継続的クエリの概要
このドキュメントでは、BigQuery の継続的クエリについて説明します。
BigQuery の継続的クエリは、継続的に実行される SQL ステートメントです。継続的クエリを使用すると、BigQuery で受信データをリアルタイムで分析できます。継続的クエリによって生成された出力行を BigQuery テーブルに挿入することも、Pub/Sub、Bigtable、または Spanner にエクスポートすることもできます。継続的クエリは、次のいずれかの方法で標準の BigQuery テーブルに書き込まれたデータを処理できます。
継続的クエリを使用すると、分析情報の作成と即時実行、リアルタイムの機械学習(ML)推論の適用、他のプラットフォームへのデータのレプリケーションなど、時間的制約のあるタスクを実行できます。これにより、アプリケーションの判断ロジックでイベント ドリブンのデータ処理エンジンとして BigQuery を使用できます。
次の図は、一般的な継続的クエリのワークフローを示しています。
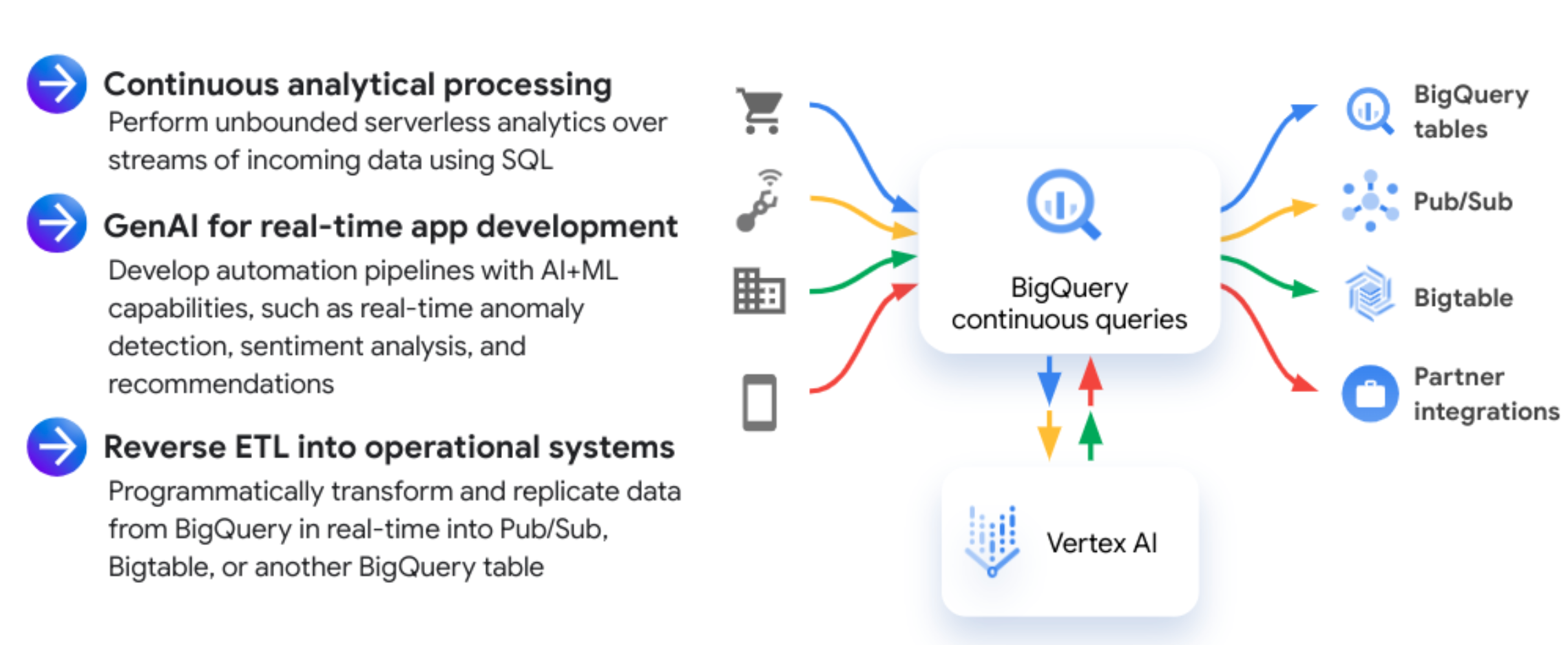
ユースケース
継続的クエリを使用する一般的なユースケースは次のとおりです。
- カスタマイズされた顧客対応: 生成 AI を使用して、顧客対応ごとにカスタマイズされたメッセージを作成します。
- 異常検出: 複雑なデータに対して異常と脅威をリアルタイムで検出できるソリューションを構築し、問題に迅速に対応できるようにします。
- カスタマイズ可能なイベント ドリブン パイプライン: Pub/Sub と継続的クエリを統合して、受信データに基づいてダウンストリーム アプリケーションをトリガーします。
- データの拡充とエンティティの抽出: 継続的クエリを使用して、SQL 関数と ML モデルを使用してリアルタイムでデータの拡充と変換を行います。
- リバース ETL(抽出 / 変換 / 読み込み): 低レイテンシのアプリケーション サービングに適した他のストレージ システムにリアルタイムのリバース ETL を実行します。たとえば、BigQuery に書き込まれたイベントデータを分析または拡充し、Bigtable または Spanner にストリーミングしてアプリケーション サービングを行うことができます。
サポートされているオペレーション
継続的クエリでは、次のオペレーションがサポートされています。
INSERTステートメントを実行して、継続的クエリから BigQuery テーブルにデータを書き込む。EXPORT DATAステートメントを実行して、Pub/Sub トピックに継続的クエリの出力をパブリッシュする。詳細については、Pub/Sub にデータをエクスポートするをご覧ください。Pub/Sub トピックから、Dataflow を使用してストリーミング分析を実行したり、アプリケーション統合ワークフローでデータを使用するなど、他のサービスでデータを使用できます。
EXPORT DATAステートメントを実行して、BigQuery から Bigtable テーブルにデータをエクスポートする。詳細については、Bigtable にデータをエクスポートするをご覧ください。EXPORT DATAステートメントを実行して、BigQuery から Spanner テーブルにデータをエクスポートする。詳細については、Spanner にデータをエクスポートする(リバース ETL)をご覧ください。次の生成 AI 関数を呼び出す。
この関数を使用するには、Vertex AI モデルを介して BigQuery ML リモートモデルを利用する必要があります。
次の AI 関数を呼び出す。
これらの関数を使用するには、Cloud AI API を介して BigQuery ML リモートモデルを利用する必要があります。
ML.NORMALIZER関数を使用して数値データを正規化する。ステートレスな GoogleSQL 関数(変換関数など)を使用する。ステートレス関数では、各行がテーブル内の他の行とは独立して処理されます。
APPENDS変更履歴関数を使用して、特定の時点から継続的クエリの処理を開始する。
認可
継続的クエリジョブの実行時に使用される Google Cloud アクセス トークンは、ユーザー アカウントによって生成された場合、有効期間(TTL)が 2 日間になります。そのため、このようなジョブは 2 日後に実行を停止します。サービス アカウントによって生成されたアクセス トークンはより長く実行できますが、それでも最大クエリ実行時間は遵守する必要があります。詳細については、サービス アカウントを使用して継続的クエリを実行するをご覧ください。
ロケーション
継続的クエリは、次のロケーションでサポートされています。
| リージョンの説明 | リージョン名 | 詳細 | |
|---|---|---|---|
| 南北アメリカ | |||
| 米国(マルチリージョン) | us |
||
| ダラス | us-south1 |
|
|
| アイオワ | us-central1 |
|
|
| ロサンゼルス | us-west2 |
||
| メキシコ | northamerica-south1 |
||
| モントリオール | northamerica-northeast1 |
|
|
| バージニア州北部 | us-east4 |
||
| オレゴン | us-west1 |
|
|
| ソルトレイクシティ | us-west3 |
||
| サンパウロ | southamerica-east1 |
|
|
| サウスカロライナ州 | us-east1 |
||
| トロント | northamerica-northeast2 |
|
|
| アジア太平洋 | |||
| デリー | asia-south2 |
||
| 香港 | asia-east2 |
||
| ジャカルタ | asia-southeast2 |
||
| メルボルン | australia-southeast2 |
||
| ムンバイ | asia-south1 |
||
| 大阪 | asia-northeast2 |
||
| ソウル | asia-northeast3 |
||
| シンガポール | asia-southeast1 |
||
| シドニー | australia-southeast1 |
||
| 台湾 | asia-east1 |
||
| 東京 | asia-northeast1 |
||
| ヨーロッパ | |||
| EU(マルチリージョン) | eu |
||
| ベルギー | europe-west1 |
||
| ベルリン | europe-west10 |
|
|
| フィンランド | europe-north1 |
|
|
| フランクフルト | europe-west3 |
||
| ロンドン | europe-west2 |
|
|
| マドリード | europe-southwest1 |
|
|
| ミラノ | europe-west8 |
||
| オランダ | europe-west4 |
|
|
| パリ | europe-west9 |
||
| ストックホルム | europe-north2 |
||
| トリノ | europe-west12 |
||
| ワルシャワ | europe-central2 |
||
| チューリッヒ | europe-west6 |
|
|
| 中東 | |||
| ドーハ | me-central1 |
||
| ダンマーム | me-central2 |
||
| テルアビブ | me-west1 |
||
| アフリカ | |||
| ヨハネスブルグ | africa-south1 |
||
制限事項
継続的クエリには、次の制限があります。
- BigQuery の継続的クエリは、取り込まれたデータの状態を維持しません。
JOIN、集計関数、ウィンドウ関数など、状態に依存する一般的なオペレーションはサポートされていません。 継続的クエリでは、次の SQL 機能は使用できません。
JOINオペレーション- 集計関数
- 近似集計関数
次のクエリ句:
次のクエリ演算子:
クエリの集合演算子
サポートされているオペレーションに記載されていない BigQuery ML 関数
データ操作言語(DML)ステートメント(
INSERTを除く)。Bigtable、Pub/Sub、Spanner をターゲットとしない
EXPORT DATAステートメント。
継続的クエリでは、変更データ キャプチャ(CDC)アップサート データの処理はサポートされていません。
継続的クエリでは、データソースとしてワイルドカード テーブルはサポートされていません。
継続的クエリでは、データソースとして外部テーブルはサポートされていません。
継続的クエリでは、データソースである INFORMATION_SCHEMA ビューはサポートされていません。
継続的クエリでは、BigQuery 内の Apache Iceberg 用 BigLake テーブルはサポートされていません。
継続的クエリは、次の BigQuery セキュリティ機能をサポートしていません。
Bigtable にデータをエクスポートする場合、クエリ対象のテーブルを含む BigQuery データセットと同じGoogle Cloud リージョン内にある Bigtable インスタンスにのみエクスポートできます。詳しくは、ロケーションに関する留意事項をご覧ください。Pub/Sub はグローバル リソースであるため、この制限は Pub/Sub へのデータのエクスポートには適用されません。
Bigtable、Spanner、または Pub/Sub ロケーション エンドポイントにデータをエクスポートする場合、クエリ対象のテーブルを含む BigQuery データセットと同じ Google Cloudリージョン境界内に存在する Bigtable、Spanner、または Pub/Sub のリソースのみをターゲットに設定できます。この制限は、Pub/Sub グローバル エンドポイントにデータをエクスポートする場合には適用されません。
データ キャンバスから継続的クエリを実行することはできません。
継続的クエリジョブの実行中は、継続的クエリで使用される SQL を変更できません。詳細については、継続的クエリの SQL を変更するをご覧ください。
継続的クエリジョブの受信データ処理が遅れて、出力ウォーターマークの遅延が 48 時間を超えると、ジョブは失敗します。クエリを再度実行し、
APPENDS変更履歴関数を使用して、以前の継続的クエリジョブを停止した時点から処理を再開できます。詳細については、特定の時点から継続的クエリを開始するをご覧ください。ユーザー アカウントを使用して構成された継続的クエリは、最大 2 日間実行できます。サービス アカウントを使用して構成された継続的クエリは、最大 150 日間実行できます。クエリの最大実行時間に達すると、クエリは失敗し、受信データの処理を停止します。
継続的クエリは BigQuery の信頼性機能を使用して構築されていますが、一時的な問題が発生することがあります。問題が発生すると、継続的クエリの自動再処理が実行され、継続的クエリの出力に重複データが生じる可能性があります。このような状況に対処するようにダウンストリーム システムを設計します。
予約の制限事項
- 継続的クエリを実行するには、Enterprise エディションまたは Enterprise Plus エディションの予約を作成する必要があります。継続的クエリは、オンデマンド コンピューティングの課金モデルをサポートしていません。
CONTINUOUS予約の割り当てを作成すると、関連する予約は最大 500 スロットに制限されます。この上限の引き上げをリクエストするには、bq-continuous-queries-feedback@google.com 宛てにメールをお送りください。- 継続的クエリの予約の割り当てでは、予約が共有するように構成されている場合でも、アイドル スロットは共有されません。
- 継続的クエリの予約割り当てと同じ予約で、異なるジョブタイプを使用する予約割り当てを作成することはできません。
- 継続的クエリの同時実行を構成することはできません。BigQuery は、
CONTINUOUSジョブタイプを使用する使用可能な予約割り当てに基づいて、同時に実行できる継続的クエリの数を自動的に決定します。 - 同じ予約を使用して複数の継続的クエリを実行すると、個々のジョブで使用可能なリソースが公平に分割されない場合があります(BigQuery の公平性を参照)。
スロットの自動スケーリング
継続的クエリでは、スロットの自動スケーリングを使用して、割り当てられた容量をワークロードに合わせて動的にスケーリングできます。継続的クエリのワークロードが増減すると、BigQuery はスロットを動的に調整します。
継続的クエリが実行を開始すると、受信データを積極的にリッスンし、スロット リソースが消費されます。継続的クエリが実行されている予約はゼロスロットにスケールダウンされませんが、主に受信データをリッスンしているアイドル状態の継続的クエリは、通常 1 スロット程度の最小限のスロットを消費します。
料金
継続的クエリでは、スロットで測定される BigQuery 容量コンピューティングの料金が使用されます。継続的クエリを実行するには、Enterprise エディションまたは Enterprise Plus エディションを使用する予約と、CONTINUOUS ジョブタイプを使用する予約割り当てが必要です。
データの取り込みやストレージなど、他の BigQuery リソースの使用量は、BigQuery の料金に記載されている料金で課金されます。
継続的クエリの結果を受け取るサービス、または継続的クエリの処理中に呼び出されるサービスの使用量は、そのサービスに公開されている料金で課金されます。継続的クエリで使用される他の Google Cloud サービスの料金については、次のトピックをご覧ください。
次のステップ
継続的クエリを作成してみる。