Introducción a las transferencias de Blob Storage
BigQuery Data Transfer Service para Azure Blob Storage te permite programar y gestionar automáticamente las tareas de carga periódicas de Azure Blob Storage y Azure Data Lake Storage Gen2 en BigQuery.
Formatos de archivo admitidos
Actualmente, BigQuery Data Transfer Service permite cargar datos de Blob Storage en los siguientes formatos:
- Valores separados por comas (CSV)
- JSON (delimitado por líneas nuevas)
- Avro
- Parquet
- ORC
Tipos de compresión admitidos
BigQuery Data Transfer Service para Blob Storage admite la carga de datos comprimidos. Los tipos de compresión admitidos por BigQuery Data Transfer Service son los mismos que los admitidos por las tareas de carga de BigQuery. Para obtener más información, consulta Cargar datos comprimidos y sin comprimir.
Requisitos para transferir dominios
Para cargar datos de una fuente de datos de Blob Storage, primero debes reunir lo siguiente:
- El nombre de la cuenta de Blob Storage, el nombre del contenedor y la ruta de datos (opcional) de los datos de origen. El campo de ruta de datos es opcional y se usa para hacer coincidir prefijos de objetos y extensiones de archivo comunes. Si se omite la ruta de datos, se transferirán todos los archivos del contenedor.
- Un token de firma de acceso compartido (SAS) de Azure que concede acceso de lectura a tu fuente de datos. Para obtener información sobre cómo crear un token de SAS, consulta Firma de acceso compartido (SAS).
Transferir la parametrización del tiempo de ejecución
La ruta de datos de Blob Storage y la tabla de destino se pueden parametrizar, lo que te permite cargar datos de contenedores organizados por fecha. Los parámetros que usan las transferencias de Blob Storage son los mismos que los que usan las transferencias de Cloud Storage. Para obtener más información, consulta Parámetros de tiempo de ejecución en transferencias.
Ingestión de datos para transferencias de Azure Blob
Puede especificar cómo se cargan los datos en BigQuery seleccionando una preferencia de escritura en la configuración de la transferencia al configurar una transferencia de Azure Blob.
Hay dos tipos de preferencias de escritura disponibles: transferencias incrementales y transferencias truncadas.Transferencias incrementales
Una configuración de transferencia con una preferencia de escritura APPEND o WRITE_APPEND, también denominada transferencia incremental, añade de forma incremental los datos nuevos desde la transferencia correcta anterior a una tabla de destino de BigQuery. Cuando se ejecuta una configuración de transferencia con la preferencia de escritura APPEND, BigQuery Data Transfer Service filtra los archivos que se han modificado desde la ejecución de transferencia anterior. Para determinar cuándo se modifica un archivo, BigQuery Data Transfer Service consulta los metadatos del archivo para ver la propiedad "hora de última modificación". Por ejemplo, BigQuery Data Transfer Service consulta la propiedad de marca de tiempo updated
de un archivo de Cloud Storage. Si BigQuery Data Transfer Service encuentra algún archivo con una marca de tiempo de última modificación posterior a la de la última transferencia correcta, BigQuery Data Transfer Service transferirá esos archivos en una transferencia incremental.
Para mostrar cómo funcionan las transferencias incrementales, vamos a ver el siguiente ejemplo de transferencia de Cloud Storage. Un usuario crea un archivo en un segmento de Cloud Storage a las 00:00 del 1 de julio del 2023 (2023-07-01T00:00Z) llamado file_1. La updated marca de tiempo de file_1 es la hora en la que se creó el archivo. A continuación, el usuario crea una transferencia incremental desde el bucket de Cloud Storage, programada para ejecutarse una vez al día a las 03:00 UTC, a partir del 1 de julio del 2023 a las 03:00 UTC.
- A las 2023-07-01T03:00Z, se inicia la primera ejecución de transferencia. Como esta es la primera ejecución de transferencia de esta configuración, BigQuery Data Transfer Service intenta cargar todos los archivos que coincidan con el URI de origen en la tabla de BigQuery de destino. La ejecución de la transferencia se completa correctamente y BigQuery Data Transfer Service carga
file_1en la tabla de BigQuery de destino. - En la siguiente ejecución de la transferencia, el 2023-07-02T03:00Z, no se detectan archivos en los que la propiedad de marca de tiempo
updatedsea posterior a la de la última ejecución de la transferencia (2023-07-01T03:00Z). La ejecución de la transferencia se realiza correctamente sin cargar datos adicionales en la tabla de BigQuery de destino.
En el ejemplo anterior se muestra cómo BigQuery Data Transfer Service consulta la propiedad de marca de tiempo updated del archivo de origen para determinar si se han realizado cambios en los archivos de origen y transferir esos cambios si se detectan.
Siguiendo el mismo ejemplo, supongamos que el usuario crea otro archivo en el segmento de Cloud Storage a las 00:00 del 3 de julio del 2023, llamado file_2. La updated marca de tiempo de file_2 es la hora en la que se creó el archivo.
- En la siguiente ejecución de la transferencia, el 3 de julio del 2023 a las 03:00 UTC, se detecta que
file_2tiene una marca de tiempoupdatedposterior a la de la última ejecución de la transferencia (1 de julio del 2023 a las 03:00 UTC). Supongamos que, cuando se inicia la ejecución de la transferencia, falla debido a un error transitorio. En este caso,file_2no se carga en la tabla de BigQuery de destino. La marca de tiempo de la última transferencia correcta sigue siendo 2023-07-01T03:00Z. - En la siguiente ejecución de la transferencia, el 4 de julio del 2023 a las 03:00 (UTC), se detecta que
file_2tiene una marca de tiempoupdatedposterior a la de la última ejecución de la transferencia correcta (el 1 de julio del 2023 a las 03:00 [UTC]). Esta vez, la ejecución de la transferencia se completa sin problemas, por lo quefile_2se carga correctamente en la tabla de BigQuery de destino. - En la siguiente ejecución de la transferencia, el 5 de julio del 2023 a las 03:00 UTC, no se detectan archivos cuya marca de tiempo
updatedsea posterior a la de la última ejecución de la transferencia (4 de julio del 2023 a las 03:00 UTC). La ejecución de la transferencia se completa correctamente sin cargar datos adicionales en la tabla de BigQuery de destino.
En el ejemplo anterior se muestra que, cuando falla una transferencia, no se transfiere ningún archivo a la tabla de destino de BigQuery. Los cambios en los archivos se transfieren en la siguiente transferencia correcta. Las transferencias posteriores que se realicen correctamente después de una transferencia fallida no provocarán que se dupliquen los datos. Si la transferencia falla, también puede iniciarla manualmente fuera del horario programado.
Transferencias truncadas
Una configuración de transferencia con una preferencia de escritura MIRROR o WRITE_TRUNCATE, también denominada transferencia truncada, sobrescribe los datos de la tabla de destino de BigQuery durante cada ejecución de la transferencia con los datos de todos los archivos que coincidan con el URI de origen. MIRROR sobrescribe una copia nueva de los datos de la tabla de destino. Si la tabla de destino usa un decorador de partición, la transferencia solo sobrescribe los datos de la partición especificada. Una tabla de destino con un decorador de partición tiene el formato my_table${run_date}, por ejemplo, my_table$20230809.
Si repites las mismas transferencias incrementales o truncadas en un día, no se duplicarán los datos. Sin embargo, si ejecutas varias configuraciones de transferencia diferentes que afectan a la misma tabla de destino de BigQuery, BigQuery Data Transfer Service puede duplicar los datos.
Compatibilidad con comodines en la ruta de datos de Blob Storage
Puedes seleccionar datos de origen que estén separados en varios archivos especificando uno o varios caracteres comodín de asterisco (*) en la ruta de datos.
Aunque se puede usar más de un comodín en la ruta de datos, se puede optimizar el proceso si solo se usa un comodín:
- Hay un límite superior en el número máximo de archivos por transferencia.
- El comodín abarcará los límites del directorio. Por ejemplo, la ruta de datos
my-folder/*.csvcoincidirá con el archivomy-folder/my-subfolder/my-file.csv.
Ejemplos de rutas de datos de Blob Storage
A continuación, se muestran ejemplos de rutas de datos válidas para una transferencia de Blob Storage. Tenga en cuenta que las rutas de datos no empiezan por /.
Ejemplo: un solo archivo
Para cargar un solo archivo de Blob Storage en BigQuery, especifica el nombre del archivo de Blob Storage:
my-folder/my-file.csv
Ejemplo: Todos los archivos
Para cargar todos los archivos de un contenedor de Blob Storage en BigQuery, defina la ruta de datos en un solo comodín:
*
Ejemplo: archivos con un prefijo común
Para cargar todos los archivos de Blob Storage que compartan un prefijo común, especifica el prefijo común con o sin un comodín:
my-folder/
o
my-folder/*
Ejemplo: archivos con una ruta similar
Para cargar todos los archivos de Blob Storage con una ruta similar, especifica el prefijo y el sufijo comunes:
my-folder/*.csv
Si solo usas un comodín, se abarcan los directorios. En este ejemplo, se seleccionan todos los archivos CSV de my-folder, así como todos los archivos CSV de todas las subcarpetas de my-folder.
Ejemplo: comodín al final de la ruta
Consideremos la siguiente ruta de datos:
logs/*
Se seleccionan todos los archivos siguientes:
logs/logs.csv
logs/system/logs.csv
logs/some-application/system_logs.log
logs/logs_2019_12_12.csv
Ejemplo: comodín al principio de la ruta
Consideremos la siguiente ruta de datos:
*logs.csv
Se seleccionan todos los archivos siguientes:
logs.csv
system/logs.csv
some-application/logs.csv
Y no se ha seleccionado ninguno de los siguientes archivos:
metadata.csv
system/users.csv
some-application/output.csv
Ejemplo: Varios comodines
Si usas varios comodines, tendrás más control sobre la selección de archivos, pero los límites serán más bajos. Cuando usas varios comodines, cada uno de ellos solo abarca un subdirectorio.
Consideremos la siguiente ruta de datos:
*/*.csv
Ambos archivos están seleccionados:
my-folder1/my-file1.csv
my-other-folder2/my-file2.csv
Y no se ha seleccionado ninguno de los siguientes archivos:
my-folder1/my-subfolder/my-file3.csv
my-other-folder2/my-subfolder/my-file4.csv
Firma de acceso compartido (SAS)
El token de SAS de Azure se usa para acceder a los datos de Blob Storage en tu nombre. Sigue estos pasos para crear un token de SAS para tu transferencia:
- Crea o usa un usuario de Blob Storage para acceder a la cuenta de almacenamiento de tu contenedor de Blob Storage.
Cree un token de SAS a nivel de cuenta de almacenamiento. Para crear un token de SAS con Azure Portal, siga estos pasos:
- En Servicios permitidos, selecciona Blob.
- En Tipos de recursos permitidos, selecciona Contenedor y Objeto.
- En Permisos permitidos, selecciona Leer y Lista.
- El tiempo de expiración predeterminado de los tokens de SAS es de 8 horas. Define una hora de vencimiento que se adapte a tu programación de transferencias.
- No especifiques ninguna dirección IP en el campo Direcciones IP permitidas.
- En Protocolos permitidos, selecciona Solo HTTPS.
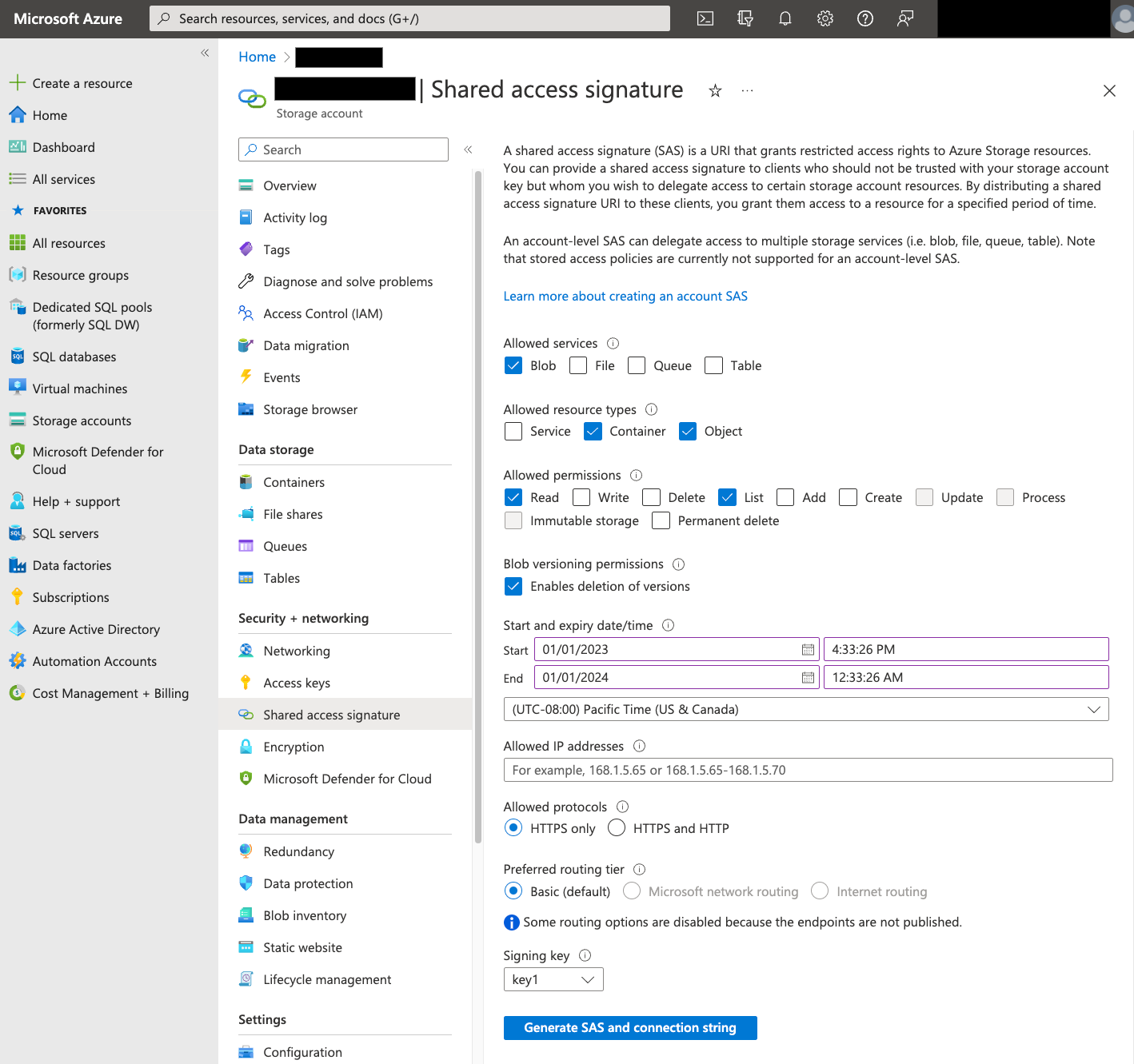
Una vez creado el token de SAS, anota el valor Token de SAS que se devuelve. Necesitará este valor cuando configure las transferencias.
Restricciones de IP
Si restringes el acceso a tus recursos de Azure mediante un firewall de Azure Storage, debes añadir los intervalos de direcciones IP que usan los trabajadores de BigQuery Data Transfer Service a tu lista de IPs permitidas.
Para añadir intervalos de IP como IPs permitidas a los cortafuegos de Azure Storage, consulta Restricciones de IP.
Consideraciones sobre la coherencia
Un archivo tarda unos 5 minutos en estar disponible para BigQuery Data Transfer Service después de añadirse al contenedor de Blob Storage.
Prácticas recomendadas para controlar los costes de salida
Las transferencias desde Blob Storage pueden fallar si la tabla de destino no está configurada correctamente. Estos son algunos de los posibles motivos de una configuración incorrecta:
- La tabla de destino no existe.
- El esquema de la tabla no está definido.
- El esquema de la tabla no es compatible con los datos que se van a transferir.
Para evitar costes de salida adicionales de Blob Storage, primero prueba una transferencia con un subconjunto de archivos pequeño pero representativo. Asegúrate de que esta prueba sea pequeña tanto en tamaño de datos como en número de archivos.
También es importante tener en cuenta que la coincidencia de prefijos de las rutas de datos se produce antes de que se transfieran los archivos desde Blob Storage, pero la coincidencia de comodines se produce en Google Cloud. Esta distinción podría aumentar los costes de salida de Blob Storage de los archivos que se transfieran aGoogle Cloud pero no se carguen en BigQuery.
Por ejemplo, considere esta ruta de datos:
folder/*/subfolder/*.csv
Ambos archivos se transfieren a Google Cloudporque tienen el prefijo folder/:
folder/any/subfolder/file1.csv
folder/file2.csv
Sin embargo, solo se carga el archivo folder/any/subfolder/file1.csv en BigQuery, ya que coincide con la ruta de datos completa.
Precios
Para obtener más información, consulta los precios de BigQuery Data Transfer Service.
También es posible que se apliquen cargos adicionales fuera de Google por utilizar este servicio. Para obtener más información, consulta los precios de Blob Storage.
Cuotas y límites
BigQuery Data Transfer Service usa tareas de carga para cargar datos de Blob Storage en BigQuery. Se aplican todas las cuotas y todos los límites de BigQuery a las tareas de carga de Blob Storage periódicas, con las siguientes consideraciones adicionales:
| Límite | Predeterminado |
|---|---|
| Tamaño máximo por ejecución de transferencia de trabajos de carga | 15 TB |
| Número máximo de archivos por ejecución de transferencia cuando la ruta de datos de Blob Storage incluye 0 o 1 comodín | 10.000.000 de archivos |
| Número máximo de archivos por ejecución de transferencia cuando la ruta de datos de Blob Storage incluye dos o más comodines | 10.000 archivos |
Siguientes pasos
- Más información sobre cómo configurar una transferencia de Blob Storage
- Más información sobre los parámetros de tiempo de ejecución en las transferencias
- Más información sobre BigQuery Data Transfer Service