Update tabel streaming dengan pengambilan data perubahan
Pengambilan data perubahan BigQuery (CDC) akan memperbarui tabel BigQuery dengan memproses dan menerapkan perubahan yang di-streaming pada data yang ada. Sinkronisasi ini dilakukan melalui operasi baris upsert and delete yang di-streaming secara real time oleh BigQuery Storage Write API, yang harus Anda ketahui sebelum melanjutkan.
Sebelum memulai
Berikan peran Identity and Access Management (IAM) yang memberi pengguna izin yang diperlukan untuk melakukan setiap tugas dalam dokumen ini, dan pastikan alur kerja Anda memenuhi setiap prasyarat.
Izin yang diperlukan
Untuk mendapatkan izin yang Anda perlukan guna menggunakan Storage Write API,
minta administrator untuk memberi Anda
peran IAM BigQuery Data Editor (roles/bigquery.dataEditor).
Untuk mengetahui informasi selengkapnya tentang cara memberikan peran, lihat Mengelola akses ke project, folder, dan organisasi.
Peran bawaan ini berisi izin
bigquery.tables.updateData
yang diperlukan untuk
menggunakan Storage Write API.
Anda mungkin juga bisa mendapatkan izin ini dengan peran khusus atau peran bawaan lainnya.
Untuk mengetahui informasi lebih lanjut tentang peran dan izin IAM di BigQuery, baca Pengantar IAM.
Prasyarat
Untuk menggunakan BigQuery CDC, alur kerja Anda harus memenuhi kondisi berikut:
- Anda harus menggunakan Storage Write API di aliran default.
- Anda harus menggunakan format protobuf sebagai format penyerapan. Format Apache Arrow tidak didukung.
- Anda harus mendeklarasikan kunci utama untuk tabel tujuan di BigQuery. Kunci utama gabungan yang berisi hingga 16 kolom didukung.
- Resource komputasi BigQuery yang memadai harus tersedia untuk menjalankan operasi baris CDC. Perlu diketahui bahwa jika operasi modifikasi baris CDC gagal, Anda mungkin secara tidak sengaja menyimpan data yang ingin dihapus. Untuk informasi selengkapnya, lihat Pertimbangan data yang dihapus.
Menentukan perubahan pada data yang ada
Di BigQuery CDC, kolom semu _CHANGE_TYPE menunjukkan jenis
perubahan yang akan diproses untuk setiap baris. Untuk menggunakan CDC, tetapkan _CHANGE_TYPE saat
Anda melakukan streaming modifikasi baris menggunakan Storage Write API. Kolom
semu _CHANGE_TYPE hanya menerima nilai UPSERT dan DELETE.
Tabel dianggap mendukung CDC saat Storage Write API
melakukan streaming modifikasi baris ke tabel dengan cara ini.
Contoh dengan nilai UPSERT dan DELETE
Pertimbangkan tabel berikut di BigQuery:
| ID | Nama | Gaji |
|---|---|---|
| 100 | Charlie | 2000 |
| 101 | Tal | 3000 |
| 102 | Lee | 5000 |
Modifikasi baris berikut di-streaming oleh Storage Write API:
| ID | Nama | Gaji | _CHANGE_TYPE |
|---|---|---|---|
| 100 | HAPUS | ||
| 101 | Tal | 8000 | UPSERT |
| 105 | Izumi | 6000 | UPSERT |
Tabel yang diupdate kini menjadi sebagai berikut:
| ID | Nama | Gaji |
|---|---|---|
| 101 | Tal | 8000 |
| 102 | Lee | 5000 |
| 105 | Izumi | 6000 |
Mengelola penghentian tabel yang tidak berlaku
Secara default, setiap kali Anda menjalankan kueri, BigQuery akan menampilkan hasil terbaru. Untuk memberikan hasil terbaru saat membuat kueri tabel yang mendukung
CDC, BigQuery harus menerapkan setiap modifikasi baris yang di-streaming hingga
waktu mulai kueri, sehingga versi tabel terbaru dikueri. Menerapkan perubahan baris ini pada waktu proses kueri akan meningkatkan latensi
dan biaya kueri. Namun, jika Anda tidak memerlukan hasil kueri yang sepenuhnya terbaru,
Anda dapat mengurangi biaya dan latensi pada kueri dengan menetapkan opsi max_staleness
di tabel Anda. Jika opsi ini disetel, BigQuery akan menerapkan
perubahan baris setidaknya sekali dalam interval yang ditentukan oleh nilai
max_staleness, sehingga Anda dapat menjalankan kueri tanpa menunggu update
diterapkan, dengan mengorbankan beberapa data yang tidak berlaku.
Perilaku ini sangat berguna untuk dasbor dan laporan yang tidak terlalu mementingkan keaktualan data. Opsi ini juga berguna untuk pengelolaan biaya dengan memberi Anda lebih banyak kontrol atas seberapa sering BigQuery menerapkan modifikasi baris.
Tabel kueri dengan kumpulan opsi max_staleness
Saat Anda membuat kueri
pada tabel dengan kumpulan opsi max_staleness, BigQuery
akan menampilkan hasil berdasarkan nilai max_staleness
dan waktu saat penerapan tugas terakhir terjadi, yang diwakili oleh
stempel waktu upsert_stream_apply_watermark.
Perhatikan contoh berikut, saat tabel memiliki opsi max_staleness yang
ditetapkan ke 10 menit, dan penerapan tugas terbaru terjadi di T20:
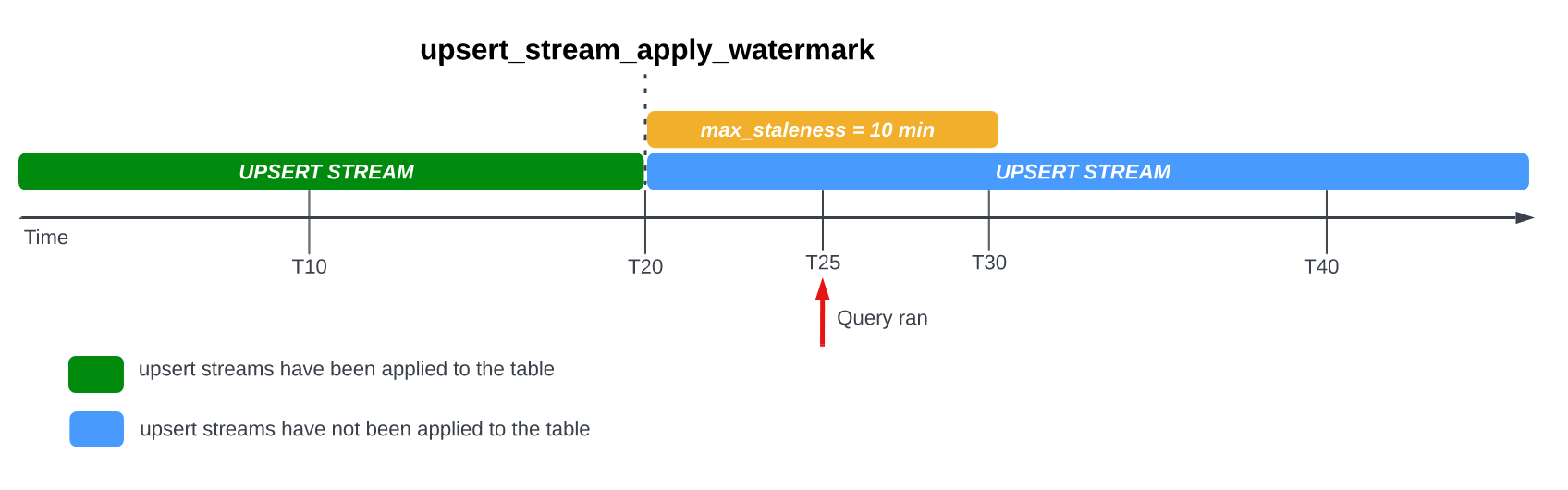
Jika Anda membuat kueri tabel di T25, maka versi tabel saat ini akan berstatus 5
menit tidak berlaku, yang kurang dari interval max_staleness 10 menit. Dalam
hal ini, BigQuery akan menampilkan versi tabel di T20,
yang berarti data yang ditampilkan juga sudah 5 menit tidak berlaku.
Saat Anda menetapkan opsi max_staleness di tabel, BigQuery
akan menerapkan modifikasi baris yang tertunda setidaknya sekali dalam interval max_staleness. Namun, dalam beberapa kasus, BigQuery mungkin tidak menyelesaikan
proses penerapan modifikasi baris tertunda ini dalam interval.
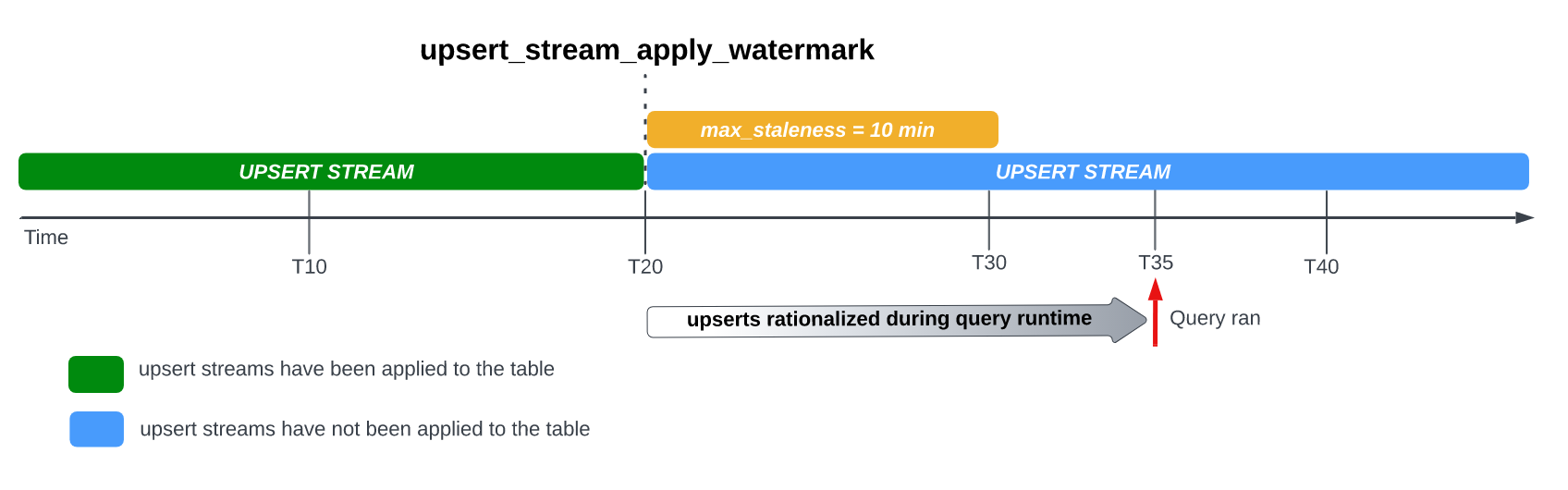
Misalnya, jika Anda membuat kueri tabel di T35, dan proses penerapan modifikasi baris yang tertunda
belum selesai, maka versi tabel saat ini sudah 15 menit tidak berlaku, yang lebih besar daripada interval max_staleness 10 menit.
Dalam hal ini, pada waktu proses kueri, BigQuery akan menerapkan semua modifikasi baris antara T20 dan T35 untuk kueri saat ini, yang berarti data yang dikueri benar-benar terbaru, dengan mengorbankan beberapa latensi kueri tambahan.
Hal ini dianggap sebagai tugas penggabungan runtime.
Nilai max_staleness tabel yang direkomendasikan
Nilai max_staleness tabel umumnya harus lebih tinggi dari dua nilai berikut:
- Kehabisan data maksimum yang dapat ditoleransi untuk alur kerja Anda.
- Dua kali waktu maksimum yang diperlukan untuk menerapkan perubahan yang telah di-upsert ke tabel Anda, ditambah beberapa buffer tambahan.
Guna menghitung waktu yang diperlukan untuk menerapkan perubahan yang telah diupdate dan dimasukkan ke tabel yang ada, gunakan kueri SQL berikut untuk menentukan durasi persentil ke-95 tugas yang diterapkan di latar belakang, ditambah buffer tujuh menit untuk memungkinkan konversi penyimpanan yang dioptimalkan untuk penulisan BigQuery (buffer streaming).
SELECT project_id, destination_table.dataset_id, destination_table.table_id, APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)] AS p95_background_apply_duration_in_seconds, CEILING(APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)]*2/60)+7 AS recommended_max_staleness_with_buffer_in_minutes FROM `region-REGION`.INFORMATION_SCHEMA.JOBS AS job WHERE project_id = 'PROJECT_ID' AND DATE(creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE "%cdc_background%" GROUP BY 1,2,3;
Ganti kode berikut:
REGION: nama region tempat project Anda berada. Contohnya,us.PROJECT_ID: ID project yang berisi tabel BigQuery yang sedang dimodifikasi oleh BigQuery CDC.
Durasi penerapan tugas di latar belakang dipengaruhi oleh beberapa faktor, termasuk jumlah dan kompleksitas operasi CDC yang dikeluarkan dalam interval yang tidak berlaku, ukuran tabel, dan ketersediaan resource BigQuery. Untuk informasi selengkapnya tentang ketersediaan resource, lihat Mengukur dan memantau pemesanan LATAR BELAKANG.
Membuat tabel dengan opsi max_staleness
Untuk membuat tabel dengan opsi max_staleness, gunakan
pernyataan CREATE TABLE.
Contoh berikut membuat tabel employees dengan batas max_staleness
selama 10 menit:
CREATE TABLE employees ( id INT64 PRIMARY KEY NOT ENFORCED, name STRING) CLUSTER BY id OPTIONS ( max_staleness = INTERVAL 10 MINUTE);
Mengubah opsi max_staleness untuk tabel yang sudah ada
Untuk menambahkan atau mengubah batas max_staleness dalam tabel yang ada, gunakan
pernyataan ALTER TABLE.
Contoh berikut mengubah batas max_staleness pada tabel employees
menjadi 15 menit:
ALTER TABLE employees SET OPTIONS ( max_staleness = INTERVAL 15 MINUTE);
Menentukan nilai max_staleness tabel saat ini
Untuk menentukan nilai max_staleness tabel saat ini, buat kueri
tampilan INFORMATION_SCHEMA.TABLE_OPTIONS.
Contoh berikut akan memeriksa nilai max_staleness tabel
mytable saat ini:
SELECT option_name, option_value FROM DATASET_NAME.INFORMATION_SCHEMA.TABLE_OPTIONS WHERE option_name = 'max_staleness' AND table_name = 'TABLE_NAME';
Ganti kode berikut:
DATASET_NAME: nama set data tempat tabel yang mendukung CDC.TABLE_NAME: nama tabel yang mendukung CDC.
Hasilnya menunjukkan bahwa nilai max_staleness adalah 10 menit:
+---------------------+--------------+ | Row | option_name | option_value | +---------------------+--------------+ | 1 | max_staleness | 0-0 0 0:10:0 | +---------------------+--------------+
Memantau progres operasi upsert tabel
Untuk memantau status tabel dan memeriksa kapan modifikasi baris
terakhir diterapkan, buat kueri
tampilan INFORMATION_SCHEMA.TABLES
untuk mendapatkan stempel waktu upsert_stream_apply_watermark.
Contoh berikut memeriksa nilai upsert_stream_apply_watermark
tabel mytable:
SELECT upsert_stream_apply_watermark FROM DATASET_NAME.INFORMATION_SCHEMA.TABLES WHERE table_name = 'TABLE_NAME';
Ganti kode berikut:
DATASET_NAME: nama set data tempat tabel yang mendukung CDC.TABLE_NAME: nama tabel yang mendukung CDC.
Hasilnya serupa dengan berikut ini:
[{
"upsert_stream_apply_watermark": "2022-09-15T04:17:19.909Z"
}]
Operasi upsert dilakukan oleh akun layanan bigquery-adminbot@system.gserviceaccount.com
dan muncul dalam histori tugas project yang berisi
tabel yang mendukung CDC.
Mengelola pengurutan kustom
Saat melakukan streaming update dan penyisipan ke BigQuery, perilaku default pengurutan kumpulan data dengan kunci utama yang identik ditentukan oleh waktu sistem BigQuery saat kumpulan data diserap ke dalam BigQuery. Dengan kata lain, data yang baru saja diproses dengan stempel waktu terbaru lebih diprioritaskan daripada data yang sebelumnya diproses dengan stempel waktu yang lebih lama. Untuk kasus penggunaan tertentu, seperti kasus penggunaan saat upsert yang sangat sering dapat terjadi pada kunci utama yang sama dalam jangka waktu yang sangat singkat, atau saat urutan upsert tidak dijamin, hal ini mungkin tidak cukup. Untuk skenario ini, kunci pengurutan yang disediakan pengguna mungkin diperlukan.
Untuk mengonfigurasi kunci pengurutan yang disediakan pengguna, pseudokolom
_CHANGE_SEQUENCE_NUMBER digunakan untuk menunjukkan urutan penerapan
BigQuery pada rekaman, berdasarkan
_CHANGE_SEQUENCE_NUMBER yang lebih besar antara dua rekaman yang cocok dengan kunci
primer yang sama. Pseudokolom _CHANGE_SEQUENCE_NUMBER adalah kolom opsional dan hanya
menerima nilai dalam format tetap STRING.
Format _CHANGE_SEQUENCE_NUMBER
Kolom semu _CHANGE_SEQUENCE_NUMBER hanya menerima nilai STRING,
yang ditulis dalam format tetap. Format tetap ini menggunakan nilai STRING yang ditulis dalam
hexadesimal, yang dipisahkan menjadi beberapa bagian dengan garis miring /. Setiap bagian dapat dinyatakan dalam maksimal 16 karakter heksadesimal, dan hingga empat bagian diizinkan per _CHANGE_SEQUENCE_NUMBER. Rentang yang diizinkan untuk
_CHANGE_SEQUENCE_NUMBER mendukung nilai antara 0/0/0/0 dan
FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF.
Nilai _CHANGE_SEQUENCE_NUMBER mendukung karakter huruf besar dan huruf kecil.
Mengekspresikan kunci pengurutan dasar dapat dilakukan dengan menggunakan satu bagian. Misalnya, untuk mengurutkan kunci hanya berdasarkan stempel waktu pemrosesan rekaman dari server aplikasi, Anda dapat menggunakan satu bagian: '2024-04-30 11:19:44 UTC', yang dinyatakan sebagai heksadesimal dengan mengonversi stempel waktu ke milidetik dari Epoch, '18F2EBB6480' dalam hal ini. Logika untuk mengonversi data menjadi heksadesimal
adalah tanggung jawab klien yang mengeluarkan perintah tulis ke BigQuery
menggunakan Storage Write API.
Mendukung beberapa bagian memungkinkan Anda menggabungkan beberapa nilai logika pemrosesan
ke dalam satu kunci untuk kasus penggunaan yang lebih kompleks. Misalnya, untuk mengurutkan kunci berdasarkan stempel waktu pemrosesan
rekaman dari server aplikasi, nomor urut log, dan status rekaman, Anda dapat menggunakan tiga bagian:
'2024-04-30 11:19:44 UTC' / '123' / 'complete', yang masing-masing dinyatakan sebagai heksadesimal.
Urutan bagian adalah pertimbangan penting untuk memberi peringkat logika pemrosesan Anda. BigQuery membandingkan nilai _CHANGE_SEQUENCE_NUMBER dengan membandingkan bagian pertama, lalu membandingkan bagian berikutnya hanya jika bagian sebelumnya sama.
BigQuery menggunakan _CHANGE_SEQUENCE_NUMBER untuk melakukan pengurutan dengan membandingkan dua atau lebih kolom _CHANGE_SEQUENCE_NUMBER sebagai nilai numerik yang tidak bertanda.
Perhatikan contoh perbandingan _CHANGE_SEQUENCE_NUMBER berikut dan hasil prioritasnya:
Contoh 1:
- Catatan #1:
_CHANGE_SEQUENCE_NUMBER= '77' - Catatan #2:
_CHANGE_SEQUENCE_NUMBER= '7B'
Hasil: Record #2 dianggap sebagai record terbaru karena '7B' > '77' (yaitu '123' > '119')
- Catatan #1:
Contoh 2:
- Catatan #1:
_CHANGE_SEQUENCE_NUMBER= 'FFF/B' - Record #2:
_CHANGE_SEQUENCE_NUMBER= 'FFF/ABC'
Hasil: Data #2 dianggap sebagai data terbaru karena 'FFF/ABC' > 'FFF/B' (yaitu '4095/2748' > '4095/11')
- Catatan #1:
Contoh 3:
- Record #1:
_CHANGE_SEQUENCE_NUMBER= 'BA/FFFFFFFF' - Record #2:
_CHANGE_SEQUENCE_NUMBER= 'ABC'
Hasil: Record #2 dianggap sebagai record terbaru karena 'ABC' > 'BA/FFFFFFFF' (yaitu '2748' > '186/4294967295')
- Record #1:
Contoh 4:
- Catatan #1:
_CHANGE_SEQUENCE_NUMBER= 'FFF/ABC' - Record #2:
_CHANGE_SEQUENCE_NUMBER= 'ABC'
Hasil: Data #1 dianggap sebagai data terbaru karena 'FFF/ABC' > 'ABC' (yaitu '4095/2748' > '2748')
- Catatan #1:
Jika dua nilai _CHANGE_SEQUENCE_NUMBER identik, maka kumpulan data dengan waktu penyerapan sistem BigQuery terbaru akan lebih diutamakan daripada kumpulan data yang diserap sebelumnya.
Jika pengurutan kustom digunakan untuk tabel, nilai _CHANGE_SEQUENCE_NUMBER
harus selalu diberikan. Setiap permintaan tulis yang tidak menentukan nilai
_CHANGE_SEQUENCE_NUMBER, sehingga menyebabkan campuran baris dengan dan tanpa nilai
_CHANGE_SEQUENCE_NUMBER, akan menghasilkan pengurutan yang tidak dapat diprediksi.
Mengonfigurasi pemesanan BigQuery untuk digunakan dengan CDC
Anda dapat menggunakan pemesanan BigQuery guna mengalokasikan resource compute BigQuery khusus untuk operasi modifikasi baris CDC. Dengan pemesanan, Anda dapat menetapkan batas biaya untuk melakukan operasi ini. Pendekatan ini sangat berguna untuk alur kerja dengan operasi CDC yang sering dilakukan terhadap tabel besar, yang akan menimbulkan biaya sesuai permintaan yang tinggi karena banyaknya byte yang diproses saat melakukan setiap operasi.
Tugas BigQuery CDC yang menerapkan modifikasi baris tertunda dalam
interval max_staleness dianggap sebagai tugas latar belakang dan menggunakan
jenis penetapan BACKGROUND,
bukan jenis penetapan QUERY.
Sebaliknya, kueri di luar interval max_staleness yang memerlukan modifikasi
baris untuk diterapkan saat waktu proses kueri menggunakan
jenis penetapan QUERY. Tabel tanpa setelan max_staleness atau tabel dengan max_staleness yang ditetapkan ke 0 juga menggunakan jenis penetapan QUERY.
Tugas latar belakang BigQuery CDC yang dilakukan tanpa penetapan BACKGROUND
menggunakan harga sesuai permintaan.
Pertimbangan ini penting saat merancang strategi pengelolaan workload untuk
BigQuery CDC.
Untuk mengonfigurasi pemesanan BigQuery yang akan digunakan dengan CDC, mulailah dengan
mengonfigurasi pemesanan
di region tempat tabel BigQuery Anda berada. Untuk panduan ukuran pemesanan Anda, lihat
Mengukur dan memantau BACKGROUND pemesanan.
Setelah membuat pemesanan,
tetapkan project BigQuery
ke pemesanan, dan tetapkan opsi job_type ke BACKGROUND dengan
menjalankan
pernyataan CREATE ASSIGNMENT berikut:
CREATE ASSIGNMENT `ADMIN_PROJECT_ID.region-REGION.RESERVATION_NAME.ASSIGNMENT_ID` OPTIONS ( assignee = 'projects/PROJECT_ID', job_type = 'BACKGROUND');
Ganti kode berikut:
ADMIN_PROJECT_ID: ID project administrasi yang memiliki pemesanan.REGION: nama region tempat project Anda berada. Contohnya,us.RESERVATION_NAME: nama pemesanan.ASSIGNMENT_ID: ID tugas. ID harus unik untuk project dan lokasi, diawali dan diakhiri dengan huruf kecil atau angka, serta hanya berisi huruf kecil, angka, dan tanda hubung.PROJECT_ID: ID project yang berisi tabel BigQuery yang diubah oleh BigQuery CDC. Project ini ditetapkan ke pemesanan.
Mengukur dan memantau pemesanan BACKGROUND
Pemesanan akan menentukan jumlah resource compute yang tersedia untuk menjalankan
operasi compute BigQuery. Meremehkan pemesanan dapat
meningkatkan waktu pemrosesan operasi modifikasi baris CDC. Untuk menentukan ukuran
pemesanan secara akurat, pantau pemakaian slot historis untuk project yang
menjalankan operasi CDC dengan membuat kueri
tampilan INFORMATION_SCHEMA.JOBS_TIMELINE:
SELECT period_start, SUM(period_slot_ms) / (1000 * 60) AS slots_used FROM region-REGION.INFORMATION_SCHEMA.JOBS_TIMELINE_BY_PROJECT WHERE DATE(job_creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE '%cdc_background%' GROUP BY period_start ORDER BY period_start DESC;
Ganti REGION dengan
nama region tempat project Anda berada. Misalnya, us.
Pertimbangan data yang dihapus
- Operasi BigQuery CDC menggunakan resource
compute BigQuery. Jika operasi CDC dikonfigurasi untuk menggunakan
penagihan sesuai permintaan, operasi CDC
akan dilakukan secara rutin menggunakan resource BigQuery internal. Jika
operasi CDC dikonfigurasi dengan pemesanan
BACKGROUND, operasi CDC tunduk pada ketersediaan resource pemesanan yang dikonfigurasi. Jika tidak tersedia cukup resource dalam pemesanan yang dikonfigurasi, pemrosesan operasi CDC, termasuk penghapusan, mungkin memerlukan waktu lebih lama daripada yang diperkirakan. - Operasi
DELETECDC dianggap akan diterapkan hanya jika stempel waktuupsert_stream_apply_watermarktelah melewati stempel waktu saat Storage Write API mengalirkan operasi. Untuk mengetahui informasi selengkapnya tentang stempel waktuupsert_stream_apply_watermark, lihat Memantau progres operasi upsert tabel. - Untuk menerapkan operasi
DELETECDC yang tiba tidak berurutan, BigQuery mempertahankan periode retensi penghapusan selama dua hari. Operasi tabelDELETEdisimpan selama periode ini sebelum Google Cloud proses penghapusan data standar dimulai. OperasiDELETEdalam periode retensi penghapusan menggunakan harga penyimpanan BigQuery standar.
Batasan
- BigQuery CDC tidak melakukan penerapan kunci, sehingga kunci utama Anda harus unik.
- Kunci utama tidak boleh lebih dari 16 kolom.
- Tabel yang mendukung CDC tidak boleh memiliki lebih dari 2.000 kolom tingkat teratas yang ditentukan oleh skema tabel.
- Tabel yang mendukung CDC tidak mendukung hal berikut:
- Mengubah pernyataan
bahasa pengolahan data (DML)
seperti
DELETE,UPDATE, danMERGE - Membuat kueri tabel karakter pengganti
- Indeks penelusuran
- Mengubah pernyataan
bahasa pengolahan data (DML)
seperti
- Tabel yang mendukung CDC dan menjalankan tugas penggabungan runtime karena nilai
max_stalenesstabel terlalu rendah tidak dapat mendukung hal berikut: - Operasi ekspor
BigQuery pada tabel yang mendukung CDC tidak mengekspor modifikasi baris yang baru-baru ini di-stream
dan belum diterapkan oleh tugas latar belakang. Untuk mengekspor
tabel lengkap, gunakan pernyataan
EXPORT DATA. - Jika kueri Anda memicu penggabungan runtime pada tabel berpartisi, maka seluruh tabel akan dipindai, terlepas dari apakah kueri dibatasi untuk subset partisi tersebut atau tidak.
- Jika Anda menggunakan edisi Standar,
pemesanan
BACKGROUNDtidak tersedia, sehingga menerapkan modifikasi baris yang tertunda akan menggunakan model harga on demand. Namun, Anda dapat membuat kueri tabel yang mendukung CDC, apa pun edisi Anda. - Kolom semu
_CHANGE_TYPEdan_CHANGE_SEQUENCE_NUMBERbukan kolom yang dapat dikueri saat melakukan pembacaan tabel. - Mencampur baris yang memiliki nilai
UPSERTatauDELETEuntuk_CHANGE_TYPEdengan baris yang memiliki nilaiINSERTatau tidak ditentukan untuk_CHANGE_TYPEdalam koneksi yang sama tidak didukung dan akan menghasilkan error validasi berikut:The given value is not a valid CHANGE_TYPE.
Harga CDC BigQuery
BigQuery CDC menggunakan Storage Write API untuk penyerapan data, penyimpanan BigQuery untuk penyimpanan data, dan compute BigQuery untuk operasi modifikasi baris, yang semuanya dikenai biaya. Untuk mengetahui informasi harga, lihat harga BigQuery.
Memperkirakan biaya CDC BigQuery
Selain praktik terbaik estimasi biaya BigQuery umum, memperkirakan biaya CDC BigQuery mungkin penting untuk alur kerja yang memiliki data dalam jumlah besar, konfigurasi max_staleness rendah, atau data yang sering berubah.
Harga penyerapan data BigQuery dan harga penyimpanan BigQuery dihitung secara langsung berdasarkan jumlah data yang Anda serap dan simpan, termasuk pseudokolom. Namun, harga komputasi BigQuery dapat lebih sulit diperkirakan, karena terkait dengan konsumsi resource komputasi yang digunakan untuk menjalankan tugas CDC BigQuery.
Tugas CDC BigQuery dibagi menjadi tiga kategori:
- Tugas penerapan di latar belakang: tugas yang berjalan di latar belakang dengan interval reguler yang ditentukan oleh nilai
max_stalenesstabel. Tugas ini menerapkan modifikasi baris yang baru-baru ini di-streaming ke dalam tabel yang mendukung CDC. - Pekerjaan kueri: Kueri GoogleSQL yang berjalan dalam jangka waktu
max_stalenessdan hanya membaca dari tabel dasar CDC. - Tugas penggabungan runtime: tugas yang dipicu oleh kueri GoogleSQL ad hoc yang berjalan di luar periode
max_staleness. Tugas ini harus melakukan penggabungan langsung tabel dasar CDC dan modifikasi baris yang baru-baru ini di-streaming pada runtime kueri.
Hanya tugas kueri yang memanfaatkan partisi BigQuery. Tugas penerapan di latar belakang dan tugas penggabungan runtime tidak dapat menggunakan partisi karena, saat menerapkan modifikasi baris yang baru-baru ini di-streaming, tidak ada jaminan ke partisi tabel mana upsert yang baru-baru ini di-streaming akan diterapkan. Dengan kata lain, tabel dasar pengukuran lengkap dibaca selama tugas penerapan di latar belakang dan tugas penggabungan runtime. Untuk alasan yang sama, hanya tugas kueri yang dapat memanfaatkan filter pada kolom pengelompokan BigQuery. Memahami jumlah data yang dibaca untuk melakukan operasi CDC akan membantu memperkirakan total biaya.
Jika jumlah data yang dibaca dari dasar tabel tinggi, pertimbangkan untuk menggunakan model harga kapasitas BigQuery, yang tidak didasarkan pada jumlah data yang diproses.
Praktik terbaik biaya CDC BigQuery
Selain praktik terbaik biaya BigQuery umum, gunakan teknik berikut untuk mengoptimalkan biaya operasi CDC BigQuery:
- Kecuali jika diperlukan, hindari mengonfigurasi opsi
max_stalenesstabel dengan nilai yang sangat rendah. Nilaimax_stalenessdapat meningkatkan terjadinya tugas penerapan di latar belakang dan tugas penggabungan runtime, yang lebih mahal dan lebih lambat daripada tugas kueri. Untuk panduan mendetail, lihat Nilaimax_stalenesstabel yang direkomendasikan. - Pertimbangkan untuk mengonfigurasi
pemesanan BigQuery untuk digunakan dengan tabel CDC.
Jika tidak, tugas penerapan di latar belakang dan tugas penggabungan runtime menggunakan harga sesuai permintaan,
yang bisa lebih mahal karena pemrosesan data yang lebih banyak. Untuk mengetahui detail selengkapnya, pelajari
reservasi BigQuery dan
ikuti panduan tentang
cara menentukan ukuran dan memantau reservasi
BACKGROUNDuntuk digunakan dengan BigQuery CDC.
Langkah berikutnya
- Pelajari cara menerapkan aliran default Storage Write API.
- Pelajari praktik terbaik untuk Storage Write API.
- Pelajari cara menggunakan Datastream untuk mereplikasi database transaksional ke BigQuery dengan BigQuery CDC.