Présentation des transferts de stockage de blobs
Le Service de transfert de données BigQuery pour Azure Blob Storage vous permet de programmer et de gérer automatiquement les jobs de chargement récurrents à partir d'Azure Blob Storage et d'Azure Data Lake Storage Gen2 dans BigQuery.
Formats de fichiers acceptés
Le service de transfert de données BigQuery est actuellement compatible avec le chargement de données à partir de Blob Storage aux formats suivants :
- Valeurs séparées par une virgule (CSV)
- JSON (délimité par un retour à la ligne)
- Avro
- Parquet
- ORC
Types de compression acceptés
Le service de transfert de données BigQuery pour Blob Storage accepte le chargement de données compressées. Les types de compression acceptés par le service de transfert de données BigQuery sont identiques aux types de compression acceptés par les tâches de chargement BigQuery. Pour en savoir plus, consultez la section Charger des données compressées et non compressées.
Conditions préalables au transfert
Pour charger des données à partir d'une source de données Blob Storage, commencez par collecter les éléments suivants :
- Le nom du compte Blob Storage, nom du conteneur et chemin d'accès aux données (facultatif) pour les données sources. Le champ de chemin d'accès aux données est facultatif ; il permet de faire correspondre les extensions de fichier et les préfixes d'objets courants. Si le chemin d'accès aux données est omis, tous les fichiers du conteneur sont transférés.
- Un jeton de signature d'accès partagé (SAP) Azure qui accorde un accès en lecture à votre source de données. Pour en savoir plus sur la création d'un jeton SAP, consultez la section Signature d'accès partagé (SAP).
Paramétrer l'exécution du transfert
Le chemin d'accès aux données Blob Storage et la table de destination peuvent être tous deux paramétrés, ce qui vous permet de charger des données à partir de conteneurs organisés par date. Les paramètres utilisés par les transferts Blob Storage sont les mêmes que ceux utilisés par les transferts Cloud Storage. Pour plus de détails, consultez la page Paramètres d'exécution dans les transferts.
Ingestion de données pour les transferts Azure Blob
Vous pouvez spécifier la manière dont les données sont chargées dans BigQuery en sélectionnant une préférence d'écriture dans la configuration du transfert lorsque vous configurez un transfert Azure Blob.
Il existe deux types de préférences d'écriture : les transferts incrémentiels et les transferts tronqués.Transferts incrémentiels
Une configuration de transfert avec une préférence d'écriture APPEND ou WRITE_APPEND, également appelée transfert incrémentiel, ajoute de nouvelles données depuis le dernier transfert réussi vers une table de destination BigQuery. Lorsqu'une configuration de transfert s'exécute avec une préférence d'écriture APPEND, le Service de transfert de données BigQuery filtre les fichiers modifiés depuis la dernière exécution de transfert réussie. Pour déterminer le moment où un fichier est modifié, le Service de transfert de données BigQuery recherche une propriété "dernière modification" dans les métadonnées du fichier. Par exemple, le Service de transfert de données BigQuery examine la propriété d'horodatage updated dans un fichier Cloud Storage. Si le Service de transfert de données BigQuery trouve des fichiers dont l'heure de la dernière modification a eu lieu après l'horodatage du dernier transfert réussi, le service transfère ces fichiers dans un transfert incrémentiel.
Pour illustrer le fonctionnement des transferts incrémentiels, prenons l'exemple de transfert Cloud Storage suivant. Un utilisateur crée un fichier dans un bucket Cloud Storage à la date 2023-07-01T00:00Z nomméfile_1. L'horodatage updated pour file_1 correspond à l'heure à laquelle le fichier a été créé. L'utilisateur crée ensuite un transfert incrémentiel à partir du bucket Cloud Storage, dont l'exécution est programmée une fois par jour à 03:00Z, à partir du 2023-07-01T03:00Z.
- À la date 2023-07-01T03:00Z, la première exécution du transfert commence. Comme il s'agit de la première exécution de transfert pour cette configuration, le Service de transfert de données BigQuery tente de charger tous les fichiers correspondant à l'URI source dans la table BigQuery de destination. L'exécution du transfert aboutit et le service de transfert de données BigQuery charge correctement
file_1dans la table BigQuery de destination. - La prochaine exécution de transfert, à 2023-07-02T03:00Z, ne détecte aucun fichier dont la propriété d'horodatage
updatedest supérieure à la dernière exécution de transfert réussie (2023-07-01T03:00Z). L'exécution du transfert aboutit sans charger de données supplémentaires dans la table BigQuery de destination.
L'exemple précédent montre comment le service de transfert de données BigQuery examine la propriété d'horodatage updated du fichier source pour déterminer si des modifications ont été apportées aux fichiers sources, et pour transférer ces modifications le cas échéant.
Après ce même exemple, supposons que l'utilisateur crée ensuite un autre fichier dans le bucket Cloud Storage, à la date 2023-07-03T00:00Z, nommé file_2. L'horodatage updated pour file_2 correspond à l'heure à laquelle le fichier a été créé.
- La prochaine exécution de transfert, à 2023-07-03T03:00Z, détecte que
file_2possède un horodatageupdatedsupérieur à la dernière exécution de transfert réussie (2023-07-01T03:00Z). Supposons que l'exécution du transfert échoue au démarrage en raison d'une erreur temporaire. Dans ce scénario,file_2n'est pas chargé dans la table BigQuery de destination. Le dernier horodatage d'exécution de transfert réussi reste 2023-07-01T03:00Z. - La prochaine exécution de transfert, à 2023-07-04T03:00Z, détecte que
file_2possède un horodatageupdatedsupérieur à la dernière exécution de transfert réussie (2023-07-01T03:00Z). Cette fois, l'exécution du transfert se termine sans problème et charge correctementfile_2dans la table BigQuery de destination. - La prochaine exécution de transfert, à 2023-07-05T03:00Z, ne détecte aucun fichier dont l'horodatage
updatedest supérieur à la dernière exécution de transfert réussie (2023-07-04T03:00Z). L'exécution du transfert réussit sans charger de données supplémentaires dans la table BigQuery de destination.
L'exemple précédent montre que lorsqu'un transfert échoue, aucun fichier n'est transféré vers la table de destination BigQuery. Toutes les modifications de fichiers sont transférées lors de la prochaine exécution de transfert réussie. Un transfert réussi après un transfert ayant échoué n'entraîne pas de données en double. En cas d'échec d'un transfert, vous pouvez également choisir de déclencher manuellement un transfert en dehors de son heure de planification habituelle.
Transferts tronqués
Une configuration de transfert avec une préférence d'écriture MIRROR ou WRITE_TRUNCATE, également appelée transfert tronqué, écrase des données dans la table de destination BigQuery à chaque exécution de transfert avec les données de tous les fichiers correspondant à l'URI source. MIRROR écrase une nouvelle copie des données de la table de destination. Si la table de destination utilise un décorateur de partition, l'exécution du transfert n'écrase que les données de la partition spécifiée. Une table de destination avec un décorateur de partition se présente au format my_table${run_date} (par exemple, my_table$20230809).
Répéter les mêmes transferts incrémentiels ou tronqués une journée n'entraîne pas de données en double. Toutefois, si vous exécutez plusieurs configurations de transfert différentes qui affectent la même table de destination BigQuery, le Service de transfert de données BigQuery peut dupliquer les données.
Compatibilité des caractères génériques pour le chemin d'accès aux données Blob Storage
Vous pouvez sélectionner des données sources séparées en plusieurs fichiers en spécifiant un ou plusieurs caractères génériques astérisque (*) dans le chemin de données.
Bien que vous puissiez utiliser plusieurs caractères génériques dans le chemin de données, une certaine optimisation est possible lorsqu'un seul caractère générique est utilisé :
- Il existe une limite plus élevée sur le nombre maximal de fichiers par exécution de transfert.
- Le caractère générique couvre également les répertoires. Par exemple, le chemin d'accès aux données
my-folder/*.csvcorrespond au fichiermy-folder/my-subfolder/my-file.csv.
Exemples de chemin d'accès aux données Blob Storage
Vous trouverez ci-dessous des exemples valides de chemins d'accès aux données pour un transfert Blob Storage. Notez que les chemins d'accès aux données ne commencent pas par /.
Exemple : Fichier unique
Pour charger un fichier unique depuis Blob Storage dans BigQuery, spécifiez le nom du fichier Blob Storage :
my-folder/my-file.csv
Exemple : Tous les fichiers
Pour charger tous les fichiers d'un conteneur Blob Storage dans BigQuery, définissez le chemin d'accès aux données sur un seul caractère générique :
*
Exemple : Fichiers avec un préfixe commun
Pour charger tous les fichiers de Blob Storage qui partagent un préfixe commun, spécifiez ce préfixe commun avec ou sans caractère générique :
my-folder/
ou
my-folder/*
Exemple : Fichiers avec un chemin similaire
Pour charger tous les fichiers de Blob Storage avec un chemin similaire, spécifiez le préfixe et le suffixe communs :
my-folder/*.csv
Lorsque vous n'utilisez qu'un seul caractère générique, il couvre plusieurs répertoires. Dans cet exemple, chaque fichier CSV dans my-folder est sélectionné, ainsi que chaque fichier CSV dans chaque sous-dossier de my-folder.
Exemple : Caractère générique à la fin du chemin d'accès
Prenons l'exemple du chemin de données suivant :
logs/*
Tous les fichiers suivants sont sélectionnés :
logs/logs.csv
logs/system/logs.csv
logs/some-application/system_logs.log
logs/logs_2019_12_12.csv
Exemple : Caractère générique au début du chemin d'accès
Prenons l'exemple du chemin de données suivant :
*logs.csv
Tous les fichiers suivants sont sélectionnés :
logs.csv
system/logs.csv
some-application/logs.csv
Aucun des fichiers suivants n'est sélectionné :
metadata.csv
system/users.csv
some-application/output.csv
Exemple : Plusieurs caractères génériques
En utilisant plusieurs caractères génériques, vous contrôlez mieux la sélection de fichiers, au prix de limites plus faibles. Lorsque vous utilisez plusieurs caractères génériques, chaque caractère générique ne couvre qu'un seul sous-répertoire.
Prenons l'exemple du chemin de données suivant :
*/*.csv
Les deux fichiers suivants sont sélectionnés :
my-folder1/my-file1.csv
my-other-folder2/my-file2.csv
Aucun des deux fichiers suivants n'est sélectionné :
my-folder1/my-subfolder/my-file3.csv
my-other-folder2/my-subfolder/my-file4.csv
Signature d'accès partagé (SAP)
Le jeton SAP Azure permet d'accéder aux données Blob Storage en votre nom. Pour créer un jeton SAP pour votre transfert, procédez comme suit :
- Créez ou utilisez un utilisateur existant de Blob Storage pour accéder au compte de stockage de votre conteneur Blob Storage.
Créez un jeton SAP au niveau du compte de stockage. Pour créer un jeton SAP à l'aide du portail Azure, procédez comme suit :
- Pour Allowed services (Services autorisés), sélectionnez Blob.
- Pour Allowed resource types (Types de ressources autorisés), sélectionnez Container (Conteneur) et Object (Objet).
- Pour Allowed permissions (Autorisations accordées), sélectionnez Read (Lecture) et List (Liste).
- Le délai d'expiration par défaut pour les jetons SAP est de 8 heures. Définissez un délai d'expiration adapté à votre planning de transfert.
- Ne spécifiez aucune adresse IP dans le champ Allowed IP addresses (Adresses IP autorisées).
- Dans le champ Allowed protocols (Protocoles autorisés), sélectionnez HTTPS only (HTTPS seulement).
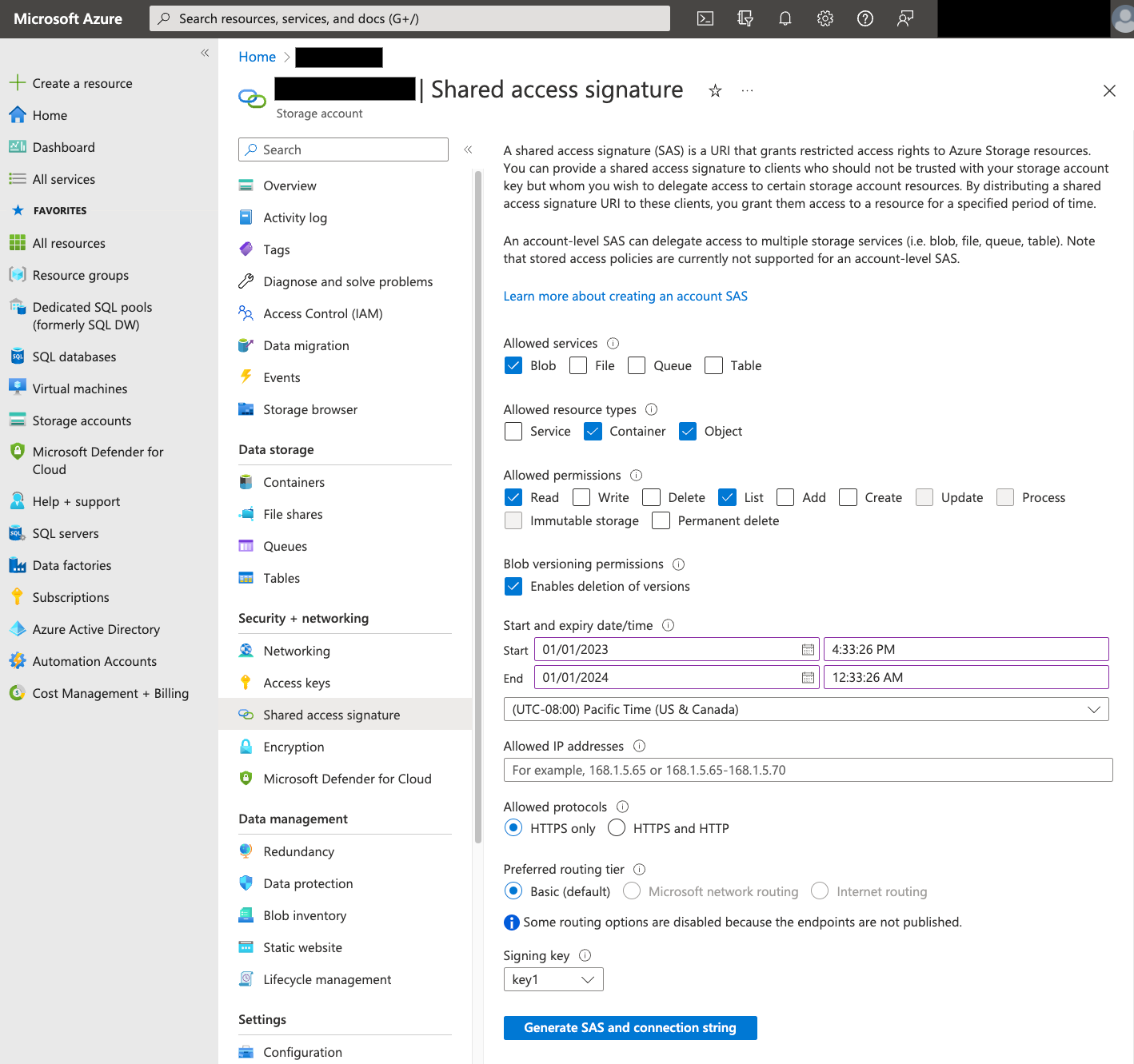
Une fois le jeton SAP créé, notez la valeur du jeton SAP qui est renvoyé. Vous aurez besoin de cette valeur lors de la configuration des transferts.
Restrictions d'adresse IP
Si vous limitez l'accès à vos ressources Azure à l'aide d'un pare-feu Azure Storage, vous devez ajouter les plages d'adresses IP utilisées par les nœuds de calcul du service de transfert de données BigQuery à votre liste d'adresses IP autorisées.
Pour ajouter des plages d'adresses IP en tant qu'adresses IP autorisées aux pare-feu Azure Storage, consultez la section Restrictions d'adresses IP.
Considérations relatives à la cohérence
Après son ajout au conteneur Blob Storage, il faut attendre environ cinq minutes avant qu'un fichier ne soit disponible pour le service de transfert de données BigQuery.
Bonnes pratiques pour contrôler les coûts de sortie
Les transferts à partir de Blob Storage peuvent échouer si la table de destination n'est pas correctement configurée. Voici des causes possibles d'une configuration incorrecte :
- La table de destination n'existe pas.
- Le schéma de la table n'est pas défini.
- Le schéma de la table n'est pas compatible avec les données transférées.
Pour éviter des coûts de sortie supplémentaires dans Blob Storage, testez d'abord un transfert avec un sous-ensemble de fichiers restreint, mais représentatif. Assurez-vous que ce test est petit en matière de taille de données et de nombre de fichiers.
Il est également important de noter que la correspondance des préfixes pour les chemins de données se produit avant le transfert des fichiers de Blob Storage, mais que la correspondance des caractères génériques s'effectue dans Google Cloud. Cette distinction peut augmenter les coûts de sortie Blob Storage pour les fichiers qui sont transférés versGoogle Cloud , mais pas chargés dans BigQuery.
À titre d'exemple, considérons le chemin de données suivant :
folder/*/subfolder/*.csv
Les deux fichiers suivants sont transférés vers Google Cloud, car ils comportent le préfixe folder/ :
folder/any/subfolder/file1.csv
folder/file2.csv
Cependant, seul le fichier folder/any/subfolder/file1.csv est chargé dans BigQuery, car il correspond au chemin d'accès complet aux données.
Tarifs
Pour plus d'informations, consultez la section Tarifs du service de transfert de données BigQuery.
L'utilisation de ce service peut également engendrer des coûts hors de Google. Pour en savoir plus, consultez les tarifs de Blob Storage.
Quotas et limites
Le service de transfert de données BigQuery utilise des tâches de chargement pour charger les données Blob Storage dans BigQuery. Tous les quotas et limites BigQuery associés aux tâches de chargement s'appliquent aux transferts Blob Storage récurrents, avec les considérations supplémentaires suivantes :
| Limite | Par défaut |
|---|---|
| Taille maximale par exécution de transfert de tâche de chargement | 15 To |
| Nombre maximal de fichiers par exécution de transfert lorsque le chemin d'accès aux données Blob Storage inclut 0 ou 1 caractère générique | 10 000 000 fichiers |
| Nombre maximal de fichiers par exécution de transfert lorsque le chemin d'accès aux données Blob Storage inclut au moins deux caractères génériques | 10 000 fichiers |
Étapes suivantes
- Découvrez comment configurer un transfert Blob Storage.
- Obtenez plus d'informations sur les paramètres d'exécution dans les transferts.
- Obtenez plus d'informations sur le Service de transfert de données BigQuery.