클러스터링된 테이블 소개
BigQuery의 클러스터링된 테이블은 클러스터링된 열을 사용하여 사용자 정의 열 정렬 순서가 있는 테이블입니다. 클러스터링된 테이블을 사용하면 쿼리 성능을 높이고 쿼리 비용을 줄일 수 있습니다.
BigQuery에서 클러스터링된 열은 클러스터링된 열의 값을 기준으로 스토리지 블록을 정렬하는 사용자 정의 테이블 속성입니다. 스토리지 블록 크기는 테이블 크기에 따라 조정됩니다. 코로케이션은 개별 행 수준이 아닌 스토리지 블록 수준에서 발생하며 이 컨텍스트에서의 코로케이션에 대한 자세한 내용은 클러스터링을 참조하세요.
클러스터링된 테이블에서는 해당 테이블을 수정하는 각 작업과 관련하여 정렬 속성이 유지됩니다. 클러스터링된 열을 기준으로 필터링 또는 집계하는 쿼리는 전체 테이블 또는 테이블 파티션 대신 클러스터링된 열을 기준으로 관련 블록만 스캔합니다. 그 결과 BigQuery가 쿼리에 의해 처리되는 바이트나 쿼리 비용을 정확히 예측하지 못할 수도 있지만, 실행 시 총 바이트 수를 줄이려고 시도합니다.
다음 예와 같이 여러 열을 사용하여 테이블을 클러스터링할 경우 열 순서는 BigQuery가 데이터를 정렬하여 스토리지 블록으로 그룹화할 때 우선 적용되는 열을 결정합니다. 테이블 1은 클러스터링되지 않은 테이블의 논리적 스토리지 블록 레이아웃을 보여줍니다. 반면 테이블 2는 Country 열로만 클러스터링되고 테이블 3은 Country 및 Status의 여러 열로 클러스터링됩니다.
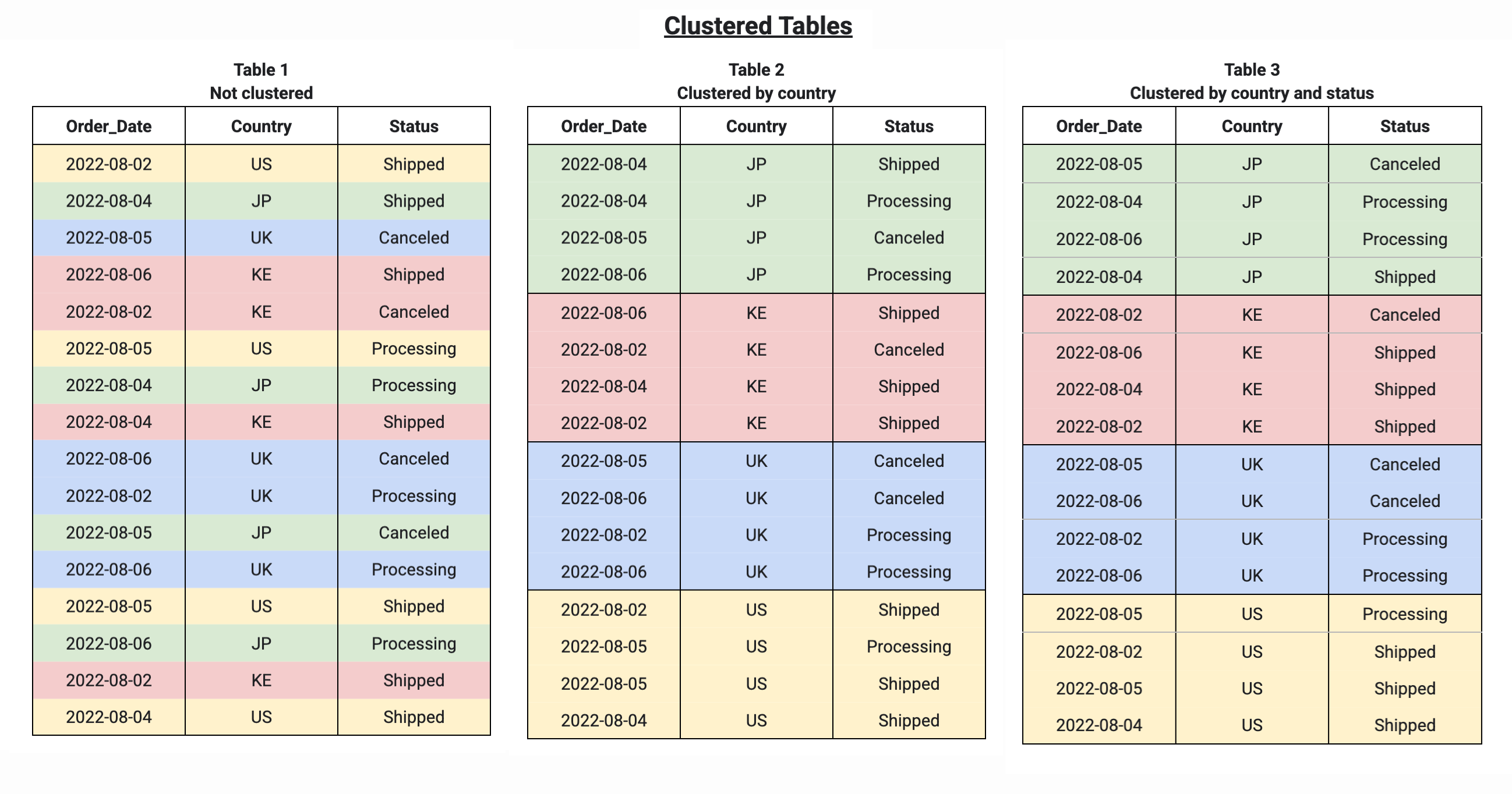
클러스터링된 테이블을 쿼리하는 경우 쿼리 실행 전에 스캔할 스토리지 블록 수를 알 수 없으므로 쿼리 실행 전에 정확한 쿼리 비용 예상치가 제공되지 않습니다. 최종 비용은 쿼리 실행이 완료된 후 결정되며 스캔된 특정 스토리지 블록을 기반으로 합니다.
클러스터링을 사용해야 하는 경우
클러스터링은 테이블이 저장되는 방식을 결정하므로 일반적으로 쿼리 성능 향상을 위해 가장 먼저 고려할 만한 옵션입니다. 따라서 다음과 같은 이점을 제공하는 경우 클러스터링을 사용하는 것이 좋습니다.
- 파티션을 나누지 않은 테이블이 64MB보다 클 경우 클러스터링하면 이점이 있을 수 있습니다. 마찬가지로 64MB보다 큰 테이블 파티션도 클러스터링 시 이점을 누릴 수 있습니다. 더 작은 테이블 또는 파티션도 클러스터링할 수 있지만 일반적으로 성능 개선이 미미합니다.
- 쿼리에서 특정 열을 기준으로 필터링하는 경우가 많다면 쿼리에서 필터와 일치하는 블록만 스캔하므로 클러스터링이 쿼리 속도를 높입니다.
- 쿼리의 필터링 기준 열에 고유 값이 많다면(카디널리티가 높음) 클러스터링은 입력 데이터를 가져올 위치에 대한 상세 메타데이터를 BigQuery에 제공하여 쿼리 속도를 높입니다.
- 클러스터링을 사용하면 테이블의 기본 스토리지 블록의 크기를 테이블 크기에 따라 적응적으로 조절할 수 있습니다.
클러스터링 외에도 테이블 파티션 나누기를 고려할 수 있습니다. 이 접근 방식에서는 먼저 데이터를 파티션으로 분할한 다음 클러스터링 열을 통해 각 파티션 내의 데이터를 클러스터링합니다. 다음과 같은 경우에 이 방법을 사용하는 것이 좋습니다.
- 쿼리를 실행하려면 먼저 엄격한 쿼리 비용 추정이 필요합니다. 클러스터링된 테이블의 쿼리 비용은 쿼리가 실행된 후에만 확인할 수 있습니다. 파티션 나누기는 쿼리를 실행하기 전에 세분화된 쿼리 비용 추정치를 제공합니다.
- 테이블 파티션을 나누면 평균 파티션 크기가 파티션당 최소 10GB가 됩니다. 작은 파티션을 여러 개 만들면 테이블의 메타데이터가 증가하여 테이블을 쿼리할 때 메타데이터 액세스 시간에 영향을 줄 수 있습니다.
- 테이블을 지속적으로 업데이트해야 하지만 장기 스토리지 요금을 활용하려고 합니다. 파티션 나누기를 사용하면 각 파티션이 장기 요금 대상으로 개별적으로 고려됩니다. 테이블의 파티션을 나누지 않은 경우 장기 요금 대상으로 고려되려면 테이블 전체가 90일 연속으로 수정되지 않아야 합니다.
자세한 내용은 클러스터링된 테이블과 파티션을 나눈 테이블 결합을 참조하세요.
클러스터 열 유형 및 순서
이 섹션에서는 열 유형과 테이블 클러스터링에서 열 순서가 작동하는 방식을 설명합니다.
클러스터 열 유형
클러스터 열은 반복되지 않는 최상위 열이어야 하며 다음 유형 중 하나여야 합니다.
BIGNUMERICBOOLDATEDATETIMEGEOGRAPHYINT64NUMERICRANGESTRINGTIMESTAMP
데이터 유형에 대한 자세한 내용은 GoogleSQL 데이터 유형을 참조하세요.
클러스터 열 순서
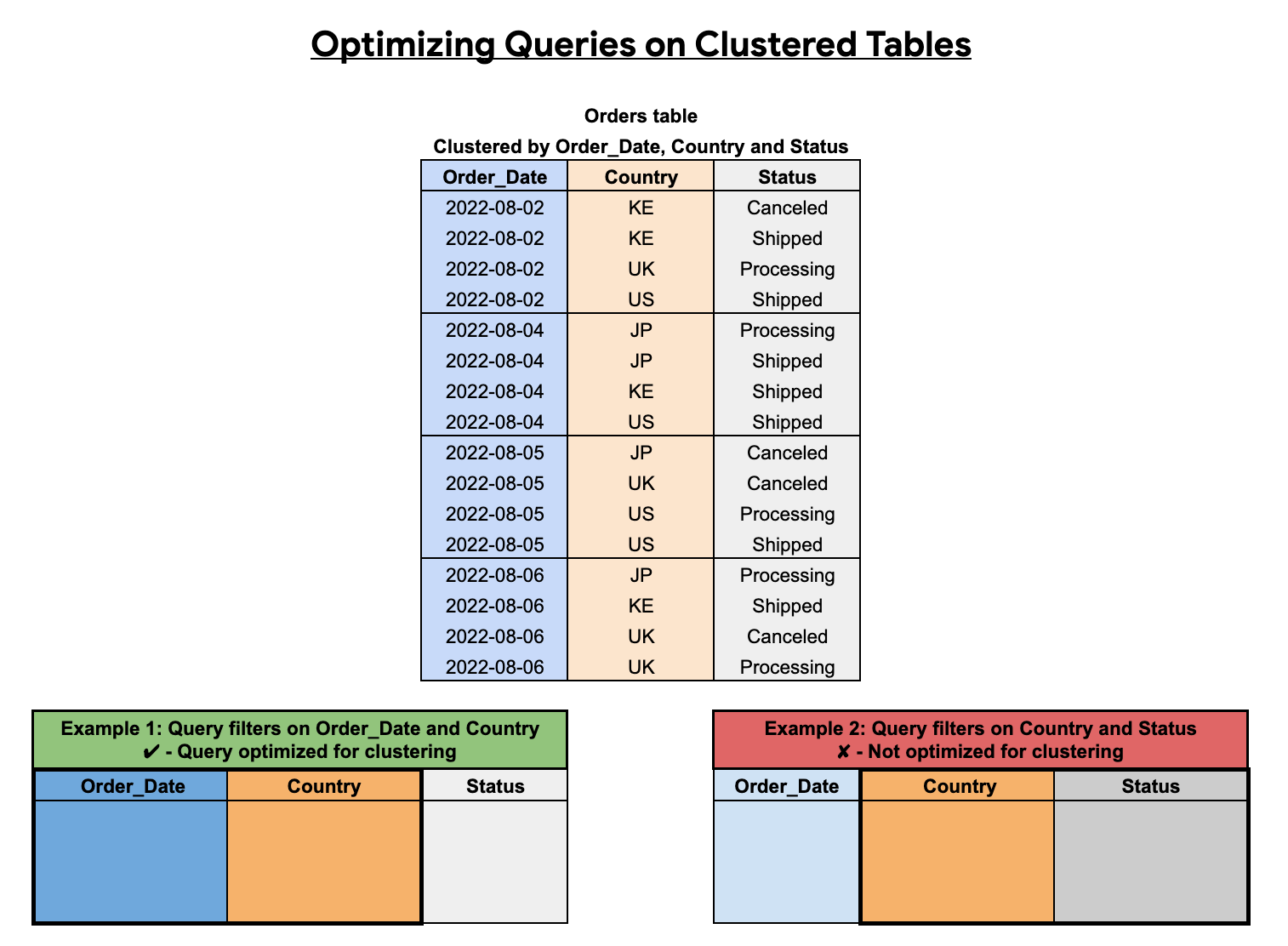
클러스터링된 열의 순서는 쿼리 성능에 영향을 미칩니다. 다음 예시에서 Orders 테이블은 Order_Date, Country, Status의 열 정렬 순서를 사용하여 클러스터링됩니다. 이 예의 첫 번째 클러스터형 열은 Order_Date이므로 Order_Date 및 Country를 필터링하는 쿼리는 클러스터링에 최적화되어 있지만 Country 및 Status만 필터링하는 쿼리는 최적화되어 있지 않습니다.
블록 프루닝
클러스터링된 테이블을 사용하면 데이터를 프루닝해 쿼리로 데이터가 처리되지 않도록 하여 쿼리 비용을 절감할 수 있습니다. 이 프로세스를 블록 프루닝이라고 합니다. BigQuery는 클러스터링 열의 값에 따라 클러스터링된 테이블의 데이터를 정렬하고 블록으로 정리합니다.
클러스터링된 열의 필터를 포함한 쿼리를 클러스터링된 테이블에 실행하는 경우 BigQuery는 필터 표현식과 블록 메타데이터를 사용해 쿼리로 스캔할 블록을 프루닝합니다. 이렇게 하면 BigQuery가 관련 블록만 스캔할 수 있습니다.
블록이 프루닝되면 스캔되지 않습니다. 스캔된 블록만이 쿼리로 처리된 데이터의 바이트를 계산하는 데 사용됩니다. 클러스터링된 테이블에 대한 쿼리로 처리되는 바이트 수는 스캔된 블록에서 쿼리에 참조된 각 열에서 읽은 바이트 수의 합계와 동일합니다.
클러스터링된 테이블이 여러 필터를 사용하는 쿼리에서 여러 번 참조되는 경우, BigQuery는 각 필터에 해당하는 블록의 열 스캔 작업에 대해 요금을 청구합니다. 블록 프루닝의 작동 방식에 대한 예시를 참조하세요.
클러스터링된 테이블과 파티션을 나눈 테이블 결합
테이블 클러스터링과 테이블 파티션 나누기를 결합하면 쿼리를 더욱 세부적으로 정렬할 수 있습니다.
파티션을 나눈 테이블에서 데이터는 데이터의 한 파티션을 포함하는 각 물리적 블록에 저장됩니다. 파티션을 나눈 각 테이블은 테이블을 수정하는 모든 작업에서 정렬 속성에 대한 다양한 메타데이터를 유지합니다. 메타데이터를 통해 BigQuery가 쿼리를 실행하기 전에 쿼리 비용을 더 정확히 예측할 수 있습니다. 그러나 파티션 나누기를 수행하려면 BigQuery가 파티션을 나누지 않은 테이블보다 더 많은 메타데이터를 유지해야 합니다. 파티션의 수가 증가하면 유지할 메타데이터의 양도 증가합니다.
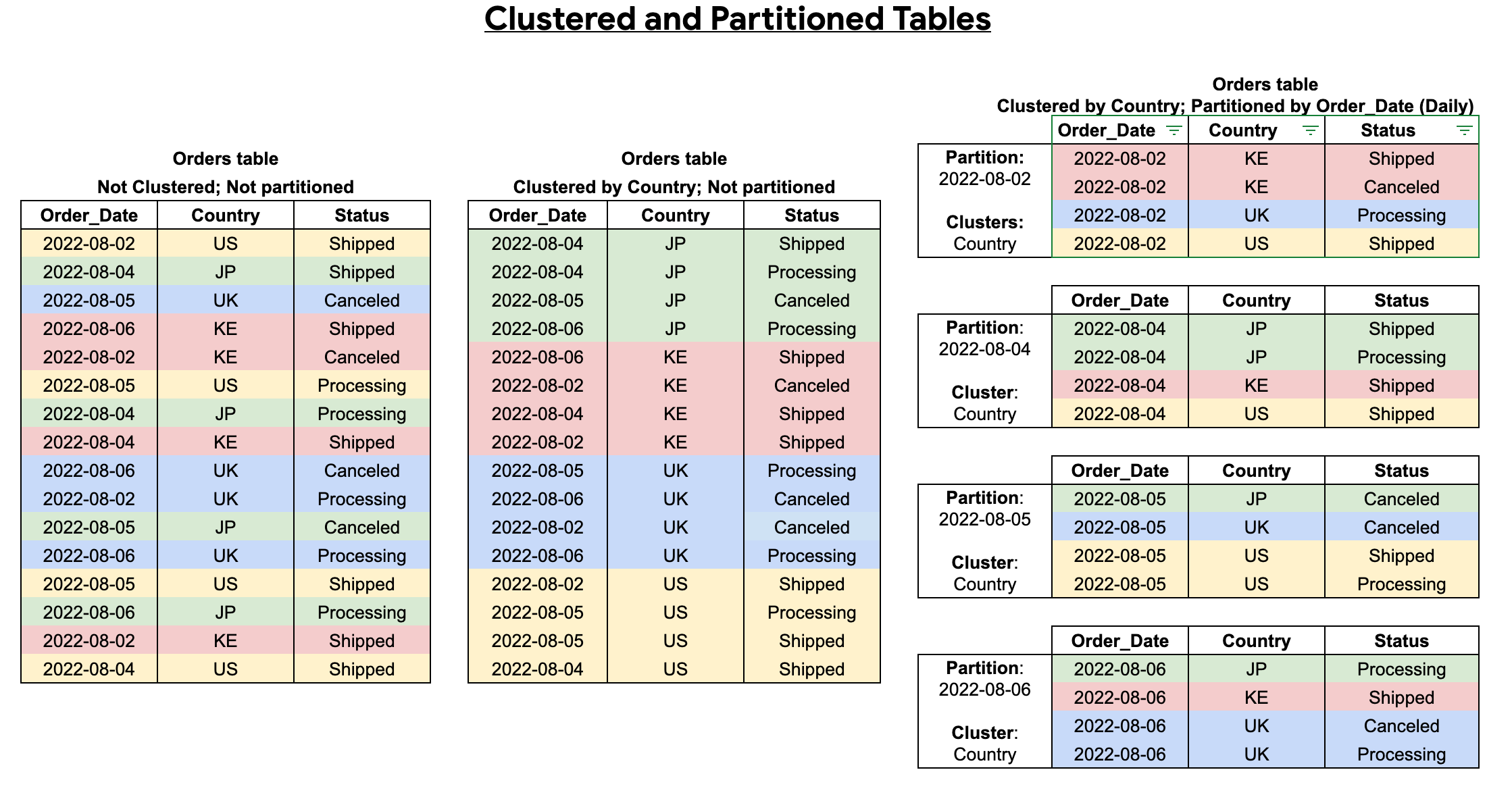
클러스터링되고 파티션을 나눈 테이블을 만들 때 다음 다이어그램과 같이 보다 세부적인 정렬을 달성할 수 있습니다.
예
이름이 ClusteredSalesData인 클러스터링된 테이블이 있습니다. 이 테이블은 timestamp 열로 파티션을 나누고 customer_id 열로 클러스터링됩니다. 데이터는 다음 블록 세트로 정리됩니다.
| 파티션 식별자 | 블록 ID | 블록의 customer_id 최솟값 | 블록의 customer_id 최댓값 |
|---|---|---|---|
| 20160501 | B1 | 10000 | 19999 |
| 20160501 | B2 | 20000 | 24999 |
| 20160502 | B3 | 15000 | 17999 |
| 20160501 | B4 | 22000 | 27999 |
다음 쿼리를 테이블에 실행합니다. 쿼리에는 customer_id 열에 필터가 포함되어 있습니다.
SELECT SUM(totalSale) FROM `mydataset.ClusteredSalesData` WHERE customer_id BETWEEN 20000 AND 23000 AND DATE(timestamp) = "2016-05-01"
위 쿼리에는 다음 단계가 포함됩니다.
- 블록 B2와 B4에서
timestamp,customer_id,totalSale열을 스캔합니다. timestamp파티션을 나눈 열의DATE(timestamp) = "2016-05-01"필터 조건자로 인해 B3 블록을 프루닝합니다.customer_id클러스터링 열의customer_id BETWEEN 20000 AND 23000필터 조건자로 인해 B1 블록을 프루닝합니다.
자동 재클러스터링
클러스터링된 테이블에 데이터가 추가되면 새 데이터가 블록으로 구성되고 새 스토리지 블록이 생성되거나 기존 블록이 업데이트될 수 있습니다. 새 데이터가 동일한 클러스터 값이 있는 기존 데이터와 그룹화되지 않을 수 있으므로 최적의 쿼리 및 스토리지 성능을 위해 블록 최적화가 필요합니다.
BigQuery는 클러스터링된 테이블의 성능 특성을 유지하기 위해 백그라운드에서 자동 재클러스터링을 수행합니다. 파티션을 나눈 테이블의 경우에는 각 파티션 범위 내의 데이터에 대해 클러스터링이 유지됩니다.
제한사항
- 클러스터링된 테이블을 쿼리하고 클러스터링된 테이블에 쿼리 결과를 쓰는 데는 GoogleSQL만 지원됩니다.
- 클러스터링 열은 최대 4개만 지정할 수 있습니다. 추가 열이 필요한 경우 클러스터링과 파티션 나누기를 결합하는 것이 좋습니다.
- 클러스터링에
STRING유형 열을 사용하는 경우 BigQuery는 처음 1,024자(영문 기준)만 사용하여 데이터를 클러스터링합니다. 열의 값 자체는 1,024자(영문 기준)보다 길 수 있습니다. - 클러스터링되지 않은 기존 테이블을 클러스터링할 경우 기존 데이터는 자동으로 클러스터링되지 않습니다. 클러스터링된 열을 사용하여 저장된 새 데이터에만 자동 재클러스터링이 적용됩니다.
UPDATE문을 사용하여 기존 데이터를 재클러스터링하는 방법에 대한 자세한 내용은 클러스터링 사양 수정을 참조하세요.
클러스터링된 테이블의 할당량 및 한도
BigQuery는 특정 테이블 작업 또는 하루 동안 실행되는 작업 수에 대한 제한사항 등의 할당량 및 한도로 공유 Google Cloud 리소스의 사용을 제한합니다.
파티션을 나눈 테이블로 클러스터링된 테이블 기능을 사용할 때는 파티션을 나눈 테이블의 한도가 적용될 수 있습니다.
할당량과 한도는 클러스터링된 테이블에 대해 실행할 수 있는 다양한 유형의 작업에도 적용됩니다. 테이블에 적용되는 작업 할당량에 대한 자세한 내용은 '할당량 및 한도'의 작업을 참조하세요.
클러스터링된 테이블 가격 책정
BigQuery에서 클러스터링된 테이블을 만들고 사용할 때 부과되는 요금은 데이터를 대상으로 실행하는 쿼리와 테이블에 저장된 데이터의 양에 따라 결정됩니다. 자세한 내용은 스토리지 가격 책정 및 쿼리 가격 책정을 참조하세요.
클러스터링된 테이블 작업은 다른 BigQuery 테이블 작업과 마찬가지로 일괄 로드, 테이블 복사, 자동 재클러스터링, 데이터 내보내기와 같은 BigQuery 무료 작업을 활용합니다. 이러한 작업에는 BigQuery 할당량 및 한도가 적용됩니다. 무료 작업에 대한 자세한 내용은 무료 작업을 참조하세요.
클러스터링된 테이블 가격의 자세한 예시는 스토리지 및 쿼리 비용 추정을 참조하세요.
테이블 보안
BigQuery에서 테이블에 대한 액세스를 제어하려면 IAM으로 리소스에 대한 액세스 제어를 참고하세요.
다음 단계
- 클러스터링된 테이블을 만들고 사용하는 방법은 클러스터링된 테이블 생성 및 사용을 참조하세요.
- 클러스터링된 테이블 쿼리에 대한 자세한 내용은 클러스터링된 테이블 쿼리를 참조하세요.