이 튜토리얼에서는 단일 쿼리로 여러 시계열 예측을 수행하도록 시계열 모델 집합 학습을 대폭 가속화하는 방법을 알아봅니다. 예측 정확도를 평가하는 방법도 알아봅니다.
마지막 단계를 제외한 모든 단계에서 new_york.citibike_trips 데이터를 사용합니다.
이 데이터에는 Citi Bike를 이용한 뉴욕시 여행에 관한 정보가 포함되어 있습니다. 이 데이터 세트에는 시계열 수백 개만 포함됩니다. 모델 학습을 가속화하는 다양한 전략을 설명하는 데 사용됩니다.
마지막 단계에서는 iowa_liquor_sales.sales 데이터를 사용하여 시계열을 100만 개 넘게 예측합니다.
이 튜토리얼을 읽기 전에 NYC 도심 자전거 여행 데이터에서 단일 쿼리로 여러 시계열 예측 수행을 읽어야 합니다. 대규모 시계열 예측 권장사항도 읽어야 합니다.
목표
이 가이드에서는 다음을 사용합니다.
CREATE MODEL문은 시계열 모델이나 시계열 모델 집합을 만듭니다.ML.EVALUATE함수는 예측 정확도를 평가합니다.AUTO_ARIMA_MAX_ORDER,TIME_SERIES_LENGTH_FRACTION,MIN_TIME_SERIES_LENGTH,MAX_TIME_SERIES_LENGTH학습 옵션은 모델 학습 시간을 크게 줄입니다.
편의를 위해 이 튜토리얼에서는 ML.FORECAST 또는 ML.EXPLAIN_FORECAST를 사용하여 설명 가능한 예측을 생성하는 방법을 다루지 않습니다. 이러한 함수를 사용하는 방법은 NYC 도심 자전거 여행 데이터에서 단일 쿼리로 여러 시계열 예측 수행을 참조하세요.
비용
이 가이드에서는 비용이 청구될 수 있는 다음과 같은 Google Cloud 구성요소를 사용합니다.
- BigQuery
- BigQuery ML
비용에 대한 자세한 내용은 BigQuery 가격 책정 페이지와 BigQuery ML 가격 책정 페이지를 참조하세요.
시작하기 전에
- Google Cloud 계정에 로그인합니다. Google Cloud를 처음 사용하는 경우 계정을 만들고 Google 제품의 실제 성능을 평가해 보세요. 신규 고객에게는 워크로드를 실행, 테스트, 배포하는 데 사용할 수 있는 $300의 무료 크레딧이 제공됩니다.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
- BigQuery는 새 프로젝트에서 자동으로 사용 설정됩니다.
기존 프로젝트에서 BigQuery를 활성화하려면 다음으로 이동합니다.
Enable the BigQuery API.
1단계: 데이터 세트 만들기
ML 모델을 저장할 BigQuery 데이터 세트를 만듭니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
Explorer 창에서 프로젝트 이름을 클릭합니다.
작업 보기 > 데이터 세트 만들기를 클릭합니다.
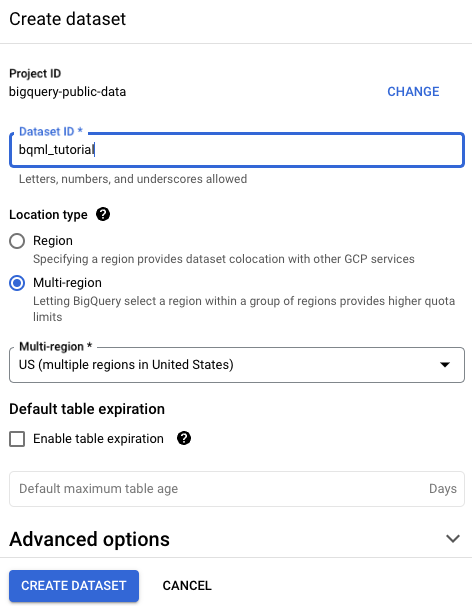
데이터 세트 만들기 페이지에서 다음을 수행합니다.
데이터 세트 ID에
bqml_tutorial를 입력합니다.위치 유형에 대해 멀티 리전을 선택한 다음 US(미국 내 여러 리전)를 선택합니다.
공개 데이터 세트는
US멀티 리전에 저장됩니다. 편의상 같은 위치에 데이터 세트를 저장합니다.나머지 기본 설정은 그대로 두고 데이터 세트 만들기를 클릭합니다.
2단계: 예측할 시계열 만들기
다음 쿼리에서 FROM bigquery-public-data.new_york.citibike_trips 절은 new_york 데이터 세트에서 citibike_trips 테이블을 쿼리 중임을 나타냅니다.
CREATE OR REPLACE TABLE `bqml_tutorial.nyc_citibike_time_series` AS WITH input_time_series AS ( SELECT start_station_name, EXTRACT(DATE FROM starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY start_station_name, date ) SELECT table_1.* FROM input_time_series AS table_1 INNER JOIN ( SELECT start_station_name, COUNT(*) AS num_points FROM input_time_series GROUP BY start_station_name) table_2 ON table_1.start_station_name = table_2.start_station_name WHERE num_points > 400
쿼리를 실행하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 새 쿼리 작성 버튼을 클릭합니다.
쿼리 편집기 텍스트 영역에 위의 GoogleSQL 쿼리를 입력합니다.
실행을 클릭합니다.
쿼리의 SELECT 문은 EXTRACT 함수를 사용하여 starttime 열에서 날짜 정보를 추출합니다. 이 쿼리는 COUNT(*) 절을 사용하여 일간 총 도심 자전거 여행 수를 가져옵니다.
table_1에는 시계열이 679개 있습니다. 이 쿼리는 추가 INNER JOIN 논리를 사용하여 시점이 400개를 초과하는 모든 시계열을 선택하므로 시계열이 총 383개 생성됩니다.
3단계: 기본 매개변수를 사용하여 여러 시계열 동시 예측
이 단계에서는 여러 Citi Bike 자전거 대여소에서 시작하는 일간 총 여행 수를 예측합니다. 이를 위해서는 여러 시계열을 예측해야 합니다.
여러 CREATE MODEL 쿼리를 작성할 수 있지만, 특히 시계열 수가 많을 때 이렇게 하면 번거롭고 시간도 많이 소요될 수 있습니다.
이를 개선하기 위해 BigQuery ML에서는 단일 쿼리만 사용해서 여러 시계열을 예측하기 위한 일련의 시계열 모델을 생성할 수 있습니다. 또한 모든 시계열에 대한 모델 집합이 동시에 이루어집니다.
다음 GoogleSQL 쿼리에서 CREATE MODEL은 bqml_tutorial.nyc_citibike_arima_model_default이라는 모델 집합을 만들고 학습시킵니다.
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_default` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name' ) AS SELECT * FROM bqml_tutorial.nyc_citibike_time_series WHERE date < '2016-06-01'
모델 생성 및 학습을 위해 CREATE MODEL 쿼리를 실행하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 새 쿼리 작성 버튼을 클릭합니다.
쿼리 편집기 텍스트 영역에 위의 GoogleSQL 쿼리를 입력합니다.
실행을 클릭합니다.
쿼리가 완료되려면 약 14분 25초가 걸립니다.
OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) 절은 ARIMA 기반 시계열 ARIMA_PLUS 모델 집합을 만들고 있음을 나타냅니다. time_series_timestamp_col 및 time_series_data_col 외에도 다른 입력 시계열을 주석 처리하는 데 사용되는 time_series_id_col을 지정해야 합니다.
이 예시에서는 2016년 6월 1일 이후 시계열의 시점을 제외하여 나중에 ML.EVALUATE 함수를 사용하여 예측 정확도를 평가하는 데 사용할 수 있습니다.
4단계: 각 시계열의 예측 정확도 평가
이 단계에서는 다음 ML.EVALUATE 쿼리를 사용하여 각 시계열의 예측 정확도를 평가합니다.
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation))
위의 쿼리를 실행하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 새 쿼리 작성 버튼을 클릭합니다.
쿼리 편집기 텍스트 영역에 위의 GoogleSQL 쿼리를 입력합니다.
실행을 클릭합니다. 이 쿼리는 다음과 같은 몇 가지 예측 측정항목을 보고합니다.
결과는 다음과 같이 표시됩니다.
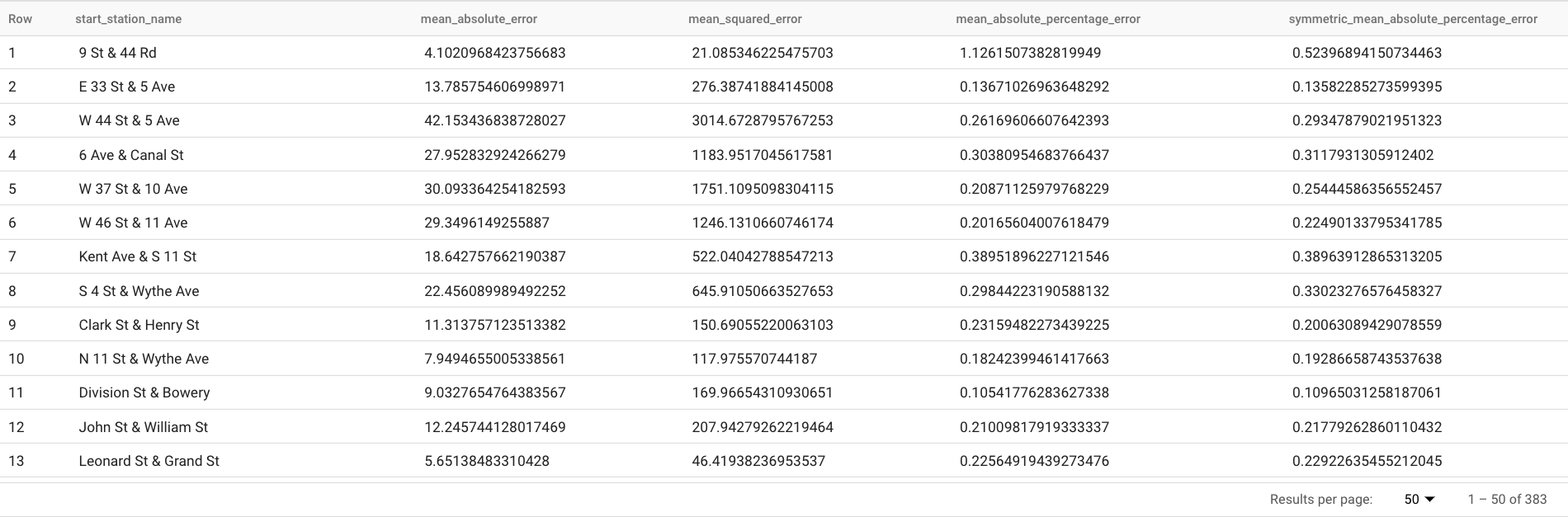
ML.EVALUATE는 이전 단계에서 학습된 ARIMA_PLUS 모델을 첫 번째 인수로 사용합니다.
두 번째 인수는 정답 데이터가 포함된 데이터 테이블입니다. 이러한 예측 결과를 정답 데이터와 비교하여 정확도 측정항목을 계산합니다. 이 경우 nyc_citibike_time_series에는 2016년 6월 1일 이전과 2016년 6월 1일 이후의 시계열 지점이 모두 포함됩니다. 2016년 6월 1일 이후 지점은 정답 데이터입니다. 2016년 6월 1일 이전의 지점은 해당 날짜 이후의 예측을 생성하도록 모델을 학습시키는 데 사용됩니다.
측정항목을 계산할 때는 2016년 6월 1일 이후 지점만 있으면 됩니다. 2016년 6월 1일 이전의 지점은 측정항목 계산에서 무시됩니다.
세 번째 인수는 매개변수 두 개가 포함된 STRUCT입니다. 범위는 7입니다. 즉, 쿼리가 7지점 예측을 기반으로 예측 정확도를 계산한다는 의미입니다. 정답 데이터의 비교 지점이 7개 미만인 경우 사용 가능한 지점을 기준으로 정확도 측정항목이 계산됩니다. perform_aggregation의 값은 TRUE입니다. 즉, 예측 정확도 측정항목은 시점을 기준으로 측정항목에서 집계됩니다. perform_aggregation을 FALSE로 지정하면 예측된 각 시점마다 예측 정확도가 반환됩니다.
5단계: 모든 시계열의 전체 예측 정확도 평가
이 단계에서는 다음 쿼리를 사용하여 전체 383개의 시계열의 예측 정확성을 평가합니다.
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation))
ML.EVALUATE에서 반환한 예측 측정항목 중 평균 절대 비율 오류와 대칭 평균 절대 비율 오류만 시계열 값 독립적입니다. 따라서 시계열 집합의 전체 예측 정확도를 평가하려면 이러한 두 측정항목의 집계만 의미가 있습니다.
이 쿼리는 MAPE가 0.3471, sMAPE가 0.2563인 결과를 반환합니다.
6단계: 더 작은 초매개변수 검색 공간을 사용하여 여러 시계열 동시 예측
3단계에서는 auto_arima_max_order를 포함한 모든 학습 옵션의 기본값을 사용했습니다. 이 옵션은 auto.ARIMA 알고리즘에서 초매개변수를 조정할 수 있도록 검색 공간을 제어합니다.
이 단계에서는 초매개변수에 더 작은 검색 공간을 사용합니다.
CREATE OR REPLACE MODELbqml_tutorial.nyc_citibike_arima_model_max_order_2OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2 ) AS SELECT * FROMbqml_tutorial.nyc_citibike_time_seriesWHERE date < '2016-06-01'
이 쿼리는 auto_arima_max_order를 5(기본값)에서 2로 줄입니다.
쿼리를 실행하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 새 쿼리 작성 버튼을 클릭합니다.
쿼리 편집기 텍스트 영역에 위의 GoogleSQL 쿼리를 입력합니다.
실행을 클릭합니다.
쿼리가 완료되는 데 약 1분 45초가 걸립니다.
auto_arima_max_order가 5이면 쿼리가 완료되는 데 14분 25초가 걸립니다. 따라서auto_arima_max_order를 2로 설정하면 속도가 약 7배 빨라집니다. 속도 향상이 5/2=2.5x가 아닌 이유는auto_arima_max_order순서를 늘릴 때 후보 모델 수가 증가할 뿐만 아니라 복잡하므로 모델 학습 시간이 증가하기 때문입니다.
7단계: 더 작은 초매개변수 검색 공간을 기반으로 예측 정확도 평가
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation))
이 쿼리는 MAPE가 0.3337, sMAPE가 0.2337인 결과를 반환합니다.
5단계에서 더 큰 초매개변수 검색 공간인 auto_arima_max_order = 5를 사용하여 MAPE는 0.3471 및 sMAPE는 0.2563이 되었습니다.
따라서 초매개변수 검색 공간이 작을수록 실제로 예측 정확도가 높아집니다. 한 가지 이유는 auto.ARIMA 알고리즘이 전체 모델링 파이프라인의 트렌드 모듈에 대해서만 초매개변수 조정을 수행하기 때문입니다. auto.ARIMA 알고리즘으로 선택한 최적의 ARIMA 모델은 전체 파이프라인에 대한 최적의 예측 결과를 생성하지 못할 수 있습니다.
8단계: 더 작은 초매개변수 검색 공간과 스마트한 빠른 학습 전략으로 여러 시계열 동시 예측
이 단계에서는 더 작은 초매개변수 검색 공간과 max_time_series_length, max_time_series_length 또는 time_series_length_fraction 학습 옵션을 하나 이상 사용하는 스마트한 빠른 학습 전략을 모두 사용합니다.
계절성과 같은 주기적 모델링에는 특정 시점 수가 필요하지만 트렌드 모델링에는 필요한 시점이 줄어듭니다. 한편 트렌드 모델링의 연산 비용은 계절성과 같은 다른 시계열 구성요소보다 매우 높습니다. 위 빠른 학습 옵션을 사용하면 시계열의 하위 집합으로 트렌드 구성요소를 효율적으로 모델링할 수 있지만 다른 시계열 구성요소는 전체 시계열을 사용합니다.
이 예시에서는 max_time_series_length를 사용하여 빠른 학습을 수행합니다.
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2, max_time_series_length = 30 ) AS SELECT * FROM `bqml_tutorial.nyc_citibike_time_series` WHERE date < '2016-06-01'
max_time_series_length 옵션 값은 30이므로 각 383개 시계열의 경우 최근 시점 30개만 트렌드 구성요소를 모델링하는 데 사용됩니다. 모든 시계열은 트렌드가 아닌 구성요소를 모델링하는 데 계속 사용됩니다.
쿼리를 실행하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 새 쿼리 작성 버튼을 클릭합니다.
쿼리 편집기 텍스트 영역에 위의 GoogleSQL 쿼리를 입력합니다.
실행을 클릭합니다.
쿼리가 완료되려면 약 35초 정도 걸립니다. 이는 빠른 학습 전략을 사용하지 않는 학습 쿼리(즉, 1분 45초 소요)에 비해 3배 더 빠릅니다. 데이터 사전 처리 등 쿼리의 비학습 부분에 대한 일정한 시간 오버헤드로 인해 시계열 수가 이 경우보다 현저히 클 때 속도가 훨씬 높아집니다. 시계열 수가 100만 개인 경우 속도 증가는 시계열 길이와 max_time_series_length 값의 비율에 접근합니다. 이 경우 속도 증가는 10배보다 큽니다.
9단계: 초매개변수 검색 공간이 작고 스마트한 빠른 학습 전략을 통해 모델의 예측 정확도 평가
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation))
이 쿼리는 MAPE가 0.3515, sMAPE가 0.2473인 결과를 반환합니다.
빠른 학습 전략을 사용하지 않으면 예측 정확도 결과는 MAPE가 0.3337이고 sMAPE는 0.2337입니다. 두 측정항목 값 집합 간의 차이가 3% 이내이므로 통계적으로 유의미하지 않습니다.
간단히 말해, 더 작은 초매개변수 검색 공간과 스마트한 빠른 학습 전략을 사용하여 예측 정확도 저하 없이 모델 학습 속도를 20배 이상 향상시켰습니다. 앞에서 언급했듯이 더 많은 시계열을 사용하면 스마트한 빠른 학습 전략을 통한 속도가 더욱 빨라집니다. 또한 ARIMA_PLUS에서 사용하는 기본 ARIMA 라이브러리는 이전보다 5배 빠르게 실행되도록 최적화되었습니다. 이러한 이점을 함께 사용하면 몇 시간 안에 시계열을 수백만 개 예측할 수 있습니다.
10단계: 100만 개 이상의 시계열 예측
이 단계에서는 아이오와주 주류 판매 공개 데이터를 사용하여 다양한 매장의 100만 개가 넘는 주류 제품에 대한 주류 판매를 예측합니다.
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast_by_product` OPTIONS( MODEL_TYPE = 'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COL = 'date', TIME_SERIES_DATA_COL = 'total_bottles_sold', TIME_SERIES_ID_COL = ['store_number', 'item_description'], HOLIDAY_REGION = 'US', AUTO_ARIMA_MAX_ORDER = 2, MAX_TIME_SERIES_LENGTH = 30 ) AS SELECT store_number, item_description, date, SUM(bottles_sold) as total_bottles_sold FROM `bigquery-public-data.iowa_liquor_sales.sales` WHERE date BETWEEN DATE("2015-01-01") AND DATE("2021-12-31") GROUP BY store_number, item_description, date
모델 학습에서는 작은 초매개변수 검색 공간과 스마트한 빠른 학습 전략을 계속 사용합니다. 쿼리가 완료되는 데 약 1시간 16분이 소요됩니다.
삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
- 만든 프로젝트를 삭제할 수 있습니다.
- 또는 프로젝트를 유지하고 데이터 세트를 삭제할 수 있습니다.
데이터 세트 삭제
프로젝트를 삭제하면 프로젝트의 데이터 세트와 테이블이 모두 삭제됩니다. 프로젝트를 다시 사용하려면 이 튜토리얼에서 만든 데이터 세트를 삭제할 수 있습니다.
필요한 경우 Google Cloud 콘솔에서 BigQuery 페이지를 엽니다.
앞서 만든 bqml_tutorial 데이터 세트를 탐색에서 선택합니다.
데이터 세트 삭제를 클릭하여 데이터 세트, 테이블, 모든 데이터를 삭제합니다.
데이터 세트 삭제 대화상자에서 데이터 세트 이름(
bqml_tutorial)을 입력하고 삭제를 클릭하여 삭제 명령어를 확인합니다.
프로젝트 삭제
프로젝트를 삭제하는 방법은 다음과 같습니다.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
다음 단계
- 머신러닝에 대한 자세한 내용은 머신러닝 단기집중과정을 참조하세요.
- BigQuery ML 개요는 BigQuery ML 소개를 참조하세요.
- Google Cloud 콘솔에 대한 자세한 내용은 Google Cloud 콘솔 사용을 참조하세요.