno de ellos tenga desactivada la opción de distinguir entre mayúsculas y minúsculas. Para ver algunos ejemplos, consulta Crear un conjunto de datos que no distinga entre mayúsculas y minúsculas y Recurso: conjunto de datos.
Los nombres de los conjuntos de datos no pueden contener espacios ni caracteres especiales, como -, &, @ o %.
Conjuntos de datos ocultos
Un conjunto de datos oculto es un conjunto de datos cuyo nombre empieza por un guion bajo. Puedes consultar tablas y vistas de conjuntos de datos ocultos de la misma forma que lo harías en cualquier otro conjunto de datos. Los conjuntos de datos ocultos tienen las siguientes restricciones:
- Se ocultan en el panel Explorador de la consola de Google Cloud .
- No aparecen en ninguna
INFORMATION_SCHEMAvista. - No se pueden usar con conjuntos de datos vinculados.
- No se pueden usar como conjunto de datos de origen con los siguientes recursos autorizados:
- No aparecen en Data Catalog (obsoleto) ni en Dataplex Universal Catalog.
Seguridad de los conjuntos de datos
Para controlar el acceso a los conjuntos de datos en BigQuery, consulta el artículo Controlar el acceso a los conjuntos de datos. Para obtener información sobre el cifrado de datos, consulta el artículo Cifrado en reposo.
Siguientes pasos
- Para obtener más información sobre cómo enumerar conjuntos de datos en un proyecto, consulta Enumerar conjuntos de datos.
- Para obtener más información sobre los metadatos de los conjuntos de datos, consulta Obtener información sobre conjuntos de datos.
- Para obtener más información sobre cómo cambiar las propiedades de los conjuntos de datos, consulta el artículo Actualizar conjuntos de datos.
- Para obtener más información sobre cómo crear y gestionar etiquetas, consulta el artículo Crear y gestionar etiquetas.
Pruébalo
Si es la primera vez que utilizas Google Cloud, crea una cuenta para evaluar el rendimiento de BigQuery en situaciones reales. Los nuevos clientes también reciben 300 USD en crédito gratuito para ejecutar, probar y desplegar cargas de trabajo.
Probar BigQuery gratis