중첩 및 반복 필드 사용
BigQuery는 여러 가지 데이터 모델링 방법에서 사용 가능하며 일반적으로 여러 데이터 모델 방법론에서 고성능을 제공합니다. 성능을 위해 데이터 모델을 더 세부적으로 조정할 때 고려할 수 있는 한 가지 방법은 데이터 비정규화입니다. 비정규화에서는 단일 테이블에 데이터 열을 추가하여 테이블 조인을 줄이거나 삭제합니다.
권장사항: 중첩 및 반복 필드를 사용하여 데이터 스토리지를 비정규화하고 쿼리 성능을 높이세요.
비정규화는 이전에 정규화된 관계형 데이터 세트의 읽기 성능을 높이기 위한 일반적인 전략입니다. BigQuery에서 데이터를 비정규화할 때는 중첩되고 반복되는 입력란을 사용하는 것이 좋습니다. 이 전략은 관계가 계층적이며 부모-자식 관계와 같이 자주 쿼리되는 경우 사용하는 것이 가장 좋습니다.
현대적인 시스템에서는 정규화된 데이터 사용에 따른 스토리지 비용 절감 효과가 크지 않습니다. 비정규화된 데이터 사용은 스토리지 비용을 높이지만 이를 상쇄하는 성능상의 이점을 제공합니다. 조인에는 데이터 조정(통신 대역폭)이 필요합니다. 비정규화는 데이터를 개별 슬롯에 로컬화하므로 병렬 실행이 가능합니다.
데이터의 비정규화와 동시에 관계를 유지해야 한다면 데이터를 완전히 병합하는 대신 중첩 및 반복 필드를 사용하면 됩니다. 관계형 데이터가 완전히 병합되면 네트워크 통신(무작위 섞기)이 쿼리 성능에 악영향을 줄 수 있습니다.
예를 들어 중첩 및 반복 필드를 사용하지 않고 주문 스키마를 비정규화하면(일대다 관계가 존재하는 경우) order_id처럼 필드별로 그룹화해야 할 수도 있습니다. 무작위 섞기가 동원되기 때문에 데이터 그룹화는 중첩 및 반복 필드를 이용한 데이터 비정규화보다 효과가 떨어집니다.
중첩 및 반복 필드로 데이터를 비정규화해도 성능이 향상되지 않을 수 있습니다. 예를 들어 별표 스키마는 일반적으로 분석에 최적화된 스키마이므로 추가로 비정규화하려고 해도 성능이 크게 달라지지 않을 수 있습니다.
중첩 및 반복 필드 사용
BigQuery는 완전한 병합 비정규화를 요구하지 않습니다. 중첩 및 반복 필드를 이용해 관계를 유지할 수 있습니다.
데이터 중첩(
STRUCT)- 데이터를 중첩하면 외부 항목을 인라인으로 표현할 수 있습니다.
- 중첩 데이터를 쿼리하면 조인을 사용하는 구문과 유사한 '점' 구문을 사용하여 리프 필드를 참조합니다.
- 중첩된 데이터는 GoogleSQL에서
STRUCT유형으로 표현됩니다.
반복 데이터(
ARRAY)- 모드를
REPEATED로 설정하고RECORD유형의 필드를 만들면 관계의 카디널리티가 높지 않은 한 일대다 관계를 인라인으로 유지할 수 있습니다. - 반복 데이터가 있으면 셔플링이 필요 없습니다.
- 반복 데이터는
ARRAY로 표현됩니다. 반복 데이터를 쿼리할 때 GoogleSQL에서ARRAY함수를 사용할 수 있습니다.
- 모드를
중첩 및 반복 데이터(
STRUCT의ARRAY)- 중첩과 반복은 서로를 보완합니다.
- 예를 들어 트랜잭션 레코드 테이블에 항목
STRUCT배열을 넣을 수 있습니다.
자세한 내용은 테이블 스키마에서 중첩 및 반복 열 지정을 참조하세요.
데이터 비정규화에 대한 자세한 내용은 비정규화를 참조하세요.
예
판매된 각 항목에 대한 행이 있는 Orders 테이블을 가정해 보세요.
| Order_Id | Item_Name |
|---|---|
| 001 | A1 |
| 001 | B1 |
| 002 | A1 |
| 002 | C1 |
이 테이블의 데이터를 분석하려면 다음과 비슷한 GROUP BY 절을 사용해야 합니다.
SELECT COUNT (Item_Name) FROM Orders GROUP BY Order_Id;
GROUP BY 절에는 추가 계산 오버헤드가 포함되지만, 반복되는 데이터를 중첩하면 이를 피할 수 있습니다. 행당 주문 하나가 있는 테이블을 만들어 GROUP BY 절을 사용하지 않도록 할 수 있습니다. 여기서 주문 행 항목은 중첩 필드에 있어야 합니다.
| Order_Id | Item_Name |
|---|---|
| 001 |
A1 B1 |
| 002 |
A1 C1 |
BigQuery에서는 일반적으로 중첩된 스키마를 STRUCT 객체의 ARRAY으로 지정합니다. 다음 쿼리에 표시된 것처럼 UNNEST 연산자를 사용하여 중첩된 데이터를 평면화합니다.
SELECT * FROM UNNEST( [ STRUCT('001' AS Order_Id, ['A1', 'B1'] AS Item_Name), STRUCT('002' AS Order_Id, ['A1', 'C1'] AS Item_Name) ] );
이 쿼리는 다음과 유사한 결과를 생성합니다.
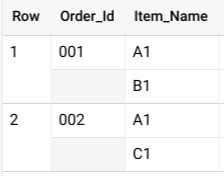
이 데이터가 중첩되지 않은 경우 각 주문에서 판매된 항목별로 여러 개의 행이 생길 수 있으며, 이 경우 테이블이 커지고 비용이 많이 드는 GROUP BY 작업이 발생할 수 있습니다.
운동
이 섹션의 단계를 수행하면 중첩 필드를 사용하는 쿼리와 그렇지 않은 쿼리의 성능 차이를 확인할 수 있습니다.
bigquery-public-data.stackoverflow.comments공개 데이터 세트를 기반으로 테이블을 만듭니다.CREATE OR REPLACE TABLE `PROJECT.DATASET.stackoverflow` AS ( SELECT user_id, post_id, creation_date FROM `bigquery-public-data.stackoverflow.comments` );
stackoverflow테이블을 사용하여 다음 쿼리를 실행하여 각 사용자의 처음 댓글을 확인합니다.SELECT user_id, ARRAY_AGG(STRUCT(post_id, creation_date AS earliest_comment) ORDER BY creation_date ASC LIMIT 1)[OFFSET(0)].* FROM `PROJECT.DATASET.stackoverflow` GROUP BY user_id ORDER BY user_id ASC;
이 쿼리는 실행하는 데 약 25초가 소요되며 1.88GB의 데이터를 처리합니다.
동일한 데이터로 두 개의 개별 필드 대신
STRUCT유형을 사용하여comments필드를 만들어post_id및creation_date데이터를 저장할 두 번째 테이블을 만듭니다.CREATE OR REPLACE TABLE `PROJECT.DATASET.stackoverflow_nested` AS ( SELECT user_id, ARRAY_AGG(STRUCT(post_id, creation_date) ORDER BY creation_date ASC) AS comments FROM `bigquery-public-data.stackoverflow.comments` GROUP BY user_id );
stackoverflow_nested테이블을 사용하여 다음 쿼리를 실행하여 각 사용자의 처음 댓글을 확인합니다.SELECT user_id, (SELECT AS STRUCT post_id, creation_date as earliest_comment FROM UNNEST(comments) ORDER BY creation_date ASC LIMIT 1).* FROM `PROJECT.DATASET.stackoverflow_nested` ORDER BY user_id ASC;
이 쿼리는 실행하는 데 약 10초가 소요되고 1.28GB의 데이터를 처리합니다.
사용을 마쳤으면
stackoverflow및stackoverflow_nested테이블을 삭제합니다.