Einführung in Blob Storage-Übertragungen
Mit dem BigQuery Data Transfer Service für Azure Blob Storage können Sie wiederkehrende Ladejobs von Azure Blob Storage und Azure Data Lake Storage Gen2 automatisch in BigQuery planen und verwalten.
Unterstützte Dateiformate
Derzeit unterstützt BigQuery Data Transfer Service das Laden von Daten aus Blob Storage in den folgenden Formaten:
- Kommagetrennte Werte (CSV)
- JSON (durch Zeilenvorschub getrennt)
- Avro
- Parquet
- ORC
Unterstützte Komprimierungstypen
Der BigQuery Data Transfer Service für Blob Storage unterstützt das Laden komprimierter Daten. Die Komprimierungstypen, die von BigQuery Data Transfer Service unterstützt werden, sind mit jenen identisch, die von BigQuery-Ladejobs unterstützt werden. Weitere Informationen finden Sie unter Komprimierte und unkomprimierte Daten laden.
Voraussetzungen für die Übertragung
Wenn Sie Daten aus einer Blob Storage-Datenquelle laden möchten, erfassen Sie zuerst Folgendes:
- Den Blob Storage-Kontonamen, den Containernamen und den Datenpfad (optional) für Ihre Quelldaten. Das Feld für den Datenpfad ist optional; es wird zum Abgleichen gängiger Objektpräfixe und Dateiendungen verwendet. Wenn der Datenpfad weggelassen wird, werden alle Dateien im Container übertragen.
- Ein Shared Access Signature-Token (SAS) für Azure, das Lesezugriff auf Ihre Datenquelle gewährt. Weitere Informationen zum Erstellen eines SAS-Tokens finden Sie unter Shared Access Signature (SAS).
Laufzeitparametrisierung für die Übertragung
Der Blob Storage-Datenpfad und die Zieltabelle lassen sich parametrisieren, um Daten geordnet nach Datum aus Containern zu laden. Die von Blob Storage-Übertragungen verwendeten Parameter sind die gleichen wie die von Cloud Storage-Übertragungen. Weitere Informationen finden Sie unter Laufzeitparameter in Übertragungen.
Datenaufnahme für Azure Blob-Übertragungen
Sie können angeben, wie Daten in BigQuery geladen werden. Wählen Sie dazu beim Einrichten einer Azure Blob-Übertragung eine Schreibeinstellung in der Übertragungskonfiguration aus.
Es gibt zwei Arten von Schreibeinstellungen: inkrementelle Übertragungen und abgeschnittene Übertragungen.Inkrementelle Übertragungen
Eine Übertragungskonfiguration mit der Schreibeinstellung APPEND oder WRITE_APPEND, auch inkrementelle Übertragung genannt, fügt inkrementell neue Daten seit der letzten erfolgreichen Übertragung an eine BigQuery-Zieltabelle an. Wenn eine Übertragungskonfiguration mit der Schreibeinstellung APPEND ausgeführt wird, filtert BigQuery Data Transfer Service nach Dateien, die seit dem letzten erfolgreichen Übertragungslauf geändert wurden. Um zu ermitteln, wann eine Datei geändert wird, prüft BigQuery Data Transfer Service die Dateimetadaten auf das Attribut „Zeitpunkt der letzten Änderung“. BigQuery Data Transfer Service prüft beispielsweise das Zeitstempelattribut updated in einer Cloud Storage-Datei. Wenn BigQuery Data Transfer Service Dateien mit einem „Zeitpunkt der letzten Änderung“ findet, der nach dem Zeitstempel der letzten erfolgreichen Übertragung aufgetreten ist, überträgt BigQuery Data Transfer Service diese Dateien inkrementell.
Sehen Sie sich das folgende Beispiel für eine Cloud Storage-Übertragung an, um die Funktionsweise inkrementeller Übertragungen zu veranschaulichen. Ein Nutzer erstellt zum Zeitpunkt 2023-07-01T00:00Z in einem Cloud Storage-Bucket eine Datei namens file_1. Der Zeitstempel updated für file_1 ist der Zeitpunkt, zu dem die Datei erstellt wurde. Der Nutzer erstellt dann eine inkrementelle Übertragung aus dem Cloud Storage-Bucket, der ab 2023-07-01T03:00Z einmal täglich um 03:00Z ausgeführt wird.
- Zum Zeitpunkt 2023-07-01T03:00Z beginnt die erste Übertragungsausführung. Da dies die erste Übertragungsausführung für diese Konfiguration ist, versucht BigQuery Data Transfer Service, alle Dateien, die mit dem Quell-URI übereinstimmen, in die BigQuery-Zieltabelle zu laden. Die Übertragungsausführung ist erfolgreich und BigQuery Data Transfer Service lädt
file_1erfolgreich in die BigQuery-Zieltabelle. - Die nächste Übertragungsausführung zum Zeitpunkt 2023-07-02T03:00Z erkennt keine Dateien, bei denen das Zeitstempelattribut
updatedgrößer als die letzte erfolgreiche Übertragungsausführung ist (2023-07-01T03:00Z). Die Übertragungsausführung ist erfolgreich, ohne zusätzliche Daten in die BigQuery-Zieltabelle zu laden.
Das vorherige Beispiel zeigt, wie BigQuery Data Transfer Service das Zeitstempelattribut updated der Quelldatei prüft, um festzustellen, ob Änderungen an den Quelldateien vorgenommen wurden, und um diese Änderungen zu übertragen, falls welche erkannt wurden.
Angenommen, der Nutzer erstellt dann zum Zeitpunkt 2023-07-03T00:00Z im Cloud Storage-Bucket eine weitere Datei mit dem Namen file_2. Der Zeitstempel updated für file_2 ist der Zeitpunkt, zu dem die Datei erstellt wurde.
- Die nächste Übertragungsausführung zum Zeitpunkt 2023-07-03T03:00Z erkennt, dass
file_2einenupdated-Zeitstempel hat, der größer als die letzte erfolgreiche Übertragungsausführung ist (2023-07-01T03:00Z). Angenommen, die Übertragungsausführung schlägt aufgrund eines vorübergehenden Fehlers fehl. In diesem Szenario wirdfile_2nicht in die BigQuery-Zieltabelle geladen. Der Zeitstempel der letzten erfolgreichen Übertragungsausführung bleibt bei 2023-07-01T03:00Z. - Die nächste Übertragungsausführung zum Zeitpunkt 2023-07-04T03:00Z erkennt, dass
file_2einenupdated-Zeitstempel hat, der größer als die letzte erfolgreiche Übertragungsausführung ist (2023-07-01T03:00Z). Dieses Mal wird die Übertragung ohne Probleme abgeschlossen. Daher wirdfile_2erfolgreich in die BigQuery-Zieltabelle geladen. - Die nächste Übertragungsausführung zum Zeitpunkt 2023-07-05T03:00Z erkennt keine Dateien, bei denen der
updated-Zeitstempel größer als die letzte erfolgreiche Übertragungsausführung ist (2023-07-04T03:00Z). Die Übertragungsausführung ist erfolgreich, ohne zusätzliche Daten in die BigQuery-Zieltabelle zu laden.
Das vorherige Beispiel zeigt, dass bei einer fehlgeschlagenen Übertragung keine Dateien in die BigQuery-Zieltabelle übertragen werden. Alle Dateiänderungen werden bei der nächsten erfolgreichen Übertragungsausführung übertragen. Alle nachfolgenden erfolgreichen Übertragungen nach einer fehlgeschlagenen Übertragung verursachen keine doppelten Daten. Bei einer fehlgeschlagenen Übertragung können Sie auch außerhalb der regelmäßig geplanten Zeit eine Übertragung manuell auslösen.
Abgeschnittene Übertragungen
Eine Übertragungskonfiguration mit der Schreibpräferenz MIRROR oder WRITE_TRUNCATE, auch als abgeschnittene Übertragung bezeichnet, überschreibt die Daten in der BigQuery-Zieltabelle bei jedem Übertragungslauf mit Daten aus allen Dateien, die dem Quell-URI entsprechen. MIRROR überschreibt eine neue Kopie der Daten in der Zieltabelle. Wenn die Zieltabelle einen Partitions-Decorator verwendet, überschreibt die Übertragungsausführung nur Daten in der angegebenen Partition. Eine Zieltabelle mit einem Partitions-Decorator hat das Format my_table${run_date}, z. B. my_table$20230809.
Die Ausführung derselben inkrementellen oder abgeschnittenen Übertragungen pro Tag führt nicht zu doppelten Daten. Wenn Sie jedoch mehrere verschiedene Übertragungskonfigurationen ausführen, die sich auf dieselbe BigQuery-Zieltabelle auswirken, kann der BigQuery Data Transfer Service dazu führen, dass Daten dupliziert werden.
Unterstützung von Platzhaltern für den Datenpfad von Blob Storage
Sie können Quelldaten auswählen, die in mehrere Dateien aufgeteilt sind, indem Sie im Datenpfad ein oder mehrere Sternchen (*) als Platzhalter angeben.
Obwohl im Datenpfad mehr als ein Platzhalter verwendet werden kann, ist eine Optimierung möglich, wenn nur ein einzelner Platzhalter verwendet wird:
- Es gibt ein höheres Limit für die maximale Anzahl von Dateien pro Übertragungsausführung.
- Der Platzhalter reicht über Verzeichnisgrenzen hinweg. Der Datenpfad
my-folder/*.csvstimmt beispielsweise mit der Dateimy-folder/my-subfolder/my-file.csvüberein.
Beispiele für Datenpfade von Blob Storage
Im Folgenden finden Sie Beispiele für gültige Datenpfade für eine Blob Storage-Übertragung. Datenpfade beginnen nicht mit /.
Beispiel: Einzelne Datei
Geben Sie den Blob Storage-Dateinamen an, um eine einzelne Datei aus Blob Storage in BigQuery zu laden:
my-folder/my-file.csv
Beispiel: Alle Dateien
Zum Laden aller Dateien aus einem Blob Storage-Container in BigQuery legen Sie den Datenpfad auf einen einzelnen Platzhalter fest:
*
Beispiel: Dateien mit einem gemeinsamen Präfix
Wenn Sie aus Blob Storage alle Dateien mit einem gemeinsamen Präfix laden möchten, geben Sie das gemeinsame Präfix mit oder ohne Platzhalter an:
my-folder/
oder
my-folder/*
Beispiel: Dateien mit einem ähnlichen Pfad
Wenn Sie aus Blob Storage alle Dateien mit einem ähnlichen Pfad laden möchten, geben Sie das gemeinsame Präfix und Suffix an:
my-folder/*.csv
Wenn Sie nur einen einzelnen Platzhalter verwenden, erstreckt sich dieser über Verzeichnisse. In diesem Beispiel ist jede CSV-Datei in my-folder sowie jede CSV-Datei in jedem Unterordner von my-folder ausgewählt.
Beispiel: Platzhalter am Ende des Pfads
Sehen Sie sich den folgenden Datenpfad an:
logs/*
Alle folgenden Dateien sind ausgewählt:
logs/logs.csv
logs/system/logs.csv
logs/some-application/system_logs.log
logs/logs_2019_12_12.csv
Beispiel: Platzhalter am Anfang des Pfads
Sehen Sie sich den folgenden Datenpfad an:
*logs.csv
Alle folgenden Dateien sind ausgewählt:
logs.csv
system/logs.csv
some-application/logs.csv
Keine der folgenden Dateien ist ausgewählt:
metadata.csv
system/users.csv
some-application/output.csv
Beispiel: Mehrere Platzhalter
Durch die Verwendung mehrerer Platzhalter haben Sie mehr Kontrolle über die Dateiauswahl. Dafür müssen Sie jedoch niedrigere Limits einplanen. Wenn Sie mehrere Platzhalter verwenden, umfasst jeder einzelne Platzhalter nur ein einzelnes Unterverzeichnis.
Sehen Sie sich den folgenden Datenpfad an:
*/*.csv
Die beiden folgenden Dateien werden ausgewählt:
my-folder1/my-file1.csv
my-other-folder2/my-file2.csv
Außerdem ist keine der folgenden Dateien ausgewählt:
my-folder1/my-subfolder/my-file3.csv
my-other-folder2/my-subfolder/my-file4.csv
Shared Access Signature (SAS)
Das Azure SAS-Token wird verwendet, um in Ihrem Namen auf Blob Storage-Daten zuzugreifen. Gehen Sie folgendermaßen vor, um ein SAS-Token für Ihre Übertragung zu erstellen:
- Erstellen oder verwenden Sie einen vorhandenen Blob Storage-Nutzer, um auf das Speicherkonto für Ihren Blob Storage-Container zuzugreifen.
Erstellen Sie ein SAS-Token auf Speicherkontoebene. So erstellen Sie ein SAS-Token mit dem Azure-Portal:
- Wählen Sie für Zulässige Dienste die Option Blob aus.
- Wählen Sie unter Zulässige Ressourcentypen sowohl Container als auch Objekt aus.
- Wählen Sie für Zulässige Berechtigungen die Option Lesen und Liste aus.
- Die Standardablaufzeit für SAS-Tokens beträgt 8 Stunden. Legen Sie eine Ablaufzeit fest, die für Ihren Übertragungsplan funktioniert.
- Geben Sie im Feld Zulässige IP-Adressen keine IP-Adressen an.
- Wählen Sie für Zulässige Protokolle die Option Nur HTTPS aus.
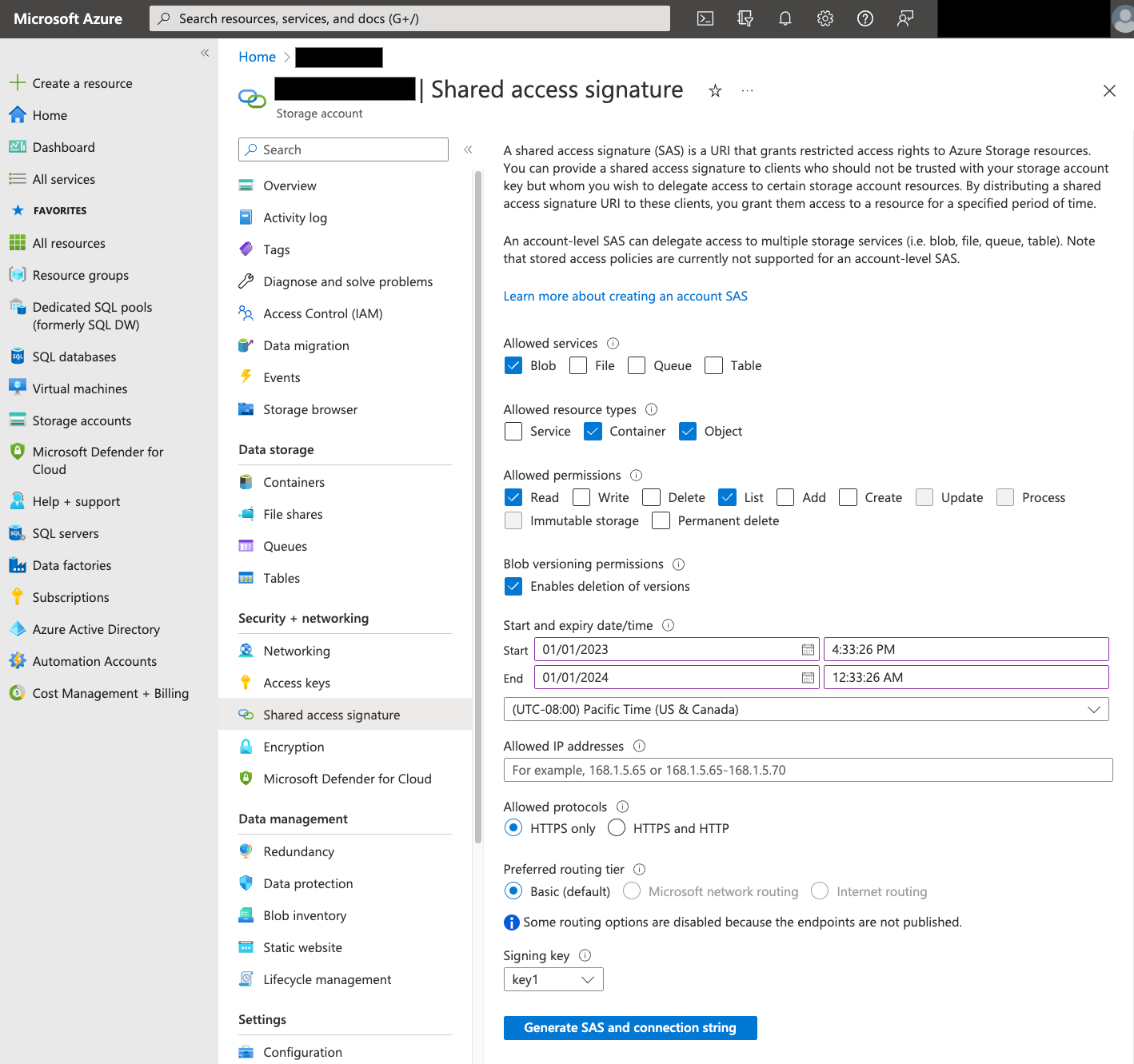
Notieren Sie sich nach dem Erstellen des SAS-Tokens den zurückgegebenen Wert für SAS-Token. Sie benötigen diesen Wert, wenn Sie Übertragungen konfigurieren.
IP-Einschränkungen
Wenn Sie den Zugriff auf Ihre Azure-Ressourcen über eine Azure Storage-Firewall beschränken, müssen Sie die von BigQuery Data Transfer Service-Workern verwendeten IP-Bereiche der Liste der zulässigen IP-Adressen hinzufügen.
Informationen zum Hinzufügen von IP-Bereichen als zulässige IP-Adressen zu Azure Storage-Firewalls finden Sie unter IP-Einschränkungen.
Überlegungen zur Konsistenz
Es sollte ungefähr 5 Minuten dauern, bis eine Datei für BigQuery Data Transfer Service verfügbar ist, nachdem sie dem Blob Storage-Container hinzugefügt wurde.
Best Practices zur Kostenkontrolle für ausgehenden Traffic
Übertragungen aus Blob Storage können fehlschlagen, wenn die Zieltabelle nicht richtig konfiguriert ist. Mögliche Gründe für eine fehlerhafte Konfiguration sind:
- Die Zieltabelle ist nicht vorhanden.
- Das Tabellenschema ist nicht definiert.
- Das Tabellenschema ist nicht mit den übertragenen Daten kompatibel.
Testen Sie zuerst eine Übertragung mit einer kleinen, aber repräsentativen Teilmenge von Dateien, um zusätzliche Kosten für ausgehenden Blob Storage-Traffic zu vermeiden. Achten Sie darauf, dass dieser Test sowohl bezüglich der Datengröße als auch der Anzahl der Dateien klein ist.
Beachten Sie auch, dass der Präfixabgleich für Datenpfade erfolgt, bevor Dateien aus Blob Storage übertragen werden. Der Platzhalterabgleich erfolgt jedoch in Google Cloud. Diese Unterscheidung kann die Kosten für ausgehenden Blob Storage-Traffic für Dateien erhöhen, die anGoogle Cloud übertragen, aber nicht in BigQuery geladen werden.
Sehen Sie sich als Beispiel diesen Datenpfad an:
folder/*/subfolder/*.csv
Die beiden folgenden Dateien werden an Google Cloudübertragen, da sie das Präfix folder/ haben:
folder/any/subfolder/file1.csv
folder/file2.csv
Es wird jedoch nur die Datei folder/any/subfolder/file1.csv in BigQuery geladen, da sie mit dem vollständigen Datenpfad übereinstimmt.
Preise
Weitere Informationen finden Sie unter Preise für BigQuery Data Transfer Service.
Durch die Nutzung dieses Dienstes können auch Kosten außerhalb von Google anfallen. Weitere Informationen finden Sie unter Blob Storage – Preise.
Kontingente und Limits
BigQuery Data Transfer Service nutzt Ladejobs, um Blob Storage-Daten in BigQuery zu laden. Alle BigQuery-Kontingente und -Limits für Ladejobs gelten für wiederkehrende Blob Storage-Übertragungen. Dabei ist Folgendes zu beachten:
| Limit | Standard |
|---|---|
| Maximale Größe pro Ladejob-Übertragungsausführung | 15 TB |
| Maximale Anzahl von Dateien pro Übertragung, wenn der Blob Storage-Datenpfad 0 oder 1 Platzhalter enthält | 10.000.000 Dateien |
| Maximale Anzahl von Dateien pro Übertragung, wenn der Blob Storage-Datenpfad 2 oder mehr Platzhalter enthält | 10.000 Dateien |
Nächste Schritte
- Weitere Informationen zum Einrichten einer Blob Storage-Übertragung
- Weitere Informationen zu Laufzeitparametern für Übertragungen
- Weitere Informationen zum BigQuery Data Transfer Service