En este instructivo, aprenderás a acelerar de manera significativa el entrenamiento de un conjunto de modelos de series temporales univariados ARIMA_PLUS para realizar varias previsiones de series temporales con una sola consulta. También aprenderás a evaluar la exactitud de la previsión.
En este instructivo, se realizan previsiones para varias series temporales. Los valores previstos se calculan para cada punto temporal y para cada valor en una o más columnas especificadas. Por ejemplo, si deseas predecir el clima y especificas una columna que contiene datos de la ciudad, los datos previstos contendrán predicciones para todos los puntos temporales de la ciudad A, luego los valores previstos para todos los puntos temporales de la ciudad B, y así sucesivamente.
En este instructivo, se usan datos de las tablas públicas bigquery-public-data.new_york.citibike_trips y iowa_liquor_sales.sales. Los datos de viajes en bicicleta solo contienen unos cientos de series temporales, por lo que se usan para ilustrar varias estrategias para acelerar el entrenamiento de modelos.
Los datos de ventas de licores tienen más de 1 millón de series temporales, por lo que se usan para mostrar la previsión de series temporales a gran escala.
Antes de leer este instructivo, debes leer Prevé varias series temporales con un modelo univariado y Prácticas recomendadas para la previsión de series temporales a gran escala.
Objetivos
En este instructivo usarás lo siguiente:
- Crear un modelo de series temporales con la declaración
CREATE MODEL - Evaluar la precisión del modelo con la función
ML.EVALUATE - Usa las opciones
AUTO_ARIMA_MAX_ORDER,TIME_SERIES_LENGTH_FRACTION,MIN_TIME_SERIES_LENGTHyMAX_TIME_SERIES_LENGTHde la instrucciónCREATE MODELpara reducir significativamente el tiempo de entrenamiento de modelos.
Para que sea más simple, en este instructivo no se explica cómo usar las funciones ML.FORECAST o ML.EXPLAIN_FORECAST para generar previsiones. Para aprender a usar esas funciones, consulta Cómo predecir varias series temporales con un modelo univariado.
Costos
En este instructivo, se usan los siguientes componentes facturables de Google Cloud:
- BigQuery
- BigQuery ML
Para obtener más información sobre los costos, consulta la página de precios de BigQuery y la página de precios de BigQuery ML.
Antes de comenzar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- BigQuery se habilita automáticamente en proyectos nuevos.
Para activar BigQuery en un proyecto existente, ve a
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Para crear el conjunto de datos, necesitas el permiso
bigquery.datasets.createde IAM.Para crear el modelo, necesitas los siguientes permisos:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
Para ejecutar inferencias, necesitas los siguientes permisos:
bigquery.models.getDatabigquery.jobs.create
Permisos necesarios
Para obtener más información sobre los roles y permisos de IAM en BigQuery, consulta Introducción a IAM.
Crea un conjunto de datos
Crea un conjunto de datos de BigQuery para almacenar tu modelo de AA.
Console
En la consola de Google Cloud , ve a la página BigQuery.
En el panel Explorador, haz clic en el nombre de tu proyecto.
Haz clic en Ver acciones > Crear conjunto de datos.
En la página Crear conjunto de datos, haz lo siguiente:
En ID del conjunto de datos, ingresa
bqml_tutorial.En Tipo de ubicación, selecciona Multirregión y, luego, EE.UU. (varias regiones en Estados Unidos).
Deja la configuración predeterminada restante como está y haz clic en Crear conjunto de datos.
bq
Para crear un conjunto de datos nuevo, usa el comando bq mk con la marca --location. Para obtener una lista completa de los parámetros posibles, consulta la
referencia del
comando bq mk --dataset.
Crea un conjunto de datos llamado
bqml_tutorialcon la ubicación de los datos establecida enUSy una descripción deBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
En lugar de usar la marca
--dataset, el comando usa el acceso directo-d. Si omites-dy--dataset, el comando crea un conjunto de datos de manera predeterminada.Confirma que se haya creado el conjunto de datos:
bq ls
API
Llama al método datasets.insert con un recurso de conjunto de datos definido.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
Permite trabajar con BigQuery DataFrames.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
Crea una tabla de datos de entrada
La declaración SELECT de la siguiente consulta usa la función EXTRACT para extraer la información de la fecha de la columna starttime. La consulta usa la cláusula COUNT(*) para obtener la cantidad total diaria de viajes con Citi Bike.
table_1 tiene 679 series temporales. La consulta usa la lógica adicional INNER JOIN para seleccionar todas las series temporales que tienen más de 400 puntos temporales, lo que da como resultado un total de 383 series temporales.
Sigue estos pasos para crear la tabla de datos de entrada:
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
CREATE OR REPLACE TABLE `bqml_tutorial.nyc_citibike_time_series` AS WITH input_time_series AS ( SELECT start_station_name, EXTRACT(DATE FROM starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY start_station_name, date ) SELECT table_1.* FROM input_time_series AS table_1 INNER JOIN ( SELECT start_station_name, COUNT(*) AS num_points FROM input_time_series GROUP BY start_station_name) table_2 ON table_1.start_station_name = table_2.start_station_name WHERE num_points > 400;
Crea un modelo para varias series temporales con parámetros predeterminados
Deseas prever la cantidad de viajes en bicicleta para cada estación de Citi Bike, lo que requiere muchos modelos de series temporales, uno para cada estación de Citi Bike que se incluye en los datos de entrada. Puedes escribir varias consultas de CREATE MODEL para hacerlo, pero puede ser un proceso tedioso y lento, en especial cuando tienes una gran cantidad de series temporales. En su lugar, puedes usar una sola consulta para crear y ajustar un conjunto de modelos de series temporales y, así, prever varias series temporales a la vez.
La cláusula OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) indica que creas un conjunto de modelos de serie temporal ARIMA_PLUS basados en ARIMA. La opción time_series_timestamp_col especifica la columna que contiene las series temporales, la opción time_series_data_col especifica la columna para la que se realizará la previsión y la opción time_series_id_col especifica una o más dimensiones para las que deseas crear series temporales.
En este ejemplo , se omiten los puntos temporales de las series temporales posteriores al 1 de junio de 2016 para que esos puntos temporales se puedan usar a fin de evaluar la exactitud de la previsión más adelante con la función ML.EVALUATE.
Sigue estos pasos para crear el modelo:
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_default` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name' ) AS SELECT * FROM bqml_tutorial.nyc_citibike_time_series WHERE date < '2016-06-01';
La consulta tarda alrededor de 15 minutos en completarse.
Evalúa la exactitud de la previsión para cada serie temporal
Evalúa la exactitud de la previsión del modelo con la función ML.EVALUATE.
Sigue estos pasos para evaluar el modelo:
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Esta consulta informa varias métricas de previsión, incluidas las siguientes:
Los resultados deberían ser similares a los siguientes:
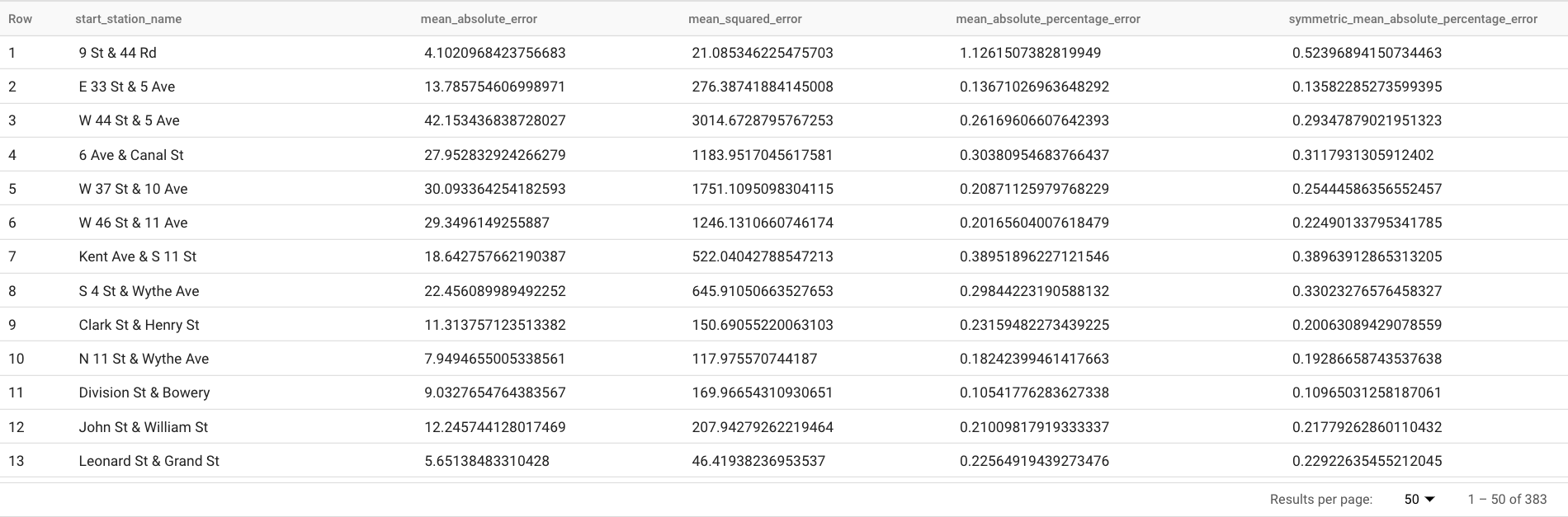
La cláusula
TABLEen la funciónML.EVALUATEidentifica una tabla que contiene los datos de verdad fundamental. Los resultados de la previsión se comparan con los datos de verdad fundamental para calcular las métricas de precisión. En este caso,nyc_citibike_time_seriescontiene los puntos de series temporales anteriores y posteriores al 1 de junio de 2016. Los puntos posteriores al 1 de junio de 2016 son los datos de verdad fundamental. Los puntos anteriores al 1 de junio de 2016 se usan para entrenar el modelo y generar previsiones después de esa fecha. Para calcular las métricas, solo se necesitan los puntos posteriores al 1 de junio de 2016. Los puntos anteriores al 1 de junio de 2016 se ignoran en el cálculo de las métricas.La cláusula
STRUCTde la funciónML.EVALUATEespecificó parámetros para la función. El valor dehorizones7, lo que significa que la consulta calcula la exactitud de la previsión en función de una previsión de siete puntos. Ten en cuenta que, si los datos de verdad fundamental tienen menos de siete puntos para la comparación, las métricas de exactitud se calculan solo en función de los puntos disponibles. El valor deperform_aggregationesTRUE, lo que significa que las métricas de exactitud de la previsión se agregan en función de las métricas de los puntos temporales. Si especificas un valor deperform_aggregationdeFALSE, se muestra la exactitud de la previsión para cada punto temporal previsto.Para obtener más información sobre las columnas de salida, consulta la función
ML.EVALUATE.
Evalúa la precisión general de la previsión
Evalúa la exactitud de la previsión para las 383 series temporales.
De las métricas de previsión que muestra ML.EVALUATE, solo el error porcentual absoluto medio y el error porcentual absoluto medio simétrico son independientes del valor de la serie temporal. Por lo tanto, para evaluar la exactitud total de la previsión del conjunto de series temporales, solo la agregación de estas dos métricas es relevante.
Sigue estos pasos para evaluar el modelo:
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Esta consulta devuelve un valor MAPE de 0.3471 y un valor sMAPE de 0.2563.
Crea un modelo para prever varias series temporales con un espacio de búsqueda de hiperparámetros más pequeño
En la sección Crea un modelo para varias series temporales con parámetros predeterminados, usaste los valores predeterminados para todas las opciones de entrenamiento, incluida la opción auto_arima_max_order. Esta opción controla el espacio de búsqueda para el ajuste de hiperparámetros en el algoritmo auto.ARIMA.
En el modelo creado por la siguiente consulta, usarás un espacio de búsqueda más pequeño para los hiperparámetros. Para ello, cambiarás el valor de la opción auto_arima_max_order del valor predeterminado 5 a 2.
Sigue estos pasos para evaluar el modelo:
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2 ) AS SELECT * FROM `bqml_tutorial.nyc_citibike_time_series` WHERE date < '2016-06-01';
La consulta tarda alrededor de 2 minutos en completarse. Recuerda que el modelo anterior tardó alrededor de 15 minutos en completarse cuando el valor de
auto_arima_max_orderera5, por lo que este cambio mejora la velocidad de entrenamiento de modelos en alrededor de 7 veces. Si te preguntas por qué el aumento de velocidad no es5/2=2.5x, esto se debe a que, cuando aumenta el valor deauto_arima_max_order, no solo aumenta la cantidad de modelos candidatos, sino también la complejidad. Esto hace que aumente el tiempo de entrenamiento del modelo.
Evalúa la exactitud de la previsión de un modelo con un espacio de búsqueda de hiperparámetros más pequeño
Sigue estos pasos para evaluar el modelo:
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Esta consulta devuelve un valor MAPE de 0.3337 y un valor sMAPE de 0.2337.
En la sección Evalúa la exactitud general de la previsión, evaluaste un modelo con un espacio de búsqueda de hiperparámetros más grande, en el que el valor de la opción auto_arima_max_order es 5. Esto generó un valor de MAPE de 0.3471 y un valor de sMAPE de 0.2563. En este caso, puedes ver que un espacio de búsqueda de hiperparámetros más pequeño proporciona una exactitud de previsión más alta. Un motivo es que el algoritmo auto.ARIMA solo realiza el ajuste de hiperparámetros para el módulo de tendencia de toda la canalización de modelado. Es posible que el mejor modelo ARIMA que selecciona el algoritmo auto.ARIMA no genere los mejores resultados de previsión para toda la canalización.
Crea un modelo para prever varias series temporales con un espacio de búsqueda de hiperparámetros más pequeño y estrategias de entrenamiento rápido inteligentes
En este paso, usarás un espacio de búsqueda de hiperparámetros más pequeño y la estrategia de entrenamiento rápido inteligente con una o más de las opciones de entrenamiento max_time_series_length, max_time_series_length o time_series_length_fraction.
Si bien el modelado periódico, como la estacionalidad, requiere una cierta cantidad de puntos temporales, el modelado de tendencias requiere menos puntos temporales. Por otra parte, el modelado de tendencias es mucho más costoso desde el punto de vista del procesamiento que otros componentes de las series temporales, como la estacionalidad. Si usas las opciones de entrenamiento rápido anteriores, puedes modelar de manera eficiente el componente de tendencia con un subconjunto de las series temporales, mientras que los otros componentes de series temporales usan todas las series temporales.
En el siguiente ejemplo, se usa la opción max_time_series_length para lograr un entrenamiento rápido. Si estableces el valor de la opción max_time_series_length en 30, solo se usarán los 30 puntos temporales más recientes para modelar el componente de tendencia. Aún se usan todas las 383 series temporales para modelar los componentes distintos de la tendencia.
Sigue estos pasos para crear el modelo:
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2, max_time_series_length = 30 ) AS SELECT * FROM `bqml_tutorial.nyc_citibike_time_series` WHERE date < '2016-06-01';
La consulta tarda unos 35 segundos en completarse. Esto es 3 veces más rápido en comparación con la consulta que usaste en la sección Crea un modelo para predecir varias series temporales con un espacio de búsqueda de hiperparámetros más pequeño. Debido a la sobrecarga de tiempo constante para la parte de la consulta que no es de entrenamiento, como el procesamiento previo de los datos, el aumento de velocidad es mucho mayor cuando la cantidad de series temporales es mucho más grande que en este ejemplo. Para un millón de series temporales, el aumento de velocidad se aproxima a la proporción de la longitud de la serie temporal y el valor de la opción
max_time_series_length. En ese caso, la velocidad será mayor que 10 veces.
Evalúa la exactitud de la previsión de un modelo con un espacio de búsqueda de hiperparámetros más pequeño y estrategias de entrenamiento rápido inteligentes
Sigue estos pasos para evaluar el modelo:
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Esta consulta devuelve un valor MAPE de 0.3515 y un valor sMAPE de 0.2473.
Recuerda que, sin el uso de estrategias de entrenamiento rápido, los resultados de la exactitud de la previsión arrojan un valor de MAPE de 0.3337 y un valor de sMAPE de 0.2337.
La diferencia entre los dos conjuntos de valores de métricas se encuentra dentro del 3%, lo que es insignificante en términos estadísticos.
En resumen, usaste un espacio de búsqueda de hiperparámetros más pequeño y estrategias de entrenamiento rápido inteligentes para que tu entrenamiento de modelos sea 20 veces más rápido sin sacrificar la exactitud de la previsión. Como se mencionó antes, con más series temporales, el aumento de velocidad que logran las estrategias de entrenamiento rápido inteligentes puede ser mucho mayor. Además, la biblioteca ARIMA subyacente que usan los modelos ARIMA_PLUS se optimizó para ejecutarse 5 veces más rápido que antes. En conjunto, estos beneficios permiten la previsión de millones de series temporales en cuestión de horas.
Crea un modelo para prever un millón de series temporales
En este paso, prevés las ventas de licores de más de 1 millón de productos de licores en diferentes tiendas mediante los datos públicos de ventas de licores de Iowa. El entrenamiento de modelos usa un espacio de búsqueda de hiperparámetros pequeño y la estrategia de entrenamiento rápido inteligente.
Sigue estos pasos para evaluar el modelo:
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast_by_product` OPTIONS( MODEL_TYPE = 'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COL = 'date', TIME_SERIES_DATA_COL = 'total_bottles_sold', TIME_SERIES_ID_COL = ['store_number', 'item_description'], HOLIDAY_REGION = 'US', AUTO_ARIMA_MAX_ORDER = 2, MAX_TIME_SERIES_LENGTH = 30 ) AS SELECT store_number, item_description, date, SUM(bottles_sold) as total_bottles_sold FROM `bigquery-public-data.iowa_liquor_sales.sales` WHERE date BETWEEN DATE("2015-01-01") AND DATE("2021-12-31") GROUP BY store_number, item_description, date;
La consulta tarda alrededor de 1 hora y 16 minutos en completarse.
Realiza una limpieza
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
- Puedes borrar el proyecto que creaste.
- De lo contrario, puedes mantener el proyecto y borrar el conjunto de datos.
Borra tu conjunto de datos
Borrar tu proyecto quita todos sus conjuntos de datos y tablas. Si prefieres volver a usar el proyecto, puedes borrar el conjunto de datos que creaste en este instructivo:
Si es necesario, abre la página de BigQuery en la consola deGoogle Cloud .
En el panel de navegación, haz clic en el conjunto de datos bqml_tutorial que creaste.
Haz clic en Borrar conjunto de datos para borrar el conjunto de datos, la tabla y todos los datos.
En el cuadro de diálogo Borrar conjunto de datos, escribe el nombre del conjunto de datos (
bqml_tutorial) para confirmar el comando de borrado y, luego, haz clic en Borrar.
Borra tu proyecto
Para borrar el proyecto, haz lo siguiente:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
¿Qué sigue?
- Aprende a prever una sola serie temporal con un modelo univariable
- Aprende a prever una sola serie temporal con un modelo multivariable
- Obtén más información para prever varias series temporales con un modelo univariable
- Aprende a predecir jerárquicamente varias series temporales con un modelo univariable
- Para obtener una descripción general de BigQuery ML, consulta Introducción a la IA y el aprendizaje automático en BigQuery.