Dalam tutorial ini, Anda akan mempelajari cara mempercepat pelatihan sekumpulan model deret waktu univariat ARIMA_PLUS secara signifikan untuk melakukan beberapa perkiraan deret waktu dengan satu kueri. Anda juga akan mempelajari cara mengevaluasi akurasi perkiraan.
Tutorial ini melakukan perkiraan untuk beberapa deret waktu. Nilai yang diperkirakan dihitung untuk setiap titik waktu, untuk setiap nilai dalam satu atau beberapa kolom yang ditentukan. Misalnya, jika Anda ingin memperkirakan cuaca dan menentukan kolom yang berisi data kota, data yang diperkirakan akan berisi perkiraan untuk semua titik waktu untuk Kota A, lalu nilai yang diperkirakan untuk semua titik waktu untuk Kota B, dan seterusnya.
Tutorial ini menggunakan data dari tabel publik
bigquery-public-data.new_york.citibike_trips
dan
iowa_liquor_sales.sales. Data perjalanan sepeda hanya berisi beberapa ratus deret waktu, sehingga digunakan untuk mengilustrasikan berbagai strategi untuk mempercepat pelatihan model.
Data penjualan minuman keras memiliki lebih dari 1 juta deret waktu, sehingga digunakan untuk menunjukkan perkiraan deret waktu dalam skala besar.
Sebelum membaca tutorial ini, Anda harus membaca Memperkirakan beberapa deret waktu dengan model univariat dan Praktik terbaik perkiraan deret waktu skala besar.
Tujuan
Dalam tutorial ini, Anda akan menggunakan:
- Membuat model deret waktu menggunakan
pernyataan
CREATE MODEL. - Mengevaluasi akurasi model menggunakan
fungsi
ML.EVALUATE. - Menggunakan opsi
AUTO_ARIMA_MAX_ORDER,TIME_SERIES_LENGTH_FRACTION,MIN_TIME_SERIES_LENGTH, danMAX_TIME_SERIES_LENGTHdari pernyataanCREATE MODELuntuk mengurangi waktu pelatihan model secara signifikan.
Demi kemudahan, tutorial ini tidak membahas cara menggunakan fungsi
ML.FORECAST
atau
ML.EXPLAIN_FORECAST
untuk membuat perkiraan. Untuk mempelajari cara menggunakan fungsi tersebut, lihat
Memperkirakan beberapa deret waktu dengan model univariat.
Biaya
Tutorial ini menggunakan komponen Google Cloudyang dapat ditagih, termasuk:
- BigQuery
- BigQuery ML
Untuk mengetahui informasi selengkapnya tentang biaya, lihat halaman Harga BigQuery dan halaman Harga BigQuery ML.
Sebelum memulai
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
- BigQuery secara otomatis diaktifkan dalam project baru.
Untuk mengaktifkan BigQuery dalam project yang sudah ada, buka
Enable the BigQuery API.
Untuk membuat set data, Anda memerlukan izin IAM
bigquery.datasets.create.Untuk membuat model, Anda memerlukan izin berikut:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
Untuk menjalankan inferensi, Anda memerlukan izin berikut:
bigquery.models.getDatabigquery.jobs.create
Izin yang Diperlukan
Untuk mengetahui informasi lebih lanjut tentang peran dan izin IAM di BigQuery, baca Pengantar IAM.
Membuat set data
Buat set data BigQuery untuk menyimpan model ML Anda.
Konsol
Di konsol Google Cloud , buka halaman BigQuery.
Di panel Explorer, klik nama project Anda.
Klik View actions > Create dataset.
Di halaman Create dataset, lakukan hal berikut:
Untuk Dataset ID, masukkan
bqml_tutorial.Untuk Location type, pilih Multi-region, lalu pilih US (multiple regions in United States).
Jangan ubah setelan default yang tersisa, lalu klik Create dataset.
bq
Untuk membuat set data baru, gunakan perintah bq mk dengan flag --location. Untuk daftar lengkap kemungkinan parameter, lihat referensi
perintah bq mk --dataset.
Buat set data bernama
bqml_tutorialdengan lokasi data yang ditetapkan keUSdan deskripsiBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Perintah ini menggunakan pintasan
-d, bukan flag--dataset. Jika Anda menghapus-ddan--dataset, perintah defaultnya adalah membuat set data.Pastikan set data telah dibuat:
bq ls
API
Panggil metode datasets.insert dengan resource set data yang ditentukan.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di Panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Membuat tabel data input
Pernyataan SELECT dari kueri berikut menggunakan
fungsi EXTRACT
untuk mengekstrak informasi tanggal dari kolom starttime. Kueri ini menggunakan
klausa COUNT(*) untuk mendapatkan jumlah total harian perjalanan Citi Bike.
table_1 memiliki 679 deret waktu. Kueri menggunakan logika INNER JOIN tambahan
untuk memilih semua deret waktu yang memiliki lebih dari 400 titik waktu, sehingga menghasilkan total 383 deret waktu.
Ikuti langkah-langkah berikut untuk membuat tabel data input:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, tempel kueri berikut, lalu klik Run:
CREATE OR REPLACE TABLE `bqml_tutorial.nyc_citibike_time_series` AS WITH input_time_series AS ( SELECT start_station_name, EXTRACT(DATE FROM starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY start_station_name, date ) SELECT table_1.* FROM input_time_series AS table_1 INNER JOIN ( SELECT start_station_name, COUNT(*) AS num_points FROM input_time_series GROUP BY start_station_name) table_2 ON table_1.start_station_name = table_2.start_station_name WHERE num_points > 400;
Membuat model untuk beberapa deret waktu dengan parameter default
Anda ingin memperkirakan jumlah perjalanan sepeda untuk setiap
stasiun Citi Bike, yang memerlukan banyak model deret waktu; satu untuk setiap
stasiun Citi Bike yang disertakan dalam data input. Anda dapat menulis beberapa kueri
CREATE MODEL
untuk melakukannya, tetapi itu mungkin membosankan dan memakan waktu, terutama jika Anda memiliki banyak deret waktu. Sebagai gantinya, Anda dapat menggunakan satu kueri untuk membuat dan menyesuaikan sekumpulan model deret waktu guna memperkirakan beberapa deret waktu sekaligus.
Klausa OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...)
menunjukkan bahwa Anda membuat kumpulan
model ARIMA_PLUS deret waktu
berbasis ARIMA. Opsi
time_series_timestamp_col menentukan kolom yang berisi deret waktu, opsi time_series_data_col menentukan kolom yang akan diperkirakan, dan time_series_id_col menentukan satu atau beberapa dimensi yang ingin Anda buat deret waktunya.
Contoh ini tidak menyertakan titik waktu dalam deret waktu setelah 1 Juni 2016 , sehingga titik waktu tersebut dapat digunakan untuk mengevaluasi akurasi perkiraan di lain waktu menggunakan fungsi ML.EVALUATE.
Ikuti langkah-langkah berikut untuk membuat model:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, tempel kueri berikut, lalu klik Run:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_default` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name' ) AS SELECT * FROM bqml_tutorial.nyc_citibike_time_series WHERE date < '2016-06-01';
Kueri membutuhkan waktu sekitar 15 menit untuk menyelesaikannya.
Mengevaluasi akurasi perkiraan untuk setiap deret waktu
Evaluasi akurasi perkiraan model menggunakan fungsi ML.EVALUATE.
Ikuti langkah-langkah berikut untuk mengevaluasi model:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, tempel kueri berikut, lalu klik Run:
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Kueri ini melaporkan beberapa metrik perkiraan, termasuk:
Hasilnya akan terlihat seperti berikut:
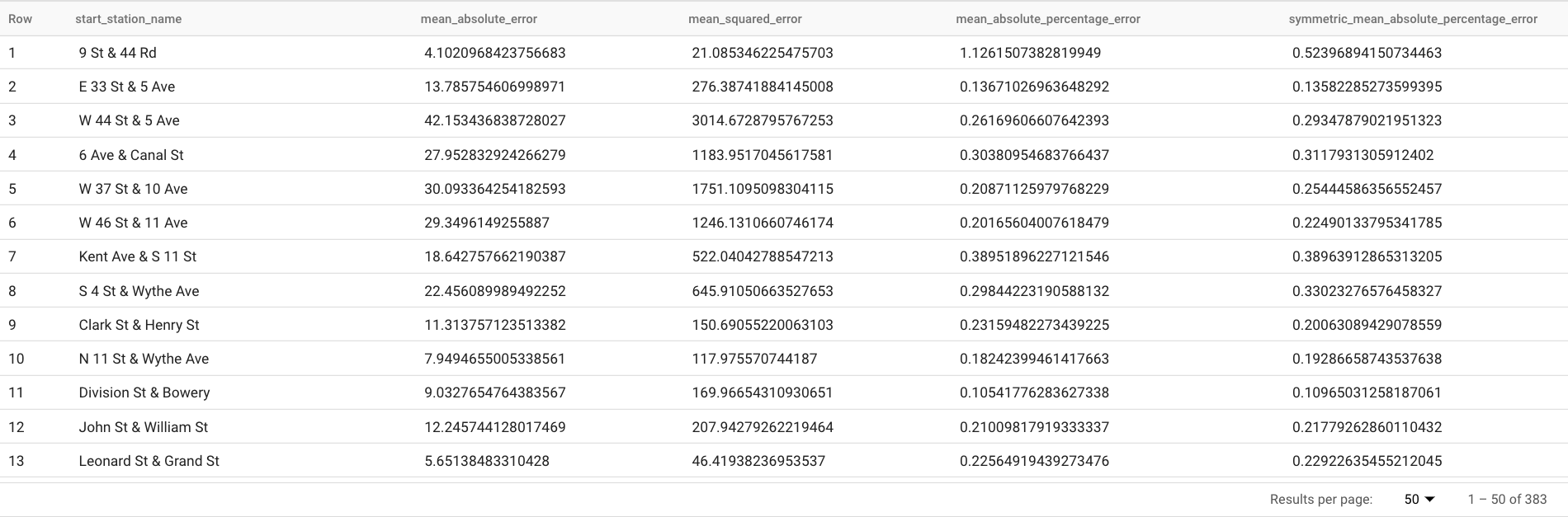
Klausa
TABLEdalam fungsiML.EVALUATEmengidentifikasi tabel yang berisi data kebenaran dasar. Hasil perkiraan dibandingkan dengan data kebenaran dasar untuk menghitung metrik akurasi. Dalam hal ini,nyc_citibike_time_seriesberisi titik deret waktu yang berada sebelum dan setelah 1 Juni 2016. Poin setelah 1 Juni 2016 adalah data kebenaran dasar. Titik sebelum 1 Juni 2016 digunakan untuk melatih model agar menghasilkan perkiraan setelah tanggal tersebut. Hanya poin setelah 1 Juni 2016 yang diperlukan untuk menghitung metrik. Poin sebelum 1 Juni 2016 akan diabaikan dalam penghitungan metrik.Klausa
STRUCTdalam fungsiML.EVALUATEmenentukan parameter untuk fungsi. Nilaihorizonadalah7, yang berarti kueri menghitung akurasi perkiraan berdasarkan perkiraan tujuh titik. Perhatikan bahwa jika data kebenaran dasar memiliki kurang dari tujuh poin untuk perbandingan, metrik akurasi akan dihitung berdasarkan poin yang tersedia saja. Nilaiperform_aggregationadalahTRUE, yang berarti metrik akurasi perkiraan digabungkan melalui metrik berdasarkan titik waktu. Jika Anda menentukan nilaiperform_aggregationsebesarFALSE, akurasi perkiraan akan ditampilkan untuk setiap perkiraan titik waktu.Untuk mengetahui informasi selengkapnya tentang kolom output, lihat fungsi
ML.EVALUATE.
Mengevaluasi akurasi perkiraan secara keseluruhan
Evaluasi akurasi perkiraan untuk semua 383 deret waktu.
Dari metrik perkiraan yang ditampilkan oleh ML.EVALUATE, hanya rata-rata error persentase absolut dan rata-rata error persentase absolut simetris yang tidak bergantung pada nilai deret waktu. Oleh karena itu, untuk mengevaluasi seluruh akurasi perkiraan dari rangkaian deret waktu, hanya gabungan dari kedua metrik ini yang bermanfaat.
Ikuti langkah-langkah berikut untuk mengevaluasi model:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, tempel kueri berikut, lalu klik Run:
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Kueri ini menampilkan nilai MAPE sebesar 0.3471, dan nilai sMAPE sebesar 0.2563.
Buat model untuk memperkirakan beberapa deret waktu dengan ruang penelusuran hyperparameter yang lebih kecil
Di bagian
Buat model untuk beberapa deret waktu dengan parameter default, Anda menggunakan nilai default untuk semua opsi pelatihan, termasuk opsi auto_arima_max_order. Opsi ini mengontrol ruang penelusuran
untuk penyesuaian hyperparameter dalam algoritma auto.ARIMA.
Dalam model yang dibuat oleh kueri berikut, Anda menggunakan ruang penelusuran yang lebih kecil untuk hyperparameter dengan mengubah nilai opsi auto_arima_max_order dari default 5 menjadi 2.
Ikuti langkah-langkah berikut untuk mengevaluasi model:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, tempel kueri berikut, lalu klik Run:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2 ) AS SELECT * FROM `bqml_tutorial.nyc_citibike_time_series` WHERE date < '2016-06-01';
Kueri membutuhkan waktu sekitar 2 menit untuk menyelesaikannya. Ingatlah bahwa model sebelumnya membutuhkan waktu sekitar 15 menit untuk diselesaikan saat nilai
auto_arima_max_orderadalah5, sehingga perubahan ini meningkatkan kecepatan pelatihan model sekitar 7x. Jika Anda bertanya-tanya mengapa peningkatan kecepatannya bukan5/2=2.5x, ini karena saat nilaiauto_arima_max_ordermeningkat, tidak hanya jumlah model kandidat yang meningkat, tetapi juga kompleksitasnya. Hal ini menyebabkan waktu pelatihan model meningkat.
Mengevaluasi akurasi perkiraan untuk model dengan ruang penelusuran hyperparameter yang lebih kecil
Ikuti langkah-langkah berikut untuk mengevaluasi model:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, tempel kueri berikut, lalu klik Run:
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Kueri ini menampilkan nilai MAPE sebesar 0.3337, dan nilai sMAPE sebesar 0.2337.
Di bagian
Mengevaluasi akurasi perkiraan keseluruhan, Anda mengevaluasi model dengan ruang penelusuran hyperparameter yang lebih besar, dengan nilai opsi auto_arima_max_order adalah 5. Hal ini menghasilkan nilai MAPE
0.3471, dan nilai sMAPE 0.2563. Dalam hal ini, Anda dapat melihat bahwa ruang penelusuran hyperparameter yang lebih kecil sebenarnya memberikan akurasi perkiraan yang lebih tinggi. Salah satu alasannya adalah karena algoritma auto.ARIMA hanya melakukan penyesuaian hyperparameter untuk modul tren di seluruh pipeline pemodelan. Model ARIMA terbaik yang dipilih oleh algoritma auto.ARIMA mungkin tidak menghasilkan hasil perkiraan terbaik untuk seluruh pipeline.
Buat model untuk memperkirakan beberapa deret waktu dengan ruang penelusuran hyperparameter yang lebih kecil dan strategi pelatihan yang cepat dan cerdas
Pada langkah ini, Anda akan menggunakan ruang penelusuran hyperparameter yang lebih kecil dan strategi pelatihan cerdas cepat menggunakan satu atau beberapa opsi pelatihan max_time_series_length, max_time_series_length, atau time_series_length_fraction.
Meskipun pemodelan berkala seperti tren musiman memerlukan jumlah titik waktu tertentu, pemodelan tren memerlukan titik waktu yang lebih sedikit. Sementara itu, pemodelan tren jauh lebih mahal secara komputasi daripada komponen deret waktu lainnya seperti musiman. Dengan opsi pelatihan cepat di atas, Anda dapat membuat model komponen tren secara efisien dengan subset deret waktu, sedangkan komponen deret waktu lainnya menggunakan seluruh deret waktu.
Contoh berikut menggunakan opsi max_time_series_length untuk mencapai pelatihan yang cepat. Dengan menetapkan nilai opsi max_time_series_length ke 30, hanya
30 titik waktu terbaru yang digunakan untuk membuat model komponen tren. Semua 383
deret waktu masih digunakan untuk membuat model komponen yang tidak trending.
Ikuti langkah-langkah berikut untuk membuat model:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, tempel kueri berikut, lalu klik Run:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2, max_time_series_length = 30 ) AS SELECT * FROM `bqml_tutorial.nyc_citibike_time_series` WHERE date < '2016-06-01';
Kueri membutuhkan waktu sekitar 35 detik untuk menyelesaikannya. Proses ini 3x lebih cepat dibandingkan dengan kueri yang Anda gunakan di bagian Buat model untuk memperkirakan beberapa deret waktu dengan ruang penelusuran hyperparameter yang lebih kecil. Karena overhead waktu yang konstan untuk bagian non-pelatihan pada kueri, seperti pemrosesan data, perolehan kecepatan jauh lebih tinggi jika jumlah deret waktu jauh lebih besar daripada dalam contoh ini. Untuk satu juta deret waktu, peningkatan kecepatan mendekati rasio panjang deret waktu dan nilai opsi
max_time_series_length. Dalam hal ini, peningkatan kecepatan lebih besar dari 10x.
Evaluasi akurasi perkiraan untuk model dengan ruang penelusuran hyperparameter yang lebih kecil dan strategi pelatihan yang cepat dan cerdas
Ikuti langkah-langkah berikut untuk mengevaluasi model:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, tempel kueri berikut, lalu klik Run:
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Kueri ini menampilkan nilai MAPE sebesar 0.3515, dan nilai sMAPE sebesar 0.2473.
Ingat bahwa tanpa penggunaan strategi pelatihan yang cepat, hasil akurasi perkiraan menghasilkan nilai MAPE sebesar 0.3337 dan nilai sMAPE sebesar 0.2337.
Perbedaan antara kedua kumpulan nilai metrik adalah dalam 3%, yang secara statistik tidak signifikan.
Singkatnya, Anda telah menggunakan ruang penelusuran hyperparameter yang lebih kecil dan strategi pelatihan yang cepat dan cerdas untuk membuat pelatihan model Anda lebih dari 20x lebih cepat tanpa mengorbankan akurasi perkiraan. Seperti yang disebutkan sebelumnya, dengan lebih banyak deret waktu, peningkatan kecepatan oleh strategi pelatihan cepat yang cerdas dapat jauh lebih tinggi. Selain itu, library ARIMA dasar yang digunakan oleh model ARIMA_PLUS telah dioptimalkan untuk berjalan 5x lebih cepat dari sebelumnya. Bersama-sama, keuntungan ini memungkinkan
perkiraan jutaan deret waktu dalam hitungan jam.
Membuat model untuk memperkirakan satu juta deret waktu
Pada langkah ini, Anda memperkirakan penjualan minuman keras untuk lebih dari 1 juta produk minuman keras di berbagai toko menggunakan data penjualan minuman keras publik Iowa. Pelatihan model ini menggunakan ruang penelusuran hyperparameter yang kecil serta strategi pelatihan yang cepat dan cerdas.
Ikuti langkah-langkah berikut untuk mengevaluasi model:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, tempel kueri berikut, lalu klik Run:
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast_by_product` OPTIONS( MODEL_TYPE = 'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COL = 'date', TIME_SERIES_DATA_COL = 'total_bottles_sold', TIME_SERIES_ID_COL = ['store_number', 'item_description'], HOLIDAY_REGION = 'US', AUTO_ARIMA_MAX_ORDER = 2, MAX_TIME_SERIES_LENGTH = 30 ) AS SELECT store_number, item_description, date, SUM(bottles_sold) as total_bottles_sold FROM `bigquery-public-data.iowa_liquor_sales.sales` WHERE date BETWEEN DATE("2015-01-01") AND DATE("2021-12-31") GROUP BY store_number, item_description, date;
Kueri membutuhkan waktu sekitar 1 jam 16 menit untuk menyelesaikannya.
Pembersihan
Agar akun Google Cloud Anda tidak dikenai biaya untuk resource yang digunakan dalam tutorial ini, hapus project yang berisi resource tersebut, atau simpan project dan hapus resource satu per satu.
- Anda dapat menghapus project yang dibuat.
- Atau, Anda dapat menyimpan project dan menghapus set data.
Menghapus set data
Jika project Anda dihapus, semua set data dan semua tabel dalam project akan dihapus. Jika ingin menggunakan kembali project tersebut, Anda dapat menghapus set data yang dibuat dalam tutorial ini:
Jika perlu, buka halaman BigQuery di konsolGoogle Cloud .
Di navigasi, klik set data bqml_tutorial yang Anda buat.
Klik Hapus set data untuk menghapus set data, tabel, dan semua data.
Pada dialog Hapus set data, konfirmasi perintah hapus dengan mengetikkan nama set data Anda (
bqml_tutorial), lalu klik Hapus.
Menghapus project Anda
Untuk menghapus project:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Langkah berikutnya
- Pelajari cara memperkirakan deret waktu tunggal dengan model univariat
- Pelajari cara memperkirakan deret waktu tunggal dengan model multivariat
- Pelajari cara memperkirakan beberapa deret waktu dengan model univariat
- Pelajari cara memperkirakan beberapa deret waktu secara hierarkis dengan model univariat
- Untuk ringkasan BigQuery ML, lihat Pengantar AI dan ML di BigQuery.