In dieser Anleitung lernen Datenanalysten die Funktionen von BigQuery ML kennen.
Mit BigQuery ML können Nutzer mithilfe von SQL-Abfragen Modelle für maschinelles Lernen in BigQuery erstellen und ausführen. In dieser Anleitung wird das Feature Engineering unter Zuhilfenahme der Klausel TRANSFORM erläutert. Mit der Klausel TRANSFORM können Sie während der Modellerstellung die gesamte Vorverarbeitung festlegen. Die Vorverarbeitung wird während der Vorhersage- und Bewertungsphase des maschinellen Lernens automatisch angewendet.
In dieser Anleitung verwenden Sie die Beispieltabelle natality zum Erstellen eines Modells zur Vorhersage des Geburtsgewichts eines Kindes basierend auf dem Geschlecht des Kindes, der Länge der Schwangerschaft und segmentierten demografischen Informationen über die Mutter. Die Beispieltabelle natality enthält Informationen zu jeder Geburt in den USA über einen Zeitraum von 40 Jahren.
Ziele
In dieser Anleitung verwenden Sie:
- BigQuery ML zur Erstellung eines linearen Regressionsmodells unter Verwendung der
CREATE MODEL-Anweisung mit der KlauselTRANSFORM - Die Vorverarbeitungsfunktionen
ML.FEATURE_CROSSundML.QUANTILE_BUCKETIZE - Die
ML.EVALUATE-Funktion zur Bewertung des ML-Modells - Die Funktion
ML.PREDICTzum Erstellen von Vorhersagen mithilfe des ML-Modells
Kosten
In dieser Anleitung werden kostenpflichtige Komponenten von Google Cloud verwendet, darunter:
- BigQuery
- BigQuery ML
Weitere Informationen zu den Kosten von BigQuery finden Sie auf der Seite BigQuery-Preise.
Vorbereitung
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- BigQuery ist in neuen Projekten automatisch aktiviert.
Zum Aktivieren von BigQuery in einem vorhandenen Projekt wechseln Sie zu
Enable the BigQuery API.
.
Schritt 1: Dataset erstellen
Erstellen Sie ein BigQuery-Dataset, um Ihr ML-Modell zu speichern:
Rufen Sie in der Google Cloud Console die Seite „BigQuery“ auf.
Klicken Sie im Bereich Explorer auf den Namen Ihres Projekts.
Klicken Sie auf Aktionen ansehen > Dataset erstellen.
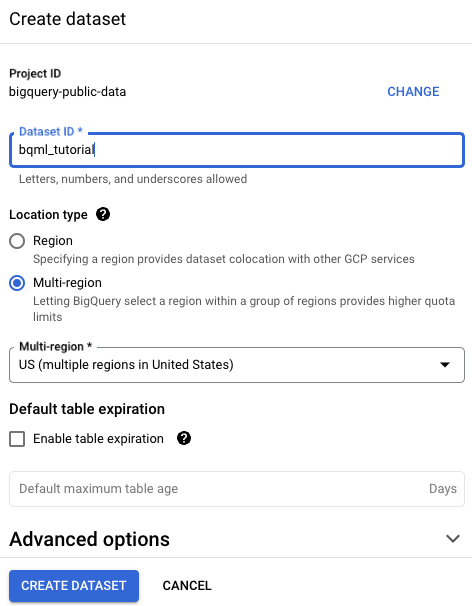
Führen Sie auf der Seite Dataset erstellen die folgenden Schritte aus:
Geben Sie unter Dataset-ID
bqml_tutorialein.Wählen Sie als Standorttyp die Option Mehrere Regionen und dann USA (mehrere Regionen in den USA) aus.
Die öffentlichen Datasets sind am multiregionalen Standort
USgespeichert. Der Einfachheit halber sollten Sie Ihr Dataset am selben Standort speichern.Übernehmen Sie die verbleibenden Standardeinstellungen unverändert und klicken Sie auf Dataset erstellen.
Schritt 2: Modell erstellen
Erstellen Sie als Nächstes mit der Beispieltabelle für BigQuery ein Modell mit linearer Regression. Mit der folgenden Google-SQL-Abfrage wird das Modell erstellt. Sie können damit das Geburtsgewicht eines Kindes vorhersagen.
#standardSQL CREATE MODEL `bqml_tutorial.natality_model` TRANSFORM(weight_pounds, is_male, gestation_weeks, ML.QUANTILE_BUCKETIZE(mother_age, 5) OVER() AS bucketized_mother_age, CAST(mother_race AS string) AS mother_race, ML.FEATURE_CROSS(STRUCT(is_male, CAST(mother_race AS STRING) AS mother_race)) is_male_mother_race) OPTIONS (model_type='linear_reg', input_label_cols=['weight_pounds']) AS SELECT * FROM `bigquery-public-data.samples.natality` WHERE weight_pounds IS NOT NULL AND RAND() < 0.001
Durch Ausführen des Befehls CREATE MODEL wird das Modell, das Sie erstellen, außerdem trainiert.
Abfragedetails
Mit der Klausel CREATE MODEL wird das Modell bqml_tutorial.natality_model erstellt und trainiert.
Die Klausel OPTIONS(model_type='linear_reg', input_label_cols=['weight_pounds']) gibt an, dass Sie ein Modell mit linearer Regression erstellen. Eine lineare Regression ist eine Art von Regressionsmodell, das aus einer linearen Kombination von Eingabemerkmalen einen kontinuierlichen Wert generiert. Die Spalte weight_pounds ist die Eingabelabel-Spalte. Bei linearen Regressionsmodellen muss die Labelspalte reelle Zahlen als Werte enthalten.
Die Klausel TRANSFORM dieser Abfrage verwendet die folgenden Spalten aus der SELECT-Anweisung:
weight_pounds: Gewicht des Kindes in Pfund (FLOAT64).is_male: Geschlecht des Kindes. TRUE, wenn das Kind männlich ist, FALSE, wenn es weiblich ist (BOOL).gestation_weeks: Anzahl der Schwangerschaftswochen (INT64).mother_age: Alter der Mutter bei der Entbindung (INT64).mother_race: Ethnie der Mutter (INT64). Dieser ganzzahlige Wert entspricht dem Wertchild_raceim Tabellenschema. Wenn Sie erzwingen möchten, dass BigQuery MLmother_raceals nicht numerisches Merkmal behandelt und jeder Wert eine andere Kategorie repräsentiert, wandelt die Abfragemother_racein einen STRING um. Dies ist insofern wichtig, als die Ethnie eher als Kategorie und nicht als (geordnete und skalierbare) Ganzzahl von Bedeutung ist.
Mit der Klausel TRANSFORM werden die ursprünglichen Merkmale als Feed für das Training vorverarbeitet. Folgende Spalten werden erstellt:
weight_pounds: ohne Änderung übernommenis_male: als Feed für das Training übernommengestation_weeks: als Feed für das Training übernommenbucketized_mother_age: erstellt ausmother_age, wobeimother_agemit der AnalysefunktionML.QUANTILE_BUCKETIZE()basierend auf Quantilen gruppiert wirdmother_race: ursprünglicher Wertmother_raceim Stringformatis_male_mother_race: ermittelt durch Kreuzung vonis_maleundmother_racemit der FunktionML.FEATURE_CROSS
Die SELECT-Anweisung der Abfrage enthält die Spalten, die Sie in der TRANSFORM-Klausel verwenden können. Sie müssen jedoch in der TRANSFORM-Klausel nicht alle Spalten verwenden. Dadurch können Sie innerhalb der TRANSFORM-Klausel sowohl die Merkmalauswahl als auch die Vorverarbeitung vornehmen.
Die FROM-Klausel (bigquery-public-data.samples.natality) gibt an, dass Sie die Stichprobentabelle für Geburtsdaten im Beispiel-Dataset abfragen.
Dieses Dataset befindet sich im Projekt bigquery-public-data.
Die WHERE-Klausel (WHERE weight_pounds IS NOT NULL AND RAND() < 0.001) schließt Zeilen aus, bei denen die Gewichtung NULL ist, und verwendet die RAND-Funktion, um eine zufällige Stichprobe der Daten zu erstellen.
Abfrage CREATE MODEL ausführen
So führen Sie die Abfrage CREATE MODEL zum Erstellen und Trainieren des Modells aus:
Klicken Sie in der Google Cloud Console auf Neue Abfrage erstellen.
Geben Sie im Textfeld des Abfrageeditors die folgende GoogleSQL-Abfrage ein.
#standardSQL CREATE MODEL `bqml_tutorial.natality_model` TRANSFORM(weight_pounds, is_male, gestation_weeks, ML.QUANTILE_BUCKETIZE(mother_age, 5) OVER() AS bucketized_mother_age, CAST(mother_race AS string) AS mother_race, ML.FEATURE_CROSS(STRUCT(is_male, CAST(mother_race AS STRING) AS mother_race)) is_male_mother_race) OPTIONS (model_type='linear_reg', input_label_cols=['weight_pounds']) AS SELECT * FROM `bigquery-public-data.samples.natality` WHERE weight_pounds IS NOT NULL AND RAND() < 0.001
Klicken Sie auf Ausführen.
Die Abfrage dauert ungefähr 30 Sekunden. Anschließend wird das Modell (
natality_model) im Navigationsbereich angezeigt. Da die Abfrage eineCREATE MODEL-Anweisung zum Erstellen einer Tabelle verwendet, werden keine Abfrageergebnisse angezeigt.
Schritt 3 (optional): Trainingsstatistiken abrufen
Mit der Funktion ML.TRAINING_INFO können Sie die Ergebnisse des Modelltrainings abrufen. Alternativ lassen sich die Statistiken auch in der Google Cloud Console abrufen. In dieser Anleitung verwenden Sie die Google Cloud Console.
Ein maschineller Lernalgorithmus erstellt ein Modell durch Analyse vieler Beispiele. Ziel ist es, ein Modell zu finden, das den Verlust minimiert. Dieser Vorgang wird als empirische Risikominimierung bezeichnet.
Die Konsequenz einer schlechten Vorhersage ist ein Verlust. Er wird als eine Zahl angegeben, die anzeigt, wie schlecht die Vorhersage des Modells in einem einzelnen Beispiel war. Wenn die Vorhersage des Modells genau ist, entspricht dies einem Verlust von null. Je ungenauer die Vorhersage ist, desto höher ist der Verlust. Ziel des Modelltrainings ist es, eine Reihe von Gewichtungen und Verzerrungen zu finden, die bei allen Beispielen im Schnitt einen geringen Verlust aufweisen.
So können Sie die Statistiken zum Modelltraining ansehen, die beim Ausführen der CREATE MODEL-Abfrage erzeugt wurden:
Gehen Sie im Navigationsbereich der Google Cloud Console in den Abschnitt Ressourcen, maximierenproject-name > bqml_tutorial und klicken Sie dann aufnatality_model.
Klicken Sie auf den Tab Training und wählen Sie unter Anzeigen als die Option Tabelle aus. Die Ergebnisse sollten so aussehen:
+-----------+--------------------+----------------------+--------------------+ | Iteration | Training data loss | Evaluation data loss | Duration (seconds) | +-----------+--------------------+----------------------+--------------------+ | 0 | 1.6640 | 1.7352 | 6.27 | +-----------+--------------------+----------------------+--------------------+
Die Spalte Trainingsdatenverlust enthält den Verlustmesswert, der berechnet wird, nachdem das Modell mit dem Trainings-Dataset trainiert wurde. Da Sie eine lineare Regression durchgeführt haben, enthält diese Spalte die mittlere quadratische Abweichung.
Die Spalte Evaluation Data Loss (Evaluationsdatenverlust) enthält denselben Verlustmesswert, der für das Holdout-Dataset berechnet wurde (Daten, die vom Training zurückgehalten werden, um das Modell zu validieren). Die für das Training verwendete Standard-Optimierungsstrategie ist "normal_equation", sodass nur eine Ausführung erforderlich ist, um eine Annäherung an das endgültige Modell zu erreichen.
Weitere Informationen zur Option
optimize_strategyfinden Sie auf der Seite zur AnweisungCREATE MODEL.Weitere Informationen zur Funktion
ML.TRAINING_INFOund zur Trainingsoption "optimize_strategy" finden Sie in der Referenz zur BigQuery ML-Syntax.
Schritt 4: Modell bewerten
Nach der Erstellung des Modells können Sie die Leistung des Klassifikators mit der Funktion ML.EVALUATE bewerten. Die Funktion ML.EVALUATE wertet die vorhergesagten Werte anhand der tatsächlichen Daten aus.
Die Abfrage, die zur Bewertung des Modells verwendet wird, lautet:
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.natality_model`, ( SELECT * FROM `bigquery-public-data.samples.natality` WHERE weight_pounds IS NOT NULL))
Abfragedetails
Die obere SELECT-Anweisung ruft die Spalten aus Ihrem Modell ab.
In der FROM-Klausel wird die Funktion ML.EVALUATE für das Modell bqml_tutorial.natality_model verwendet.
Die geschachtelte SELECT-Anweisung und die FROM-Klausel dieser Abfrage sind dieselben wie jene in der Abfrage CREATE MODEL. Da die Klausel TRANSFORM beim Training verwendet wird, müssen Sie nicht die spezifischen Spalten und Transformationen angeben. Sie werden automatisch wiederhergestellt.
Die WHERE-Klausel (WHERE weight_pounds IS NOT NULL) schließt Zeilen mit einer Gewichtung von NULL aus.
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.natality_model`)
Abfrage ML.EVALUATE ausführen
So können Sie die ML.EVALUATE-Anfrage ausführen, die das Modell bewertet:
Klicken Sie in der Google Cloud Console auf Neue Abfrage erstellen.
Geben Sie im Textfeld des Abfrageeditors die folgende GoogleSQL-Abfrage ein.
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.natality_model`, ( SELECT * FROM `bigquery-public-data.samples.natality` WHERE weight_pounds IS NOT NULL))
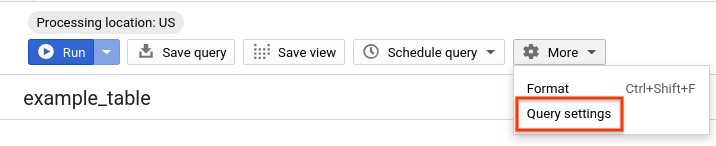
Optional: Klicken Sie in der Drop-down-Liste settings_applicationsMehr auf Abfrageeinstellungen, um den Verarbeitungsort festzulegen. Wählen Sie unter Verarbeitungsort die Option USA aus. Dieser Schritt ist optional, da der Verarbeitungsort anhand des Standorts des Datasets automatisch erkannt wird.
Klicken Sie auf Ausführen.
Sobald die Abfrage abgeschlossen ist, klicken Sie unterhalb des Textbereichs der Abfrage auf den Tab Ergebnisse. Die Ergebnisse sollten so aussehen:
+---------------------+--------------------+------------------------+---------------------+---------------------+----------------------+ | mean_absolute_error | mean_squared_error | mean_squared_log_error | mean_absolute_error | r2_score | explained_variance | +---------------------+--------------------+------------------------+---------------------+---------------------+----------------------+ | 0.9566580179970666 | 1.6756289722442677 | 0.034241471462096516 | 0.7385590721661188 | 0.04650972930257946 | 0.046516832131241026 | +---------------------+--------------------+------------------------+---------------------+---------------------+----------------------+
Da Sie eine lineare Regression durchgeführt haben, enthalten die Ergebnisse die folgenden Spalten:
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
Ein wichtiger Messwert in den Bewertungsergebnissen ist der R2-Wert.
Der R2-Wert ist ein statistisches Maß dafür, ob sich die Vorhersagen der linearen Regression den tatsächlichen Daten annähern. Der Wert 0 gibt an, dass das Modell keine der Abweichungen der Antwortdaten um den Mittelwert erklärt. Der Wert 1 gibt an, dass das Modell alle Abweichungen der Antwortdaten um den Mittelwert erklärt.
Schritt 5: Modell verwenden, um Ergebnisse vorherzusagen
Nachdem Sie Ihr Modell ausgewertet haben, besteht der nächste Schritt darin, ein Ergebnis vorherzusagen. Sie können Ihr Modell verwenden, um das Geburtsgewicht aller in Wyoming geborenen Babys vorherzusagen.
Die Abfrage zur Vorhersage des Ergebnisses lautet so:
#standardSQL SELECT predicted_weight_pounds FROM ML.PREDICT(MODEL `bqml_tutorial.natality_model`, ( SELECT * FROM `bigquery-public-data.samples.natality` WHERE state = "WY"))
Abfragedetails
Die oberste SELECT-Anweisung ruft die Spalte predicted_weight_pounds ab.
Diese Spalte wird von der ML.PREDICT-Funktion generiert. Wenn Sie die Funktion ML.PREDICT verwenden, lautet der Ausgabespaltenname für das Modell predicted_label_column_name. Bei linearen Regressionsmodellen ist predicted_label der geschätzte Wert von label. Bei logistischen Regressionsmodellen ist predicted_label eines der beiden Eingabelabels, je nachdem, welches Label die höhere prognostizierte Wahrscheinlichkeit hat.
Die Funktion ML.PREDICT wird verwendet, um Ergebnisse anhand des Modells bqml_tutorial.natality_model vorherzusagen.
Die geschachtelte SELECT-Anweisung und die FROM-Klausel dieser Abfrage sind dieselben wie jene in der Abfrage CREATE MODEL. Sie müssen jedoch nicht alle Spalten wie beim Training übergeben, sondern nur jene, die in der TRANSFORM-Klausel verwendet werden. Ähnlich wie bei ML.EVALUATE werden die Transformationen innerhalb der TRANSFORM-Klausel automatisch wiederhergestellt.
Die WHERE-Klausel (WHERE state = "WY") gibt an, dass Sie die Vorhersage auf den Bundesstaat Wyoming beschränken.
Abfrage ML.PREDICT ausführen
So führen Sie die Abfrage aus, die das Modell zur Vorhersage eines Ergebnisses verwendet:
Klicken Sie in der Google Cloud Console auf Neue Abfrage erstellen.
Geben Sie im Textfeld des Abfrageeditors die folgende GoogleSQL-Abfrage ein.
#standardSQL SELECT predicted_weight_pounds FROM ML.PREDICT(MODEL `bqml_tutorial.natality_model`, ( SELECT * FROM `bigquery-public-data.samples.natality` WHERE state = "WY"))
Optional: Klicken Sie in der Drop-down-Liste settings_applicationsMehr auf Abfrageeinstellungen, um den Verarbeitungsort festzulegen. Wählen Sie unter Verarbeitungsort die Option USA aus. Dieser Schritt ist optional, da der Verarbeitungsort anhand des Standorts des Datasets automatisch erkannt wird.
Klicken Sie auf Ausführen.
Sobald die Abfrage abgeschlossen ist, klicken Sie unterhalb des Textbereichs der Abfrage auf den Tab Ergebnisse. Die Ergebnisse sollten so aussehen:
+----------------------------+ | predicted_weight_pounds | +----------------------------+ | 7.735962399307027 | +----------------------------+ | 7.728855793480761 | +----------------------------+ | 7.383850250400428 | +----------------------------+ | 7.4132677633242565 | +----------------------------+ | 7.734971309702814 | +----------------------------+
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
- Sie können das von Ihnen erstellte Projekt löschen.
- Sie können das Projekt aber auch behalten und das Dataset löschen.
Dataset löschen
Wenn Sie Ihr Projekt löschen, werden alle Datasets und Tabellen entfernt. Wenn Sie das Projekt wieder verwenden möchten, können Sie das in dieser Anleitung erstellte Dataset löschen:
Rufen Sie, falls erforderlich, die Seite "BigQuery" in der Google Cloud Console auf.
Wählen Sie im Navigationsbereich das Dataset bqml_tutorial aus, das Sie erstellt haben.
Klicken Sie auf der rechten Seite des Fensters auf Dataset löschen. Das Dataset, die Tabelle und alle Daten werden gelöscht.
Bestätigen Sie im Dialogfeld Dataset löschen den Löschbefehl. Geben Sie dazu den Namen des Datasets (
bqml_tutorial) ein und klicken Sie auf Löschen.
Projekt löschen
So löschen Sie das Projekt:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Nächste Schritte
- Weitere Informationen über das maschinelle Lernen im Machine Learning Crash Course lesen
- Eine Übersicht über BigQuery ML finden Sie unter Einführung in BigQuery ML.
- Weitere Informationen zur Google Cloud Console finden Sie unter Google Cloud Console verwenden.