Introdução às transferências do armazenamento de blobs
O Serviço de transferência de dados do BigQuery para o Azure Blob Storage permite-lhe agendar e gerir automaticamente tarefas de carregamento recorrentes do Azure Blob Storage e do Azure Data Lake Storage Gen2 para o BigQuery.
Formatos de ficheiros suportados
Atualmente, o Serviço de transferência de dados do BigQuery suporta o carregamento de dados do Blob Storage nos seguintes formatos:
- Valores separados por vírgulas (.csv)
- JSON (delimitado por newline)
- Avro
- Parquet
- ORC
Tipos de compressão suportados
O Serviço de transferência de dados do BigQuery para o Blob Storage suporta o carregamento de dados comprimidos. Os tipos de compressão suportados pelo Serviço de transferência de dados do BigQuery são os mesmos que os tipos de compressão suportados pelas tarefas de carregamento do BigQuery. Para mais informações, consulte o artigo Carregar dados comprimidos e não comprimidos.
Pré-requisitos de transferência
Para carregar dados de uma origem de dados do armazenamento de blobs, comece por reunir o seguinte:
- O nome da conta de armazenamento de blobs, o nome do contentor e o caminho dos dados (opcional) para os dados de origem. O campo do caminho dos dados é opcional. É usado para fazer corresponder prefixos de objetos comuns e extensões de ficheiros. Se o caminho dos dados for omitido, são transferidos todos os ficheiros no contentor.
- Um token de assinatura de acesso partilhado (SAS) do Azure que concede acesso de leitura à sua origem de dados. Para ver detalhes sobre como criar um token de SAS, consulte o artigo Assinatura de acesso partilhado (SAS).
Transfira a parametrização do tempo de execução
O caminho dos dados do Blob Storage e a tabela de destino podem ser parametrizados, o que lhe permite carregar dados de contentores organizados por data. Os parâmetros usados pelas transferências do Blob Storage são os mesmos que os usados pelas transferências do Cloud Storage. Para ver detalhes, consulte o artigo Parâmetros de tempo de execução nas transferências.
Carregamento de dados para transferências de blobs do Azure
Pode especificar como os dados são carregados no BigQuery selecionando uma preferência de escrita na configuração da transferência quando configura uma transferência de blobs do Azure.
Estão disponíveis dois tipos de preferências de gravação: transferências incrementais e transferências truncadas.Transferências incrementais
Uma configuração de transferência com uma preferência de escrita APPEND ou WRITE_APPEND, também denominada transferência incremental, anexa incrementalmente novos dados desde a transferência bem-sucedida anterior para uma tabela de destino do BigQuery. Quando uma configuração de transferência é executada com uma preferência de escrita APPEND, o Serviço de transferência de dados do BigQuery filtra os ficheiros que foram modificados desde a execução de transferência bem-sucedida anterior. Para determinar quando um ficheiro é modificado, o serviço de transferência de dados do BigQuery analisa os metadados do ficheiro para uma propriedade de "hora da última modificação". Por exemplo, o Serviço de transferência de dados do BigQuery analisa a propriedade de data/hora updated num ficheiro do Cloud Storage. Se o Serviço de transferência de dados do BigQuery encontrar ficheiros com uma "data/hora da última modificação" que tenha ocorrido após a data/hora da última transferência bem-sucedida, o Serviço de transferência de dados do BigQuery transfere esses ficheiros numa transferência incremental.
Para demonstrar como funcionam as transferências incrementais, considere o seguinte exemplo de transferência do Cloud Storage. Um utilizador cria um ficheiro num contentor do Cloud Storage a 01/07/2023 às 00:00 UTC com o nome file_1. A data/hora updated de file_1 é a hora em que o ficheiro foi criado. Em seguida, o utilizador cria uma transferência incremental a partir do contentor do Cloud Storage, agendada para ser executada uma vez por dia às 03:00 UTC, a partir de 01/07/2023 às 03:00 UTC.
- A 2023-07-01T03:00Z, é iniciada a primeira execução da transferência. Como esta é a primeira execução de transferência para esta configuração, o Serviço de transferência de dados do BigQuery tenta carregar todos os ficheiros que correspondem ao URI de origem para a tabela do BigQuery de destino. A execução da transferência é bem-sucedida e o Serviço de transferência de dados do BigQuery carrega
file_1com êxito para a tabela do BigQuery de destino. - A próxima execução da transferência, a 02/07/2023 às 03:00 UTC, não deteta ficheiros em que a propriedade de data/hora
updatedseja superior à da última execução da transferência bem-sucedida (01/07/2023 às 03:00 UTC). A execução da transferência é bem-sucedida sem carregar dados adicionais para a tabela do BigQuery de destino.
O exemplo anterior mostra como o Serviço de transferência de dados do BigQuery analisa a propriedade de data/hora do ficheiro de origem para determinar se foram feitas alterações aos ficheiros de origem e transferir essas alterações, se forem detetadas.updated
Seguindo o mesmo exemplo, suponhamos que o utilizador cria outro ficheiro no contentor do Cloud Storage às 2023-07-03T00:00Z, denominado file_2. A data/hora updated de file_2 é a hora em que o ficheiro foi criado.
- A próxima execução da transferência, a 03-07-2023 às 03:00 Z, deteta que
file_2tem uma data/horaupdatedsuperior à da última execução da transferência bem-sucedida (01-07-2023 às 03:00 Z). Suponhamos que, quando a execução da transferência é iniciada, falha devido a um erro temporário. Neste cenário,file_2não é carregado na tabela do BigQuery de destino. A data/hora da última execução de transferência bem-sucedida permanece em 2023-07-01T03:00Z. - A próxima execução da transferência, a 04/07/2023 às 03:00 Z, deteta que
file_2tem uma data/horaupdatedsuperior à da última execução da transferência bem-sucedida (01/07/2023 às 03:00 Z). Desta vez, a execução da transferência é concluída sem problemas, pelo que carregafile_2com êxito para a tabela de destino do BigQuery. - A próxima execução da transferência, a 05/07/2023 às 03:00 UTC, não deteta ficheiros em que a data/hora
updatedseja posterior à da última execução da transferência bem-sucedida (04/07/2023 às 03:00 UTC). A execução da transferência é bem-sucedida sem carregar dados adicionais para a tabela do BigQuery de destino.
O exemplo anterior mostra que, quando uma transferência falha, não são transferidos ficheiros para a tabela de destino do BigQuery. Todas as alterações aos ficheiros são transferidas na próxima execução de transferência bem-sucedida. As transferências bem-sucedidas subsequentes após uma transferência com falha não causam dados duplicados. No caso de uma transferência falhada, também pode optar por acionar manualmente uma transferência fora da hora agendada regularmente.
Transferências truncadas
Uma configuração de transferência com uma preferência de escrita MIRROR ou WRITE_TRUNCATE, também denominada transferência truncada, substitui os dados na tabela de destino do BigQuery durante cada execução de transferência com dados de todos os ficheiros que correspondem ao URI de origem. MIRROR substitui uma nova cópia dos dados na tabela de destino. Se a tabela de destino estiver a usar um decorador de partição, a execução da transferência apenas substitui os dados na partição especificada. Uma tabela de destino com um decorador de partição tem o formato
my_table${run_date}, por exemplo, my_table$20230809.
A repetição das mesmas transferências incrementais ou truncadas num dia não causa dados duplicados. No entanto, se executar várias configurações de transferência diferentes que afetem a mesma tabela de destino do BigQuery, isto pode fazer com que o Serviço de transferência de dados do BigQuery duplique os dados.
Suporte de carateres universais para o caminho de dados do armazenamento de blobs
Pode selecionar dados de origem separados em vários ficheiros especificando um ou mais carateres universais (*) no caminho dos dados.
Embora seja possível usar mais do que um caráter universal no caminho de dados, é possível fazer alguma otimização quando é usado apenas um caráter universal:
- Existe um limite superior no número máximo de ficheiros por execução de transferência.
- O caráter universal abrange os limites do diretório. Por exemplo, o caminho de dados
my-folder/*.csvcorresponde ao ficheiromy-folder/my-subfolder/my-file.csv.
Exemplos de caminhos de dados do Blob Storage
Seguem-se exemplos de caminhos de dados válidos para uma transferência do
Armazenamento de blobs. Tenha em atenção que os caminhos de dados não começam com /.
Exemplo: ficheiro único
Para carregar um único ficheiro do Blob Storage para o BigQuery, especifique o nome do ficheiro do Blob Storage:
my-folder/my-file.csv
Exemplo: todos os ficheiros
Para carregar todos os ficheiros de um contentor do Blob Storage para o BigQuery, defina o caminho dos dados para um único caráter universal:
*
Exemplo: ficheiros com um prefixo comum
Para carregar todos os ficheiros do armazenamento de blobs que partilham um prefixo comum, especifique o prefixo comum com ou sem um caráter universal:
my-folder/
ou
my-folder/*
Exemplo: ficheiros com um caminho semelhante
Para carregar todos os ficheiros do Blob Storage com um caminho semelhante, especifique o prefixo e o sufixo comuns:
my-folder/*.csv
Quando usa apenas um caráter universal, este abrange diretórios. Neste exemplo, todos os ficheiros CSV em my-folder são selecionados, bem como todos os ficheiros CSV em todas as subpastas de my-folder.
Exemplo: caráter universal no final do caminho
Considere o seguinte caminho de dados:
logs/*
Estão selecionados todos os seguintes ficheiros:
logs/logs.csv
logs/system/logs.csv
logs/some-application/system_logs.log
logs/logs_2019_12_12.csv
Exemplo: carater universal no início do caminho
Considere o seguinte caminho de dados:
*logs.csv
Estão selecionados todos os seguintes ficheiros:
logs.csv
system/logs.csv
some-application/logs.csv
E nenhum dos seguintes ficheiros está selecionado:
metadata.csv
system/users.csv
some-application/output.csv
Exemplo: vários carateres universais
Ao usar vários carateres universais, ganha mais controlo sobre a seleção de ficheiros, ao custo de limites inferiores. Quando usa vários carateres universais, cada caráter universal individual abrange apenas um único subdiretório.
Considere o seguinte caminho de dados:
*/*.csv
Ambos os ficheiros seguintes estão selecionados:
my-folder1/my-file1.csv
my-other-folder2/my-file2.csv
E nenhum dos seguintes ficheiros está selecionado:
my-folder1/my-subfolder/my-file3.csv
my-other-folder2/my-subfolder/my-file4.csv
Assinatura de acesso partilhado (SAS)
O token SAS do Azure é usado para aceder aos dados do Blob Storage em seu nome. Siga os passos abaixo para criar um token SAS para a sua transferência:
- Crie ou use um utilizador do armazenamento de blobs existente para aceder à conta de armazenamento do contentor de armazenamento de blobs.
Crie um token SAS ao nível da conta de armazenamento. Para criar um token SAS com o Azure Portal, faça o seguinte:
- Para Serviços permitidos, selecione Blob.
- Para Tipos de recursos permitidos, selecione Contentor e Objeto.
- Para Autorizações permitidas, selecione Ler e Lista.
- O tempo de expiração predefinido para tokens SAS é de 8 horas. Defina uma hora de expiração adequada para o seu horário de transferências.
- Não especifique endereços IP no campo Endereços IP permitidos.
- Em Protocolos permitidos, selecione Apenas HTTPS.
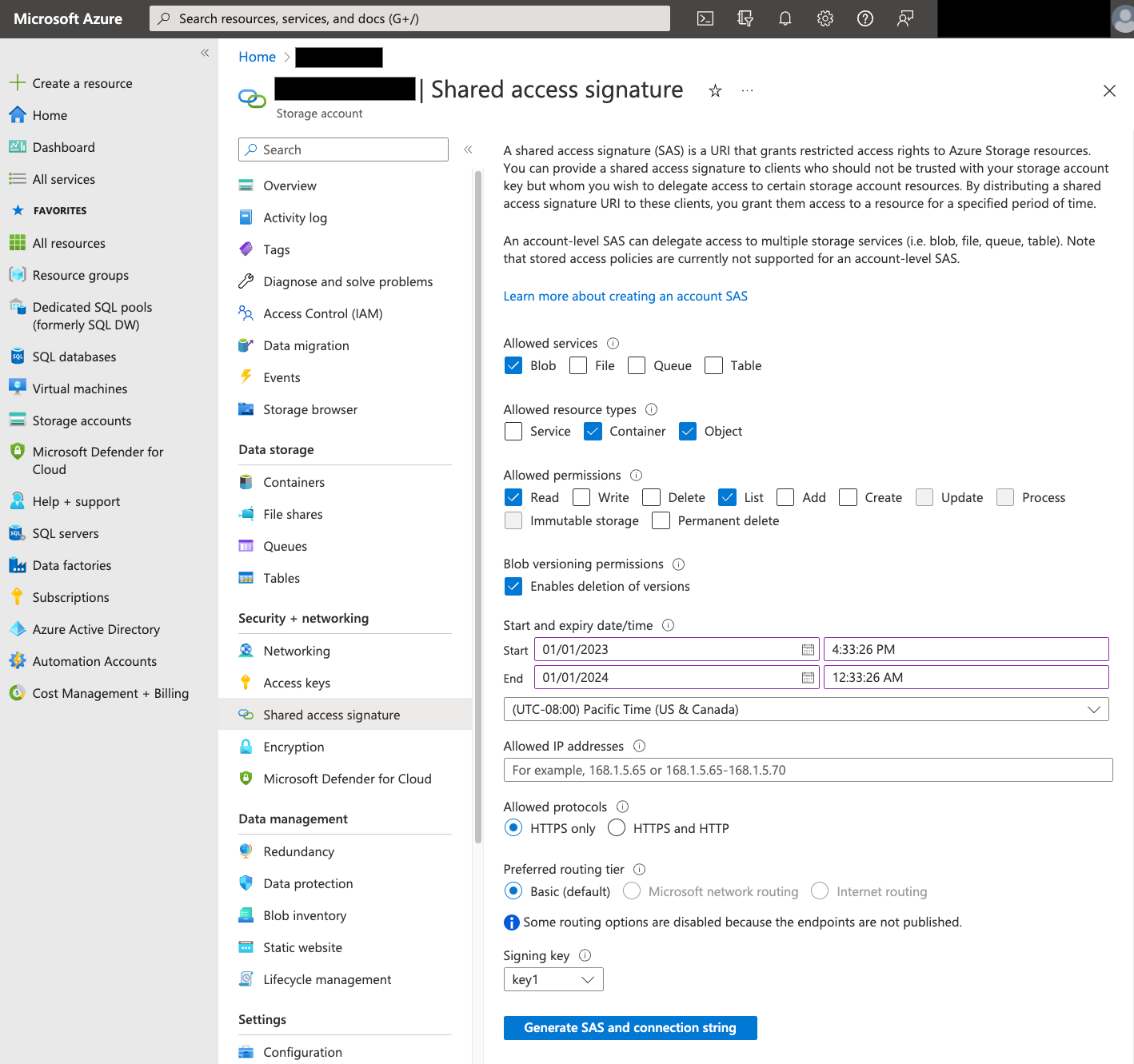
Depois de criar o token SAS, tome nota do valor do token SAS devolvido. Precisa deste valor quando configura transferências.
Restrições de IP
Se restringir o acesso aos seus recursos do Azure através de uma firewall do Azure Storage, tem de adicionar os intervalos de IP usados pelos trabalhadores do Serviço de transferência de dados do BigQuery à sua lista de IPs permitidos.
Para adicionar intervalos de IP como IPs permitidos às firewalls do Azure Storage, consulte o artigo Restrições de IP.
Considerações de consistência
Um ficheiro demora aproximadamente 5 minutos a ficar disponível para o Serviço de transferência de dados do BigQuery depois de ser adicionado ao contentor do armazenamento de blobs.
Práticas recomendadas para controlar os custos de saída
As transferências do Blob Storage podem falhar se a tabela de destino não estiver configurada corretamente. Seguem-se algumas causas possíveis de uma configuração inadequada:
- A tabela de destino não existe.
- O esquema da tabela não está definido.
- O esquema da tabela não é compatível com os dados que estão a ser transferidos.
Para evitar custos de saída do Blob Storage adicionais, teste primeiro uma transferência com um subconjunto de ficheiros pequeno, mas representativo. Certifique-se de que este teste é pequeno em termos de tamanho dos dados e número de ficheiros.
Também é importante ter em atenção que a correspondência de prefixos para caminhos de dados ocorre antes de os ficheiros serem transferidos do armazenamento de blobs, mas a correspondência com carateres universais ocorre no interior do Google Cloud. Esta distinção pode aumentar os custos de saída do armazenamento de blobs para ficheiros transferidos para o Google Cloud , mas não carregados no BigQuery.
Por exemplo, considere este caminho de dados:
folder/*/subfolder/*.csv
Os dois ficheiros seguintes são transferidos para Google Cloudporque têm o prefixo folder/:
folder/any/subfolder/file1.csv
folder/file2.csv
No entanto, apenas o ficheiro folder/any/subfolder/file1.csv é carregado no BigQuery, porque corresponde ao caminho de dados completo.
Preços
Para mais informações, consulte os preços do Serviço de transferência de dados do BigQuery.
Também pode incorrer em custos fora da Google ao usar este serviço. Para mais informações, consulte os preços do armazenamento de blobs.
Quotas e limites
O Serviço de transferência de dados do BigQuery usa tarefas de carregamento para carregar dados do Blob Storage para o BigQuery. Todas as quotas e os limites do BigQuery em tarefas de carregamento aplicam-se a transferências recorrentes do Armazenamento de blobs, com as seguintes considerações adicionais:
| Limite | Predefinição |
|---|---|
| Tamanho máximo por execução de transferência de tarefa de carregamento | 15 TB |
| Número máximo de ficheiros por execução de transferência quando o caminho de dados do armazenamento de blobs inclui 0 ou 1 carateres universais | 10 000 000 de ficheiros |
| Número máximo de ficheiros por execução de transferência quando o caminho de dados do armazenamento de blobs inclui 2 ou mais carateres universais | 10 000 ficheiros |
O que se segue?
- Saiba como configurar uma transferência do Blob Storage.
- Saiba mais acerca dos parâmetros de tempo de execução nas transferências.
- Saiba mais acerca do Serviço de transferência de dados do BigQuery.