「ARIMA_PLUS」時系列モデルの予測値を制限する
このチュートリアルでは、制限を使用して、ARIMA_PLUS 時系列モデルから返される予測結果を絞り込む方法について説明します。同じデータに対して、制限を使用する時系列モデルと、制限を使用しない時系列モデルの 2 つを作成します。これにより、モデルから返された結果を比較して、制限の指定によってどのような違いがあるのかを理解できます。
このチュートリアルでは、new_york.citibike_trips データを使用してモデルをトレーニングします。このデータセットには、ニューヨーク市でのシティバイクの利用状況に関する情報が含まれています。
このチュートリアルに進む前に、1 つの時系列予測を行う方法について理解しておく必要があります。このトピックの概要については、Google アナリティクス データからの 1 つの時系列を予測するのチュートリアルをご覧ください。
必要な権限
データセットを作成するには、
bigquery.datasets.createIAM 権限が必要です。モデルを作成するには、次の権限が必要です。
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
推論を実行するには、次の権限が必要です。
bigquery.models.getDatabigquery.jobs.create
BigQuery における IAM ロールと権限の詳細については、IAM の概要をご覧ください。
目標
このチュートリアルでは、以下を使用します。
CREATE MODELステートメント: 時系列モデルを作成します。ML.FORECAST関数: 1 日の合計訪問数を予測します。
費用
このチュートリアルでは、課金対象となる以下の Google Cloudのコンポーネントを使用しています。
- BigQuery
- BigQuery ML
BigQuery の費用の詳細については、BigQuery の料金ページをご覧ください。
BigQuery ML の費用の詳細については、BigQuery ML の料金をご覧ください。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
Google Cloud コンソールで、[BigQuery] ページに移動します。
[エクスプローラ] ペインで、プロジェクト名をクリックします。
[アクションを表示] > [データセットを作成] をクリックします。
![[データセットを作成] のメニュー オプション。](https://cloud.google.com/static/bigquery/images/create-dataset.png?authuser=0&hl=ja)
[データセットを作成] ページで、次の操作を行います。
[データセット ID] に「
bqml_tutorial」と入力します。[ロケーション タイプ] で [マルチリージョン] を選択してから、[US(米国の複数のリージョン)] を選択します。
残りのデフォルトの設定は変更せず、[データセットを作成] をクリックします。
データの場所が
USに設定され、BigQuery ML tutorial datasetという説明の付いた、bqml_tutorialという名前のデータセットを作成します。bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
このコマンドでは、
--datasetフラグの代わりに-dショートカットを使用しています。-dと--datasetを省略した場合、このコマンドはデフォルトでデータセットを作成します。データセットが作成されたことを確認します。
bq lsGoogle Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
クエリエディタに次の GoogleSQL クエリを入力します。
#standardSQL SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data`.new_york.citibike_trips GROUP BY date
[実行] をクリックします。クエリ結果は次のようになります。
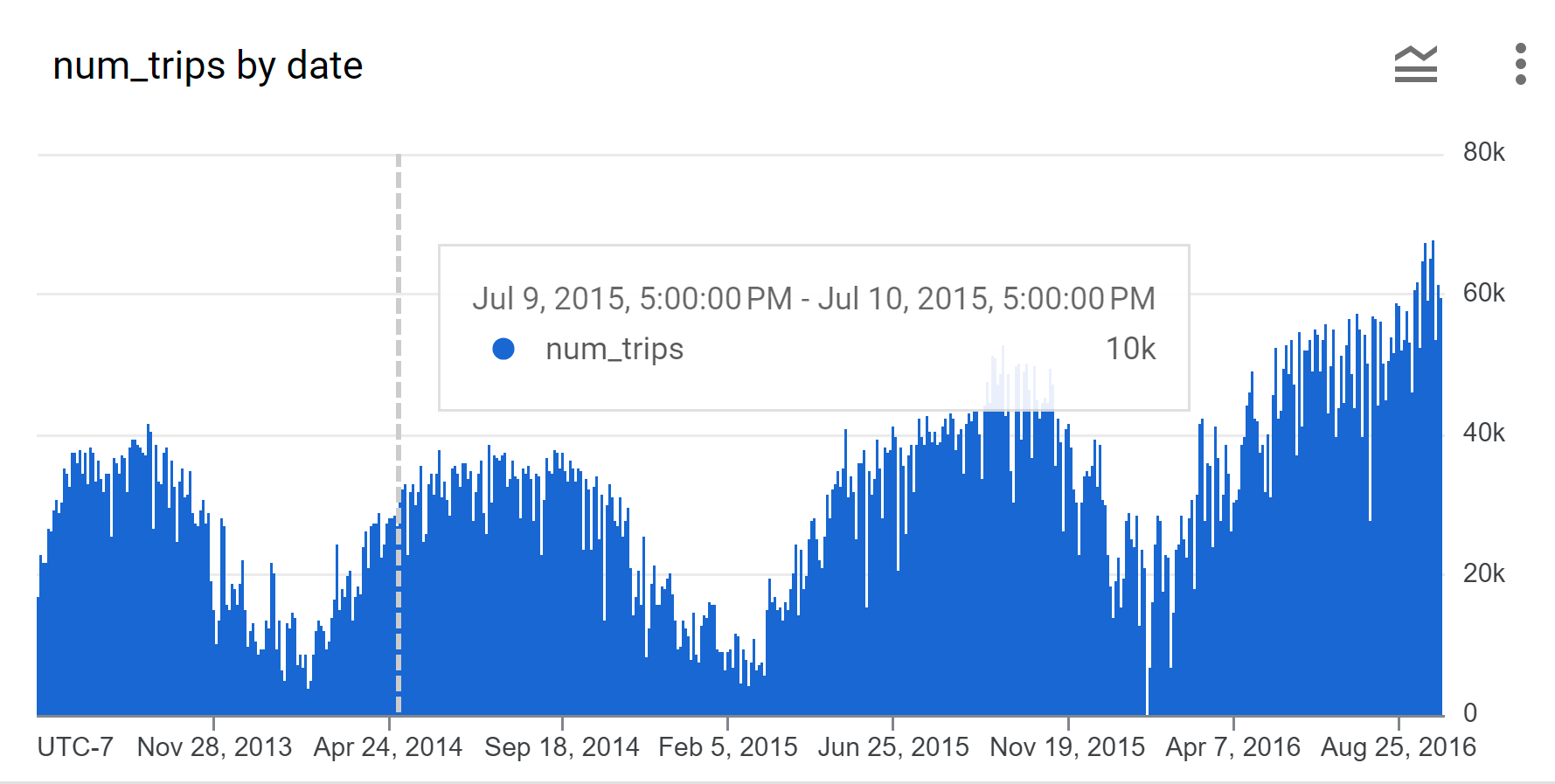
Google Cloud コンソールを使用して時系列データをグラフ化します。[クエリ結果] ペインで、[グラフ] タブをクリックします。[グラフの構成] ペインの [グラフの種類] で、[棒] を選択します。
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
クエリエディタに次の GoogleSQL クエリを入力します。
#standardSQL CREATE OR REPLACE MODEL bqml_tutorial.nyc_citibike_arima_model OPTIONS ( model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_id') AS SELECT EXTRACT(DATE FROM starttime) AS date, COUNT(*) AS num_trips, start_station_id FROM `bigquery-public-data`.new_york.citibike_trips WHERE starttime > '2014-07-11' AND starttime < '2015-02-11' GROUP BY date, start_station_id;
[実行] をクリックします。
クエリが完了するまでに約 80 秒かかります。完了後、モデル(
nyc_citibike_arima_model)が [エクスプローラ] ペインに表示されます。このクエリではCREATE MODELステートメントを使用してモデルを作成するため、クエリの結果はありません。Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
クエリエディタに次の GoogleSQL クエリを入力します。
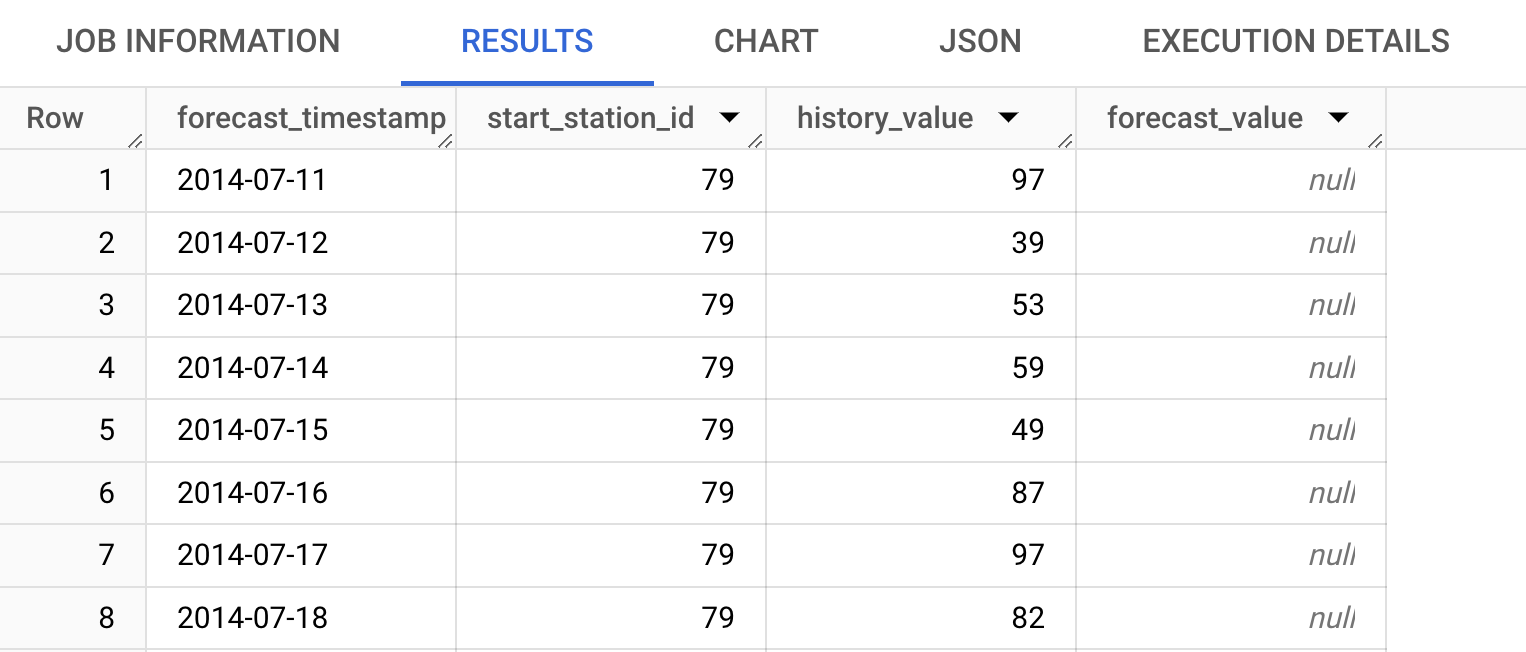
#standardSQL SELECT forecast_timestamp AS forecast_timestamp, start_station_id AS start_station_id, history_value AS history_value, forecast_value AS forecast_value FROM ( ( SELECT DATE(forecast_timestamp) AS forecast_timestamp, NULL AS history_value, forecast_value AS forecast_value, start_station_id AS start_station_id, FROM ML.FORECAST( MODEL bqml_tutorial.`nyc_citibike_arima_model`, STRUCT( 365 AS horizon, 0.9 AS confidence_level)) ) UNION ALL ( SELECT DATE(date_name) AS forecast_timestamp, num_trips AS history_value, NULL AS forecast_value, start_station_id AS start_station_id, FROM ( SELECT EXTRACT(DATE FROM starttime) AS date_name, COUNT(*) AS num_trips, start_station_id AS start_station_id FROM `bigquery-public-data`.new_york.citibike_trips WHERE starttime > '2014-07-11' AND starttime < '2015-02-11' GROUP BY date_name, start_station_id ) ) ) WHERE start_station_id = 79 ORDER BY forecast_timestamp, start_station_id
[実行] をクリックします。クエリ結果は次のようになります。
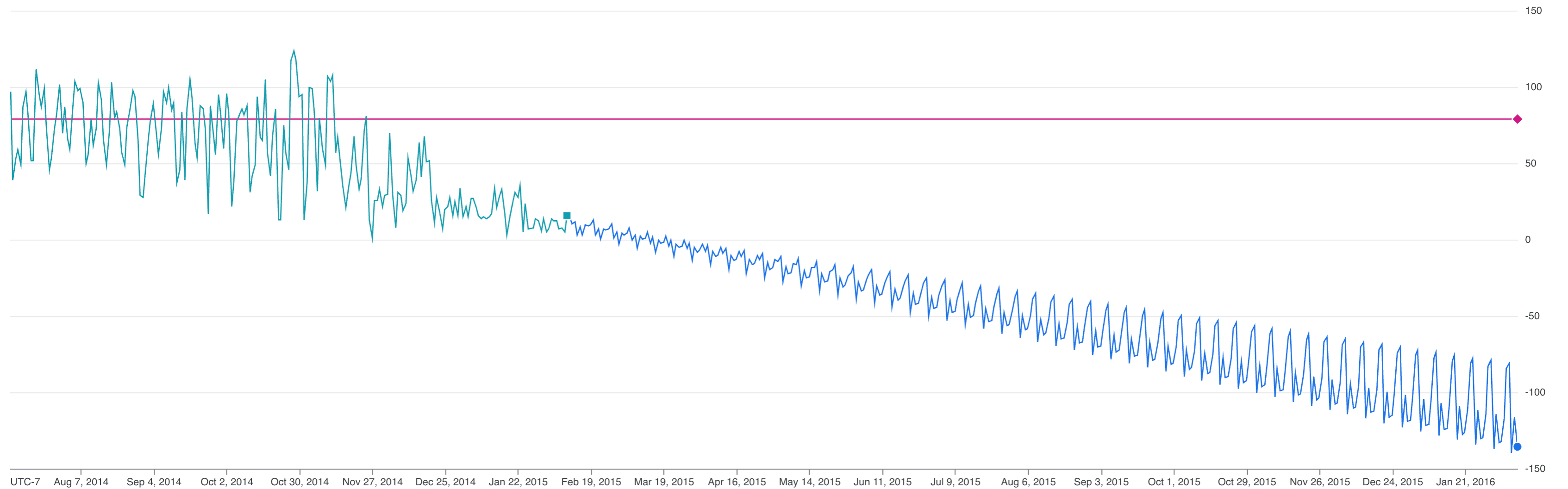
Google Cloud コンソールを使用して時系列データをグラフ化します。[クエリ結果] ペインで、[グラフ] タブをクリックします。
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
クエリエディタに次の GoogleSQL クエリを入力します。
#standardSQL CREATE OR REPLACE MODEL bqml_tutorial.nyc_citibike_arima_model OPTIONS ( model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_id', forecast_limit_lower_bound = 0) AS SELECT EXTRACT(DATE FROM starttime) AS date, COUNT(*) AS num_trips, start_station_id FROM `bigquery-public-data`.new_york.citibike_trips WHERE starttime > '2014-07-11' AND starttime < '2015-02-11' GROUP BY date, start_station_id;
[実行] をクリックします。
クエリが完了するまでに約 100 秒かかります。完了後、モデル(
nyc_citibike_arima_model_with_limits)が [エクスプローラ] ペインに表示されます。このクエリではCREATE MODELステートメントを使用してモデルを作成するため、クエリの結果はありません。Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
クエリエディタに次の GoogleSQL クエリを入力します。
#standardSQL SELECT forecast_timestamp AS forecast_timestamp, start_station_id AS start_station_id, history_value AS history_value, forecast_value AS forecast_value FROM ( ( SELECT DATE(forecast_timestamp) AS forecast_timestamp, NULL AS history_value, forecast_value AS forecast_value, start_station_id AS start_station_id, FROM ML.FORECAST( MODEL bqml_tutorial.`nyc_citibike_arima_model`, STRUCT( 365 AS horizon, 0.9 AS confidence_level)) ) UNION ALL ( SELECT DATE(date_name) AS forecast_timestamp, num_trips AS history_value, NULL AS forecast_value, start_station_id AS start_station_id, FROM ( SELECT EXTRACT(DATE FROM starttime) AS date_name, COUNT(*) AS num_trips, start_station_id AS start_station_id FROM `bigquery-public-data`.new_york.citibike_trips WHERE starttime > '2014-07-11' AND starttime < '2015-02-11' GROUP BY date_name, start_station_id ) ) ) WHERE start_station_id = 79 ORDER BY forecast_timestamp, start_station_id
[実行] をクリックします。
Google Cloud コンソールを使用して時系列データをグラフ化します。[クエリ結果] ペインで、[グラフ] タブをクリックします。
必要に応じて、Google Cloud コンソールで [BigQuery] ページを開きます。
ナビゲーションで、作成した bqml_tutorial データセットをクリックします。
ウィンドウの右側にある [データセットを削除] をクリックします。この操作を行うと、データセット、テーブル、すべてのデータが削除されます。
[データセットの削除] ダイアログ ボックスでデータセットの名前(
bqml_tutorial)を入力し、[削除] をクリックして確定します。- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- 1 つのクエリでニューヨーク市のシティバイクの利用データから複数の時系列を予測する方法を学習する。
- ARIMA_PLUS を高速化して 100 万時系列を数時間で予測する方法を学習する。
- 機械学習集中講座で機械学習について学習する。
- BigQuery ML の概要で BigQuery ML の概要を確認する。
- Google Cloud コンソールの使用で Google Cloud コンソールの詳細を確認する。
データセットを作成する
ML モデルを保存する BigQuery データセットを作成します。
コンソール
bq
新しいデータセットを作成するには、--location フラグを指定した bq mk コマンドを使用します。使用可能なパラメータの一覧については、bq mk --dataset コマンドのリファレンスをご覧ください。
API
定義済みのデータセット リソースを使用して datasets.insert メソッドを呼び出します。
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
予測する時系列を可視化する
モデルを作成する前に、入力時系列がどのように表示されるかを確認しておきましょう。
SQL
次のクエリでは、FROM bigquery-public-data.new_york.citibike_trips 句により new_york データセット内の citibike_trips テーブルのデータを取得します。
SELECT ステートメントで EXTRACT 関数を使用し、starttime 列から日付情報を抽出します。さらに、COUNT(*) 句を使用して、1 日あたりのシティバイクの合計利用回数を取得します。
#standardSQL SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data`.new_york.citibike_trips GROUP BY date
クエリを実行する手順は次のとおりです。
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
次のサンプルでは、bigquery-public-data.new_york.citibike_trips は new_york データセット内の citibike_trips テーブルにクエリを実行していることを示しています。
次のような結果になります。
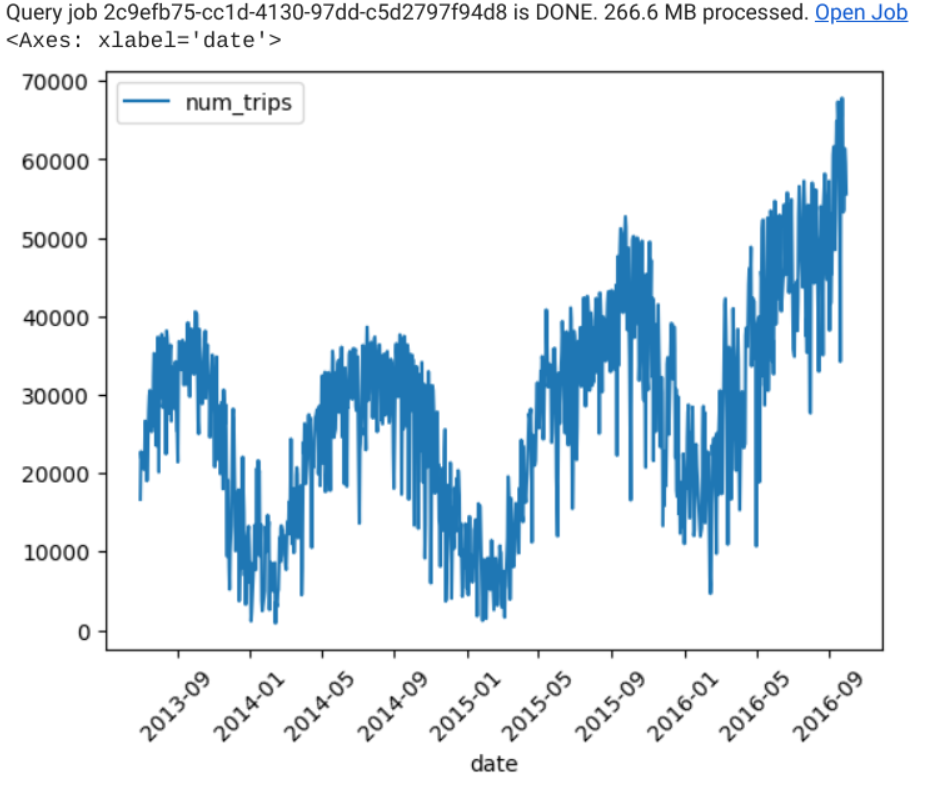
時系列モデルを作成する
ニューヨーク市のシティバイクの利用データを使用して時系列モデルを作成します。
次の GoogleSQL クエリは、シティバイクの 1 日あたりの合計利用回数を予測するモデルを作成します。CREATE MODEL ステートメントで bqml_tutorial.nyc_citibike_arima_model というモデルを作成してトレーニングします。
#standardSQL CREATE OR REPLACE MODEL bqml_tutorial.nyc_citibike_arima_model OPTIONS ( model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_id') AS SELECT EXTRACT(DATE FROM starttime) AS date, COUNT(*) AS num_trips, start_station_id FROM `bigquery-public-data`.new_york.citibike_trips WHERE starttime > '2014-07-11' AND starttime < '2015-02-11' GROUP BY date, start_station_id;
OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) 句で ARIMA ベースの時系列モデルを作成しています。デフォルトは auto_arima=TRUE であるため、auto.ARIMA アルゴリズムによって ARIMA_PLUS モデルのハイパーパラメータが自動的にチューニングされます。アルゴリズムが多数の候補モデルを学習し、Akaike information criterion(AIC)が最も低い最適なモデルを選択します。また、data_frequency='AUTO_FREQUENCY' がデフォルトのため、トレーニング プロセスでは入力時系列のデータ頻度が自動的に推定されます。CREATE MODEL ステートメントではデフォルトで decompose_time_series=TRUE を使用するため、時系列の履歴部分と予測部分の両方がモデルに保存されます。パラメータ time_series_id_col = 'start_station_id' を設定すると、モデルは start_station_id に基づく単一のクエリを使用して複数の時系列を適合し、予測します。この情報から、季節などの別々の時系列コンポーネントを取得して時系列を予測する方法について理解を深めることができます。
CREATE MODEL クエリを実行してモデルを作成し、トレーニングします。
時系列を予測して結果を可視化する
時系列を予測する方法を説明するために、ML.FORECAST 関数を使用して、季節性やトレンドなどのすべての副時系列のコンポーネントを可視化します。
その手順は次のとおりです。
グラフが示す、start_station_id=79 に基づくシティバイクの 1 日あたりの合計利用回数の予測値は負の値であるため、この予測は役に立ちません。制限のあるモデルを使用すると、予測データが改善されます。
制限のある時系列モデルを作成する
ニューヨーク市のシティバイクの利用データを使用して、制限のある時系列モデルを作成します。
次の GoogleSQL クエリは、シティバイクの 1 日あたりの合計利用回数を予測するモデルを作成します。CREATE MODEL ステートメントで bqml_tutorial.nyc_citibike_arima_model_with_limits というモデルを作成してトレーニングします。このモデルと先ほど作成したモデルとの重要な違いは、forecast_limit_lower_bound=0 オプションが追加されていることです。このオプションを使用すると、モデルは time_series_data_col 引数で指定された列(この場合は num_trips)の値に基づいて、0 より大きい値のみを予測します。
#standardSQL CREATE OR REPLACE MODEL bqml_tutorial.nyc_citibike_arima_model OPTIONS ( model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_id', forecast_limit_lower_bound = 0) AS SELECT EXTRACT(DATE FROM starttime) AS date, COUNT(*) AS num_trips, start_station_id FROM `bigquery-public-data`.new_york.citibike_trips WHERE starttime > '2014-07-11' AND starttime < '2015-02-11' GROUP BY date, start_station_id;
CREATE MODEL クエリを実行してモデルを作成し、トレーニングします。
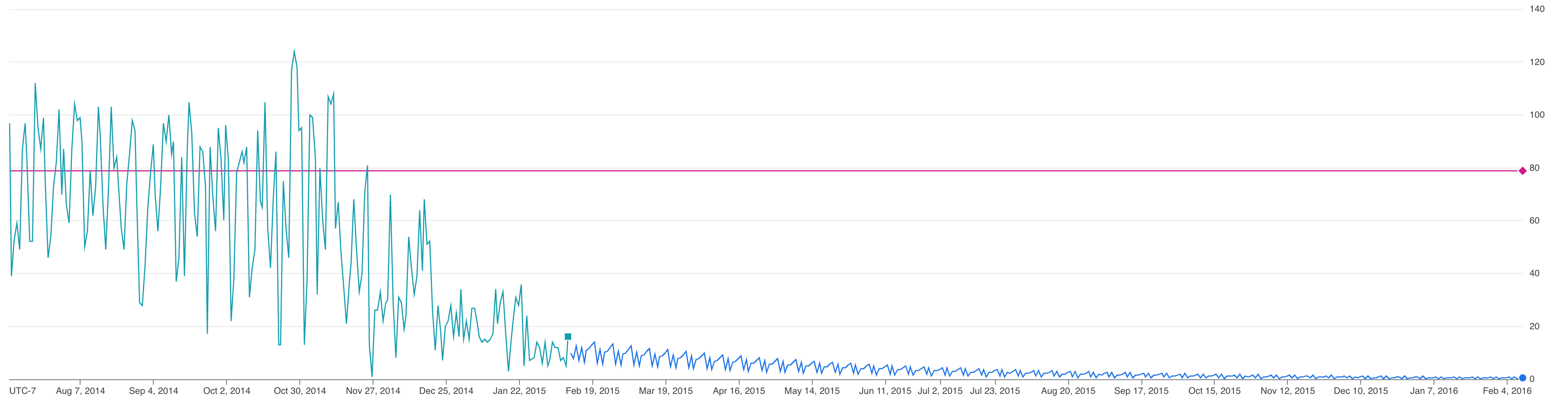
制限のあるモデルを使用して時系列を予測する
ARIMA PLUS モデルによって、start_station_id=79 に基づくシティバイクの 1 日あたりの合計利用回数が減少していることが検出されています。今後の予測値はこの傾向に従い、予測される合計利用回数は徐々に比較的少なくなっていきます。グラフが示す、start_station_id=79 に基づくシティバイクの 1 日あたりの合計利用回数の予測値は正の数値であり、役に立ちます。制限のあるモデルにより、start_station_id=79 に基づくシティバイクの 1 日あたりの合計利用回数が減少していることが検出されていますが、それでも意味のある予測値が得られます。
このチュートリアルで示すように forecast_limit_lower_bound オプションと forecast_limit_upper_bound オプションを使用すると、同様のシナリオ(株価や将来の売上額を予測する場合など)で意味のある予測値を取得できます。
データセットの削除
プロジェクトを削除すると、プロジェクト内のデータセットとテーブルがすべて削除されます。プロジェクトを再利用する場合は、このチュートリアルで作成したデータセットを削除できます。
プロジェクトの削除
プロジェクトを削除するには、次の操作を行います。