Einführung in die Zugriffssteuerung auf Spaltenebene
BigQuery bietet mithilfe von Richtlinien-Tags oder der typbasierten Klassifizierung von Daten differenzierten Zugriff auf vertrauliche Spalten. Mit der BigQuery-Zugriffssteuerung auf Spaltenebene können Sie Richtlinien erstellen, mit denen zum Zeitpunkt der Abfrage überprüft wird, ob ein Nutzer den entsprechenden Zugriff hat. Eine Richtlinie kann beispielsweise Zugriffsprüfungen wie die folgende erzwingen:
- Sie müssen sich in
group:high-accessbefinden, um die Spalten zu sehen, dieTYPE_SSNenthalten.
Zur Verbesserung der Zugriffssteuerung auf Spaltenebene können Sie optional die dynamische Datenmaskierung verwenden. Mit der Datenmaskierung können Sie sensible Daten maskieren, indem Sie anstelle des tatsächlichen Werts der Spalte Null-, Standard- oder Hash-Inhalte ersetzen.
Workflow zur Zugriffssteuerung auf Spaltenebene

So schränken Sie den Datenzugriff auf Spaltenebene ein:
Definieren Sie Taxonomie und Richtlinien-Tags. Erstellen und verwalten Sie Taxonomie und Richtlinien-Tags für Ihre Daten. Weitere Informationen finden Sie unter Best Practices für Richtlinien-Tags.
Weisen Sie Ihren BigQuery-Spalten Richtlinien-Tags zu. Verwenden Sie in BigQuery Schemaanmerkungen, um jeder Spalte, auf die Sie den Zugriff einschränken möchten, ein Richtlinien-Tag zuzuweisen.
Zugriffssteuerung für die Taxonomie erzwingen Durch das Erzwingen der Zugriffssteuerung werden die für alle Richtlinien-Tags in der Taxonomie definierten Zugriffsbeschränkungen angewendet.
Verwalten Sie den Zugriff auf die Richtlinien-Tags. Mit IAM-Richtlinien (Identity and Access Management) können Sie den Zugriff auf die einzelnen Richtlinien-Tags einschränken. Die Richtlinie gilt für jede Spalte, die zum Richtlinien-Tag gehört.
Wenn ein Nutzer versucht, zum Abfragezeitpunkt auf Spaltendaten zuzugreifen, überprüft BigQuery anhand des Spaltenrichtlinien-Tags und der zugehörigen Richtlinie, ob der Nutzer berechtigt ist, auf die Daten zuzugreifen.
Bestimmen, welche Tags getaggt werden sollen
Um festzustellen, welche Arten von sensiblen Daten Sie haben und welche Spalten Richtlinien-Tags benötigen, sollten Sie mithilfe des Schutzes sensibler Daten Profile über Ihre Daten in einer Organisation, einem Ordner oder einem Projekt erstellen. Datenprofile enthalten Messwerte und Metadaten zu Ihren Tabellen und können ermitteln, wo sich sensible und risikoreiche Daten befinden. Der Schutz sensibler Daten meldet diese Messwerte auf Projekt-, Tabellen- und Spaltenebene. Weitere Informationen finden Sie unter Datenprofile für BigQuery-Daten.
Die folgende Abbildung zeigt eine Liste der Spaltendatenprofile (zum Vergrößern anklicken). Spalten mit Hochrisiko-Datenwerten können Daten mit hoher Sensibilität enthalten und haben keine Zugriffssteuerung auf Spaltenebene. Alternativ können diese Spalten Daten mit moderater Sensibilität oder Daten mit hoher Sensibilität enthalten, die für eine große Anzahl von Personen zugänglich sind.

Anwendungsbeispiel
Stellen Sie sich eine Organisation vor, die vertrauliche Daten in zwei Kategorien einteilen muss: Hoch und Mittel.
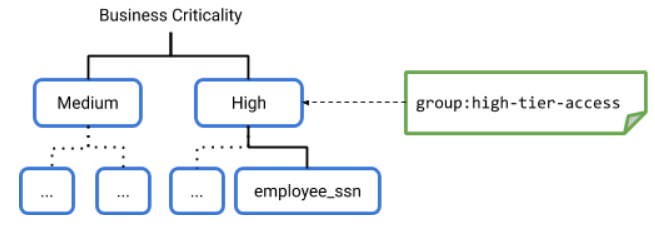
Zum Einrichten der Sicherheit auf Spaltenebene würde eine Datensicherung, die die entsprechenden Berechtigungen hat, die folgenden Schritte ausführen, um eine Hierarchie der Datenklassifizierung einzurichten.
Im Datenabgleich wird eine Taxonomie namens "Geschäftskritisch" erstellt. Diese umfasst die Knoten oder Richtlinien-Tags Hoch und Mittel.
Die Richtlinie bestimmt, welche Richtlinie für den Knoten Hoch für die Gruppe high-tier-access übernommen wird.
Die Datensicherung erstellt mehr Knotenebenen in der Taxonomie unter Hoch und Mittel. Der niedrigste Knoten ist ein Blattknoten, z. B. der Blattknoten employee_ssn. Die Datensicherung kann für den Blattknoten employee_ssn eine andere Zugriffsrichtlinie erstellen.
Durch den Datenabgleich wird ein Richtlinien-Tag bestimmten Tabellenspalten zugewiesen. In diesem Beispiel weist die Datensicherung die Zugriffsrichtlinie High der Spalte employee_ssn in einer Tabelle zu.
Auf der Seite Aktuelles Schema der Console können Datennutzer das Richtlinien-Tag sehen, das eine bestimmte Spalte regelt. In diesem Beispiel befindet sich die Spalte employee_ssn unter dem Richtlinien-Tag Hoch. Wenn Sie also das Schema für employee_ssn aufrufen, zeigt die Console den Namen der Taxonomie und das Richtlinien-Tag
Policy tagsim FeldBusiness criticality:Highan.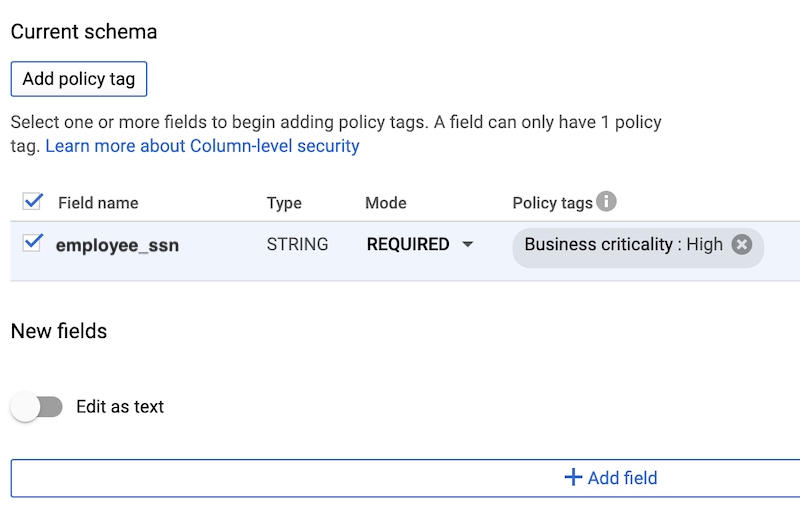
Weitere Informationen zum Festlegen eines Richtlinien-Tags in der Console finden Sie unter Richtlinien-Tag für eine Spalte festlegen.
Alternativ können Sie das Richtlinien-Tag mit dem Befehl
bq updatefestlegen. Das FeldnamesvonpolicyTagsenthält die ID des Richtlinien-Tags Hoch,projects/project-id/locations/location/taxonomies/taxonomy-id/policyTags/policytag-id:[ ... { "name": "ssn", "type": "STRING", "mode": "REQUIRED", "policyTags": { "names": ["projects/project-id/locations/location/taxonomies/taxonomy-id/policyTags/policytag-id"] } }, ... ]
Weitere Informationen zum Festlegen eines Richtlinien-Tags mit dem Befehl
bq updatefinden Sie unter Richtlinien-Tag für eine Spalte festlegen.Der Administrator führt ähnliche Schritte für das Richtlinien-Tag Mittel aus.
Mit nur wenigen Richtlinien-Tags für die Datenklassifizierung lässt sich so ein detaillierter Zugriff auf viele Spalten verwalten.
Weitere Informationen zu diesen Schritten finden Sie unter Zugriff mit Zugriffssteuerung auf Spaltenebene beschränken.
Rollen mit Zugriffssteuerung auf Spaltenebene
Die folgenden Rollen werden für die BigQuery-Zugriffssteuerung auf Spaltenebene verwendet.
Die Data Catalog-Rolle "Richtlinien-Tag-Administrator" ist für Nutzer erforderlich, die Taxonomien und Richtlinien-Tags erstellen und verwalten müssen.
| Rolle/ID | Berechtigungen | Beschreibung |
|---|---|---|
Data Catalog-Richtlinien-Tag-Administrator/datacatalog.categoryAdmin
|
datacatalog.categories.getIamPolicydatacatalog.categories.setIamPolicydatacatalog.taxonomies.createdatacatalog.taxonomies.deletedatacatalog.taxonomies.getdatacatalog.taxonomies.getIamPolicydatacatalog.taxonomies.listdatacatalog.taxonomies.setIamPolicydatacatalog.taxonomies.updateresourcemanager.projects.getresourcemanager.projects.list
|
Gilt auf Projektebene. Diese Rolle berechtigt zu Folgendem:
|
Die Rolle „Administrator für BigQuery-Datenrichtlinien“, die Rolle „BigQuery-Administrator“ oder die Rolle „BigQuery-Dateninhaber“ ist zum Erstellen und Verwalten von Datenrichtlinien erforderlich. Wenn Sie dieGoogle Cloud Console zur Durchsetzung der Zugriffssteuerung für eine Taxonomie verwenden, erstellt der Dienst automatisch eine Datenrichtlinie für Sie.
| Rolle/ID | Berechtigungen | Beschreibung |
|---|---|---|
Administrator der BigQuery-Datenrichtlinie/bigquerydatapolicy.admin BigQuery-Administrator/ bigquery.admin BigQuery-Dateninhaber/ bigquery.dataOwner
|
bigquery.dataPolicies.createbigquery.dataPolicies.deletebigquery.dataPolicies.getbigquery.dataPolicies.getIamPolicybigquery.dataPolicies.listbigquery.dataPolicies.setIamPolicybigquery.dataPolicies.update
|
Die Berechtigungen Diese Rolle berechtigt zu Folgendem:
|
datacatalog.taxonomies.get, die Sie von mehreren vordefinierten Rollen in Data Catalog erhalten können.
Die Rolle "Detaillierter Lesezugriff für Data Catalog" ist für Nutzer erforderlich, die Zugriff auf Daten in gesicherten Spalten benötigen.
| Rolle/ID | Berechtigungen | Beschreibung |
|---|---|---|
Detaillierter Lesezugriff/datacatalog.categoryFineGrainedReader
|
datacatalog.categories.fineGrainedGet |
Gilt auf der Ebene des Richtlinien-Tags. Diese Rolle berechtigt zum Zugriff auf den Inhalt von Spalten, die durch ein Richtlinien-Tag eingeschränkt sind. |
Weitere Informationen zu Data Catalog-Rollen finden Sie unter Data Catalog Identity and Access Management (IAM). Weitere Informationen zu BigQuery-Rollen finden Sie unter Zugriffssteuerung mit IAM.
Schreibvorgänge und ihre Auswirkungen
Zum Lesen der Daten einer Spalte, die durch die Zugriffssteuerung auf Spaltenebene geschützt ist, benötigt der Nutzer immer die Leseberechtigung der Richtlinien-Tags für die Spalte, die über den detaillierten Lesezugriff bereit gestellt wird.
Das gilt für:
- Tabellen, einschließlich Platzhaltertabellen
- Ansichten
- Tabellen kopieren
Wenn ein Nutzer Daten in die Zeile einer Spalte schreiben möchte, die durch die Zugriffssteuerung auf Spaltenebene geschützt ist, hängt es von der Art des Schreibvorgangs ab, welche Berechtigung er benötigt.
Wenn der Schreibvorgang das Einfügen beinhaltet, ist kein detaillierter Lesezugriff erforderlich. Der Nutzer hat in diesem Fall jedoch keinen Lesezugriff auf die eingefügten Daten, es sei denn, er verfügt über einen detaillierten Lesezugriff.
Wenn ein Nutzer eine INSERT SELECT-Anweisung ausführt, ist die Rolle "detaillierter Lesezugriff" für die abgefragte Tabelle erforderlich.
Wenn der Schreibvorgang ein Aktualisieren, ein Löschen oder ein Zusammenführen umfasst, kann der Nutzer den Vorgang nur ausführen, wenn er detaillierten Lesezugriff auf die Lesespalten hat.
Ein Nutzer kann Daten aus lokalen Dateien oder aus Cloud Storage laden. Beim Laden von Daten in eine Tabelle prüft BigQuery die detaillierte Berechtigung für die Spalten der Zieltabelle nicht. Der Grund dafür ist, dass beim Laden von Daten das Lesen von Inhalten aus der Zieltabelle nicht erforderlich ist. Ein Nutzer kann jedoch Daten aus Streams laden, da Richtlinien-Tags von den Streaming-Ladevorgängen nicht überprüft werden. Der Nutzer hat keinen Lesezugriff auf Daten, die aus einem Stream geladen wurden, es sei denn, er verfügt über detaillierten Lesezugriff.
Weitere Informationen finden Sie unter Auswirkungen auf Schreibvorgänge mit Zugriffssteuerung auf Spaltenebene.
Tabellen abfragen
Wenn ein Nutzer Zugriff auf Datasets und die Data Catalog-Rolle "Detaillierter Lesezugriff" hat, sind die Spaltendaten für den Nutzer verfügbar. Der Nutzer führt dann wie gewohnt eine Abfrage aus.
Wenn ein Nutzer Zugriff auf Datasets hat, aber nicht die Data Catalog-Rolle "Detaillierter Lesezugriff", sind die Spaltendaten für den Nutzer nicht verfügbar. Wenn dieser SELECT * ausführt, wird eine Fehlermeldung zurückgegeben, in der die Spalten aufgelistet sind, auf die er nicht zugreifen kann. Diesen Fehler können Sie so beheben:
Ändern Sie die Abfrage so, dass die Spalten ausgeschlossen sind, auf die der Nutzer nicht zugreifen kann. Wenn der Nutzer beispielsweise keinen Zugriff auf die Spalte
ssn, aber Zugriff auf die übrigen Spalten hat, kann er folgende Abfrage ausführen:SELECT * EXCEPT (ssn) FROM ...
Im vorherigen Beispiel wird mit der Klausel
EXCEPTdie Spaltessnausgeschlossen.Bitten Sie einen Data Catalog-Administrator, den Nutzer zusammen mit der Data Catalog-Rolle "Detaillierter Lesezugriff" der entsprechenden Datenklasse hinzuzufügen. Die Fehlermeldung enthält den vollständigen Namen des Richtlinien-Tags, für das der Nutzer Zugriffsrechte benötigt.
Abfrageansichten
Die Auswirkung der Sicherheit auf Spaltenebene im Hinblick auf eine Datenansicht ist unabhängig davon, ob es sich dabei um eine autorisierte Datenansicht handelt. In beiden Fällen wird die Sicherheit auf Spaltenebene transparent erzwungen.
Eine autorisierte Ansicht ist eine der folgenden:
- Eine Ansicht, die explizit für den Zugriff auf die Tabellen in einem Dataset autorisiert ist.
- Eine Ansicht, die implizit für den Zugriff auf die Tabellen in einem Dataset autorisiert ist, da sie in einem autorisierten Dataset enthalten ist.
Weitere Informationen finden Sie unter Autorisierte Ansichten und Autorisierte Datasets.
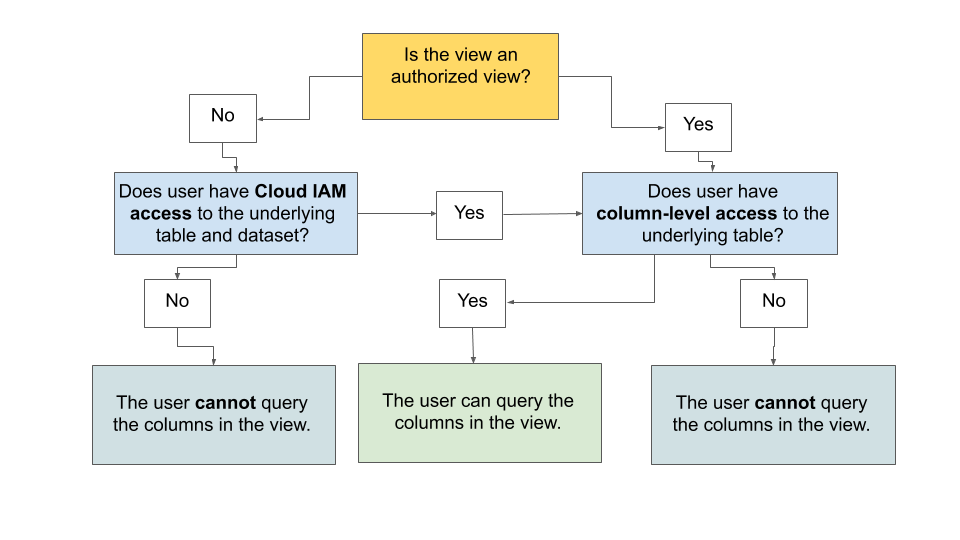
Keine autorisierte Ansicht:
Wenn der Nutzer über IAM-Zugriff auf die der Ansicht zugrunde liegenden Tabellen und das Dataset sowie über Zugriff auf Spaltenebene auf die der Ansicht zugrunde liegenden Tabellen verfügt, kann der Nutzer die Spalten in der Ansicht abfragen. Andernfalls kann er die Spalten in der Ansicht nicht abfragen.
Autorisierte Ansicht:
Nur die Sicherheit auf Spaltenebene für die Spalten in den zugrunde liegenden Tabellen der Ansicht steuert den Zugriff. IAM-Richtlinien auf Tabellen- und Dataset-Ebene werden nicht zum Prüfen des Zugriffs verwendet. Wenn der Nutzer Zugriff auf die Richtlinien-Tags hat, die in den zugrunde liegenden Tabellen der autorisierten Ansicht verwendet werden, kann er die Spalten in der autorisierten Ansicht abfragen.
Das folgende Diagramm zeigt, wie der Zugriff auf eine Ansicht bewertet und entschieden wird.
Auswirkungen von Zeitreisen und materialisierten Ansichten mit „max_saltness“
Mit BigQuery können Sie eine Tabelle in einem früheren Zustand abfragen. Mit dieser Funktion können Sie die Zeilen ab einem vorherigen Zeitpunkt abfragen. Außerdem können Sie damit eine Tabelle zu einem bestimmten Zeitpunkt wiederherstellen.
In Legacy-SQL fragen Sie Verlaufsdaten mithilfe von Zeit-Decorators für den Tabellennamen ab. In GoogleSQL fragen Sie Verlaufsdaten mithilfe der Klausel FOR SYSTEM_TIME AS OF für die Tabelle ab.
Materialisierte Ansichten mit der Option max_staleness geben Verlaufsdaten aus ihrem Veralterungsintervall zurück. Dieses Verhalten ähnelt einer Abfrage mit FOR SYSTEM_TIME AS OF zum Zeitpunkt der letzten Aktualisierung der Ansicht. BigQuery kann dadurch Datensätze abfragen, die gelöscht oder aktualisiert wurden.
Angenommen, Sie fragen die Verlaufsdaten einer Tabelle zur Zeit t ab. In diesem Fall gehen Sie so vor:
Wenn das Schema zum Zeitpunkt t mit dem aktuellen Schema der Tabelle oder mit einem Teil davon übereinstimmt, prüft BigQuery auf die neueste Sicherheit auf Spaltenebene für die aktuelle Tabelle. Wenn der Nutzer die aktuellen Spalten lesen darf, kann er die Verlaufsdaten dieser Spalten abfragen. Um sensible Daten von Spalten zu löschen oder zu maskieren, die durch die Sicherheit auf Spaltenebene geschützt sind, kann die Sicherheit auf Spaltenebene erst dann sicher aufgehoben werden, wenn das konfigurierte Zeitfenster seit der Bereinigung der sensiblen Daten verstrichen ist.
Wenn sich das Schema zum Zeitpunkt t vom aktuellen Schema für die Spalten in der Abfrage unterscheidet, schlägt die Abfrage fehl.
Überlegungen zum Standort
Beachten Sie die folgenden Einschränkungen, wenn Sie einen Standort für Ihre Taxonomie auswählen.
Richtlinien-Tags
Taxonomien sind regionale Ressourcen wie BigQuery-Datasets und -Tabellen. Wenn Sie eine Taxonomie erstellen, geben Sie die Region oder den Standort für die Taxonomie an.
Sie können eine Taxonomie erstellen und Richtlinien-Tags auf Tabellen in allen Regionen anwenden, in denen BigQuery verfügbar ist. Wenn Sie jedoch Richtlinien-Tags aus einer Taxonomie auf eine Tabellenspalte anwenden möchten, muss sich die Taxonomie und die Tabelle am selben regionalen Standort befinden.
Sie können zwar kein Richtlinien-Tag auf eine Tabellenspalte anwenden, die sich an einem anderen Standort befindet, aber Sie können die Taxonomie an einen anderen Standort kopieren, indem Sie sie dort explizit replizieren.
Wenn Sie dieselbe Taxonomie und Richtlinien-Tags für mehrere regionale Standorte verwenden möchten, finden Sie weitere Informationen zum Replizieren von Taxonomien unter Richtlinien für verschiedene Standorte verwalten.
Organisationen
Referenzen können nicht organisationsübergreifend verwendet werden. Eine Tabelle und alle Richtlinien-Tags, die Sie auf Spalten anwenden möchten, müssen in derselben Organisation vorhanden sein.
Beschränkungen
Dieses Feature ist möglicherweise nicht verfügbar, wenn Sie Reservierungen verwenden, die mit bestimmten BigQuery-Editionen erstellt wurden. Weitere Informationen dazu, welche Features in den einzelnen Editionen aktiviert sind, finden Sie unter Einführung in BigQuery-Editionen.
BigQuery unterstützt nur die Zugriffssteuerung auf Spaltenebene für BigLake-Tabellen, BigQuery-Tabellen und BigQuery Omni-Tabellen.
Wenn Sie in eine Zieltabelle überschreiben, werden alle vorhandenen Richtlinien-Tags aus der Tabelle entfernt, es sei denn, Sie verwenden das Flag
--destination_schema, um ein Schema mit Richtlinien-Tags anzugeben. Das folgende Beispiel zeigt, wie--destination_schemaverwendet wird.bq query --destination_table mydataset.mytable2 \ --use_legacy_sql=false --destination_schema=schema.json \ 'SELECT * FROM mydataset.mytable1'Schemaänderungen erfolgen in einem anderen Vorgang als der Abfrageausführung. Wenn Sie Abfrageergebnisse mit dem Flag
--destination_tablein eine Tabelle schreiben und die Abfrage anschließend eine Ausnahme auslöst, werden alle Schemaänderungen möglicherweise übersprungen. Prüfen Sie in diesem Fall das Zieltabellenschema und aktualisieren Sie es manuell, falls erforderlich.Eine Spalte kann nur ein Richtlinien-Tag haben.
Eine Tabelle kann höchstens 1.000 einzelne Richtlinien-Tags enthalten.
Sie können Legacy-SQL nicht verwenden, wenn Sie die Zugriffssteuerung auf Spaltenebene aktiviert haben. Alle Legacy-SQL-Abfragen werden abgelehnt, wenn die Zieltabellen Richtlinien-Tags enthalten.
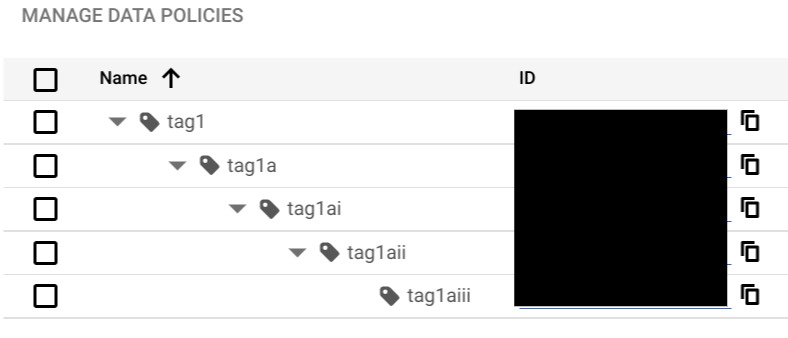
Eine Richtlinien-Tag-Hierarchie darf nicht mehr als fünf Ebenen vom Stammknoten bis zum untersten Untertag tief sein, wie im folgenden Screenshot dargestellt:
Taxonomienamen müssen in allen Projekten innerhalb einer Organisation eindeutig sein.
Sie können eine Tabelle nicht regionenübergreifend kopieren, wenn Sie die Zugriffssteuerung auf Spalten- oder Zeilenebene aktiviert haben. Alle Kopien von Tabellen in den verschiedenen Regionen werden abgelehnt, wenn die Quelltabellen Richtlinien-Tags enthalten.
Preise
Für die Zugriffssteuerung auf Spaltenebene ist sowohl BigQuery als auch Data Catalog erforderlich. Preisinformationen zu diesen Produkten finden Sie in den folgenden Themen:
Audit-Logging
Wenn Tabellendaten mit Richtlinien-Tags gelesen werden, speichern wir die referenzierten Richtlinien-Tags in Cloud Logging. Die Prüfung der Richtlinien-Tags ist jedoch nicht mit der Abfrage verknüpft, die die Prüfung ausgelöst hat.
Mit Cloud Logging können Prüfer nachvollziehen, wer welche Art von Zugriff auf welche Kategorien sensibler Daten hat. Weitere Informationen finden Sie unter Richtlinien-Tags prüfen.
Weitere Informationen zum Logging in BigQuery finden Sie unter Einführung in BigQuery-Monitoring.
Weitere Informationen zum Logging in Google Cloudfinden Sie unter Cloud Logging.
Nächste Schritte
Weitere Informationen zur Verwendung der Zugriffssteuerung auf Spaltenebene finden Sie unter Zugriff mit Zugriffssteuerung auf Spaltenebene beschränken.
Informationen zu Best Practices für Richtlinien-Tags finden Sie unter BigQuery: Best Practices für die Verwendung von Richtlinien-Tags.