在本教學課程中,您將瞭解如何大幅加快一組ARIMA_PLUS單變數時間序列模型的訓練速度,以便透過單一查詢執行多個時間序列預測。此外,您也會瞭解如何評估預測準確率。
本教學課程會預測多個時間序列。系統會針對一或多個指定資料欄中的每個值,計算每個時間點的預測值。舉例來說,如果您想預測天氣,並指定包含城市資料的資料欄,預測資料會包含城市 A 所有時間點的預測值,然後是城市 B 所有時間點的預測值,依此類推。
本教學課程會使用公開的
bigquery-public-data.new_york.citibike_trips
和
iowa_liquor_sales.sales
資料表中的資料。自行車行程資料只包含幾百個時間序列,因此可用於說明各種加速模型訓練的策略。酒類銷售資料包含超過 100 萬個時間序列,因此可用於大規模展示時間序列預測。
閱讀本教學課程之前,請先參閱「使用單變數模型預測多個時間序列」和「大規模時間序列預測最佳做法」。
目標
在本教學課程中,您會使用下列項目:
- 使用
CREATE MODEL陳述式建立時間序列模型。 - 使用
ML.EVALUATE函式評估模型準確率。 - 使用
CREATE MODEL陳述式的AUTO_ARIMA_MAX_ORDER、TIME_SERIES_LENGTH_FRACTION、MIN_TIME_SERIES_LENGTH和MAX_TIME_SERIES_LENGTH選項,大幅縮短模型訓練時間。
為求簡化,本教學課程不會說明如何使用 ML.FORECAST 或 ML.EXPLAIN_FORECAST 函式產生預測。如要瞭解如何使用這些函式,請參閱「使用單變數模型預測多個時間序列」。
費用
本教學課程使用 Google Cloud的計費元件,包括:
- BigQuery
- BigQuery ML
如要進一步瞭解費用,請參閱 BigQuery 定價頁面和 BigQuery ML 定價頁面。
事前準備
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- 新專案會自動啟用 BigQuery。如要在現有專案中啟用 BigQuery,請前往
Enable the BigQuery API.
如要建立資料集,您需要
bigquery.datasets.createIAM 權限。如要建立模型,您必須具備下列權限:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
如要執行推論,您需要下列權限:
bigquery.models.getDatabigquery.jobs.create
所需權限
如要進一步瞭解 BigQuery 中的 IAM 角色和權限,請參閱「IAM 簡介」。
建立資料集
建立 BigQuery 資料集來儲存機器學習模型。
控制台
前往 Google Cloud 控制台的「BigQuery」頁面。
在「Explorer」窗格中,按一下專案名稱。
依序點按 「View actions」(查看動作) >「Create dataset」(建立資料集)。
在「建立資料集」頁面中,執行下列操作:
在「Dataset ID」(資料集 ID) 中輸入
bqml_tutorial。針對「Location type」(位置類型) 選取「Multi-region」(多區域),然後選取「US (multiple regions in United States)」(us (多個美國區域))。
其餘設定請保留預設狀態,然後按一下「Create dataset」(建立資料集)。
bq
如要建立新的資料集,請使用 bq mk 指令搭配 --location 旗標。如需可能的完整參數清單,請參閱 bq mk --dataset 指令參考資料。
建立名為「
bqml_tutorial」的資料集,並將資料位置設為「US」,以及說明設為「BigQuery ML tutorial dataset」:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
這個指令採用
-d捷徑,而不是使用--dataset旗標。如果您省略-d和--dataset,該指令預設會建立資料集。確認資料集已建立完成:
bq ls
API
請呼叫 datasets.insert 方法,搭配已定義的資料集資源。
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
在嘗試這個範例之前,請按照使用 BigQuery DataFrames 的 BigQuery 快速入門導覽課程中的 BigQuery DataFrames 設定說明操作。 詳情請參閱 BigQuery DataFrames 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定 ADC」。
建立輸入資料表
下列查詢的 SELECT 陳述式使用 EXTRACT 函式,從 starttime 資料欄中擷取日期資訊。這項查詢會使用 COUNT(*) 子句,取得每日的 Citi Bike 行程總數。
「table_1」有 679 個時間序列。這項查詢會使用額外的 INNER JOIN 邏輯,選取超過 400 個時間點的所有時間序列,因此總共有 383 個時間序列。
請按照下列步驟建立輸入資料表:
前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中貼上以下查詢,然後點選「執行」:
CREATE OR REPLACE TABLE `bqml_tutorial.nyc_citibike_time_series` AS WITH input_time_series AS ( SELECT start_station_name, EXTRACT(DATE FROM starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY start_station_name, date ) SELECT table_1.* FROM input_time_series AS table_1 INNER JOIN ( SELECT start_station_name, COUNT(*) AS num_points FROM input_time_series GROUP BY start_station_name) table_2 ON table_1.start_station_name = table_2.start_station_name WHERE num_points > 400;
使用預設參數為多個時間序列建立模型
您想預測每個 Citi Bike 站點的單車行程數量,這需要許多時間序列模型,也就是輸入資料中每個 Citi Bike 站點各需要一個模型。您可以編寫多個 CREATE MODEL 查詢來執行這項操作,但這可能相當繁瑣且耗時,尤其是在有大量時間序列時。您可以改用單一查詢建立及調整一組時間序列模型,一次預測多個時間序列。
OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) 子句表示您要建立一組以 ARIMA 為基礎的時間序列 ARIMA_PLUS 模型。time_series_timestamp_col 選項指定包含時間序列的資料欄,time_series_data_col 選項指定要預測的資料欄,time_series_id_col 則指定要建立時間序列的一或多個維度。
這個範例會省略 2016 年 6 月 1 日之後時間序列中的時間點,以便稍後使用 ML.EVALUATE 函式評估預測準確度。
請按照下列步驟建立模型:
前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中貼上以下查詢,然後點選「執行」:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_default` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name' ) AS SELECT * FROM bqml_tutorial.nyc_citibike_time_series WHERE date < '2016-06-01';
查詢大約需要 15 分鐘才能完成。
評估每個時間序列的預測準確度
使用 ML.EVALUATE 函式評估模型的預測準確率。
請按照下列步驟評估模型:
前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中貼上以下查詢,然後點選「執行」:
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
這項查詢會回報多項預測指標,包括:
結果應如下所示:
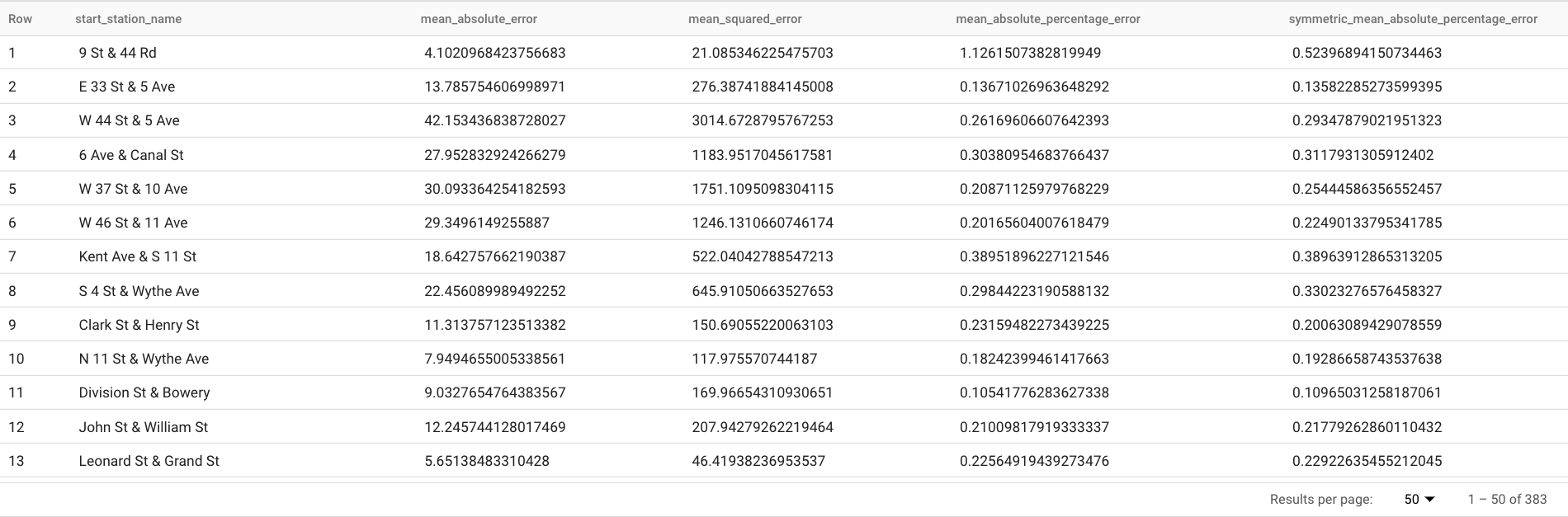
ML.EVALUATE函式中的TABLE子句會識別包含實際資料的資料表。系統會將預測結果與真值資料進行比較,藉此計算準確度指標。在本例中,nyc_citibike_time_series包含 2016 年 6 月 1 日前後的時間序列點。2016 年 6 月 1 日之後的點是實際資料。系統會使用 2016 年 6 月 1 日之前的資料點訓練模型,以便預測該日期之後的資料。計算指標時,只需要 2016 年 6 月 1 日之後的資料點。系統會忽略 2016 年 6 月 1 日前的點數,不會納入指標計算。ML.EVALUATE函式中的STRUCT子句指定了函式的參數。horizon值為7,表示查詢會根據七點預測計算預測準確度。請注意,如果真值資料的比較點少於七個,系統只會根據可用點計算準確度指標。perform_aggregation值為TRUE,表示預測準確度指標是根據時間點的指標匯總而來。如果您指定perform_aggregation值為FALSE,系統會針對每個預測時間點傳回預測準確度。如要進一步瞭解輸出資料欄,請參閱
ML.EVALUATE函式。
評估整體預測準確度
評估所有 383 個時間序列的預測準確度。
在 ML.EVALUATE 傳回的預測指標中,只有平均絕對百分比誤差和對稱平均絕對百分比誤差與時間序列值無關。因此,如要評估整組時間序列的預測準確度,只有這兩項指標的匯總值才有意義。
請按照下列步驟評估模型:
前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中貼上以下查詢,然後點選「執行」:
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
這項查詢會傳回 MAPE 值 0.3471,以及 sMAPE 值 0.2563。
建立模型,在較小的超參數搜尋空間中預測多個時間序列
在「Create a model to multiple time-series with default parameters」(使用預設參數為多個時間序列建立模型) 一節中,您使用了所有訓練選項的預設值,包括 auto_arima_max_order 選項。這個選項可控制 auto.ARIMA 演算法中超參數調整的搜尋空間。
在下列查詢建立的模型中,您可以將 auto_arima_max_order 選項值從預設的 5 變更為 2,藉此縮小超參數的搜尋空間。
請按照下列步驟評估模型:
前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中貼上以下查詢,然後點選「執行」:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2 ) AS SELECT * FROM `bqml_tutorial.nyc_citibike_time_series` WHERE date < '2016-06-01';
查詢大約需要 2 分鐘才能完成。回想一下,先前的模型在
auto_arima_max_order值為5時,大約需要 15 分鐘才能完成,因此這項變更可將模型訓練速度提升約 7 倍。如果您想知道為何速度增幅不是5/2=2.5x,這是因為auto_arima_max_order值增加時,候選模型數量和複雜度都會增加。這會導致模型訓練時間增加。
評估超參數搜尋空間較小的模型預測準確度
請按照下列步驟評估模型:
前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中貼上以下查詢,然後點選「執行」:
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
這項查詢會傳回 MAPE 值 0.3337,以及 sMAPE 值 0.2337。
在「評估整體預測準確度」部分,您評估的模型具有較大的超參數搜尋空間,其中 auto_arima_max_order 選項值為 5。這會產生 MAPE 值 0.3471,以及 sMAPE 值 0.2563。在本例中,您可以看到較小的超參數搜尋空間實際上可提供更高的預測準確度。其中一個原因是 auto.ARIMA 演算法只會針對整個模型化管道的趨勢模組執行超參數調整。auto.ARIMA演算法選取的最佳 ARIMA 模型可能無法為整個管道產生最佳預測結果。
建立模型,運用較小的超參數搜尋空間和智慧快速訓練策略,預測多個時間序列
在這個步驟中,您可以使用一或多個 max_time_series_length、max_time_series_length 或 time_series_length_fraction 訓練選項,縮小超參數搜尋空間,並採用智慧快速訓練策略。
週期性建模 (例如季節性) 需要一定數量的時間點,但趨勢建模所需的時間點較少。此外,趨勢模型化的運算成本遠高於其他時間序列元件,例如季節性。使用上述快速訓練選項,您就能以時間序列子集有效模擬趨勢元件,而其他時間序列元件則會使用整個時間序列。
以下範例使用 max_time_series_length 選項,快速完成訓練。將 max_time_series_length 選項值設為 30,即可只使用最近 30 個時間點來模擬趨勢元件。所有 383 個時間序列仍用於模擬非趨勢成分。
請按照下列步驟建立模型:
前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中貼上以下查詢,然後點選「執行」:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2, max_time_series_length = 30 ) AS SELECT * FROM `bqml_tutorial.nyc_citibike_time_series` WHERE date < '2016-06-01';
查詢大約需要 35 秒才能完成。與「建立模型,以較小的超參數搜尋空間預測多個時間序列」一節中使用的查詢相比,速度快了 3 倍。由於查詢的非訓練部分 (例如資料前處理) 會產生固定的時間負擔,因此當時間序列數量遠大於這個範例時,速度增益會高出許多。如果有一百萬個時間序列,速度增幅會接近時間序列長度與
max_time_series_length選項值的比率。在這種情況下,速度增幅會超過 10 倍。
使用較小的超參數搜尋空間和智慧快速訓練策略,評估模型的預測準確度
請按照下列步驟評估模型:
前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中貼上以下查詢,然後點選「執行」:
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
這項查詢會傳回 MAPE 值 0.3515,以及 sMAPE 值 0.2473。
請回想一下,如果不使用快速訓練策略,預測準確度會產生 MAPE 值 0.3337 和 sMAPE 值 0.2337。兩組指標值之間的差異在 3% 以內,不具統計顯著性。
簡而言之,您使用了較小的超參數搜尋空間和智慧快速訓練策略,在不犧牲預測準確度的情況下,將模型訓練速度提升超過 20 倍。如先前所述,時間序列越多,智慧快速訓練策略的加速效果就越顯著。此外,ARIMA_PLUS 模型使用的基礎 ARIMA 程式庫也經過最佳化,執行速度比以往快 5 倍。這些優勢加總起來,可讓您在數小時內預測數百萬個時間序列。
建立模型來預測數百萬個時間序列
在這個步驟中,您將使用愛荷華州酒類銷售公開資料,預測不同商店中超過 100 萬種酒類產品的銷售量。模型訓練會使用小型超參數搜尋空間,以及智慧快速訓練策略。
請按照下列步驟評估模型:
前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中貼上以下查詢,然後點選「執行」:
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast_by_product` OPTIONS( MODEL_TYPE = 'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COL = 'date', TIME_SERIES_DATA_COL = 'total_bottles_sold', TIME_SERIES_ID_COL = ['store_number', 'item_description'], HOLIDAY_REGION = 'US', AUTO_ARIMA_MAX_ORDER = 2, MAX_TIME_SERIES_LENGTH = 30 ) AS SELECT store_number, item_description, date, SUM(bottles_sold) as total_bottles_sold FROM `bigquery-public-data.iowa_liquor_sales.sales` WHERE date BETWEEN DATE("2015-01-01") AND DATE("2021-12-31") GROUP BY store_number, item_description, date;
這項查詢約需 1 小時 16 分鐘才能完成。
清除所用資源
如要避免系統向您的 Google Cloud 帳戶收取本教學課程中所用資源的相關費用,請刪除含有該項資源的專案,或者保留專案但刪除個別資源。
- 您可以刪除建立的專案。
- 或者您可以保留專案並刪除資料集。
刪除資料集
刪除專案將移除專案中所有的資料集與資料表。若您希望重新使用專案,您可以刪除本教學課程中所建立的資料集。
如有必要,請在Google Cloud 控制台中開啟 BigQuery 頁面。
在導覽窗格中,按一下您建立的 bqml_tutorial 資料集。
按一下「刪除資料集」,即可刪除資料集、資料表和所有資料。
在「Delete dataset」(刪除資料集) 對話方塊中,輸入資料集的名稱 (
bqml_tutorial),然後按一下「Delete」(刪除) 來確認刪除指令。
刪除專案
如要刪除專案,請進行以下操作:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
後續步驟
- 瞭解如何使用單變數模型預測單一時間序列
- 瞭解如何使用多變數模型預測單一時間序列
- 瞭解如何使用單變數模型預測多個時間序列
- 瞭解如何使用單變數模型,以階層方式預測多個時間序列
- 如需 BigQuery ML 的總覽,請參閱 BigQuery 中的 AI 和 ML 簡介。