Utiliser des champs imbriqués et répétés
BigQuery peut être utilisé avec de nombreuses méthodes de modélisation des données et offre généralement de hautes performances dans de nombreuses méthodologies de modèle de données. Pour affiner davantage les performances d'un modèle de données, vous pouvez envisager de recourir à la dénormalisation des données, c'est-à-dire ajouter des colonnes de données à une seule table afin de réduire ou supprimer des jointures de table.
Bonne pratique : Utilisez des champs imbriqués et répétés pour dénormaliser le stockage de données et augmenter les performances des requêtes.
La dénormalisation est une stratégie courante qui permet d'améliorer les performances de lecture sur des ensembles de données relationnels auparavant normalisés. La méthode recommandée pour dénormaliser des données dans BigQuery consiste à utiliser des champs imbriqués et répétés. Il est préférable d'employer cette stratégie lorsque vous avez affaire à des relations hiérarchiques souvent interrogées ensemble (par exemple, dans des relations parent-enfant).
Les économies de stockage rendues possibles par la normalisation des données ont moins d'impact sur les systèmes modernes. L'augmentation des coûts de stockage est justifiée par les gains de performance découlant de la dénormalisation des données. Les jointures nécessitent une coordination des données (synonyme de bande passante de communication). La dénormalisation localise les données dans des emplacements individuels, ce qui permet une exécution en parallèle.
Pour maintenir des relations tout en dénormalisant vos données, utilisez des champs imbriqués et répétés au lieu d'aplatir complètement vos données. Lorsque les données relationnelles sont complètement aplaties, la communication réseau (brassage) peut avoir un impact négatif sur les performances des requêtes.
Par exemple, dénormaliser un schéma de commandes sans utiliser de champs imbriqués et répétés peut nécessiter un regroupement par champ tel que order_id (lorsqu'il existe une relation de un à plusieurs). En raison du brassage qu'il implique, le regroupement des données est moins performant que la dénormalisation des données à l'aide de champs imbriqués et répétés.
Dans certaines circonstances, la dénormalisation des données et l'utilisation de champs imbriqués et répétés peuvent ne pas améliorer les performances. Par exemple, les schémas en étoile sont généralement des schémas optimisés pour l'analyse. Par conséquent, les performances peuvent ne pas être significativement différentes si vous tentez de les dénormaliser davantage.
Utiliser des champs imbriqués et répétés
BigQuery ne nécessite pas une dénormalisation complètement plate. Vous pouvez utiliser des champs imbriqués et répétés pour maintenir les relations.
Données d'imbrication (
STRUCT)- Les données d'imbrication vous permettent de représenter des entités étrangères de façon intégrée.
- Interroger des données imbriquées utilise la syntaxe "dot" pour référencer des champs feuille, ce qui est semblable à la syntaxe utilisée pour une jointure.
- Les données imbriquées sont représentées par un type
STRUCTen GoogleSQL.
Données répétées (
ARRAY)- Créer un champ de type
RECORDavec le mode défini surREPEATEDvous permet de conserver une relation de un à plusieurs de façon intégrée (à condition que la relation ne soit pas à cardinalité élevée). - Avec des données répétées, le brassage n'est pas nécessaire.
- Les données répétées sont représentées sous la forme d'un tableau
ARRAY. Vous pouvez utiliser une fonctionARRAYen GoogleSQL lorsque vous interrogez les données répétées.
- Créer un champ de type
Données imbriquées et répétées (
ARRAYdeSTRUCTs)- L'imbrication et la répétition se complètent.
- Par exemple, dans une table d'enregistrements de transactions, vous pouvez inclure un tableau de lignes
STRUCT.
Pour en savoir plus, consultez la page Spécifier des colonnes imbriquées et répétées dans des schémas de table.
Pour en savoir plus sur la dénormalisation des données, consultez la section Dénormalisation.
Exemple
Prenons l'exemple d'une table Orders avec une ligne pour chaque élément de ligne vendus :
| Order_Id | Item_Name |
|---|---|
| 001 | A1 |
| 001 | B1 |
| 002 | A1 |
| 002 | C1 |
Si vous souhaitez analyser les données de cette table, vous devez utiliser une clause GROUP BY, semblable à ceci :
SELECT COUNT (Item_Name) FROM Orders GROUP BY Order_Id;
La clause GROUP BY entraîne une surcharge de calcul supplémentaire, mais celle-ci peut être évitée en imbricant les données répétées. Vous pouvez éviter d'utiliser une clause GROUP BY en créant une table avec une commande par ligne dans laquelle les éléments de ligne de la commande sont dans un champ imbriqué :
| Order_Id | Item_Name |
|---|---|
| 001 |
A1 B1 |
| 002 |
A1 C1 |
Dans BigQuery, vous spécifiez généralement un schéma imbriqué en tant qu'un ARRAY d'objets STRUCT. Vous utilisez l'opérateur UNNEST pour aplatir les données imbriquées, comme indiqué dans la requête suivante :
SELECT * FROM UNNEST( [ STRUCT('001' AS Order_Id, ['A1', 'B1'] AS Item_Name), STRUCT('002' AS Order_Id, ['A1', 'C1'] AS Item_Name) ] );
Cette requête donne des résultats semblables à ceux-ci :
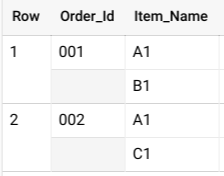
Si ces données ne sont pas imbriquées, vous pouvez potentiellement avoir plusieurs lignes pour chaque commande (une pour chaque article vendu dans cette commande), ce qui générerait une grande table et une opération GROUP BY coûteuse.
Exercice
Vous pouvez observer la différence de performances entre les requêtes utilisant des champs imbriqués et celles n'en utilisant pas en suivant les étapes décrites dans cette section.
Créez une table basée sur l'ensemble de données public
bigquery-public-data.stackoverflow.comments:CREATE OR REPLACE TABLE `PROJECT.DATASET.stackoverflow` AS ( SELECT user_id, post_id, creation_date FROM `bigquery-public-data.stackoverflow.comments` );
En utilisant la table
stackoverflow, exécutez la requête suivante pour afficher le commentaire le plus ancien pour chaque utilisateur :SELECT user_id, ARRAY_AGG(STRUCT(post_id, creation_date AS earliest_comment) ORDER BY creation_date ASC LIMIT 1)[OFFSET(0)].* FROM `PROJECT.DATASET.stackoverflow` GROUP BY user_id ORDER BY user_id ASC;
L'exécution de cette requête prend environ 25 secondes, pendant lesquelles seront traités 1,88 Go de données.
Créez une deuxième table avec des données identiques qui créent un champ
commentsen utilisant un typeSTRUCTpour stocker les donnéespost_idetcreation_date, plutôt que d'utiliser deux champs individuels :CREATE OR REPLACE TABLE `PROJECT.DATASET.stackoverflow_nested` AS ( SELECT user_id, ARRAY_AGG(STRUCT(post_id, creation_date) ORDER BY creation_date ASC) AS comments FROM `bigquery-public-data.stackoverflow.comments` GROUP BY user_id );
En utilisant la table
stackoverflow_nested, exécutez la requête suivante pour afficher le commentaire le plus ancien pour chaque utilisateur :SELECT user_id, (SELECT AS STRUCT post_id, creation_date as earliest_comment FROM UNNEST(comments) ORDER BY creation_date ASC LIMIT 1).* FROM `PROJECT.DATASET.stackoverflow_nested` ORDER BY user_id ASC;
L'exécution de cette requête prend environ 10 secondes, pendant lesquelles seront traités 1,28 Go de données.
Supprimez les tables
stackoverflowetstackoverflow_nestedlorsque vous avez terminé.