Visualizzare i grafici utilizzando BigQuery DataFrames
Questo documento mostra come tracciare vari tipi di grafici utilizzando la libreria di visualizzazione BigQuery DataFrames.
L'API bigframes.pandas
fornisce un ecosistema completo di strumenti per Python. L'API supporta operazioni statistiche avanzate e puoi visualizzare gli aggregati generati da BigQuery DataFrames. Puoi anche passare da
BigQuery DataFrames a un DataFrame pandas con operazioni di campionamento integrate.
Istogramma
L'esempio seguente legge i dati dalla tabella bigquery-public-data.ml_datasets.penguins
per tracciare un istogramma sulla distribuzione delle profondità del culmen dei pinguini:
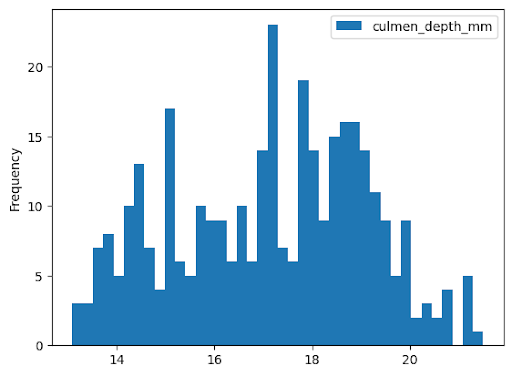
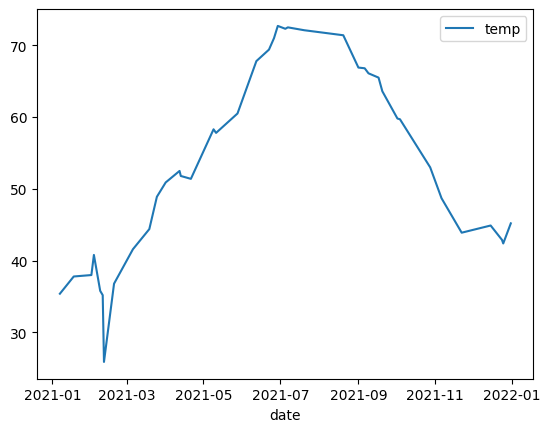
Grafico a linee
L'esempio seguente utilizza i dati della tabella bigquery-public-data.noaa_gsod.gsod2021
per tracciare un grafico a linee delle variazioni della temperatura media durante l'anno:
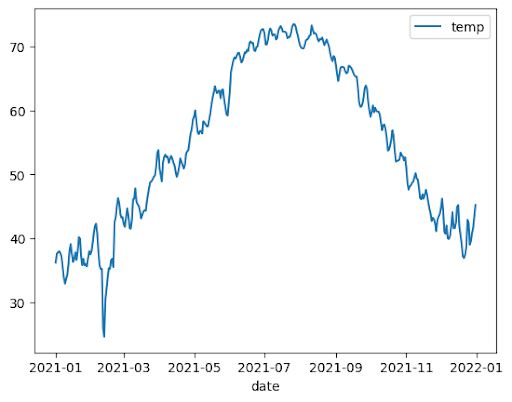
Grafico ad area
L'esempio seguente utilizza la tabella bigquery-public-data.usa_names.usa_1910_2013 per
monitorare la popolarità dei nomi nella storia degli Stati Uniti e si concentra sui nomi Mary, Emily
e Lisa:

Grafico a barre
L'esempio seguente utilizza la tabella bigquery-public-data.ml_datasets.penguins per visualizzare la distribuzione dei sessi dei pinguini:
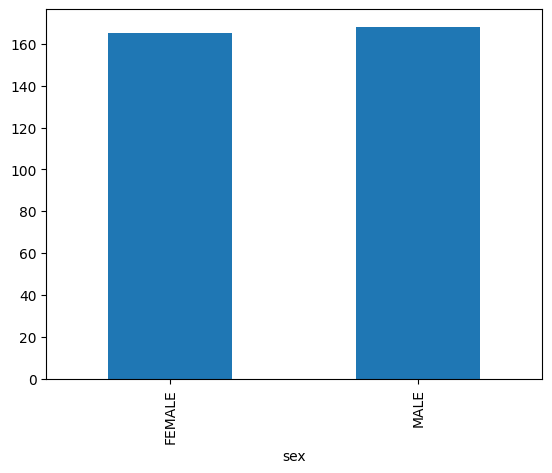
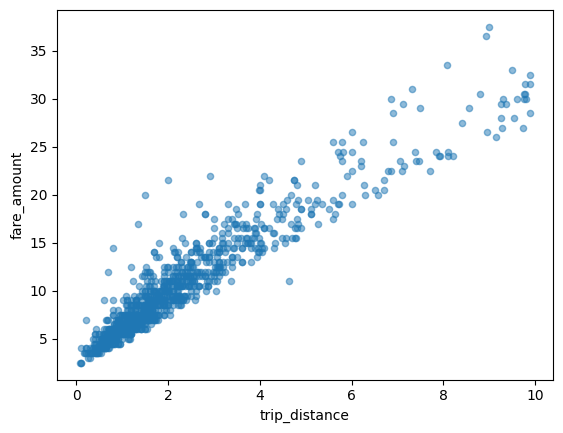
Grafico a dispersione
L'esempio seguente utilizza la tabella
bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2021 per
esplorare la relazione tra gli importi delle tariffe dei taxi e le distanze dei viaggi:
Visualizzare un set di dati di grandi dimensioni
BigQuery DataFrames scarica i dati sulla tua macchina locale per la visualizzazione. Per impostazione predefinita,il numero di punti dati da scaricare è limitato a 1000. Se il numero di punti dati supera il limite, BigQuery DataFrames campiona in modo casuale il numero di punti dati pari al limite.
Puoi eseguire l'override di questo limite impostando il parametro sampling_n durante la creazione
di un grafico, come mostrato nell'esempio seguente:
Grafici avanzati con i parametri di pandas e Matplotlib
Puoi passare più parametri per perfezionare il grafico come con pandas, perché la libreria di tracciamento di BigQuery DataFrames è basata su pandas e Matplotlib. Nelle sezioni seguenti vengono descritti alcuni esempi.
Tendenza di popolarità dei nomi con grafici secondari
Utilizzando i dati della cronologia dei nomi dell'esempio di grafico ad area, l'esempio seguente crea grafici individuali per ogni nome impostando subplots=True nella chiamata alla funzione plot.area():
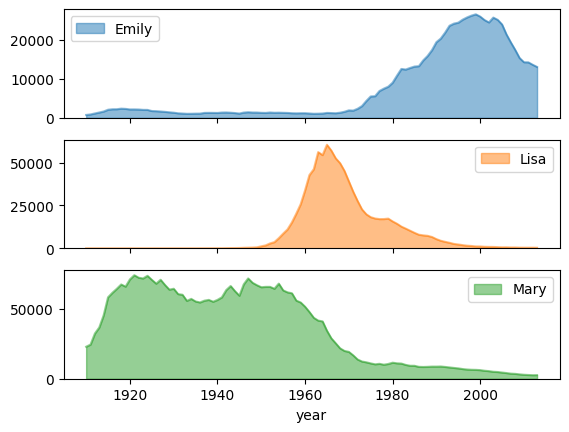
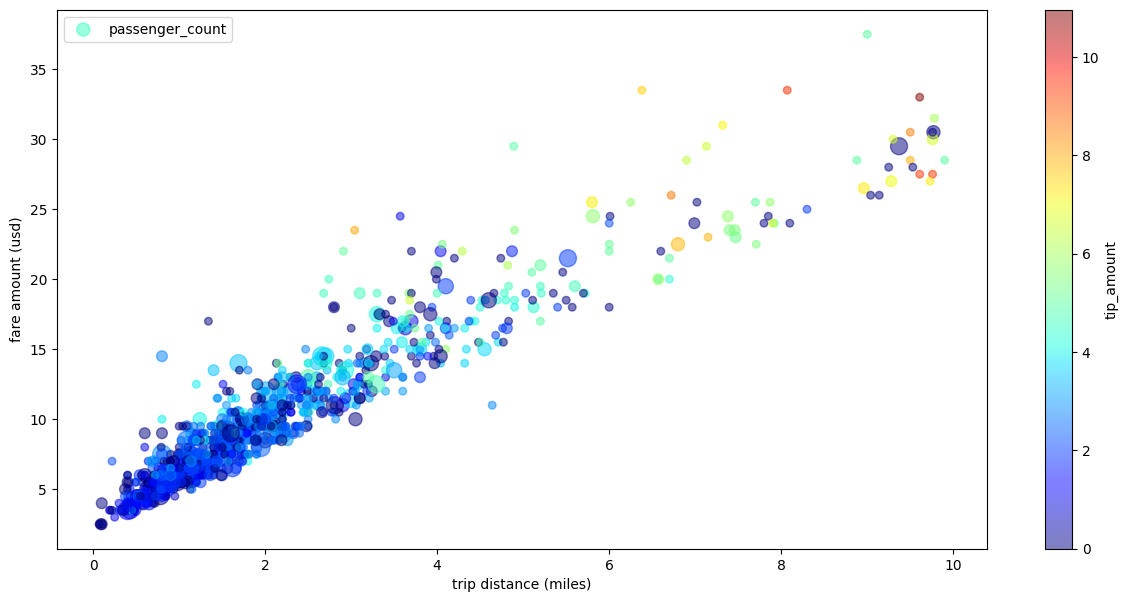
Grafico a dispersione dei viaggi in taxi con più dimensioni
Utilizzando i dati dell'esempio di grafico a dispersione, l'esempio seguente
rinomina le etichette per l'asse x e l'asse y, utilizza il parametro passenger_count
per le dimensioni dei punti, utilizza i punti colorati con il parametro tip_amount
e ridimensiona la figura:
Passaggi successivi
- Scopri come utilizzare BigQuery DataFrames.
- Scopri come utilizzare BigQuery DataFrames in dbt.
- Esplora il riferimento API BigQuery DataFrames.