Introduction to continuous queries
This document describes BigQuery continuous queries.
BigQuery continuous queries are SQL statements that run continuously. Continuous queries let you analyze incoming data in BigQuery in real time. You can insert the output rows produced by a continuous query into a BigQuery table or export them to Pub/Sub, Bigtable, or Spanner. Continuous queries can process data that has been written to standard BigQuery tables by using one of the following methods:
You can use continuous queries to perform time sensitive tasks, such as creating and immediately acting on insights, applying real time machine learning (ML) inference, and replicating data into other platforms. This lets you use BigQuery as an event-driven data processing engine for your application's decision logic.
The following diagram shows common continuous query workflows:
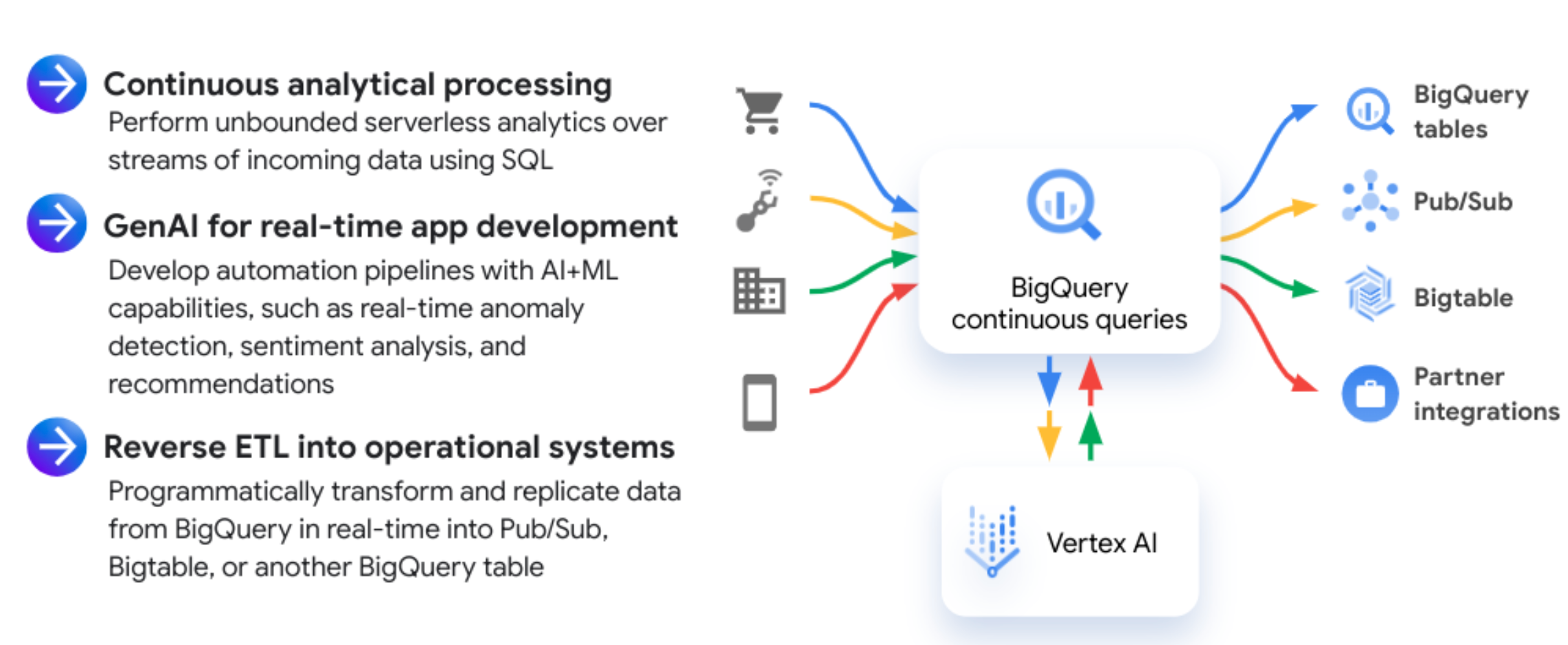
Use cases
Common use cases where you might want to use continuous queries are as follows:
- Personalized customer interaction services: use generative AI to create tailored messages customized for each customer interaction.
- Anomaly detection: build solutions that let you perform anomaly and threat detection on complex data in real time, so that you can react to issues more quickly.
- Customizable event-driven pipelines: use continuous query integration with Pub/Sub to trigger downstream applications based on incoming data.
- Data enrichment and entity extraction: use continuous queries to perform real time data enrichment and transformation by using SQL functions and ML models.
- Reverse extract-transform-load (ETL): perform real time reverse ETL into other storage systems more suited for low latency application serving. For example, analyzing or enhancing event data that is written to BigQuery, and then streaming it to Bigtable or Spanner for application serving.
Supported operations
The following operations are supported in continuous queries:
- Running
INSERTstatements to write data from a continuous query into a BigQuery table. Running
EXPORT DATAstatements to publish continuous query output to Pub/Sub topics. For more information, see Export data to Pub/Sub.From a Pub/Sub topic, you can use the data with other services, such as performing streaming analytics by using Dataflow, or using the data in an application integration workflow.
Running
EXPORT DATAstatements to export data from BigQuery to Bigtable tables. For more information, see Export data to Bigtable.Running
EXPORT DATAstatements to export data from BigQuery to Spanner tables. For more information, see Export data to Spanner (reverse ETL).Calling the following generative AI function:
This function requires you to have a BigQuery ML remote model over a Vertex AI model.
Calling the following AI functions:
These functions require you to have a BigQuery ML remote model over a Cloud AI API.
Normalizing numerical data by using the
ML.NORMALIZERfunction.Using stateless GoogleSQL functions—for example, conversion functions. In stateless functions, each row is processed independently from other rows in the table.
Using the
APPENDSchange history function to start continuous query processing from a specific point in time.
Authorization
The Google Cloud access tokens that are used when running continuous query jobs have a time to live (TTL) of two days when they are generated by a user account. Therefore, such jobs stop running after two days. The access tokens that are generated by service accounts can run longer, but must still adhere to the maximum query runtime. For more information, see Run a continuous query by using a service account.
Locations
Continuous queries are supported in the following locations:
| Region description | Region name | Details | |
|---|---|---|---|
| Americas | |||
| US multi-region | us |
||
| Dallas | us-south1 |
|
|
| Iowa | us-central1 |
|
|
| Los Angeles | us-west2 |
||
| Mexico | northamerica-south1 |
||
| Montréal | northamerica-northeast1 |
|
|
| Northern Virginia | us-east4 |
||
| Oregon | us-west1 |
|
|
| Salt Lake City | us-west3 |
||
| Santiago | southamerica-west1 |
|
|
| São Paulo | southamerica-east1 |
|
|
| South Carolina | us-east1 |
||
| Toronto | northamerica-northeast2 |
|
|
| Asia Pacific | |||
| Delhi | asia-south2 |
||
| Hong Kong | asia-east2 |
||
| Jakarta | asia-southeast2 |
||
| Melbourne | australia-southeast2 |
||
| Mumbai | asia-south1 |
||
| Osaka | asia-northeast2 |
||
| Seoul | asia-northeast3 |
||
| Singapore | asia-southeast1 |
||
| Sydney | australia-southeast1 |
||
| Taiwan | asia-east1 |
||
| Tokyo | asia-northeast1 |
||
| Europe | |||
| EU multi-region | eu |
||
| Belgium | europe-west1 |
|
|
| Berlin | europe-west10 |
||
| Finland | europe-north1 |
|
|
| Frankfurt | europe-west3 |
||
| London | europe-west2 |
|
|
| Madrid | europe-southwest1 |
|
|
| Milan | europe-west8 |
||
| Netherlands | europe-west4 |
|
|
| Paris | europe-west9 |
|
|
| Stockholm | europe-north2 |
|
|
| Turin | europe-west12 |
||
| Warsaw | europe-central2 |
||
| Zurich | europe-west6 |
|
|
| Middle East | |||
| Doha | me-central1 |
||
| Dammam | me-central2 |
||
| Tel Aviv | me-west1 |
||
| Africa | |||
| Johannesburg | africa-south1 |
||
Limitations
Continuous queries are subject to the following limitations:
- BigQuery continuous queries don't maintain the state of
ingested data. Common operations that rely on state, such as a
JOIN, aggregation function, or window function, aren't supported. You can't use the following SQL capabilities in a continuous query:
JOINoperations- Aggregate functions
- Approximate aggregate functions
The following query clauses:
The following query operators:
Query set operators
BigQuery ML functions other than those listed in Supported operations
Data manipulation language (DML) statements except for
INSERT.EXPORT DATAstatements that don't target Bigtable, Pub/Sub, or Spanner.
Continuous queries don't support processing Change Data Capture (CDC) upsert data.
Continuous queries don't support wildcard tables as a data source.
Continuous queries don't support external tables as a data source.
Continuous queries don't support INFORMATION_SCHEMA views as a data source.
Continuous queries don't support BigLake tables for Apache Iceberg in BigQuery.
Continuous queries don't support the following BigQuery security features:
When exporting data to Bigtable, you can only target Bigtable instances that fall within the same Google Cloud regional boundary as the BigQuery dataset that contains the table you are querying. For more information, see Location considerations. This restriction doesn't apply to exporting data to Pub/Sub because Pub/Sub is a global resource.
When exporting data to Bigtable, Spanner, or Pub/Sub locational endpoints you can only target Bigtable, Spanner, or Pub/Sub resources that fall within the same Google Cloud regional boundary as the BigQuery dataset that contains the table you are querying. This restriction doesn't apply when exporting data to Pub/Sub global endpoints.
You can't run a continuous query from a data canvas.
You can't modify the SQL used in a continuous query while the continuous query job is running. For more information, see Modify the SQL of a continuous query.
If a continuous query job falls behind in processing incoming data and has an output watermark lag of more than 48 hours, then it fails. You can run the query again and use the
APPENDSchange history function to resume processing from the point in time at which you stopped the previous continuous query job. For more information, see Start a continuous query from a particular point in time.A continuous query configured with a user account can run for up to two days. A continuous query configured with a service account can run for up to 150 days. When the maximum query runtime is reached, the query fails and stops processing incoming data.
Although continuous queries are built using BigQuery reliability features, occasional temporary issues can occur. Issues might lead to some amount of automatic reprocessing of your continuous query, which could result in duplicate data in the continuous query output. Design your downstream systems to handle such scenarios.
Reservation limitations
- You must create Enterprise edition or Enterprise Plus edition reservations in order to run continuous queries. Continuous queries don't support the on-demand compute billing model.
- When you create a
CONTINUOUSreservation assignment, the associated reservation is limited to at most 500 slots. You can request an increase to this limit by contacting bq-continuous-queries-feedback@google.com. - You can't create a reservation assignment that uses a different job type in the same reservation as a continuous query reservation assignment.
- You can't configure continuous query concurrency. BigQuery
automatically determines the number of continuous queries that can run
concurrently, based on available reservation assignments that use the
CONTINUOUSjob type. - When running multiple continuous queries using the same reservation, individual jobs might not split available resources fairly, as defined by BigQuery fairness.
Slots autoscaling
Continuous queries can use slot autoscaling to dynamically scale allocated capacity to accommodate your workload. As your continuous queries workload increases or decreases, BigQuery dynamically adjusts your slots.
After a continuous query starts running, it actively listens for incoming data, which consumes slot resources. While a reservation with a running continuous query does not scale down to zero slots, an idle continuous query that is primarily listening for incoming data is expected to consume a minimal amount of slots, typically around 1 slot.
Idle slot sharing
Continuous queries can use idle slot sharing to share unused slot resources with other reservations and job types.
- A
CONTINUOUSreservation assignment is still required to run a continuous query and can't solely rely on idle slots from other reservations. Thus aCONTINUOUSreservation assignment requires either a non-zero slot baseline or a non-zero slot autoscaling configuration. - Only idle baseline slots or committed slots from a
CONTINUOUSreservation assignment are sharable. Autoscaled slots aren't shareable as idle slots for other reservations.
Pricing
Continuous queries use
BigQuery capacity compute pricing,
which is measured in slots.
To run continuous queries, you must have a
reservation that uses the
Enterprise or Enterprise Plus edition,
and a reservation assignment
that uses the CONTINUOUS job type.
Usage of other BigQuery resources, such as data ingestion and storage, are charged at the rates shown in BigQuery pricing.
Usage of other services that receive continuous query results or that are called during continuous query processing are charged at the rates published for those services. For the pricing of other Google Cloud services used by continuous queries, see the following topics:
What's next
Try creating a continuous query.